Spark OCR is a new generation Optical Character Recognition (OCR) products and it allows for text extraction from images. It uses the power of artificial intelligence-based machine learning technology and scalability that gives Spark.
- Spark OCR will accumulate knowledge using Deep Learning algorithms.
- With Spark you could scale your applications and process billions of documents.
- With Databricks it’s easy to develop and put your projects to production.
It’s a really modern, scalable, and flexible OCR NLP solution for your business.
In this post, we will demonstrate how we built an Optical Character Recognition (OCR) pipeline using the Spark OCR library in the Databricks notebooks.
We will create an example notebook, which load image documents as Spark DataFrame, recognize text, and show results.
This post contains two parts:
- Spark OCR installation to Databricks
- Creating and executing the notebook
What is Spark OCR and Databricks?
Spark OCR provides a set of Spark ML transformers/estimators that help users create and use OCR pipelines. It is built on top of Apache Spark.
Databricks is the Unified Data Analytics Platform. It presents a web-based platform for working with Spark, that provides automated cluster management and IPython-style notebooks.
In case you are a newbie with Databricks please follow Getting Started. Databricks have community edition so, you can try it for free.
Libraries installation
Before you start, make sure that you have:
- Spark OCR jar file
- Spark OCR python wheel file
- License key
If not please contact info@johnsnowlabs.com to get the library and free trial license.
The installation process includes the following steps:
- Installing Spark OCR library to Databricks and attaching it to the cluster
- Same step for Spark OCR python wheel file
- Adding license key
Installing libraries to Databricks
Install Spark OCR jar file or Spark OCR python wheel file to driver and executor nodes. Use Databricks library management. (More details here).
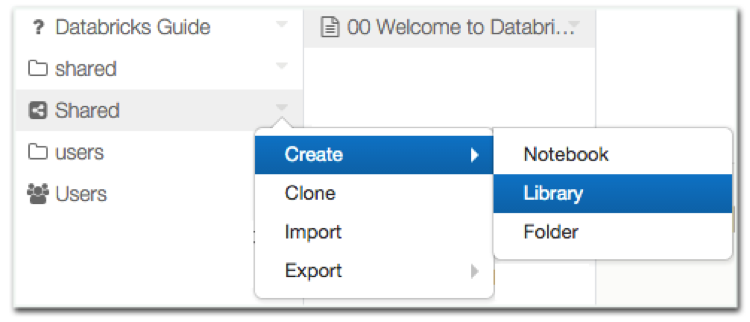
- Right-click the Workspace folder where you want to store the library.
- Select Create > Library.

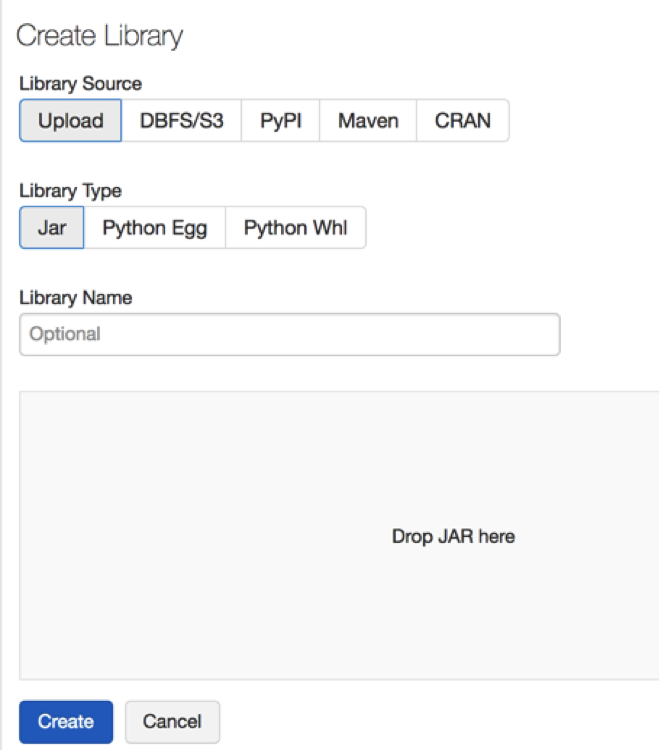
- Upload jar and Python Wheel files.
Attaching the libraries to the cluster
You can create the cluster or use an existing one. (For the new cluster please follow this instruction).
Use 6.4 version of the runtime, which includes Spark 2.4.5.
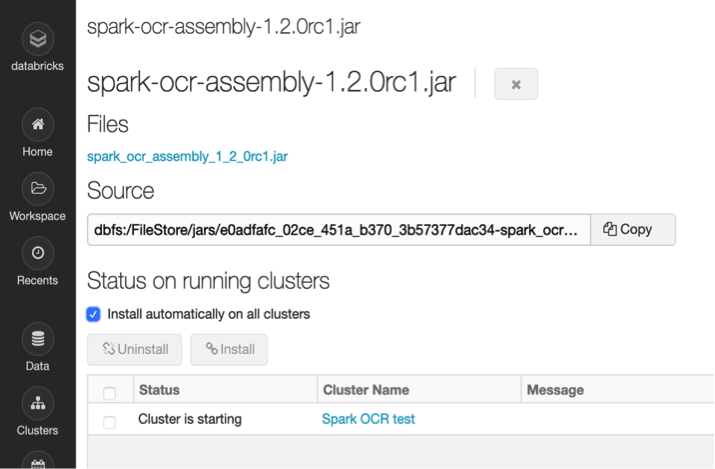
Navigate to the Spark OCR library details page attach it to your cluster. Either you can set `Install automatically on all clusters` flag to have Spark OCR in all your clusters.
Adding license key
The next step is setting license key as an environment variable.
- On the cluster configuration page, click the Advanced Options toggle.
- Click the Spark tab.
- Set the JSL_OCR_LICENSE environment variable in the Environment Variables field.
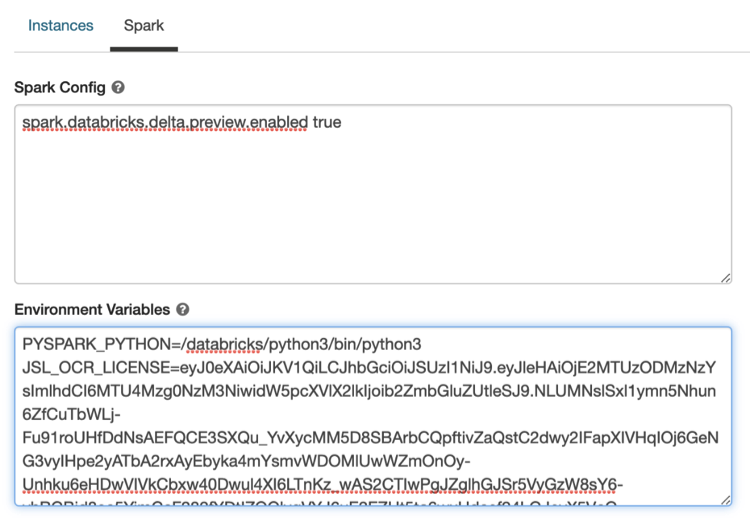 More details you can found on Databricks documentation page related environment variables.
More details you can found on Databricks documentation page related environment variables.
Creating the notebook
In the previous step, we added the Spark OCR jar file and Spark OCR python wheel file libraries to Databricks attached them to your cluster and set the license key.
Now let’s create the Python notebook. The full example you can download here.
First check that’s Spark OCR installed to your cluster. Just try to import Spark OCR transformers:
from sparkocr.transformers import *
It should work fine. Otherwise make sure that you installed properly 2 libraries in the previous step: Spark OCR jar file and Spark OCR python wheel file.
The example notebook has the following sections:
- Data preparation
- Spark OCR Pipeline definition
- Pipeline execution and displaying results
Data preparation
Download and unzip the example image files using following script:
%sh
OCR_DIR=/dbfs/tmp/ocr
if [! -d “$OCR_DIR“]; then
mkdir $OCR_DIR
cd $OCR_DIR
wget https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/ocr/datasets/images.zip
unzip images.zip
fi
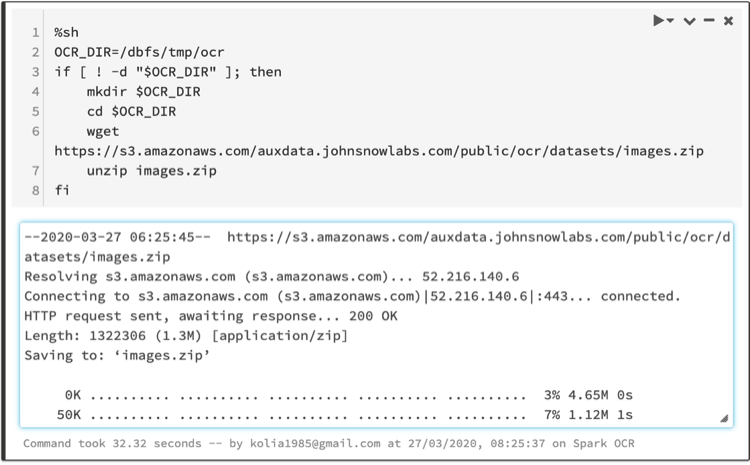
Images located in /dbfs/tmp/ocr/images folder. This dataset contains 18 TIF images.
Let’s display folder using dbutils:
display(dbutils.fs.ls(“dbfs:/tmp/ocr/images/”))
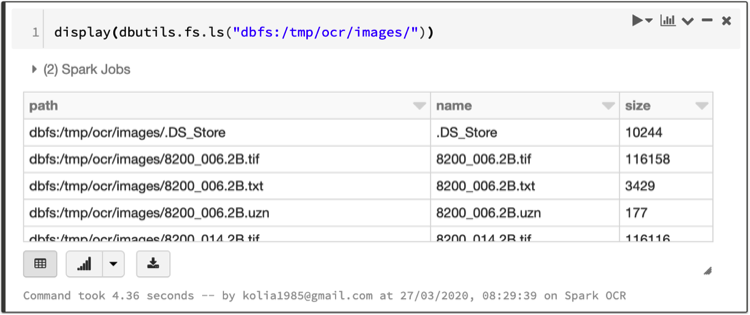
Note: We can’t process here data from S3 directly from public bucket. Databricks has custom implementation of S3 file system for Hadoop. It doesn’t support anonymous credential provider.
Note: From private S3 bucket you could read data directly using following code:
sc._jsc.hadoopConfiguration().set(“fs.s3n.awsAccessKeyId”, ACCESS_KEY)
sc._jsc.hadoopConfiguration().set(“fs.s3n.awsSecretAccessKey”, SECRET_KEY)
imagesPath = “s3a://dev.johnsnowlabs.com/ocr/datasets/news.2B/0/*.tif”
images_example_df = spark.read.format(“binaryFile”).load(imagesPath).cache()
display(images_example_df)
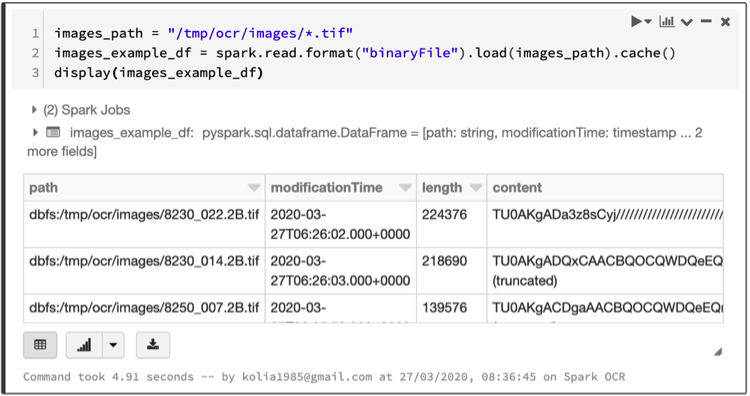
The following is the code to create images DataFrame. It uses read function with `BinaryFormat` parameter as format. (Images folder also contains text files, so for read only `tif` files defined mask: `*.tif`).
images_path = “/tmp/ocr/images/*.tif”
images_example_df = spark.read.format(“binaryFile”).load(images_path).cache()
display(images_example_df)
To preview images from DataFrame use `BinaryToImage` transformer and `display_images` function:
from sparkocr.transformers import BinaryToImage
from sparkocr.databricks import display_images
display_images(BinaryToImage().transform(images_example_df), limit=3)
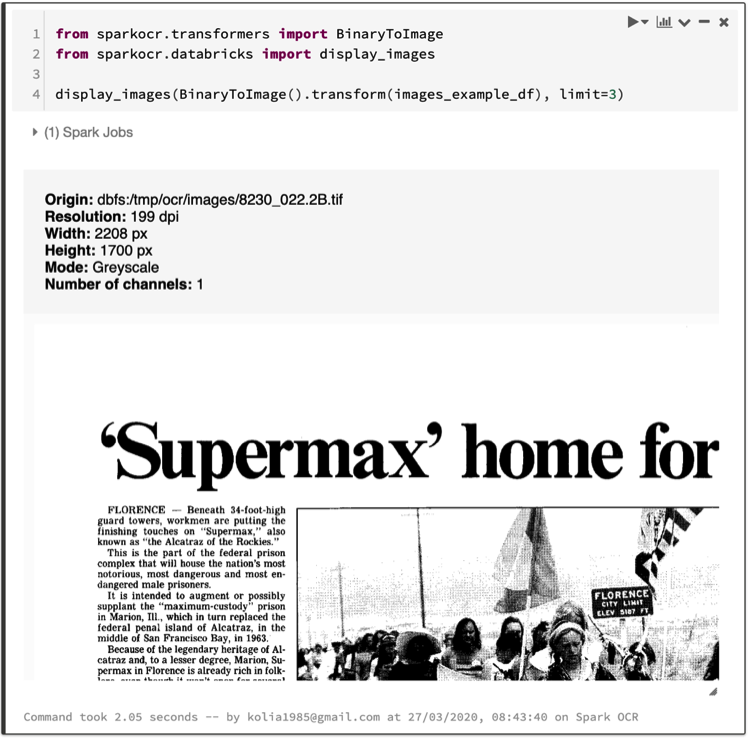
Note: `display_images` is displaying image and the metadata for it.
For DataFrame images representation Spark OCR uses following schema:
image: struct (nullable = true)
| |– origin: string (nullable = true)
| |– height: integer (nullable = false)
| |– width: integer (nullable = false)
| |– nChannels: integer (nullable = false)
| |– mode: integer (nullable = false)
| |– resolution: integer (nullable = true)
| |– data: binary (nullable = true)
More details about the fields could be found in Spark OCR documentation.
Spark OCR pipeline definition
Spark OCR based on Spark ML. So, we need to define transformers and build pipelines.
(More details in Spark ML Pipelines documentation. And here is a list of all available Spark OCR Transformers).
This code defines the Pipeline for recognition text from image. It uses `BinaryToImage` and `ImageToText` transformers:
from sparkocr.transformers import *
from sparkocr.databricks import
from pyspark.ml import PipelineModel
def pipeline():
# Transform binary data to struct image format
binary_to_image = BinaryToImage()
binary_to_image.setInputCol(“content”)
binary_to_image.setOutputCol(“image”)
# Run OCR
ocr = ImageToTex()
ocr.setInputCol(“image”)
ocr.setOutputCol(“text”)
ocr.setConfidenceThreshold(65)
pipeline = PipelineModel(stages=[
binary_to_image,
ocr
])
return pipeline
Pipeline execution and displaying results
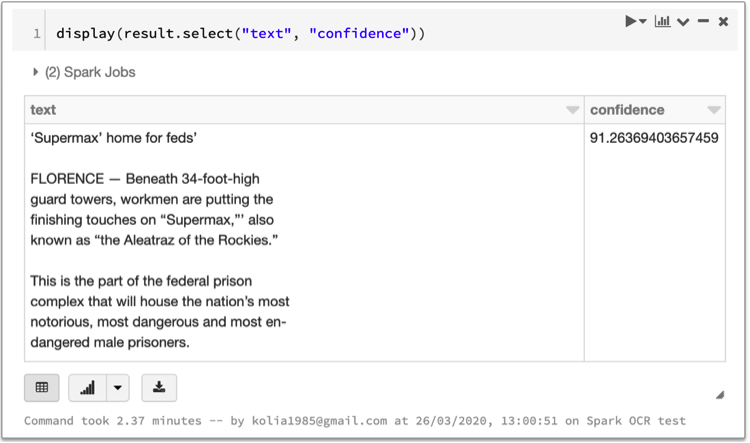
Here is a code for running our pipeline by calling transform method with DataFrame as parameter.
result = pipeline().transform(images_example_df)
display(result.select(“text”, “confidence”))
Note: This operation takes some time for processing 18 images on single node cluster.
Notebook with a full example you can download here.
More examples you can find in Spark OCR workshop repo.
By scaling high-accuracy text extraction from images with Spark OCR on Databricks, healthcare organizations can harness the power of Generative AI in Healthcare to streamline data processing and enable a Healthcare Chatbot to deliver faster, more accurate responses, enhancing patient support and operational efficiency.
Links
- Spark OCR documentation
- Databricks documentation
- Spark ML Pipelines
- Example Spark OCR Databricks Python notebooks
- Example Spark OCR Databricks Scala notebooks
- Jupyter Spark OCR notebooks
- PDF OCR