Spark NLP 3.0 is here, combining a set of major under-the-hood optimizations and upgrades that give the open-source community the most scalable and most tightly optimized NLP library ever.
This release went through intensive testing and profiling across all the platforms we support, which includes their latest versions. Spark NLP 3 is officially supported on:
- Spark 3.1, 3.0, 2.4, and 2.3
- Databricks 6.x, 7.x, 8.x – both CPU and ML GPU
- Linux, MacOS, and Windows – for local development
- Docker – with and without Kubernetes
- Hadoop 2.7.x and 3.x
- AWS EMR 5.x and 6.x
- Cloudera & Hortonworks
- AWS, Azure, and GCP
Spark NLP is most widely used in Python (often with Jupyter, Zeppelin, PyCharm, or SageMaker) but as always there is a complete & supported API in Scala and Java.
Beyond newly supported platforms, the big news for this release is a leap in the library’s speed – with a focus on the most common NLP tasks. As an example, here is an apples-to-applies comparison on running Spark NLP 3.0 versus the previous version (2.7), on 120,000 documents from AG’s corpus of news articles, which together have more than 4 million tokens. The benchmark was run on Databricks 7.3 LST ML using GPU’s with 10x AWS workers (g4dn.2xlarge) and the new version is:
- 7.9 times faster in calculating BERT-Large
- 6.5 times faster in calculating BERT-base
- 3.0 times faster in calculating named entity recognition
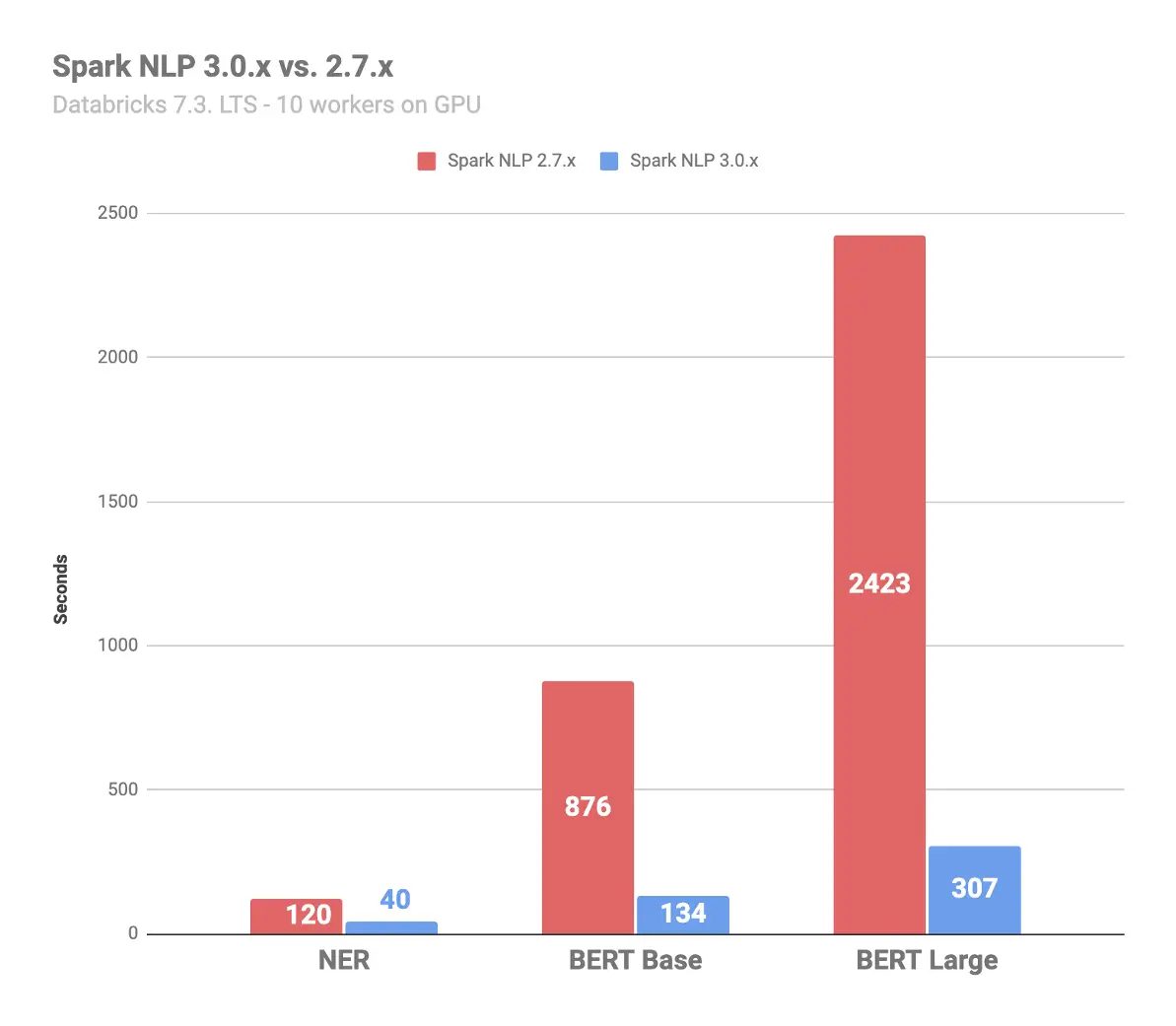 Runtime in Seconds – Lower is Better
Runtime in Seconds – Lower is Better
Spark NLP 3 will get you much faster results whether you’re running locally or in a cluster, using a CPU or GPU. We’ve spent several months diving deep into the bowels of optimizing neural networks, multi-threading, in-memory vs. on-chip computation, distributed execution planning, and compiler optimization of modern deep learning libraries & compute platforms. We would like to thank the teams at Databricks (Spark & MLflow), Google (TensorFlow), Intel (MKL), and Nvidia (Spark & Rapids) for supporting us through this journey.
As another example of the cumulative benefit of the dozens of optimizations that were added, here is the difference in number of words per seconds for running named entity recognition – one of the most common NLP tasks in practice – that Spark NLP 3.0 can process versus Spark NLP 2.7. This benchmark was run on the same 120,000 news articles from the AG corpus, on 10 AWS g4dn.2xlarge instances on Databricks 7.3 LST ML. It shows:
- 2.9 times throughput on CPU
- 3.0 times throughput on GPU
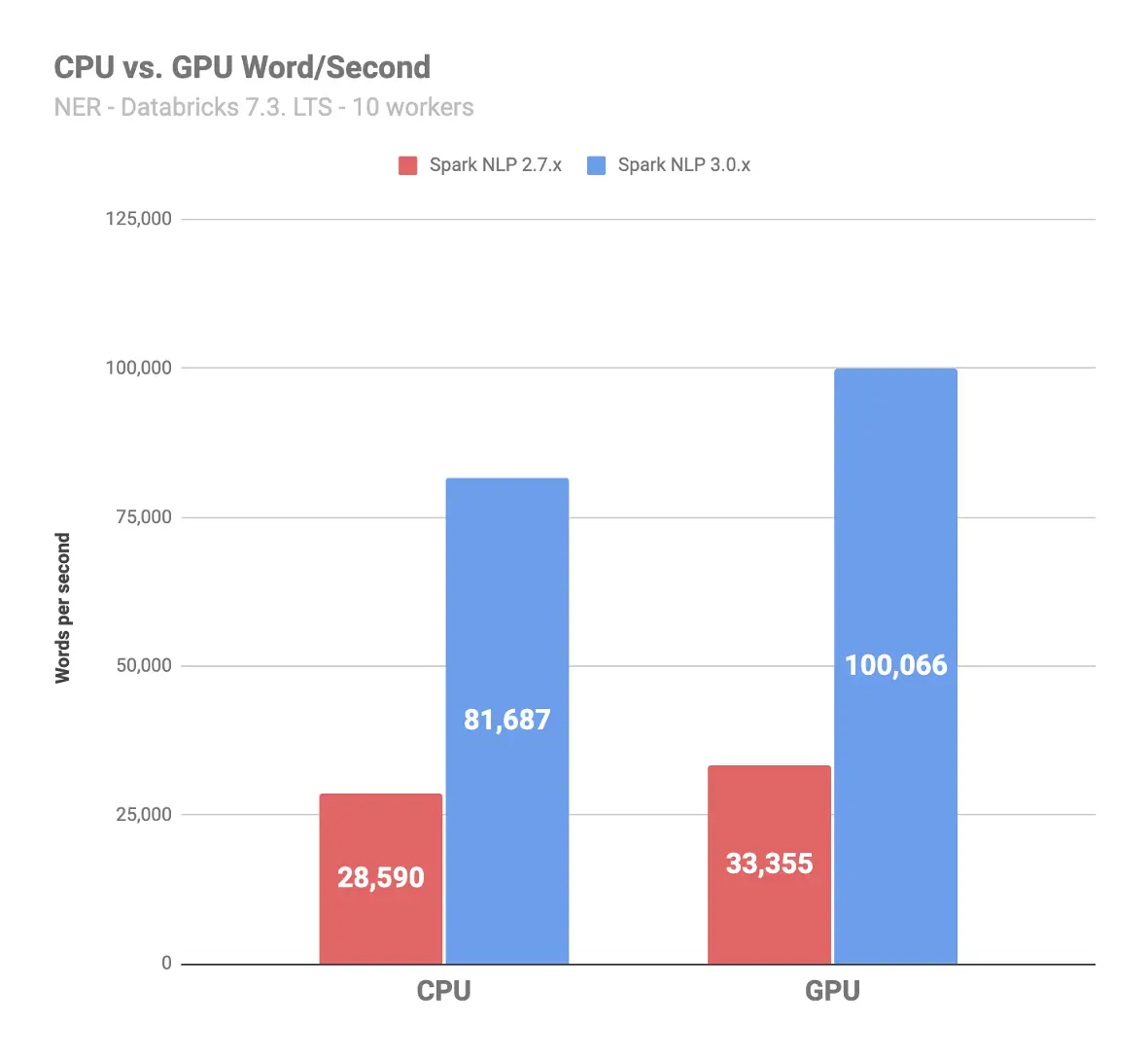 Words per Seconds – Higher is Better
Words per Seconds – Higher is Better
Spark NLP 3 is open source under the Apache 2.0 license – so 100% free for personal and commercial use. To get started and learn more, get to:
Please put it to good use!