
























































Learn how to use Spark NLP and Python to analyze part of speech and grammar relations between words at scale
Dependency parsing with POS tags with Spark NLP
TL; DR: Part-of-Speech and Dependency Parsing are NLP techniques to perform text analysis and preprocessing. Using Spark NLP, it is possible to identify POS tags and the grammar relation between the words in the text in the Spark ecosystem with high accuracy that can be easily scaled.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML. It provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale quickly in a distributed environment.
Since its first release in July 2017, Spark NLP has grown into a complete NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in the industry (5 years in a row)
- The most scalable, accurate, and fastest library in NLP history
Spark NLP comes with 12000+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.

Spark NLP modules
Spark NLP processes the data using Pipelines, a structure that contains all the steps to be run on the input data:
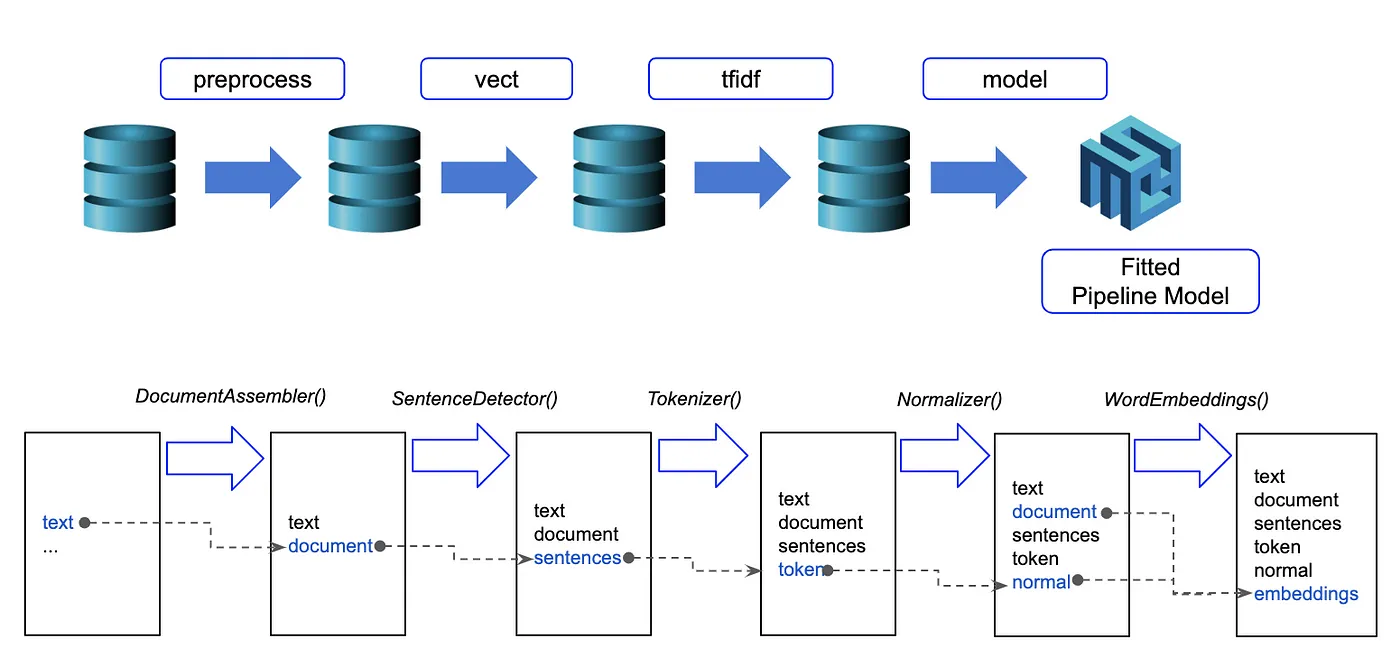
Spark NLP pipelines
Each step contains an annotator that performs a specific task, such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
How to Install Spark NLP
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp
spark = sparknlp.start()
Each word in a sentence has its grammatical role. Usual roles include subject, verb, adjective, etc. Being able to identify these roles can help to improve many NLP tasks such as Named Entity Recognition (NER), Word Sense Disambiguation (WSD), Question Answering (QA), Dependency Parsing (DP), or to make different analysis on the text.
If we know that a word is an adjective, there is a high probability that one of the neighboring words will be a noun. Also, depending on the context, words can have quite different meanings:
- What is your address? (noun)
- I will address this issue today. (verb)
So, what are the usual POS tags? There are two main sets of POS tags that are used in research and in industry. The first one is the Universal Dependencies schema that contains, for example:
The other one is designed by The University of Pennsylvania, which contains, for example:
- JJ: Adjective
- NN: Noun, singular or mass
- NNS: Noun, plural
- NNP: Proper noun, singular
- NNPS: Proper noun, plural
- RB: Adverb
- VB: Verb, base form
Different systems may have different tags, but they will be similar as they categorize the words with the same grammar rules (some with more detailed tags, such as separating tags for words in singular and plural).
There are diverse ways to train models for identifying these tags for each word, which can be divided into:
- Rules-based approach: using knowledge of the language and grammar, create rules to identify the roles of each word in the sentence.
- Statistical Learning models: uses statistical models to train a model from data. This approach is usually a good cost-benefit between the speed of predictions and accuracy.
- Deep Learning models: Models that are trained in a sizable portion of data and can afford to train complex structures of models (transformers, neural networks). It achieves state-of-the-art accuracy but requires more computational power to run.
Now that you know what POS is, let’s see how to use Spark NLP to tag words in a sentence.
Implementing on Spark NLP
In Spark NLP, the chosen approach is based on the Perceptron model (a statistical learning approach), where the model is trained on data in supervised learning.
The perceptron model (Minsky-Papert,1969)
John Snow Labs provides pretrained models on its NLP Models Hub, where we can find POS models for eighty-one different languages and multilanguage models. Let’s see how to use them in practice.
As seen above, the implementation of Spark NLP is based on pipelines, where each stage in the pipeline adds annotations of some type. To train the Perceptron model, we need DOCUMENT and TOKEN annotations. These can be obtained using common annotators from Spark NLP. Let’s see the pipeline:
from sparknlp.annotator import Tokenizer
from sparknlp.base import DocumentAssembler
from pyspark.ml import Pipeline
import pyspark.sql.function as F
# Stage 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Stage 2: Tokenization
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
# Stage 3: Perceptron model for POS Tagger
# Pretrained model `pos_anc` for texts in English
postagger = (
PerceptronModel.pretrained("pos_anc", "en")
.setInputCols("document", "token")
.setOutputCol("pos")
)
# Define the pipeline object
pos_pipeline = Pipeline(stages = [
document_assembler,
tokenizer,
postagger
])
The first stage in the pipeline creates the DOCUMENT annotation from the raw text using the DocumentAssembler annotator. The second stage tokenizes the text into words using the Tokenizer annotator. Finally, we add to the pipeline the PerceptronModel annotator, which contains the pretrained model for POS tagging.
The pipeline is defined using Spark ML Pipeline class. To use the pipeline for predictions, we need to fit it with data. Since we are only using pretrained models, we can fit in an empty data frame to obtain the PipelineModel for predictions (see this documentation page if you are not familiar with Spark ML).
# Create an empty data frame with column `text`
empty_data = spark.createDataFrame([[""]]).toDF("text")
# Fit the pipeline
model = pos_pipeline.fit(empty_data)
Let’s run the model on an example sentence: “Unions representing workers at Turner Newall say they are ‘disappointed’ after talks with stricken parent firm Federal Mogul”.
We use the .transform() method on the spark data frame containing the example sentence. Then we use pyspark.sql.functions to manipulate the obtained predictions and display each word with its corresponding big, end, and POS tag.
# Add the example sentence to a Spark Data Frame
example = spark.createDataFrame(
[
[
"Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul"
]
]
).toDF("text")
# Make predictions
result = model.Transform(example)
# Display results to check the labels
result.select(
F.explode(
F.arrays_zip(
result.token.result, result.token.begin,
result.token.end, result.pos.result
)
).alias("cols")
).select(
F.expr("cols['0']").alias("token"),
F.expr("cols['1']").alias("begin"),
F.expr("cols['2']").alias("end"),
F.expr("cols['3']").alias("pos"),
).show()
We obtain the following result:

A one-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow, especially for users that work with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Labs’ libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run POS tagging with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
example_sentence = "Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul"
# Returns a pandas Data Frame, we select the desired columns
nlp.load("pos").predict(example_sentence)[['token','pos']]

The result pandas Data Frame after using the one-liner model
The one-liner is based on default models for each NLP task. For POS, it uses the same model as before, so depending on your requirements, you may want to use the one-liner for simplicity or customize the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function include using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
Identifying Grammar Relations with Dependency Parsing
Now, let’s check how to obtain grammar relations between the tagged words. In Spark NLP, we have two annotators to extract dependencies from texts.
DependencyParserModel: extracts the relations without labelsTypedDeppendencyParserModel: extracts the relations’ labels, based on the obtained dependencies
Every model may have distinct types of relations (depending on the language they support). For English, the most common relations are the ones defined by the Universal Dependencies schema:
- acl: clausal modifier of noun (adnominal clause)
- advcl: adverbial clause modifier
- advmod: adverbial modifier
- aux: auxiliary
- cc: coordinating conjunction
- ccomp: clausal complement
- clf: classifier
- conj: conjunct
- csubj: clausal subject
- det: determiner
- iobj: indirect object
- nsubj: nominal subject
- obj: object
- obl: oblique nominal
- root: root
- vocative: vocative
- xcomp: open clausal complement
How to apply in Spark NLP
The dependency parsing models expect the pipeline to contain the following annotations: DOCUMENT, POS, TOKEN, and will output a new annotation of type DEPENDENCY. All these annotations are already in the resulting data frame obtained in the POS section above, so we can add the dependency parsing stages to the pipeline.
Thankfully, this is easy in Spark NLP by just adding the new stages:
# Import the required modules and classes
from sparknlp.annotator import (
DependencyParserModel,
TypedDependencyParserModel,
)
# New stage 1: Dependency Parsing (unlabeled)
dependency = (
DependencyParserModel.pretrained("dependency_conllu")
.setInputCols(["document", "pos", "token"])
.setOutputCol("dependency")
)
# New stage 2: Dependency Parsing (labeled)
dependency_label = (
TypedDependencyParserModel.pretrained("dependency_typed_conllu")
.setInputCols(["token", "pos", "dependency"])
.setOutputCol("dependency_type")
)
# Define the pipeline
dp_pipeline = Pipeline(
stages=[
pos_pipeline, # Use the previous pipeline for POS
dependency,
dependency_label
]
)
As before, we need to fit the obtained pipeline to be ready to make predictions. We can do that in sequence without keeping the model variable and obtain the result directly:
# Fit-transform to get predictions
result = pipeline.fit(empty_data).transform(example)
# Display the obtained spark Data Frame
result. Show()
The obtained data frame has the following format:
result.show()
+——————–+——————–+——————–+——————–+——————–+——————–+
| text| document| token| pos| dependency| dependency_type|
+——————–+——————–+——————–+——————–+——————–+——————–+
|Unions representi…|[{document, 0, 12…|[{token, 0, 5, Un…|[{pos, 0, 5, NNP,…|[{dependency, 0, …|[{labeled_depende…|
+——————–+——————–+——————–+——————–+——————–+——————–+
Each column contains its pipeline step annotation. Let’s use spark.sql.functions to visualize the information in a better format:
result.select(
F.explode(
F.arrays_zip(
result.token.result,
result.token.begin,
result.token.end,
result.dependency.result,
result.dependency_type.result,
)
).alias("cols")
).select(
F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']").alias("begin"),
F.expr("cols['2']").alias("end"),
F.expr("cols['3']").alias("dependency"),
F.expr("cols['4']").alias("dependency_type"),
).show(
truncate=False)

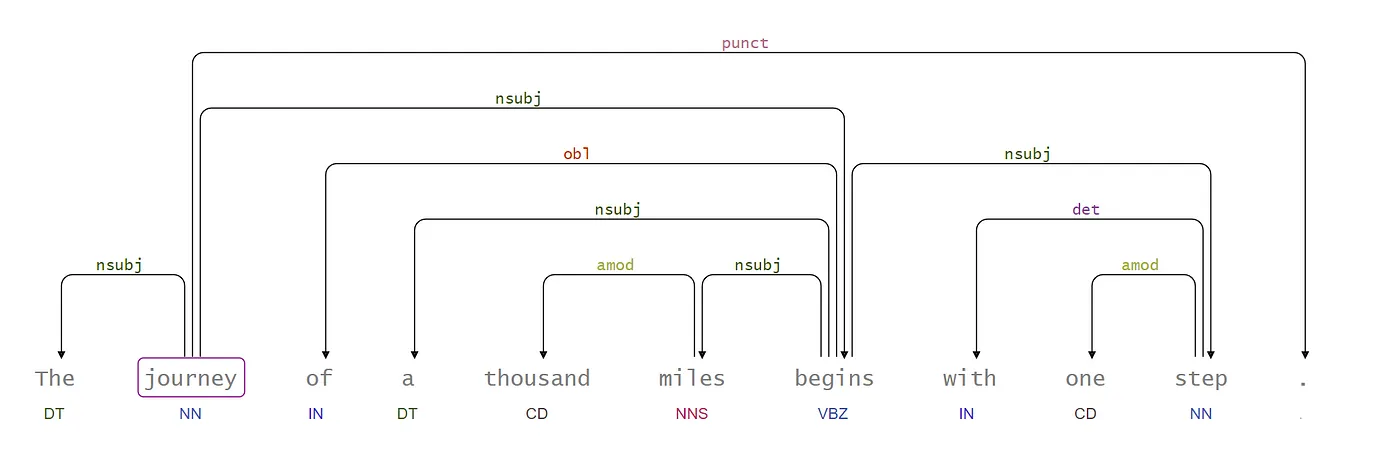
In the table above, you can see the tokens/words that have a dependency and their dependency type.
Visualizing the dependencies
For a visual representation of the dependencies, it is possible to use the module spark-nlp-display, another open-source tool. Look how simple it is:
Install with pip:
pip install spark-nlp-display
Then run the DependencyParserVisualizer to create the visualization.
from sparknlp_display import DependencyParserVisualizer
dependency_vis = DependencyParserVisualizer()
dependency_vis.display(
result.collect()[0], # should be the results of a single example, not the complete dataframe.
pos_col="pos",
dependency_col="dependency",
dependency_type_col="dependency_type",
)

The visualization of dependencies
Using the johnsnowlabs library
Again, the same result can be obtained using one line of code:
nlp.load("dep").predict(
"Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul"
)
And the visualization can be done using the .viz() method instead of .predict(), as easy as that:
nlp.load("dep").viz(
"Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul"
)
That’s all!! With this, you can use the power of Spark and Spark NLP at scale to perform dependency parsing of your texts.
Conclusion
In this post, you learned how to use pretrained models to identify POS tags and text grammar dependencies using Spark NLP. You learned why these tasks are essential and how to create a visualization of them using the Spark NLP Display library. Finally, you learned how to use the one-liner library johnsnowlabs to perform these tasks effortlessly.
References:
For additional information, don’t hesitate to consult the following references.
- Spark NLP documentation page for all available annotators
- Python API documentation for PerceptronModel and Dependency Parser
- Scala API documentation for PerceptronModel and DependencyParserModel
- For extended examples of usage of Spark NLP annotators, check the Spark NLP Workshop repository.
- Minsky, M.L. and Papert, S.A. (1969) Perceptrons. MIT Press, Cambridge.



