
























































We often call Responsibility Reports (RR) to a series of documents including sustainability reports, corporate responsibility reports, corporate social responsibility reports, and ESG reports, in charge of sharing a series of non-financial KPIs about organizations.

Result of Responsibility Reports processing with Finance NLP
Result of Responsibility Reports processing with Finance NLP
Those KPI often include information from three main verticals: environmental, social and governance, in the broadest sense.
You can find many public RR in websites as https://responsibilityreports.com
How to automatically process a RR
The main problem of automatically trying to process a Responsibility Report is that most of their content is free text.

Example from TECK Responsibility Report, Air Quality, 2021
In order to automatically process free text, we can use Natural Language Understanding (NLP), a branch of Artificial Intelligence with enough capabilities to process documents of this kind. Domain-specific NLP, as Financial NLP, based on Apache Spark, is available in libraries as John Snow Labs natural language processing for Finance, which include capabilities for RR and ESG processing.
Let’s discuss some of the challenges we will find when automatising the processing of these documents with NLP.
Non-digital text
NLP by itself will be able to process what is digital text, but everything which is inside images, will require a image-to-text preprocessing, called OCR (Optical Character Recognition).

Example from TECK Responsibility Report, KPI for Air Quality, 2021
Solution: OCR. Fortunately, there are many libraries which can do OCR for us. Since we will stick with Finance NLP, another library in the John Snow Labs suite is Visual NLP. These two libraries share a common core based on Apache Spark, so the integration between them is seamless.
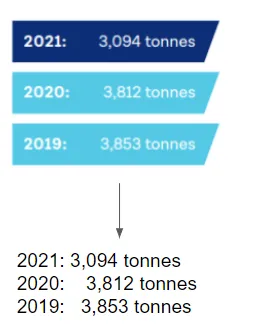
OCR-d text from images
Non-standard format
In most cases, RR are not mandatory, they hold a voluntary nature, which means they are also not regulated in format. Financial forms, on the contrary, are regulated and mandatory to fill, having all of them an assigned Form Type with strict filling rules.
With the recent breakthroughs in Deep Learning architectures (more specifically Transformers), latest Language Models (LM) have proved very effective in understanding textual details and context-dependant nuances.
Training Name Entity Recognition (NER) models, on top of Financial Language Models, will allow us to extract relevant pieces of information (entities) from our RR.
Solution: Finetuned Financial LM and NER. The main key is to finetune domain-specific (Financial) Language Models and use them to train specific Name Entity Recognition (NER) models.
By doing a search by keywords “finance”, “financial”, etc. you can find in John Snow Labs Models Hub dozens of English Financial NLP Language Models.
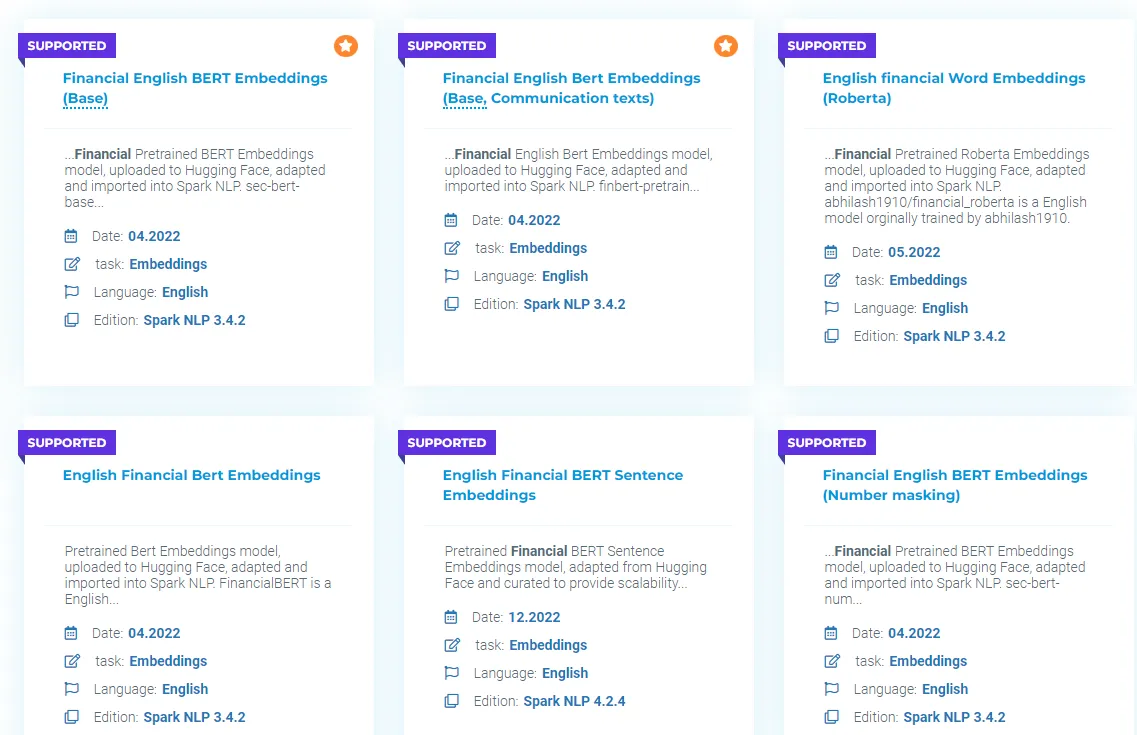
Some Financial Language Models from Models Hub
Finance NLP also includes up to 140+ pre-trained nlp models for finance, including some RR and ESG related, in John Snow Labs Models Hub.
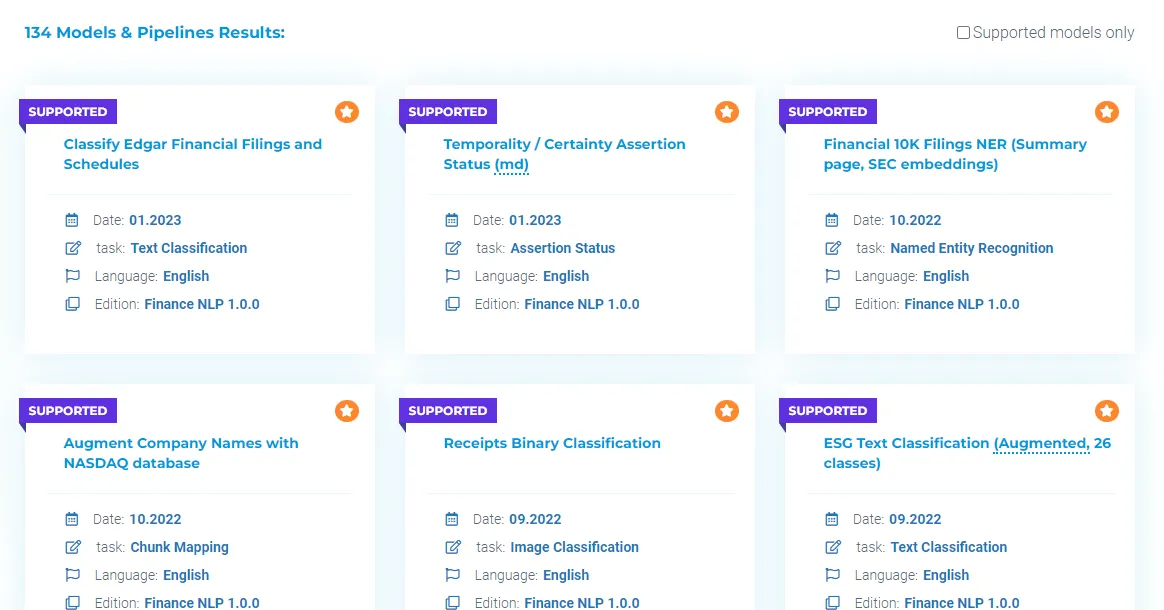
Some pre-trained Financial NLP models from Models Hub
Tables
Very often these documents contain tables and charts in them. Let’s see some tables in our previous example.

Table example from TECK Responsibility Report
If we process tables with different OCR engines (as Google’s Tesseract OCR), what we will retrieve is the text from the cells with no specific format. That will complicate the process of understanding, for example, which figures correspond to which year.
Solution: Table Extraction. Table Extraction is a Visual NLP capability included in the library, which can help us to retrieve the table in csv format and even use the integration with Finance NLP to carry out Question Answering on those tables.
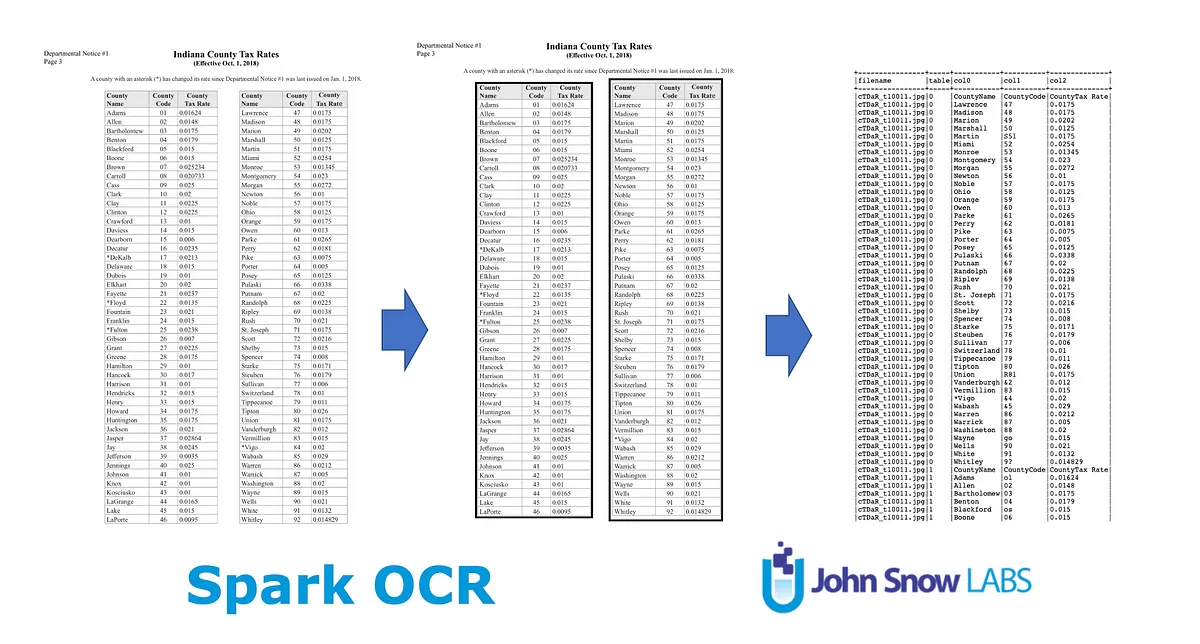
Table Detection and Extraction with Visual NLP (Spark OCR)
Charts
Charts is one of the challenges which still remain (by the publish time of this article) as not totally solved. Automatically understanding figures like this is still very challenging for the technology.
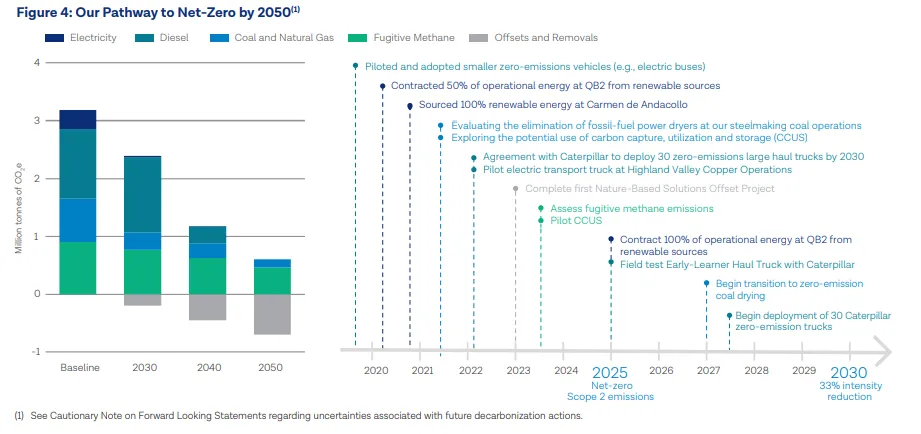
Chart example from TECK Responsibility Report
The good news is that most of the information is usually described as well in free text, so we can rely on NLP to capture some information. Another possibility would be to use Visual NLP to detect charts and then use a human-in-the-loop process to transform that information into text and add it to the document.
A use case
As mentioned before, you can use John Snow Labs Finance NLP and Visual NLP libraries combined, to process responsibility reports, carrying out the following steps:
1. Extract the text from a document (regardless if it’s digital or not), using Visual NLP.
2. Extract tables from a document, using Visual NLP;
3. Use Financial Language Models and pretrained Financial NLP NER models for detecting Responsibility Reports entities;
4. Use Table Question Answering, included in Financial NLP;
Extracting the text using Visual NLP
All the Spark NLP suite works on top of Spark MLLib, leveraging the concept of “Pipeline” as a series of Visual or Finance annotators, which carry out different tasks.
In order to extract digital (native) text and text embedded in images, we will use a PdfToText (to extract all digital text from the PDF), and PdfToImage + ImageToText (to extract all non-digital text, as for example text in images).
# If text PDF extract text
pdf_to_text = visual.PdfToText() \
.setInputCol("content") \
.setOutputCol("text") \
.setSplitPage(True) \
.setExtractCoordinates(True) \
.setStoreSplittedPdf(True)
# If image pdf, extract image
pdf_to_image = visual.PdfToImage() \
.setInputCol("content") \
.setOutputCol("image") \
.setKeepInput(True)
# Run OCR
ocr = visual.ImageToText() \
.setInputCol("image") \
.setOutputCol("text") \
.setConfidenceThreshold(60)
pipeline = PipelineModel(stages=[
pdf_to_text,
pdf_to_image,
ocr
])
You can get more information about this step in the following notebook.
After this step, you can save on the one hand the digital and OCR-d text in .txt format.

Some example OCRd text from a RR
Extracting tables using Visual NLP
The process of extracting tables requires several steps:
- First, converting the document pages to a series of images, to work at pixel level;
- Second, detecting tables using ImageTableDetector;
- After, we need to extract the tables to process them separately;
- Finally, we detect the cells and extract the textual content from them,
The pipeline, which you can see in action in this notebook, is available here.
# Convert document to images to work at pixel level
binary_to_image = visual.BinaryToImage()\
.setOutputCol("image")\
.setImageType(visual.ImageType.TYPE_3BYTE_BGR)
# Detect tables on the page using pretrained model
# It can be finetuned for have more accurate results for more specific documents
table_detector = visual.ImageTableDetector.pretrained("general_model_table_detection_v2", "en", "clinical/ocr")\
.setInputCol("image")\
.setOutputCol("region")
# Extract table regions to separate images
splitter = visual.ImageSplitRegions()\
.setInputCol("image")\
.setInputRegionsCol("region")\
.setOutputCol("table_image")\
.setDropCols("image")
# Detect cells on the table image
cell_detector = visual.ImageTableCellDetector()\
.setInputCol("table_image")\
.setOutputCol("cells")\
.setAlgoType("morphops")\
.setDrawDetectedLines(True)
# Extract text from the detected cells
table_recognition = visual.ImageCellsToTextTable()\
.setInputCol("table_image")\
.setCellsCol('cells')\
.setMargin(3)\
.setStrip(True)\
.setOutputCol('table')
pipeline_table = nlp.Pipeline(stages=[
binary_to_image,
table_detector,
splitter,
cell_detector,
table_recognition
])
Now you can save the tables in csv or json format. Let’s see an example on a random table from a RR (left), store in csv and then opened in Excel (right).

Table Extraction on DuPont 2022 RR (CO2)
Using Financial NLP Pretrained NER models for RR
We have a model available, called finner_responsibility_reports which extracts the following entities:
AGE, AMOUNT, COUNTABLE_ITEM, DATE_PERIOD, ECONOMIC_ACTION, ECONOMIC_KPI, ENVIRONMENTAL_ACTION, ENVIRONMENTAL_KPI, ENVIRONMENTAL_UNIT, ESG_ROLE, FACILITY_PLACE, ISO, PERCENTAGE, PROFESSIONAL_GROUP, RELATIVE_METRIC, SOCIAL_ACTION, SOCIAL_KPI, TARGET_GROUP, TARGET_GROUP_BUSINESS, WASTE
Again, a Spark Pipeline is required, but now with Financial NLP components:
- First, we get the text we extracted with OCR and assemble a Document with it;
- Then, we split into sentences, to manage length restrictions of DL architectures;
- After, we split sentences into tokens (something similar to words or pieces of word, inside the vocabulary of the Financial Language Model);
- Then, we use a finetuned Financial Bert-based NER available in our Models Hub;
- Finally, we merge all the tokens belonging to the same entity together with NerConverter.
document_assembler = nlp.DocumentAssembler()\
.setInputCol(“text”)\
.setOutputCol(“document”)\
sentence_detector = nlp.SentenceDetector()\
.setInputCols([“document”])\
.setOutputCol(“sentence”)\
tokenizer = nlp.Tokenizer() \
.setInputCols([“sentence”]) \
.setOutputCol(“token”)\
.setContextChars(['.', ',', ';', ':', '!', '?', '*', '-', '(', ')', '”', “'”, '%', '&'])
ner_model = finance.BertForTokenClassification.pretrained(“finner_responsibility_reports”, “en”, “finance/models”)\
.setInputCols([“sentence”, “token”])\
.setOutputCol(“ner”)\
.setCaseSensitive(True)\
.setMaxSentenceLength(512)
ner_converter = nlp.NerConverter()\
.setInputCols([“sentence”, “token”, “ner”])\
.setOutputCol(“ner_chunk”)
pipeline = nlp.Pipeline(stages=[
document_assembler,
sentence_detector,
tokenizer,
ner_model,
ner_converter
])
By using this pipeline, you can get similar results to these:

Using Financial Question Answering on tables
Let’s suppose we stored the table in step 2 as a json. Let’s load it from disk.
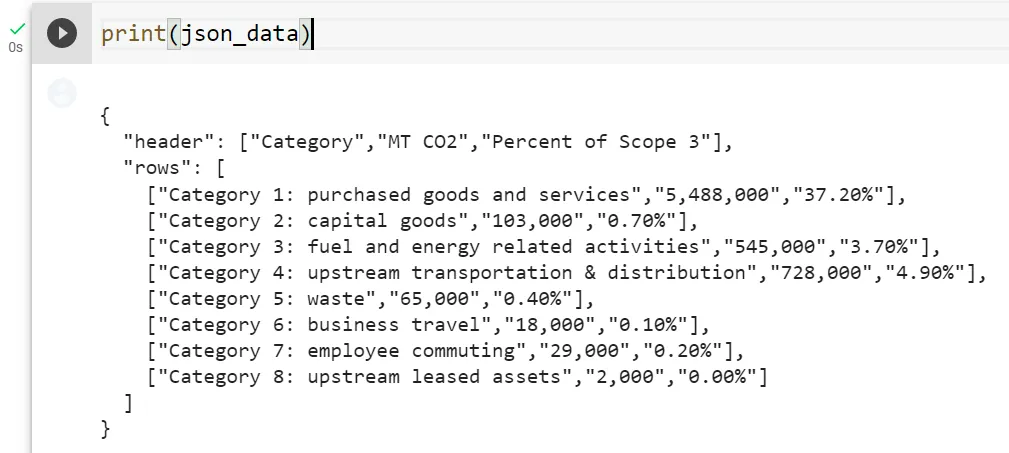
Now, let’s create some questions…
queries = [
"What is the maximum Percent of Scope 3?",
"What is the Category of the maximum Percent of Scope 3?",
"What is the sum of CO2?",
]
… and define a Table QA pipeline. It will consist of:
- A MultiDocumentAssembler, which will put together questions and the table data;
- A Sentence Splitter annotator to split the questions into sentences, in case there are several;
- A TableAssembler to transform JSON table to Spark Dataframe;
- A TAPAS Transformer, aimed to carry out Question Answering on Tables.
document_assembler = nlp.MultiDocumentAssembler() \
.setInputCols("table_json", "questions") \
.setOutputCols("document_table", "document_questions")
text_splitter = finance.SentenceDetector() \
.setInputCols(["document_questions"]) \
.setOutputCol("questions")
table_assembler = nlp.TableAssembler()\
.setInputCols(["document_table"])\
.setOutputCol("table")
tapas = nlp.TapasForQuestionAnswering.pretrained("table_qa_tapas_base_finetuned_wtq", "en")\
.setInputCols(["questions", "table"])\
.setOutputCol("answers")
pipeline = nlp.Pipeline(stages=[
document_assembler,
text_splitter,
table_assembler,
tapas
])
The result of applying this pipeline would be:

Where question is the question we asked about the table, the result is the answer, the aggregation if a possible mathematical operation on the data, and the cell positions are the coordinates of the table where the answer can be found.
You can find more about Financial Table QA in this notebook.
Extra: Check other ESG-related models
We have document classifiers and other ESG-related models in our Demo page here.
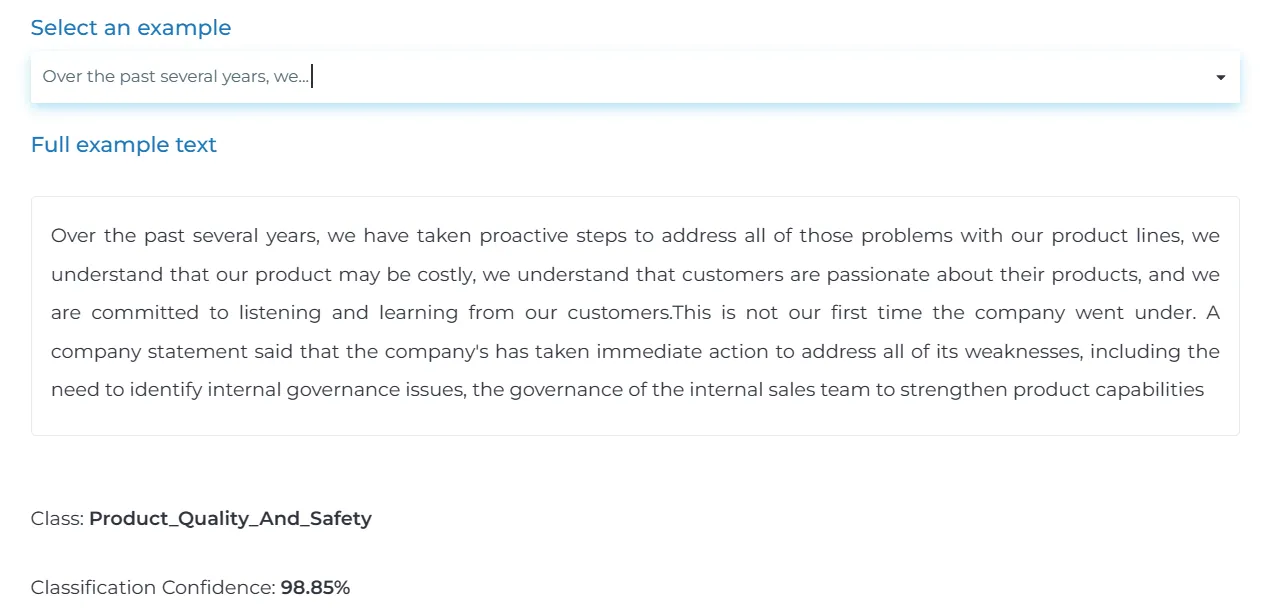
Example of ESG category detection trained on 22+ classes
Want to know more?
Find us at Slack , #finance channel, or write to support@johnsnowlabs.com.





