How to extract entities from text based in a list of desired entities or regex rules using Spark NLP at scale

Named Entity recognition can be implemented with many approaches. In this post we introduce the use of manually crafted list of entities (also called gazetteer) or regular expressions to identify them in the text using the scalability of Spark NLP with Python using the annotator EntityRuler. It can be used for NLP finance applications, healthcare NLP and many other fields.
Introduction
Named Entity Recognition (NER) is the task of identifying important words in a text and associating them with a category. For example, we may be interested in finding all the personal names in documents, or company names in news articles. Other examples include domain specific uses such as identifying all disease names in a clinical text, or company trading codes in financial ones.
There are many approaches when designing models to automatically identify entities in text, and the most recent ones include the use of complex deep learning architectures that demand huge computational power to train and use them. Alternatives are to use gazetteer, i.e. a list of wanted names to be searched in the documents, or regular expressions (regex).
Recent progress in healthcare NLP indicates that hybrid approaches, where rule-based methods like the EntityRuler are combined with transformer-based models, can offer more robust results compared to relying on a single technique. Such layered strategies make it possible to capture critical medical terminology through domain-specific rules while leveraging deep learning for contextual flexibility, helping to reduce errors in clinical decision-making.
Another important development is the growing use of entity recognition pipelines in multimodal healthcare settings. In practice, Spark NLP is increasingly applied not only to process text from EHRs but also to align structured entities with signals from medical imaging and genomic data. In areas like oncology, this combined approach can accelerate the identification of relevant patient cohorts and support precision medicine programs at scale.
There is also a clear emphasis on compliance and transparency in healthcare NLP. Rule-based components, such as gazetteers and regex-driven entity recognition, are generally easier to validate and explain than purely neural models. Many healthcare providers integrate these explainable layers into their workflows to create NLP pipelines that combine strong performance with auditability and governance, making AI solutions more trustworthy in regulated environments.
In Spark NLP, all the mentioned approaches are implemented in different annotators:
- NerDL: Deep Learning approach based on a
char CNN + LSTM + CRFarchitecture. The implementation allows training custom models and using more than 1,400 pretrained models available on NLP Models Hub. - Token Classification with Transformers: Deep Learning approach based on Transformer architectures (BERT, RoBERTa, XLNet, AlBERT). These annotators allow to use pretrained models migrated from other deep learning frameworks (Hugging Face, Tensorflow Hub) into Spark NLP and currently contains more than 1,170pretrained models on NLP Models Hub.
- NerCrf: Machine Learning approach based on Conditional Random Fields. Also allows to train custom models or use the pretrained model(only one available at the time of writing this post).
- EntityRuler: Gazetteer and regular expression approach. This annotator does not have pretrained models on NLP Models Hub, as they are used with custom lists or regular expressions.
In this post, we will explore how to use the EntityRuler annotator, and keep posted for other publications explaining the other ones. This approach is easy to implement, and many companies already have such lists (client names, interested list of stock tickers, etc.). For a fast solution, we just need to find those names in text. When dealing with big data, though, this task can be optimized with the use of proper tools such as spark.
Spark NLP is the tool to work with Natural Language Processing (NLP) tasks in spark and has all the relevant NLP tasks implemented and ready to use, with the possibility to easily scale as needed. In this post, we will introduce how to use Spark NLP in Python to perform NER task using gazetteer lists of entities and regex. Let’s dive in!
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
To install Spark NLP, you can simply use any package manager like conda or pip. For example, using pip you can simply run pip install spark-nlp. For different installation options, check the official documentation.
Spark NLP processes the data using Pipelines, a structure that contains all the steps to be run on the input data the same way Spark ML does.
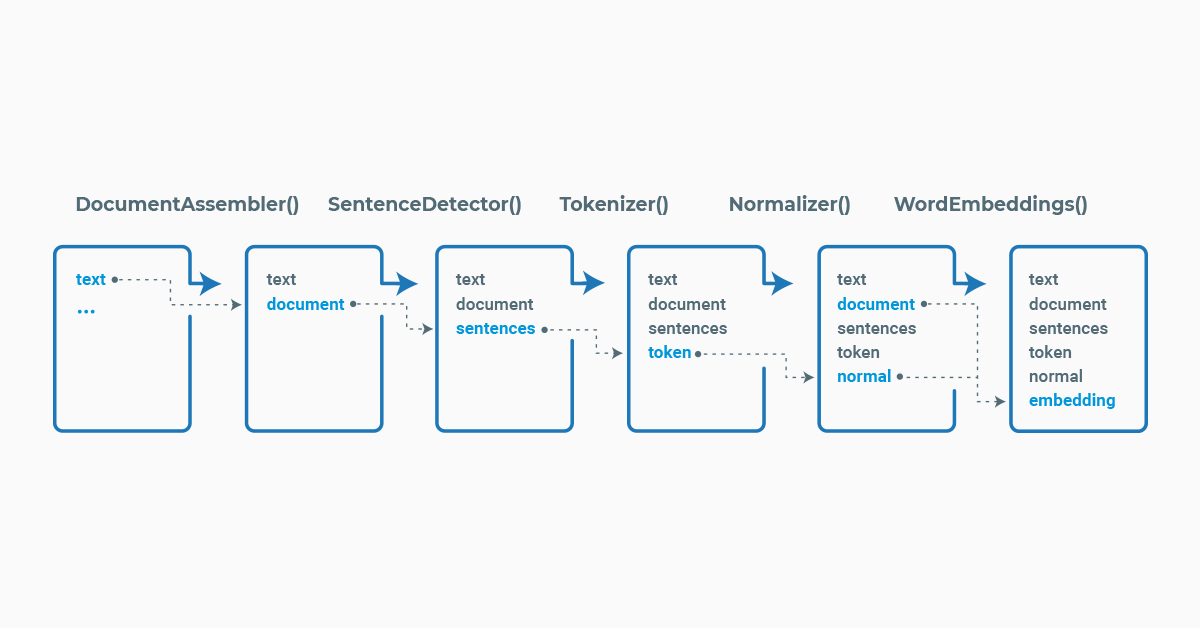
Example pipeline in Spark NLP
Each stage of the pipeline is created by an annotator that uses one or more of the previous information to create new annotation. Each annotator can be of two types, AnnotatorModel which can be used to make predictions based on pretrained models and the AnnotatorApproach which can be used to train new custom models. Pretrained models can be found in the NLP Models Hub.
As part of the spark ecosystem, before using the library we need to start a spark session, which can be done by:
import sparknlp spark = sparknlp.start()
Now that you know about Spark NLP basics, let’s see how to identify entities!
As mentioned, there are two types of annotators in Spark NLP, one that can train custom models and one that uses pretrained models. For the NER tasks based on gazetteer list, we will use the EntityRuler annotator, which has both Approach and Model versions.
As this annotator consists in finding the entities based in a list of desired names, the EntityRulerApproach annotator will store the given list in the EntityRulerModel parameters. All we need is a JSON or CSV file with the list of names or regex rules. For example, we may use the following entities.json file:
[
{
"label": "PERSON",
"patterns": [
"John",
"John Snow",
]
},
{
"label": "PERSON",
"patterns": [
"Eddard",
"Eddard Stark"
]
},
{
"label": "LOCATION",
"patterns": [
"Winterfell"
]
},
{
"label": "DATE",
"patterns": [
"[0-9]{4}-[0-9]{1,2}-[0-9]{1,2}"
],
"regex": true
}
]
Note that for the DATE entity, we added a regex pattern to match all dates in the format YYYY-mm-dd, but other formats could be used as well by just adding them to the list. Then, we can train an EntityRuler with the above JSON file with the following pipeline:
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import EntityRulerApproach, EntityRulerModel, Tokenizer
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
tokenizer = Tokenizer().setInputCols("document").setOutputCol("token")
entity_ruler = (
EntityRulerApproach()
.setInputCols(["document", "token"])
.setOutputCol("entity")
.setPatternsResource("entities.json")
)
pipeline = Pipeline(stages=[document_assembler, tokenizer, entity_ruler])
Note: We added the tokenizer to identify words in the sentences because it is necessary when using regular expressions. If your lists consist of only exact matches, you could remove this stage from the pipeline.
Then, we will create the EntityRulerModel by fitting the pipeline, which will make the gazetteer/regex list part of the model. Let’s create some example sentences in a spark data frame to fit it.
example = """Game of Thrones was released in 2011-04-17.
Lord Eddard Stark was the head of House Stark.
John Snow lives in Winterfell."""
# The name of the column is expected in the first stage of our pipeline
data = spark.createDataFrame([[example]]).toDF("text")
pipeline_model = pipeline.fit(data)
We can save the obtained EntityRulerModel to disk for future use with:
# It is the last stage of the pipeline
pipeline_model.stages[-1].write().overwrite().save('my_entityruler')
Then, a pretrained model can be loaded from disk with:
entity_ruler = (
EntityRulerModel.load("my_entityruler")
.setInputCols(["document", "token"])
.setOutputCol("entity")
)
Let’s check the results we can obtain using this model on our example sentences:
result = pipeline_model.transform(data)
import pyspark.sql.functions as F
# Make some data frame manipulation for better visualization of the results
result.select(
F.explode(F.arrays_zip("entity.result", "entity.metadata")).alias("col")
).select(
F.expr("col['0']").alias("keyword"),
F.expr("col['1']['entity']").alias("label")
).show()
+------------+--------+ | keyword| label| +------------+--------+ | 2011-04-17| DATE| |Eddard Stark| PERSON| | John Snow| PERSON| | Winterfell|LOCATION| +------------+--------+
Cool! Now you can start identifying the relevant entities in your text by curating lists of desired entities or building regular expressions. All of that with the capability of scaling the processing to thousands of documents with the use of spark.
Non-English Languages
This annotator considers an alphabet internally with the algorithm Aho-Corasick, and it won’t work as expected in some languages that have more characters than English. For example, in Spanish exists a character ñ, in Portuguese the character ç, or accents in characters (á, ú, ê, etc.). Many languages have their specific characters not present in English. To account for that and make the annotator work as expected, we can use the parameter .setAlphabetResource.
If a character is not present in the alphabet, we will get an error like this one:
Py4JJavaError: An error occurred while calling o69.fit. : java.lang.UnsupportedOperationException: Char ú not found on alphabet. Please check alphabet
To set a new alphabet in the EntityRulerApproach, we can use a plain text file (.txt) containing the characters. We can use line-breaks to improve readability. For example, this custom_alphabet.txt where we have the English standard alphabet plus some additional characters:
abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ áúéêçñ ÁÚÉÊÇÑ
Apart from setting the characters manually in a text file, you can also use a predefined alphabets for the most common languages: English, Spanish, French, and German. For example, if you have documents in Spanish, you just need to set an alphabet like the example below:
entity_ruler = (
EntityRulerApproach()
.setInputCols(["sentence"])
.setOutputCol("entity")
.setPatternsResource("locations.json")
.setAlphabetResource("Spanish")
)
Conclusion
In this article, we talked about named entity recognition using pre-determined rules or regular expressions. We introduced how to perform the task using the open-source Spark NLP library with Python, which can be used at scale in the spark ecosystem. It can be used for natural language processing applications in finance and any other field.
References
- EntityRuler annotator documentation
- Python Docs: EntityRulerApproach, EntityRulerModel
- Scala Docs: EntityRulerApproach, EntityRulerModel
- Visualization demos for NER in Spark NLP
- Named Entity Recognition (NER) with BERT in Spark NLP
FAQ
What are the main benefits of rule-based entity recognition in healthcare?
Rule-based methods provide high precision for critical medical terminology, are easier to validate in regulated settings, and complement machine learning models by capturing domain-specific vocabulary that neural networks may miss.
Can rule-based and deep learning approaches be combined in Spark NLP?
Yes. Many practitioners combine the EntityRuler with transformer-based annotators in Spark NLP. This hybrid setup allows domain rules to enforce accuracy while neural models handle context and variation, leading to stronger overall performance.
How does Spark NLP handle multilingual entity recognition?
Spark NLP supports custom alphabets and predefined resources for languages such as Spanish, French, and German. This makes it possible to adapt rule-based patterns and regex to multilingual clinical and financial datasets.
Why is explainability important in entity recognition for healthcare?
Explainability ensures that results can be traced, validated, and audited. Rule-based components are particularly useful because they offer transparent logic, which helps organizations meet compliance requirements and build trust with regulators.
What recent trends are shaping entity recognition in healthcare NLP?
Key trends include hybrid pipelines that improve accuracy, integration with multimodal data such as imaging and genomics, and increased emphasis on compliance. These developments make entity recognition more reliable and impactful in clinical practice.