























































O’Reilly survey of 1,300 enterprise practitioners ranks Spark NLP as the most widely used AI library in the enterprise after TensorFlow, scikit-learn, keras, and PyTorch.
NLP Adoption in the Enterprise
The annual O’Reilly report on AI Adoption in the Enterprise was released in February 2019. It is a survey of 1,300 practitioners in multiple industry verticals, which asked respondents about revenue-bearing AI projects their organizations have in production. It’s a fantastic analysis of how AI is really used by companies today – and how that use is quickly expanding into deep learning, human in the loop, knowledge graphs, and reinforcement learning.
The survey asks respondents to list all the ML or AI frameworks and tools which they use. This is the summary of the answers:
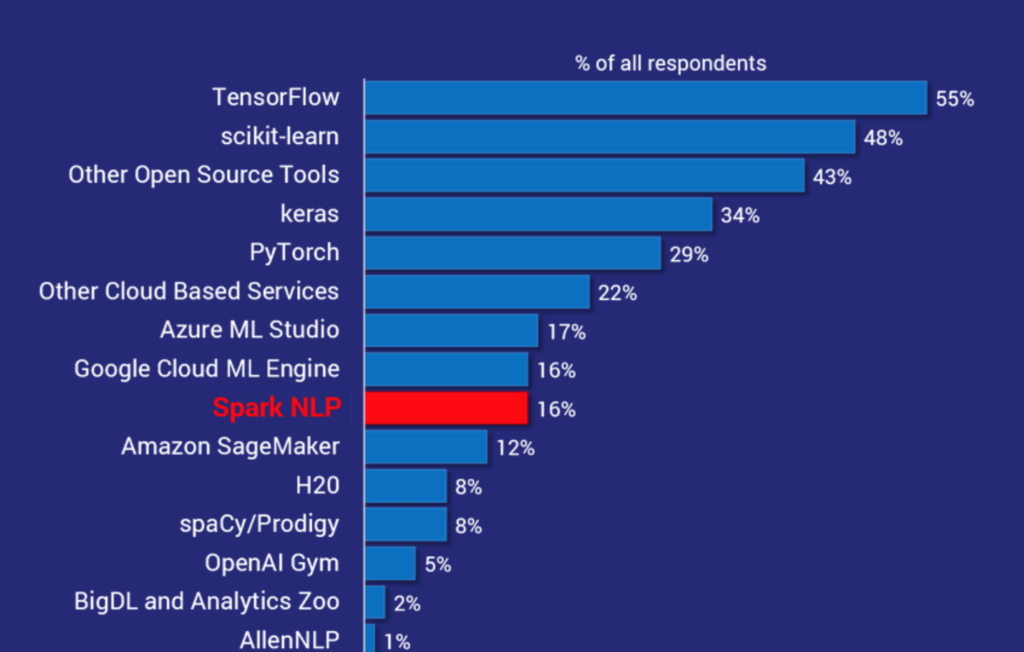
”AI Adoption in the Enterprise”, O’Reilly Media, February 2019 – Most widely used ML frameworks and tools survey of 1,300 practitioners
The 18-month-old Spark NLP library is the 7thmost popular across all AI frameworks and tools (note the “other open source tools” and “other cloud services” buckets). It is also by far the most widely used NLP library – twice as common as spaCy. In fact, it is the most popular AI library in this survey following scikit-learn, TensorFlow, keras, and PyTorch.
State-of-the-art Accuracy, Speed, and Scalability
This survey is in line with the uptick in adoption we’ve experienced in the past year, and the public case studies on using Spark NLP successfully in healthcare, finance, life science, and government. The root causes for this rapid adoption lie in the major shift in state-of-the-art NLP that happened in recent years.
Accuracy
The rise of deep learning for natural language processing in the past 3-5 years meant that the algorithms implemented in popular libraries like spaCy, Stanford CoreNLP, nltk, and OpenNLP are less accurate than what the latest scientific papers made possible.
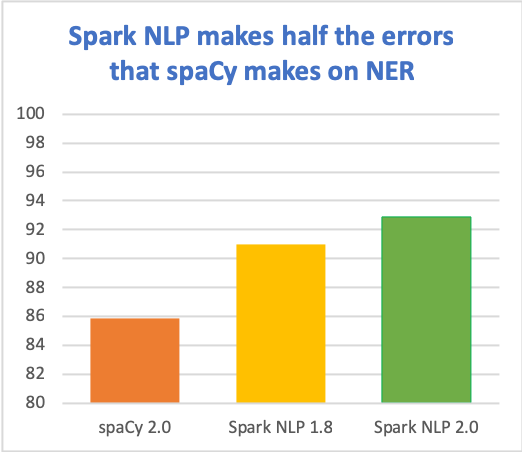
Claiming to deliver state-of-the-art accuracy & speed has us constantly on the hunt to productize the latest scientific advances (yes, it is as fun as it sounds!). Here’s how we’re doing so far (on the en_core_web_lg benchmark, micro-averaged F1 score):
Speed
Optimizations done to get Apache Spark’s performance closer to bare metal, on both single machine and on a cluster, meant that common NLP pipelines could run orders of magnitude faster than what the inherent design limitations of legacy libraries allowed.
The most comprehensive benchmark to date, Comparing production-grade NLP libraries, was published a year ago on O’Reilly Radar. On the left is the comparison of runtime for training a simple pipeline (sentence boundary detection, tokenization, and part of speech tagging) on a single Intel i5, 4-core, 16 GB memory machine:
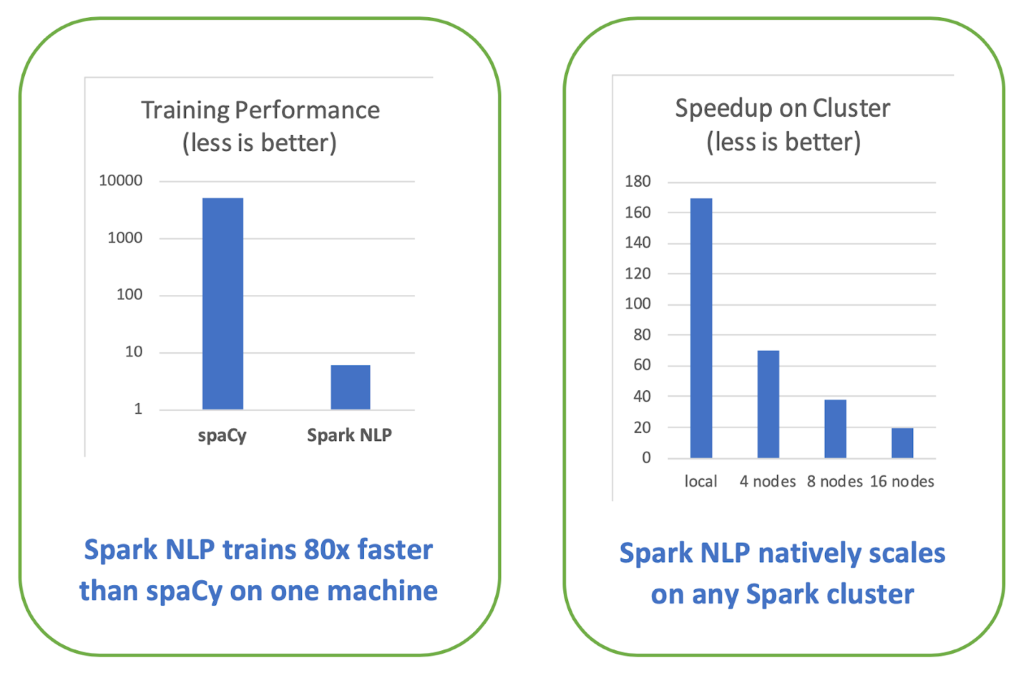
Being able to leverage GPU’s for training and inference has become table stakes. Using TensorFlow under the hood for deep learning enables Spark NLP to make the most of modern computer platforms – from nVidia’s DGX-1to Intel’s Cascade Lake processors. Older libraries, whether or not they use some deep learning techniques, will require a rewrite to take advantage of these new hardware innovations, that can add improve the speed and scale of your NLP pipelines by another order of magnitude.
Scalability
Being able to scale model training, inference, and full AI pipelines from a local machine to a cluster with little or no code changes has also become table stakes. Being natively built on Apache Spark ML enables Spark NLP to scale on any Spark cluster, on-premise or in any cloud provider. Speedups are optimized thanks to Spark’s distributed execution planning & caching, which has been tested on just about any current storage and compute platform.
Other Drivers of Enterprise Adoption
Production-grade codebase
We make our living delivering working software to enterprises. This was our primary goal here, in contrast to research-oriented libraries like AllenNLP and NLP Architect.
Permissive open source license
Sticking with an Apache 2.0 license so that the library can be used freely, including in a commercial setting. This is in contrast to Stanford CoreNLP which requires a paid license for commercial use, or the problematic ShareAlike CC licenses used for some spaCy models.
Full Python, Java and Scala API’s
Supporting multiple programming languages does not just increase the audience for a library. It also enables you to take advantage of the implemented models without having to move data back and forth between runtime environments. For example, using spaCy which is Python-only requires moving data from JVM processes to Python processes in order to call it – resulting in architectures that are more complex and often much slower than necessary.
Frequent Releases
Spark NLP is under active development by a full core team, in addition to community contributions. We release about twice a month – there were 25 new releases in 2018. We welcome contributions of code, documentation, models or issues – please start by looking at the existing issues on GitHub.
Ready to start? Go to install Spark NLP for the quick start guide, documentation, and samples.
Got questions? The homepage has a big blue button that invites you to join the Slack NLP Slack Channel. Us and the rest of the community are there every day to help you succeed.
As the world’s most widely used NLP library by enterprise practitioners, this powerful tool empowers organizations to harness the capabilities of natural language processing in various applications. By leveraging innovations like Generative AI in Healthcare and integrating a Healthcare Chatbot, enterprises can enhance patient interactions, improve data analysis, and drive more effective healthcare solutions.




