Spark NLP offers a powerful Python library for scalable text analysis tasks, and its NGramGenerator annotator simplifies n-gram generation. By following best practices, including setting up Spark NLP, loading and preprocessing data, applying the NGramGenerator annotator in a pipeline, and extracting and analyzing the resulting n-grams, users can efficiently process large-scale text data and unlock valuable insights. Spark NLP’s integration with Apache Spark enables distributed computing, making it a valuable tool for modern data analysis needs.

Introduction
Text analysis is a fundamental task in Natural Language Processing (NLP) that involves extracting meaningful insights from textual data. As the volume and complexity of text data continues to grow, efficient and scalable approaches become essential. Spark NLP, a powerful Python library built on Apache Spark, provides a comprehensive framework for processing large-scale text data. In this article, we will explore one of Spark NLP’s key features, the NGramGenerator annotator, which enables the generation of n-grams from text. We will discuss best practices for utilizing the NGramGenerator annotator to efficiently scale up text analysis tasks.
Understanding NGram Generation with Spark NLP
NGram generation involves extracting contiguous sequences of n words from text. It is a valuable technique for capturing context and identifying meaningful phrases in natural language. Spark NLP’s NGramGenerator annotator simplifies the process of generating n-grams by seamlessly integrating with Apache Spark’s distributed computing capabilities.
When processing a sentence, the number of “grams” we use determine the tokenization of the text and the number of tokens generated. See examples in the image below.
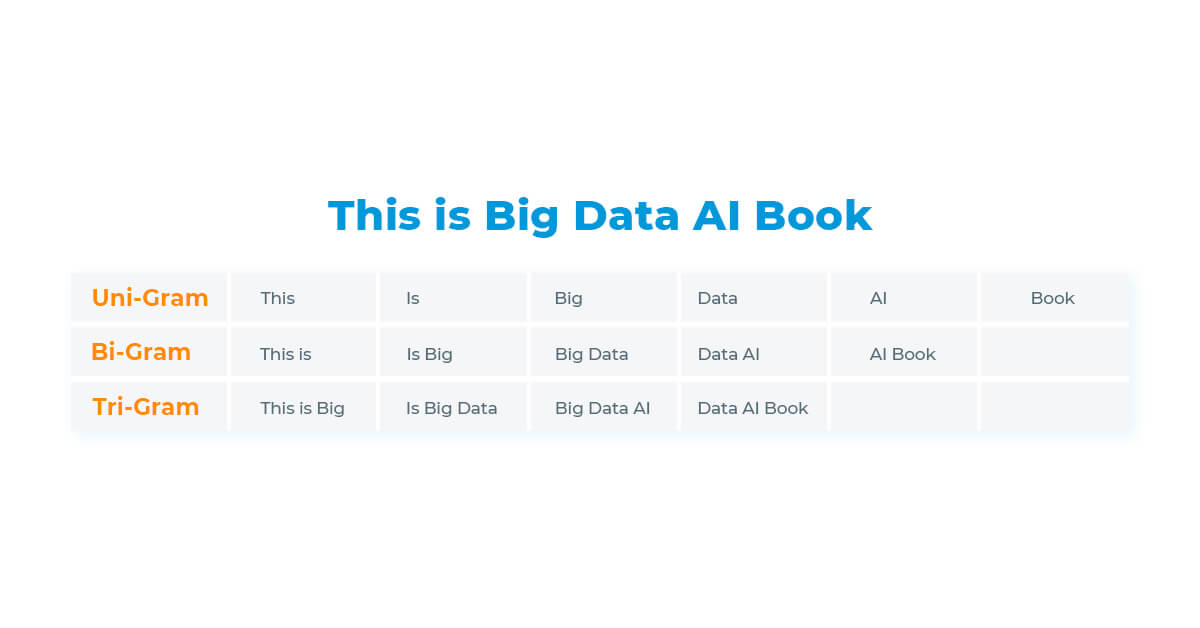
Unigrams, bigrams and trigrams. Source: Mehmood 2019
With Spark NLP’s ability to handle distributed computing, researchers and practitioners can scale up their text analysis tasks and unlock valuable insights from large volumes of text data. By harnessing the power of Spark NLP’s NGramGenerator annotator, text analysis becomes more efficient, accurate, and capable of handling the demands of modern data analysis.
Steps for N-Gram Generation with Spark NLP
To effectively utilize the NGramGenerator annotator in Spark NLP, you can simply follow these steps:
- Setting up Spark NLP
First, ensure that you have Spark NLP installed by using the following command:
pip install spark-nlp
Next, import the required objects and start a spark session:
import sparknlp from sparknlp.annotator import * from sparknlp.common import * from sparknlp.base import * spark = sparknlp.start()
- Loading and Preprocessing Text Data
Load your text data into a Spark DataFrame. Ensure that the text column is named appropriately, such as “text”:
data = [("1", "This is an example sentence."),
("2", "Spark NLP provides powerful text analysis tools.")]
df = spark.createDataFrame(data, ["id", "text"])
- Applying the NGramGenerator Annotator
Initialize the NGramGenerator annotator and specify the input and output columns:
ngram = NGramGenerator().setN(2).setInputCols(["token"]).setOutputCol("ngrams")
In this example, we set the value of “n” to 2, indicating that we want to generate bigrams. Adjust the value of “n” according to your specific requirements.
- Building the Pipeline
Create a pipeline that includes the necessary stages for text preprocessing and n-gram generation:
document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document")
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
pipeline = Pipeline(stages=[document_assembler, tokenizer, ngram])
- Applying the Pipeline to the Data
Fit the pipeline to your data and transform it to obtain the n-gram results:
model = pipeline.fit(df) result = model.transform(df)
The resulting DataFrame will include the n-grams generated from the input text.
- Extracting and Analyzing N-Grams
Extract the n-grams from the transformed DataFrame and perform further analysis or aggregation as needed:
result.select("ngrams.result").show(truncate=False)
+---------------------------------------------------------------------------------------------------+ |result | +---------------------------------------------------------------------------------------------------+ |[This is, is an, an example, example sentence, sentence .] | |[Spark NLP, NLP provides, provides powerful, powerful text, text analysis, analysis tools, tools .]| +---------------------------------------------------------------------------------------------------+
The obtained result has successfully split the text into bigrams. This output now can be used on further NLP analysis tasks such as text classification, sentiment analysis, database indexing, or others.
Conclusion
In the era of big data, scaling up text analysis tasks is paramount for deriving meaningful insights from vast amounts of textual data. Spark NLP, with its integration with Apache Spark, offers a powerful solution for efficiently processing large-scale text data. The NGramGenerator annotator in Spark NLP provides an essential tool for generating n-grams from text, enabling the extraction of contextual information, and identifying meaningful phrases.
By following the best practices outlined in this article, data scientists and NLP practitioners can leverage the NGramGenerator annotator effectively. Setting up Spark NLP, loading and preprocessing text data, applying the NGramGenerator annotator, building a pipeline, and applying it to the data enable seamless n-gram generation. The resulting n-grams can be further analyzed and used for various purposes, such as sentiment analysis, topic modeling, and more.
In summary, Spark NLP, with its NGramGenerator annotator, empowers users to scale up text analysis, extract meaningful n-grams, and gain deeper insights from vast amounts of textual data. By adopting best practices and leveraging the capabilities of Spark NLP, data scientists can unlock the full potential of text analysis and drive innovation in various domains, from social media analytics to customer feedback analysis, and beyond.
References
- Mehmood, Arshad. 2019. “Generate Unigrams Bigrams Trigrams Ngrams Etc In Python.” March 19. Accessed 2019–09–26
- Spark NLP — Annotators