























































Spark NLP For Finance 1.0.0: New state-of-the-art models in multiple languages!
Overview
Our team at John Snow Labs has great combined experience bringing leading NLP library to market and supporting our clients. 50% of the BIFS (Business, Insurance, Financial Services) use Spark NLP in Production. Downloaded more than 25 million times and experiencing 10x growth over the last year, Spark NLP is used by 41% of healthcare organizations as the world’s most widely used NLP library in the enterprise

Spark NLP in Industry
It was time to transfer our experience in the field of healthcare to the NLP for financial services. While doing this, we carried out a meticulous study by considering the sector’s expectations.

And, we are delighted to announce Spark NLP For Finance with new state-of-the-art models available in multiple languages. This is an addition to the Spark NLP ecosystem, Including the Open Source core ( Spark NLP ), Spark NLP for Healthcare, and Spark NLP for Legal. We are so proud to share this with our community!
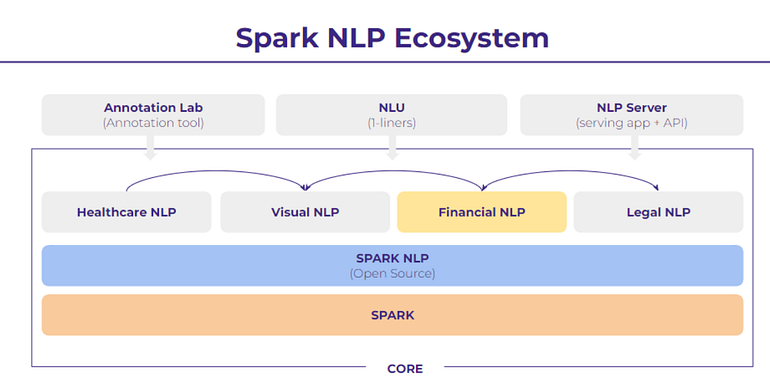
Spark NLP For Finance works on top of Spark NLP, which means it is also scalable to clusters and includes State-of-the-Art Transformer Architectures and models to achieve the best performance on Financial documents.
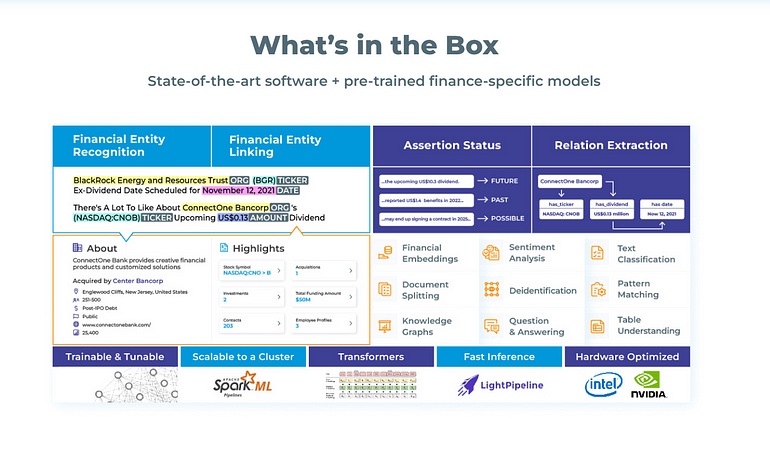
Spark NLP for Financial Overview
Major features
Spark NLP for Finance, as well as Spark NLP for Healthcare and Legal, is based on 4 main pillars:
- Financial Named Entity Recognition: including models for extracting organizations, products, revenue, profit, losses, trading symbols, SEC 10-K information, and much more.
- Entity-linking: to normalize NER entities and link them to public databases/data sources, such as Edgar, Crunchbase, and Nasdaq. By doing that, you can augment Company Names, for example, with externally available data about them.
- Assertion Status: to infer temporality (present, past, future), probability (possible), or other conditions in the context of the extracted entities
- Relation Extraction: to infer relations between the extracted entities. For example, the relations of the parties in an agreement.
You can carry out many more NLP Tasks, such as:
- Financial Embeddings: The result is an n-dimensional embedding matrix, impossible to process by the human eye, containing the interpretation of the text using a financial domain.
- Question Answering: Financial Question Answering model, finetuned on proprietary Financial questions and answers.
- Text Classification: to classify texts into specific financial categories.
- Document Splitting: Split your long documents at paragraph or sentence level, or use NER to detect sections and then split by them at the section level.
- Sentiment Analysis: to identify positive, negative, or neutral sentiments in financial news.
- Pattern Matching: Use context-aware symbolic components to model patterns to combine with Deep Learning information extraction techniques.
- Knowledge Graphs: Create Knowledge bases combining entities and relations in a graph, which can be exploited afterward in graph databases.
- Deidentification: The task of detecting privacy-related entities in text, such as person names, emails, and contact data.
- Table Understanding: Use State-of-the-Art Deep Learning architectures to query tables (extracted, for example, with Spark OCR) with Natural Language. No training is needed.
- Zero-shot Learning: Spark NLP for Finance includes Zero-shot NER and Zero-shot Relation Extraction, to create your information extraction models without any training data, just with examples (prompts).
Models and Demos
New Models
Models for the following tasks are available in Spark NLP For Finance:
Financial Named Entity Recognition, Text Classification, Image Classification, Sentiment Analysis, Question Answering, Chunk Mapping, Relation Extraction, Assertion Status, Entity Resolution, De-identification.
We also provide information such as the metrics, benchmarks and the code snippet for each model inside the page pre trained nlp models for banking and finance to download the model.
New Demos
We have prepared a new section on our Demo site, where you will find demos, showcasing some of the models available in Models Hub.
This is a showcase of one example for each category:
- Classify Financial Documents — >Demo to Classify multilabel documents for financial news categories: https://demo.johnsnowlabs.com/finance/CLASSIFICATION_MULTILABEL/
- Recognize Financial Entities — >Demo to Extract financial entities from Documents: https://demo.johnsnowlabs.com/finance/FINNER_FINANCIAL_10K/
- Understand Entities in Context — >Demo to Infer temporality from the temporal context of the entities, as. https://demo.johnsnowlabs.com/finance/FINASSERTION_TEMPORALITY/
- Extract Financial Relationships — >Demo to Extract relations between People, their present and past working places, and roles: https://demo.johnsnowlabs.com/finance/FINRE_EXPERIENCES/
- Normalization & Data Augmentation — >Demo to Normalize and Augment Company Names using SEC Edgar database: https://demo.johnsnowlabs.com/finance/FIN_LEG_COMPANY_AUGMENTATION
- Financial Deidentification — >Demo to Deidentify sensitive financial information. (Masking and obfuscation): https://demo.johnsnowlabs.com/finance/DEID_FIN/
- Financial Document Splitting — >Demo to Detect potential headers and subheaders in Financial Documents: https://demo.johnsnowlabs.com/finance/FINNER_HEADERS/
Documentation
- Visit: www.johnsnowlabs.com/finance-nlp/
- Contact us at support@johnsnowlabs.com
- Read our blog: Finance NLP blog




