

























































This is the third article of the “Serving Spark NLP via API” series, showcasing how to serve Spark NLP using Databricks Jobs and MLFlow Serve APIs.
Don’t forget to check the other articles in this series, namely:
- How to serve Spark NLP using Microsoft Synapse ML (Part 1/3), available here.
- How to server Spark NLP using FastAPI and LightPipelines (Part 2/3), available here.
Background
Spark NLP is a Natural Language Understanding Library built on top of Apache Spark, leveraging Spark MLLib pipelines, that allows you to run NLP models at scale, including SOTA Transformers. Therefore, it’s the only production-ready NLP platform that allows you to go from a simple PoC on 1 driver node, to scale to multiple nodes in a cluster, to process big amounts of data, in a matter of minutes.
Before starting, if you want to know more about all the advantages of using Spark NLP (as the ability to work at scale on air-gapped environments, for instance) we recommend you to take a look at the following resources:
- John Snow Labs webpage;
- The official technical documentation of Spark NLP;
- Spark NLP channel on Medium;
- Also, follow Veysel Kocaman, Data Scientist Lead and Head of Spark NLP for Healthcare, for the latest tips.
Motivation
Spark NLP is server-agnostic, which means it does not come with an integrated API server but offers a lot of options to serve NLP models using Rest APIs.
There is a wide range of possibilities to add a web server and serve Spark NLP pipelines using RestAPI, and in this series of articles, we are only describing some of them.
Let’s have an overview of how to use Databricks Jobs API and MLFlow Serve as an example for that purpose.
Databricks Jobs and MLFlow Server APIs

About Databricks
Databricks is an enterprise software company founded by the creators of Apache Spark. The company has also created MLflow, the Serialization and Experiment tracking library you can use (inside or outside Databricks), as described in the section “Experiment Tracking”.
Databricks develops a web-based platform for working with Spark, that provides automated cluster management and IPython-style notebooks. Their infrastructure is provided for training and production purposes and is integrated into cloud platforms like Azure and AWS.
Spark NLP is a proud partner of Databricks and we offer seamless integration with them — see Install on Databricks. All Spark NLP capabilities run in Databricks, including MLFlow serialization and Experiment tracking, which can be used for serving Spark NLP for production purposes.
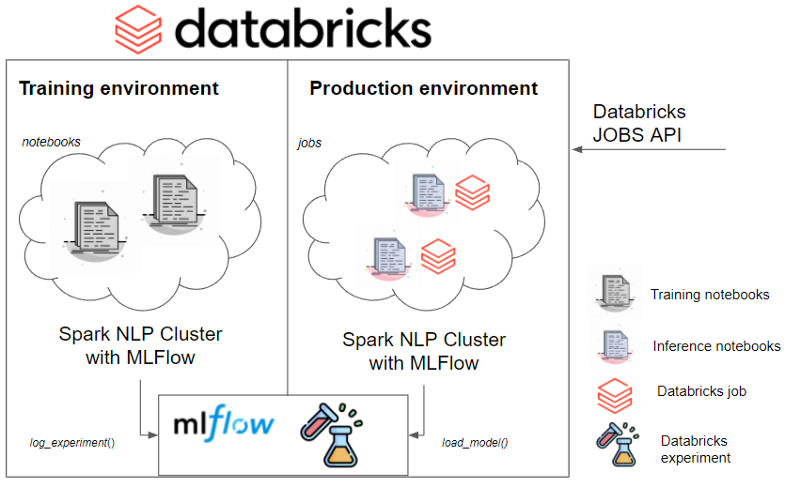
About MLFlow
MLFlow is a serialization and Experiment Tracking platform, which also natively supports Spark NLP. We have a documentation entry about MLFlow in the “Experiment Tracking” section. It’s highly recommended that you take a look before moving forward in this document since we will use some of the concepts explained there.
We will use MLFlow serialization to serve our Spark NLP models.
Strengths
- Easily configurable and scalable clusters in Databricks
- Seamless integration of SPark NLP and Databricks for automatically creating Spark NLP clusters (check to Install on Databricks URL)
- Integration with MLFlow, experiment tracking, etc.
- Configure your training and serving environments separately. Use your serving environment for inference and scale it as you need.
Weaknesses
- This approach does not allow you to customize your endpoints, it uses Databricks JOBS API ones
- Requires some time and expertise in Databricks to configure everything properly
Creating a cluster in Databricks
As mentioned before, Spark NLP offers seamless integration with Databricks. To create a cluster, please follow the instructions in Install on Databricks.
That cluster can be then replicated (cloned) for production purposes later on.
Configuring Databricks for serving Spark NLP on MLFlow
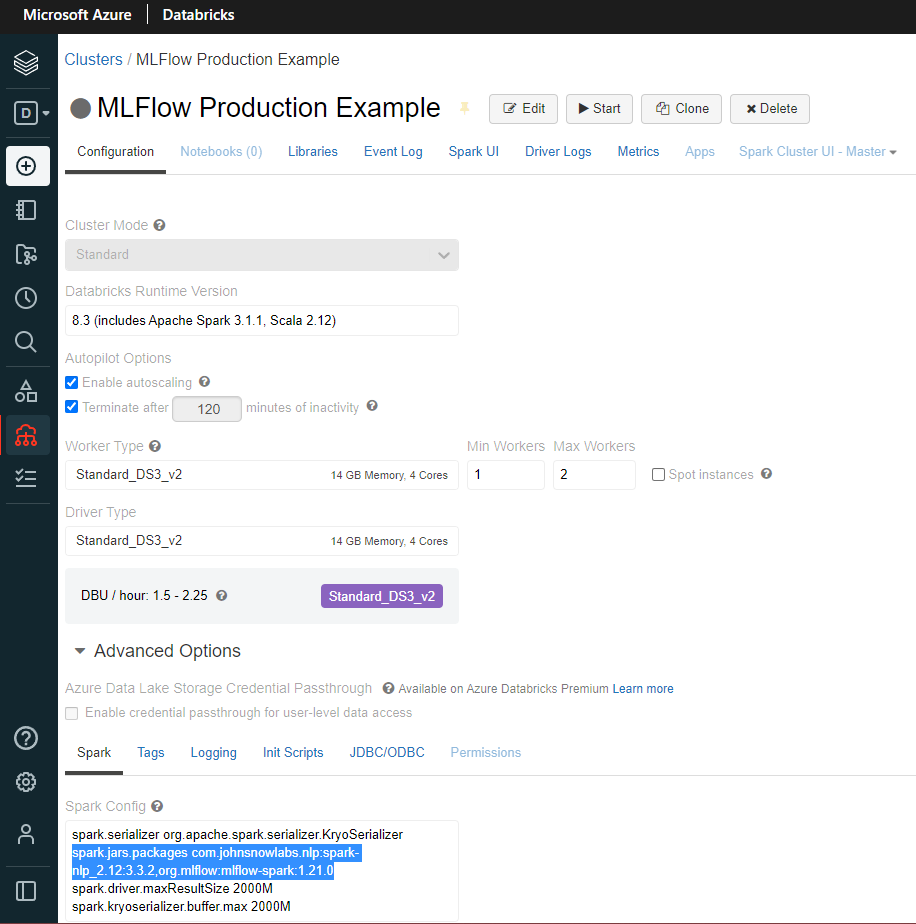
In Databricks Runtime Version, select any Standard runtime, not ML ones. These ones add their version of MLFlow, and some incompatibilities may arise. For this example, we have used 8.3 (includes Apache Spark 3.1.1, Scala 2.12)
The cluster instantiated is prepared to use Spark NLP, but to make it production-ready using MLFlow, we need to add the MLFlow jar, in addition to the Spark NLP jar, as shown in the “Experiment Tracking” section.
In that case, we did it instantiating adding both jars (“spark.jars.packages”:” com.johnsnowlabs.nlp:spark-nlp_2.12:3.3.2,org.mlflow:mlflow-spark:1.21.0″) into the SparkSession. However, in Databricks, you don’t instantiate programatically a session, but you configure it in the Compute screen, selecting your Spark NLP cluster, and then going to Configuration -> Advanced Options -> Sparl -> Spark Config, as shown in the following image:
In addition to Spark Config, we need to add the Spark NLP and MLFlow libraries to the Cluster. You can do that by going to Libraries inside your cluster. Make sure you have spark-nlp and mlflow. If not, you can install them either using PyPI or Maven artifacts. In the image below you can see the PyPI alternative:
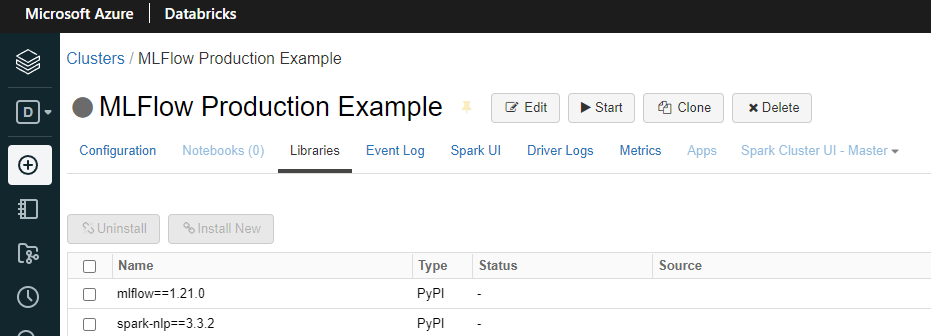
TIP: You can also use the Libraries section to add the jars (using Maven Coordinates) instead of setting them in the Spark Config, as shown before.
Creating a notebook
You are ready to create a notebook in Databricks and attach it to the recently created cluster. To do that, go to Create – Notebook, and select the cluster you want in the dropdown above your notebook. Make sure you have selected the cluster with the right Spark NLP + MLFlow configuration.
To check everything is ok, run the following lines:
- To check the session is running:spark
- To check jars are in the session:spark.sparkContext.getConf().get(‘spark.jars.packages’)
You should see the following output from the last line (versions may differ depending on which ones you used to configure your cluster)
Out[2]: 'com.johnsnowlabs.nlp:spark-nlp_2.12:3.3.2,org.mlflow:mlflow-spark:1.21.0'
Logging the experiment in Databricks using MLFlow
As explained in the “Experiment Tracking” section, MLFlow can log Spark MLLib / NLP Pipelines as experiments, to carry out runs on them, track versions, etc.
MLFlow is natively integrated into Databricks, so we can leverage the mlflow.spark.log_model() function of the Spark flavor of MLFlow, to start tracking our Spark NLP pipelines.
Let’s first import our libraries:
import mlflow import sparknlp from sparknlp.base import * from sparknlp.annotator import * from pyspark.ml import Pipeline import pandas as pd from sparknlp.training import CoNLL import pyspark from pyspark.sql import SparkSession
Then, create a Lemmatization pipeline:
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
lemmatizer = LemmatizerModel.pretrained() \
.setInputCols(["token"]) \
.setOutputCol("prediction") # It's mandatory to call it prediction
pipeline = Pipeline(stages=[
documentAssembler,
tokenizer,
lemmatizer
])
IMPORTANT: Last output column of the last component in the pipeline should be called prediction.
Finally, let’s log the experiment. In the “Experiment Tracking” section, we used the pip_requirements parameter in the log_model() function to set the required libraries:
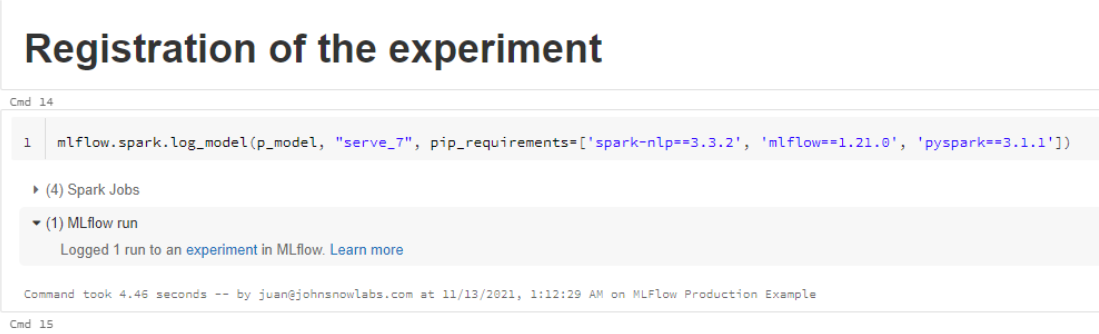
But we mentioned using conda is also available. Let’s use conda in this example:
conda_env = {
'channels': ['conda-forge'],
'dependencies': [
'python=3.8.8',
{
"pip": [
'pyspark==3.1.1',
'mlflow==1.21.0',
'spark-nlp==[YOUR_SPARKNLP_VERSION]'
]
}
],
'name': 'mlflow-env'
}
With this conda environment, we are ready to log our pipeline:
mlflow.spark.log_model(p_model, "lemmatizer", conda_env=conda_env)
You should see an output similar to this one:
(6) Spark Jobs (1) MLflow run *Logged 1 run to an experiment in MLflow. Learn more*
Experiment UI
On the top right corner of your notebook, you will see the Experiment widget, and inside, as shown in the image below.
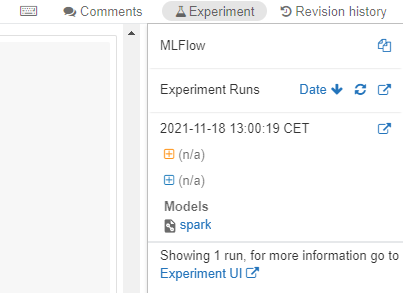
You can also access Experiments UI if you switch your environment from “Data Science & Engineering” to “Machine Learning”, on the left panel…
Once in the experiment UI, you will see the following screen, where your experiments are tracked.
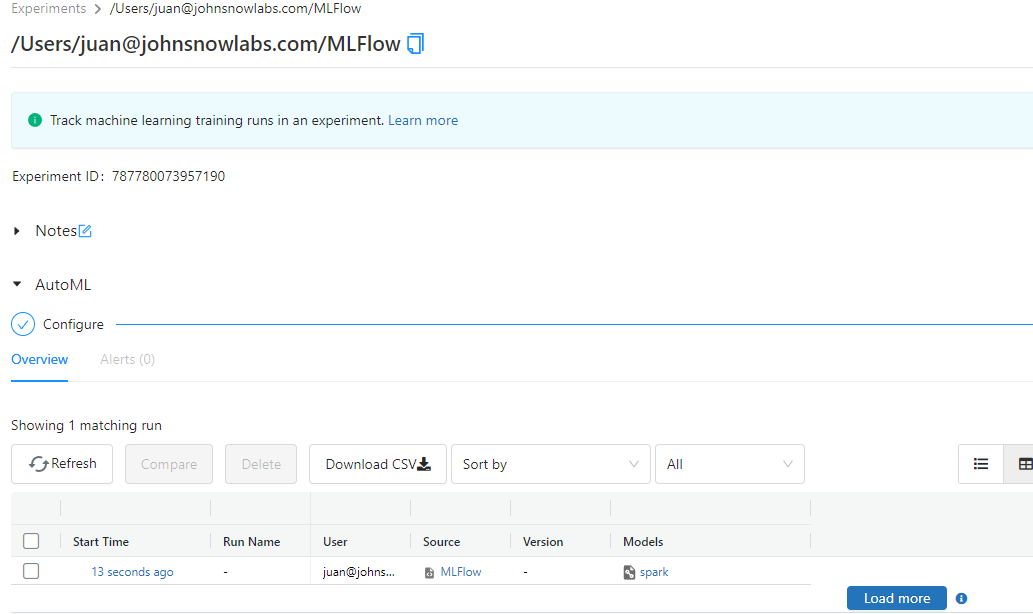
If you click on the Start Time cell of your experiment, you will reach the registered MLFlow run.
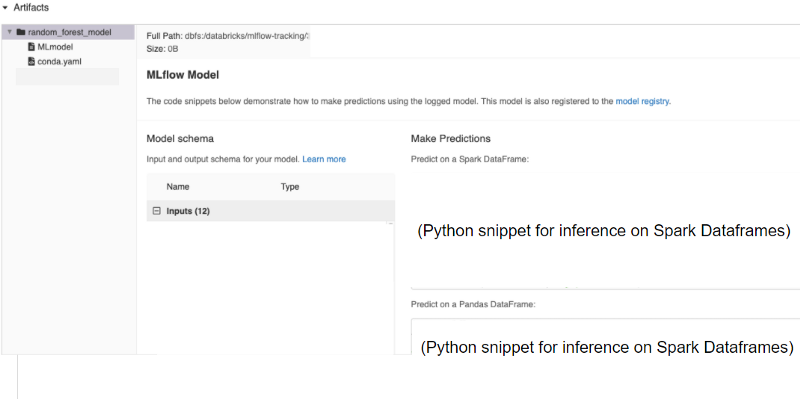
On the left panel, you will see the MLFlow model and some other artifacts, such as the conda.yml and pip_requirements.txt that manage the dependencies of your models.
On the right panel, you will see two snippets, about how to call to the model for inference internally from Databricks.
Snippet for calling with a Pandas Dataframe:
import mlflow logged_model = 'runs:/a8cf070528564792bbf66d82211db0a0/lemmatizer'
Load model as a Spark UDF.
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model)
Predict on a Spark DataFrame.
columns = list(df.columns) df.withColumn('predictions', loaded_model(*columns)).collect()
Snippet for calling with a Spark Dataframe. We won’t include it in this documentation because that snippet does not include SPark NLP specificities. To make it work, the correct snippet should be:
import mlflow logged_model = 'runs:/a8cf070528564792bbf66d82211db0a0/lemmatizer' loaded_model = mlflow.pyfunc.load_model(model_uri=logged_model)
Predict on a Spark DataFrame.
res_spark = loaded_model.predict(df_1_spark.rdd)
IMPORTANT: You will only get the last column (prediction) results, which is a list of Rows of Annotation Types. To convert the result list into a Spark Dataframe, use the following schema:
import pyspark.sql.types as T
import pyspark.sql.functions as f
annotationType = T.StructType([
T.StructField('annotatorType', T.StringType(), False),
T.StructField('begin', T.IntegerType(), False),
T.StructField('end', T.IntegerType(), False),
T.StructField('result', T.StringType(), False),
T.StructField('metadata', T.MapType(T.StringType(), T.StringType()), False),
T.StructField('embeddings', T.ArrayType(T.FloatType()), False)
])
And then, get the results (for example, in res_spark) and apply the schema:
spark_res = spark.createDataFrame(res_pandas[0], schema=annotationType)
Calling the experiment for production purposes using MLFlow Rest API
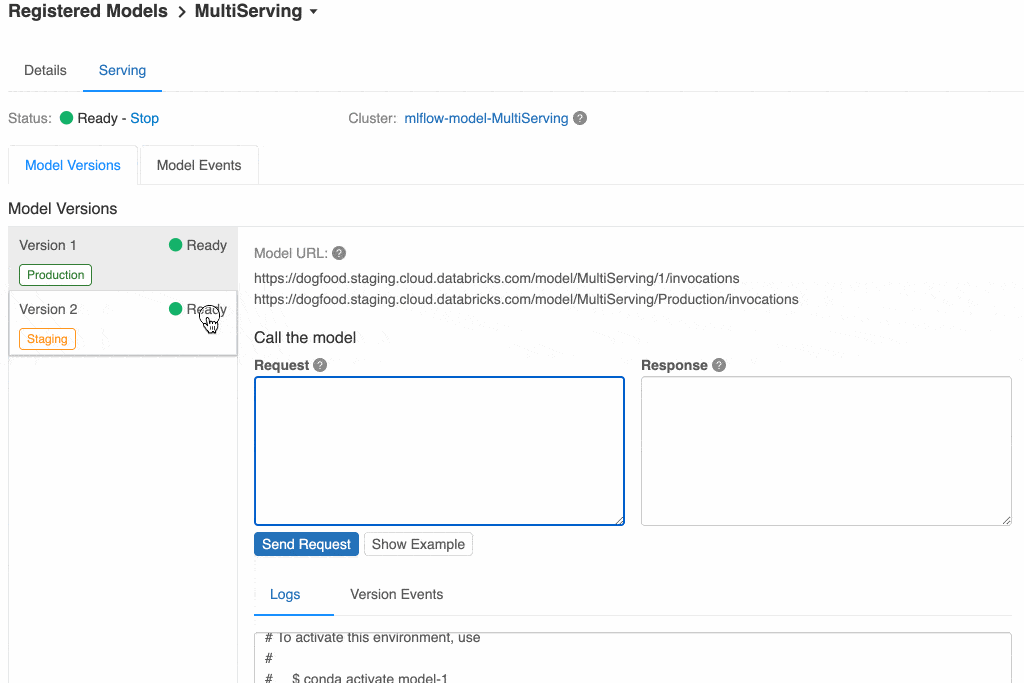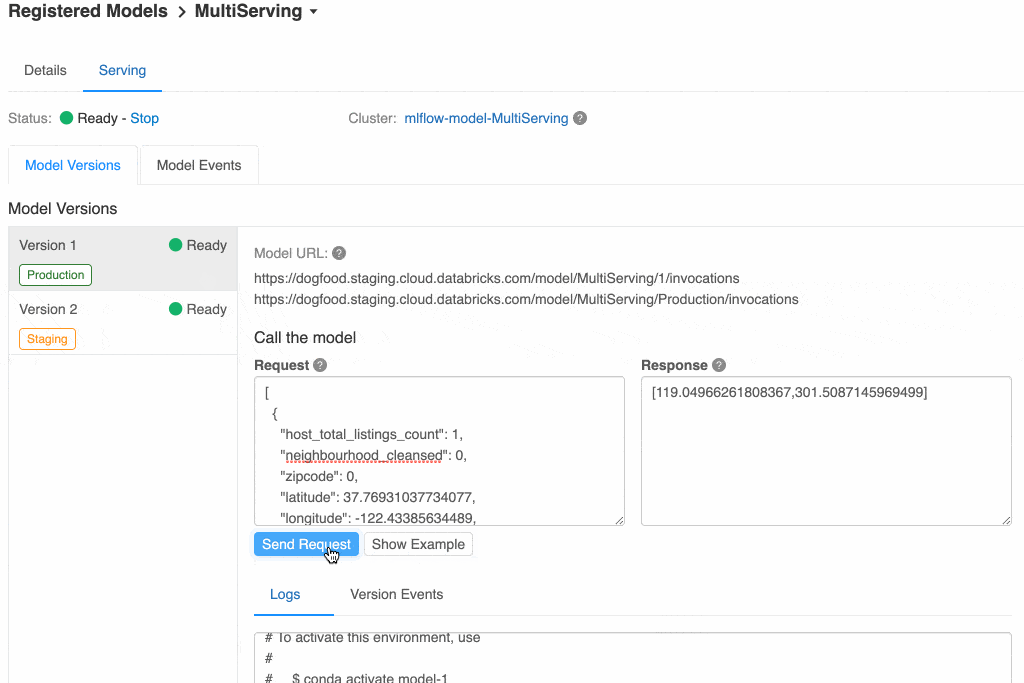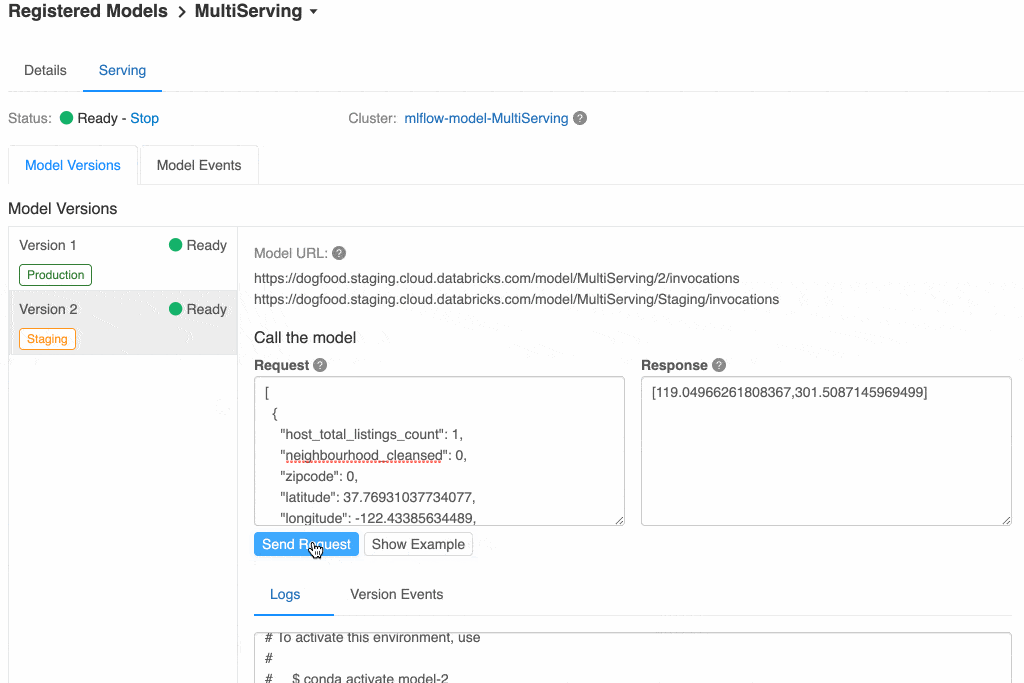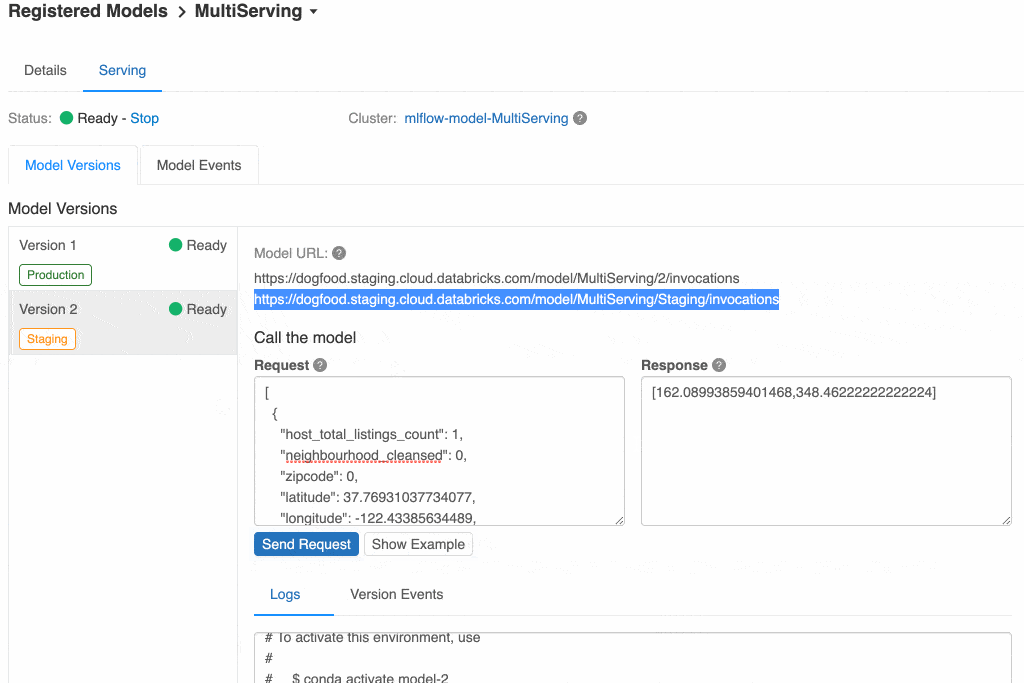
Instead of choosing a Batch Inference, you can select REST API. This will lead you to another screen when the model will be loaded for production purposes in an independent cluster. Once deployed, you will be able to:
- Check the endpoint URL to consume the model externally;
- Test the endpoint writing a json (in our example, ‘text’ is our first input col of the pipeline, so it should look similar
{"text": "This is a test of how the lemmatizer works"}
You can see the response on the same screen.
- Check what is the Python code or cURL command to do that very same thing programmatically.
By just using that Python code, you can already consume it for production purposes from any external web app.
IMPORTANT: As of 17/02/2022, there is an issue being studied by the Databricks team, regarding the creation on the fly of job clusters to serve MLFlow models that require configuring the Spark Session with specific jars. This will be fixed in later versions of Databricks. In the meantime, the way to go is using Databricks Jobs API.
Calling the experiment for production purposes using Databricks Asynchronous Jobs API
Creating the notebook for the inference job
And last, but not least, another approach to consuming models for production purposes. the Jobs API.
Databricks has its own API for managing jobs, that allows you to instantiate any notebook or script as a job, run it, stop it, and manage all the life cycle. And you can configure the cluster where this job will run beforehand, which prevents having the issue described in point 3.
To do that:
- Create a new production cluster, as described before, cloning your training environment but adapting it to your needs for production purposes. Make sure the Spark Config is right, as described at the beginning of this documentation.
- Create a new notebook. Always check that the jars are in the session:
spark.sparkContext.getConf().get('spark.jars.packages')Out[2]: 'com.johnsnowlabs.nlp:spark-nlp_2.12:[YOUR_SPARKNLP_VERSION],org.mlflow:mlflow-spark:1.21.0'
- Add the Spark NLP imports.
import mlflow import sparknlp from sparknlp.base import * from sparknlp.annotator import * from pyspark.ml import Pipeline import pandas as pd from sparknlp.training import CoNLL import pyspark from pyspark.sql import SparkSession import pyspark.sql.types as T import pyspark.sql.functions as f import json - Let’s define that an input param called text will be sent in the request. Let’s get the text from that parameter using dbutils.
input = "" try: input = dbutils.widgets.get("text") print('"text" input found: ' + input) except: print('Unable to run: dbutils.widgets.get("text"). Setting it to NOT_SET') input = "NOT_SET"
Right now, the input text will be in input var. You can trigger an exception or set the input to some default value if the parameter does not come in the request.
- Let’s create a Spark Dataframe with the input
df = spark.createDataFrame([[input]]).toDF('text') - And now, we just need to use the snippet for Spark Dataframe to consume MLFlow models, described above:
import mlflow import pyspark.sql.types as T import pyspark.sql.functions as f logged_model = 'runs:/a8cf070528564792bbf66d82211db0a0/lemmatizer' loaded_model = mlflow.pyfunc.load_model(model_uri=logged_model)
Predict on a Spark DataFrame.
res_spark = loaded_model.predict(df_1_spark.rdd)
annotationType = T.StructType([
T.StructField('annotatorType', T.StringType(), False),
T.StructField('begin', T.IntegerType(), False),
T.StructField('end', T.IntegerType(), False),
T.StructField('result', T.StringType(), False),
T.StructField('metadata', T.MapType(T.StringType(), T.StringType()), False),
T.StructField('embeddings', T.ArrayType(T.FloatType()), False)
])
spark_res = spark.createDataFrame(res_spark[0], schema=annotationType)
- Let’s transform our lemmatized tokens from the Dataframe into a list of strings:
lemmas = spark_res.select("result").collect() txt_results = [x['result'] for x in lemmas] - And finally, let’s use again dbutils to tell Databricks to spin off the run and return an exit parameter: the list of token strings.
dbutils.notebook.exit(json.dumps({ "status": "OK", "results": txt_results }))
Configuring the job
Last, but not least. We need to recreate the job so that we run it from the API. We could do that using the API as well, but we will show you how to do it using the UI.
On the left panel, go to Jobs and then Create Job.
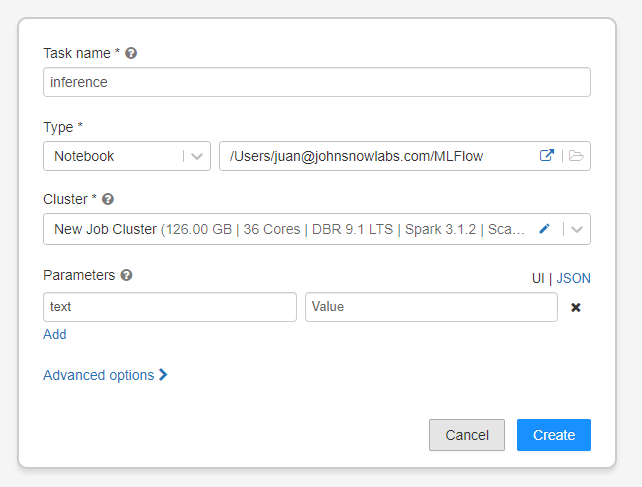
In the jobs screen, you will see your job created. It’s not running, it’s prepared to be called on-demand, programmatically or in the interface, with a text input param. Let’s see how to do that:
Running the job
- In the jobs screen, if you click on the job, you will enter the Job screen, and be able to set your text input parameter and run the job manually.
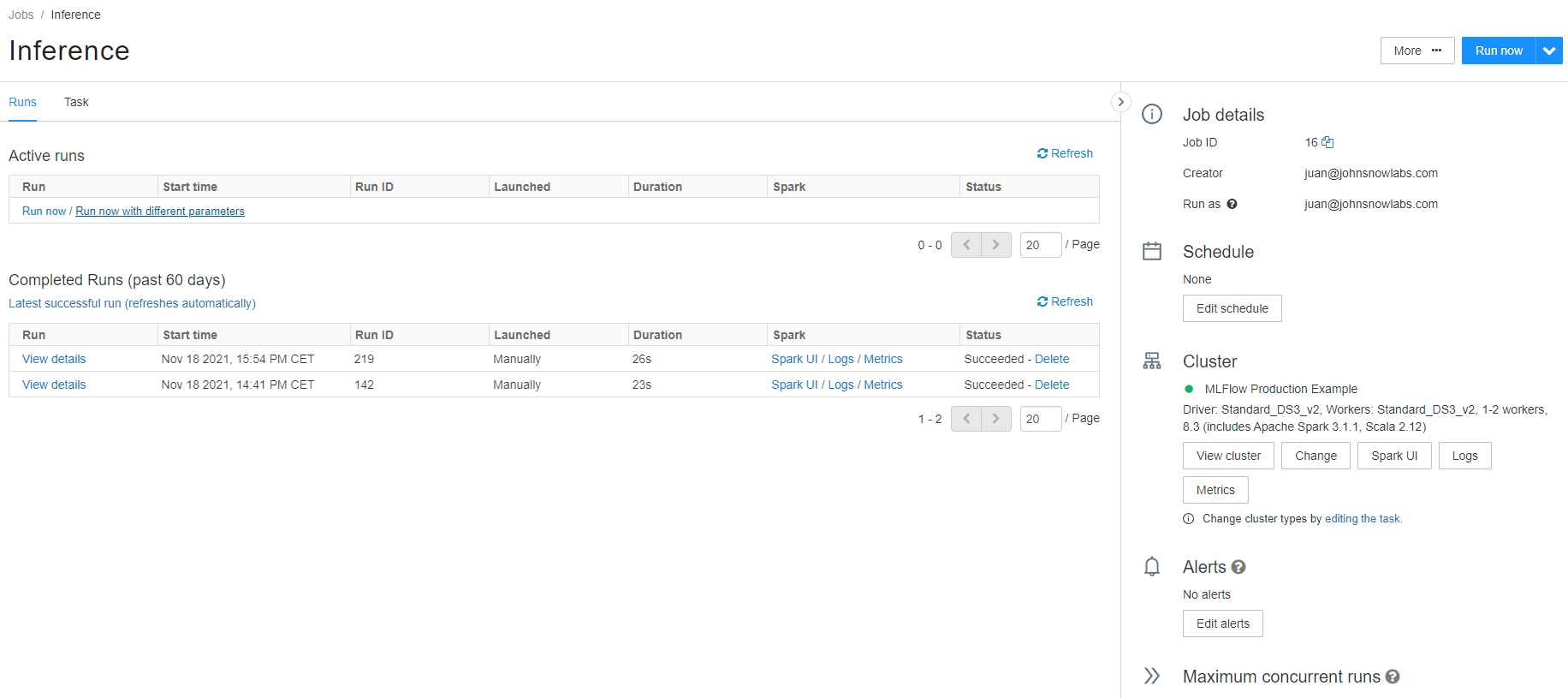
You can use this for testing purposes, but the interesting part is calling it externally, using the Databricks Jobs API.
- Using the Databricks Jobs API, from, for example, Postman.
POST HTTP request
URL: https://[your_databricks_instance]/api/2.1/jobs/run-now
Authorization: [use Bearer Token. You can get it from Databricks, Settings, User Settings, Generate New Token.]
Body:
{
"job_id": [job_id, check it in the Jobs screen],
"notebook_params": {"text": "This is an example of how well the lemmatizer works"}
}
As it’s an asynchronous call, it will return the number number of runs, but no results. You will need to query for results using the number of the run and the following URL https://[your_databricks_instance]/2.1/jobs/runs/get-output
You will get a big json, but the most relevant info, the output, will be up to the end:
Results (list of lemmatized words)
{"notebook_output": {
"status": "OK",
"results": ["This", "is", "a", "example", "of", "how", "lemmatizer", "work"]
}}
The notebook will be prepared in the job, but idle, until you call it programmatically, which will instantiate a run.
Check the Jobs API for more information about what you can do with it and how to adapt it to your solutions for production purposes.
Do you want to know more?
- Check how to production Spark NLP in our official documentation here
- Visit John Snow Labs and Spark NLP Technical Documentation websites
- Follow us on Medium: Spark NLP and Veysel Kocaman
- Write to support@johnsnowlabs.com for any additional request you may have




