
























































Speed up state-of-the-art ViT models in Hugging Face 🤗 up to 2300% (25x times faster ) with Databricks, Nvidia, and Spark NLP 🚀
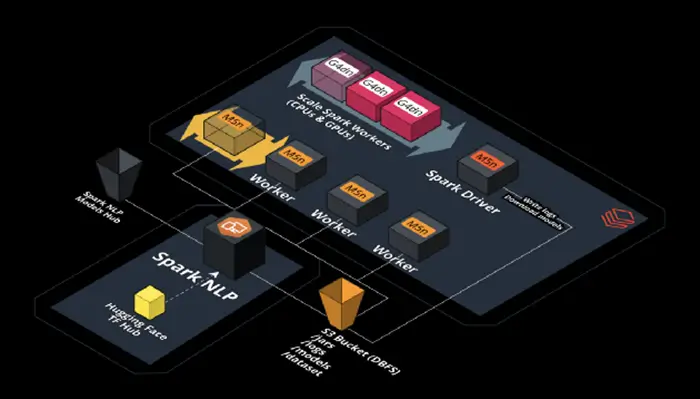
Scaling out transformer-based models by using Databricks, Nvidia, and Spark NLP
Previously on “Scale Vision Transformers (ViT) Beyond Hugging Face | Part 2”:
Databricks Single Node: Spark NLP is up to 15% faster than Hugging Face on CPUs in predicting image classes for the sample dataset with 3K images and up to 34% on the larger dataset with 34K images. Spark NLP is also 51% faster than Hugging Face on a single GPU for a larger dataset with 34K images and up to 36% faster on a smaller dataset with 3K images.
The purpose of this article is to demonstrate how to scale out Vision Transformer (ViT) models from Hugging Face and deploy them in production-ready environments for accelerated and high-performance inference. By the end, we will scale a ViT model from Hugging Face by 25x times (2300%) by using Databricks, Nvidia, and Spark NLP.
In Part 3 of this article, I will:
- Benchmark Spark NLP inside Databricks scaled to 10x Nodes with CPUs & GPUs
- Sum up everything!
In the spirit of full transparency, all the notebooks with their logs, screenshots, and even the excel sheet with numbers are provided here on GitHub
You can read Part 1 and Part 2 of this article if you need to catch up.
Scaling beyond a single machine
So far we established that Hugging Face on GPU is faster than Hugging Face on CPUs on a bare-metal server and Databricks Single Node. This is what you expect when you are comparing GPU vs. CPU with these new transformer-based models.
We have also established that Spark NLP outperforms Hugging Face for the very same pipeline (ViT model), on the very same datasets, in both bare-metal server and Databricks single node cluster, and it performs better on both CPU and GPU devices. This on the other hand was not something I expected. When I was preparing this article I expected TensorFlow inference in Spark NLP to be slightly slower than inference in Hugging Face by using PyTorch or at least be neck and neck. I was aiming for this section, scaling the pipeline beyond a single machine. But it seems Spark NLP is faster than Hugging Face even in a single machine, on both CPU and GPU, over both small and large datasets.
Question: What if you want to make your ViT pipeline even faster? What if you have even larger datasets and you just cannot fit them inside one machine or it just takes too long to get the results back?
Answer: Scaling out! This means instead of resizing the same machine, add more machines to your cluster. You need something to manage all those jobs/tasks/scheduling DAGs/manage failed tasks/etc. and those have their overheads, but if you need something to be faster or to be possible (beyond a single machine) you have to use some sort of distributed system.
Scaling up = making your machine bigger or faster so that it can handle more load.
Scaling out = adding more machines in parallel to spread out a load.
Scaling out Hugging Face:
Looking at the page on Hugging Face’s official Website suggests scaling inference is only possible by using Multi-GPUs. As we describe what scaling out is, this is still stuck in a single machine:
https://huggingface.co/docs/transformers/performance
Also, not to mention that the Multi-GPUs solution for inference in Hugging Face doesn’t exist at the moment:
https://huggingface.co/docs/transformers/perf_infer_gpu_many
So it seems there is no native/official way to scale out Hugging Face pipelines. You can implement your architecture consisting of some microservices such as a job queue, messaging protocols, RESTful APIs backend, and some other required components to distribute each request over different machines, but this scales the requests by individual users instead of scaling out the actual system itself.
In addition, the latency of such systems is not comparable with natively distributed systems such as Apache Spark (gRPC might lower this latency, but still not competitive). Not to mention the single point of failure issue, managing failed jobs/tasks/inputs, and hundreds of other features you get out-of-the-box from Apache Spark that now you have to implement/maintain by yourself.
There is a blog post on the Hugging Face Website portraying the very same architecture by scaling REST endpoints to serve more users: “Deploying 🤗 ViT on Kubernetes with TF Serving” — I believe other companies are using similar approaches to scale out Hugging Face, however, they are all scaling the number of users/requests hitting the inference REST endpoints. In addition, you cannot scale Hugging Face this way on Databricks.
For instance, inference inside fastAPI is 10x times slower than local inference: https://towardsdatascience.com/hugging-face-transformer-inference-under-1-millisecond-latency-e1be0057a51c
Once Hugging Face offers some native solutions to scale out I will re-run the benchmarks again. Until then, there is no scaling out when you have to loop through the dataset from a single machine to hit REST endpoints in a round-robin algorithm. (think again about the part we batched rows/sequences/images to feed the GPU all at once, then you’ll get it)
Scaling out Spark NLP:
Spark NLP is an extension of Spark ML therefore it scales natively and seamlessly over all supported platforms by Apache Spark such as (and not limited) Databricks, AWS EMR, Azure Insight, GCP Dataproc, Cloudera, SageMaker, Kubernetes, and many more.
Zero code changes are needed! Spark NLP can scale from a single machine to an infinite number of machines without changing anything in the code!
You also don’t need to export any models out of Spark NLP to use it in an entirely different library to speed up or scale the inference.
Spark NLP ecosystem: optimized, tested, and supported integrations
Databricks Multi-Node with CPUs on AWS
Let’s create a cluster and this time we choose Standard inside Cluster mode. This means we can have more than 1 node in our cluster which in Apache Spark terminology it means 1 Driver and N number of Workers (Executors).
We also need to install Spark NLP in this new cluster via the Libraries tab. You can follow the steps I mentioned in the previous section for Single Node Databricks with CPUs. As you can see, I have chosen the same CPU-baed AWS instance I used to benchmark both Hugging Face and Spark NLP so we can see how it scales out when we add more nodes.
This is what our Cluster configurations look like:
Databricks multi-node (standard) cluster with only CPUs
I will reuse the same Spark NLP pipeline I used in previous benchmarks (no need to change any code) and also I will only use the larger dataset with 34K images. Let’s begin!
Scale Spark NLP on CPUs with 2x nodes

Databricks with 2x Nodes — CPUs only
Let’s just add 1 more node and make the total of the machines that will do the processing from 1 to 2 machines. Let’s not forget the beauty of Spark NLP when you go from a single machine setup (your Colab, Kaggle, Databricks Single Node, or even your local Jupyter notebook) to a multi-node cluster setup (Databricks, EMR, GCP, Azure, Cloudera, YARN, Kubernetes, etc.), zero-code change is required! And I mean zero! With that in mind, I will run the same benchmark inside this new cluster on the larger datasets with 34K images:

Spark NLP image-classification pipeline on 2x nodes with CPUs (oneDNN) — predicting 34742 images
It took around 9 minutes (550 seconds) to finish predicting classes for 34K images. Let’s compare this result on 2x Nodes with Spark NLP and Hugging Face results on Databricks single node (I will keep repeating the Hugging Face results on a Single Node as a reference since Hugging Face could not be scaled out on multiple machines, especially on Databricks):
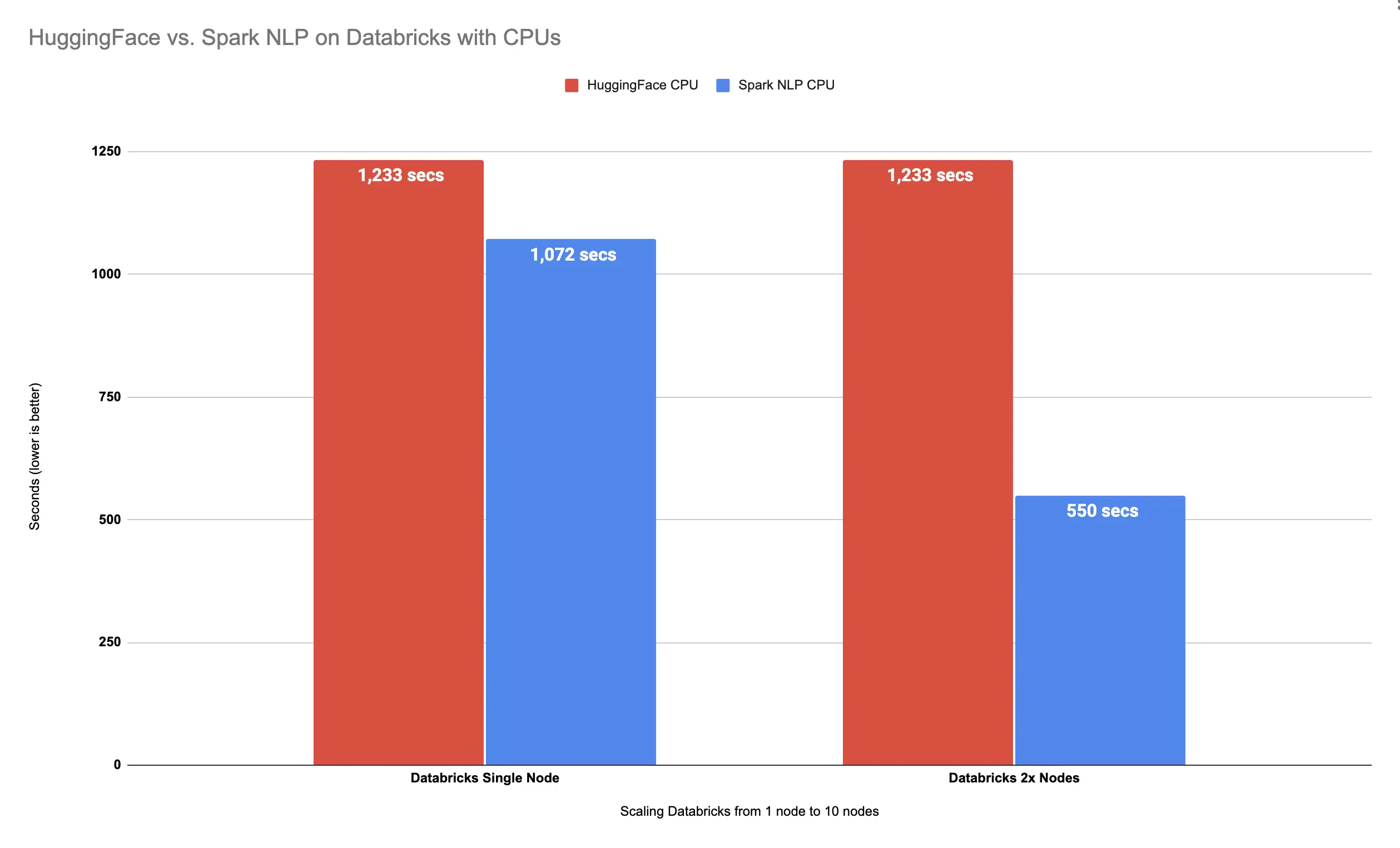
Spark NLP is 124% faster than Hugging Face with 2x Nodes
Previously, Spark NLP beat Hugging Face on a Single Node Databricks cluster by using only CPUs by 15%.
This time, by having only 2x nodes instead of 1 node, Spark NLP finished the process of over 34K images 124% faster than Hugging Face.
Scale Spark NLP on CPUs with 4x nodes
Let’s double the size of our cluster like before and go from 2x Nodes to 4x Nodes. This is how the cluster would look like with 4x nodes:
Databricks with 4x Nodes — CPUs only
I will run the same benchmark on this new cluster on the larger datasets with 34K images:

Spark NLP image-classification pipeline on 4x nodes with CPUs (oneDNN) — predicting 34742 images
It took around 5 minutes (289 seconds) to finish predicting classes for 34K images. Let’s compare this result on 4x Nodes with Spark NLP vs. Hugging Face on CPUs on Databricks:
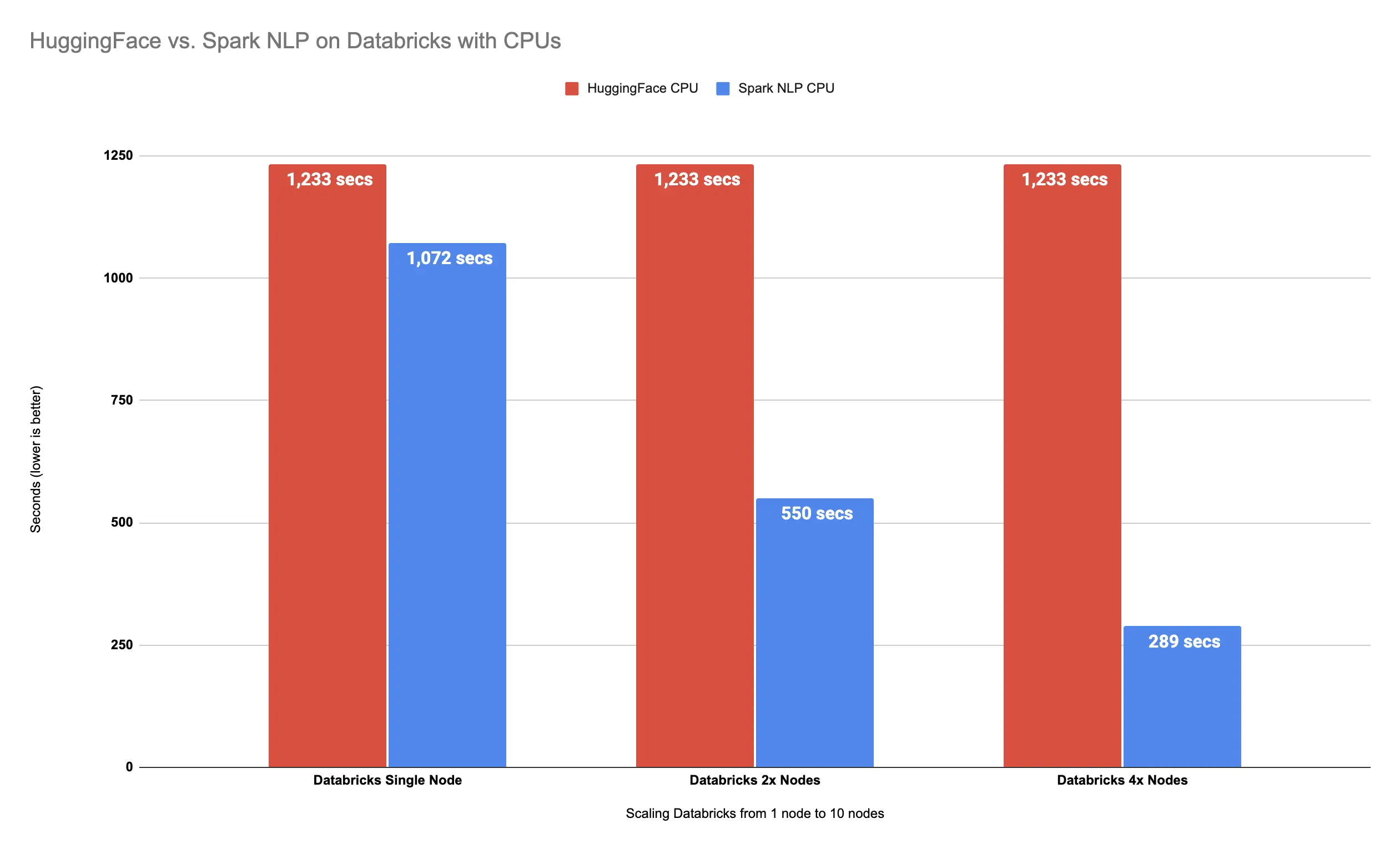
Spark NLP
is 327% faster than Hugging Face with 4x Nodes
As it can be seen, Spark NLP is now 327% faster than Hugging Face on CPUs while using only 4x Nodes in Databricks.
Scale Spark NLP on CPUs with 8x nodes
Now let’s double the previous cluster by adding 4x more Nodes and make the total of 8x Nodes. This resizing the cluster by the way is pretty easy, you just increase the number of workers in your cluster configurations:

Resizing Spark Cluster in Databricks

Databricks with 8x Nodes — CPUs only
Let’s run the same benchmark this time on 8x Nodes:

Spark NLP image-classification pipeline on 8x nodes with CPUs (oneDNN) — predicting 34742 images
It took over 2 minutes and a half (161 seconds) to finish predicting classes for 34K images. Let’s compare this result on 8x Nodes with Spark NLP vs. Hugging Face on CPUs on Databricks:
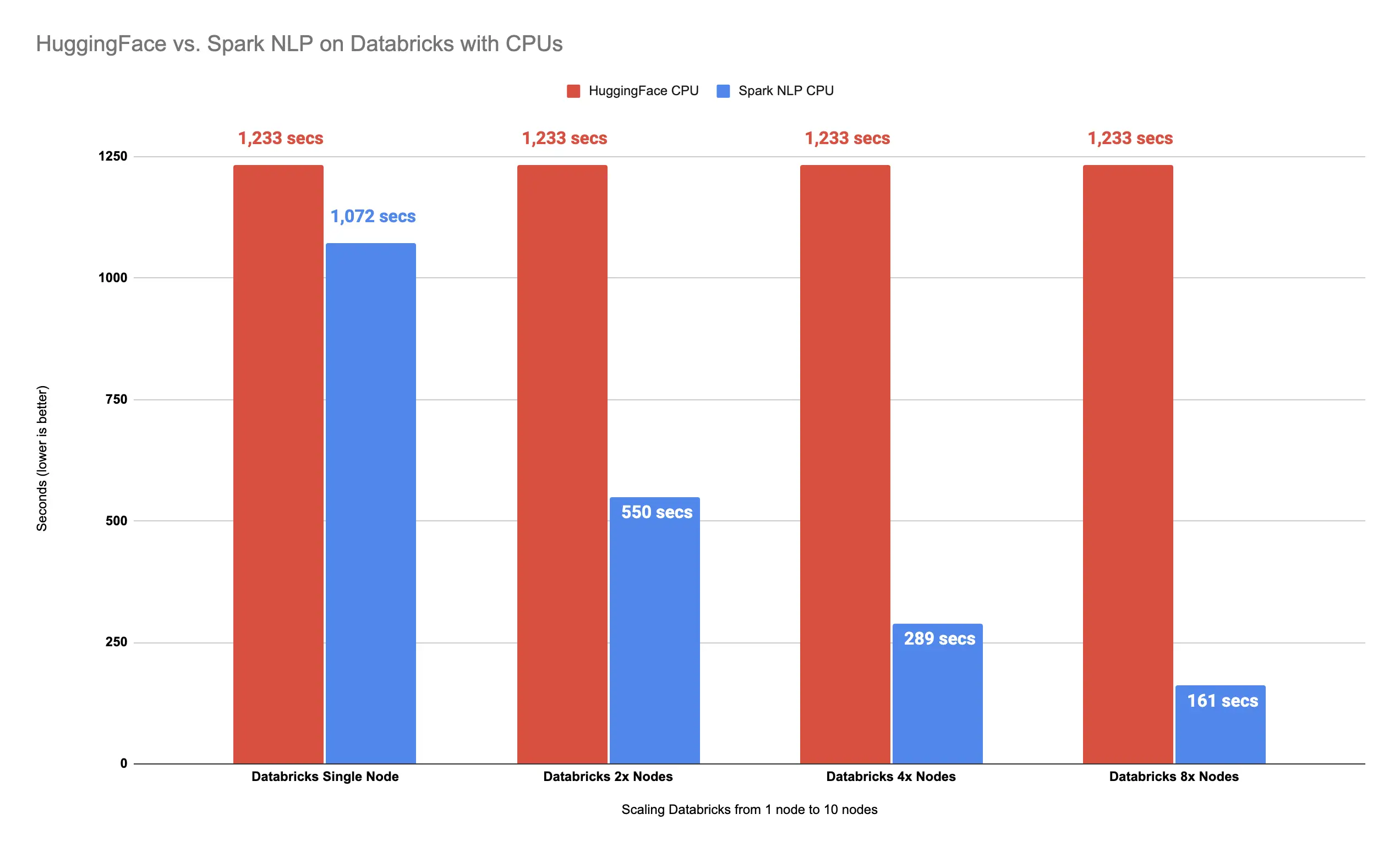
Spark NLP
is 666% faster than Hugging Face with 8x Nodes
As it can be seen, Spark NLP is now 666% faster than Hugging Face on CPUs while using only 8x Nodes in Databricks.
Let’s just ignore the number of 6s here! (it was 665.8% if it makes you feel better)
Scale Spark NLP on CPUs with 10x nodes
To finish our scaling out ViT models predictions on CPUs in Databricks by using Spark NLP I will resize the cluster one more time and increase it to 10x Nodes:

Databricks with 10x Nodes — CPUs only
Let’s run the same benchmark this time on 10x Nodes:

Spark NLP image-classification pipeline on 10x nodes with CPUs (oneDNN) — predicting 34742 images
It took less than 2 minutes (112 seconds) to finish predicting classes for 34K images. Let’s compare this result on 10x Nodes with all the previous results from Spark NLP vs. Hugging Face on CPUs on Databricks:
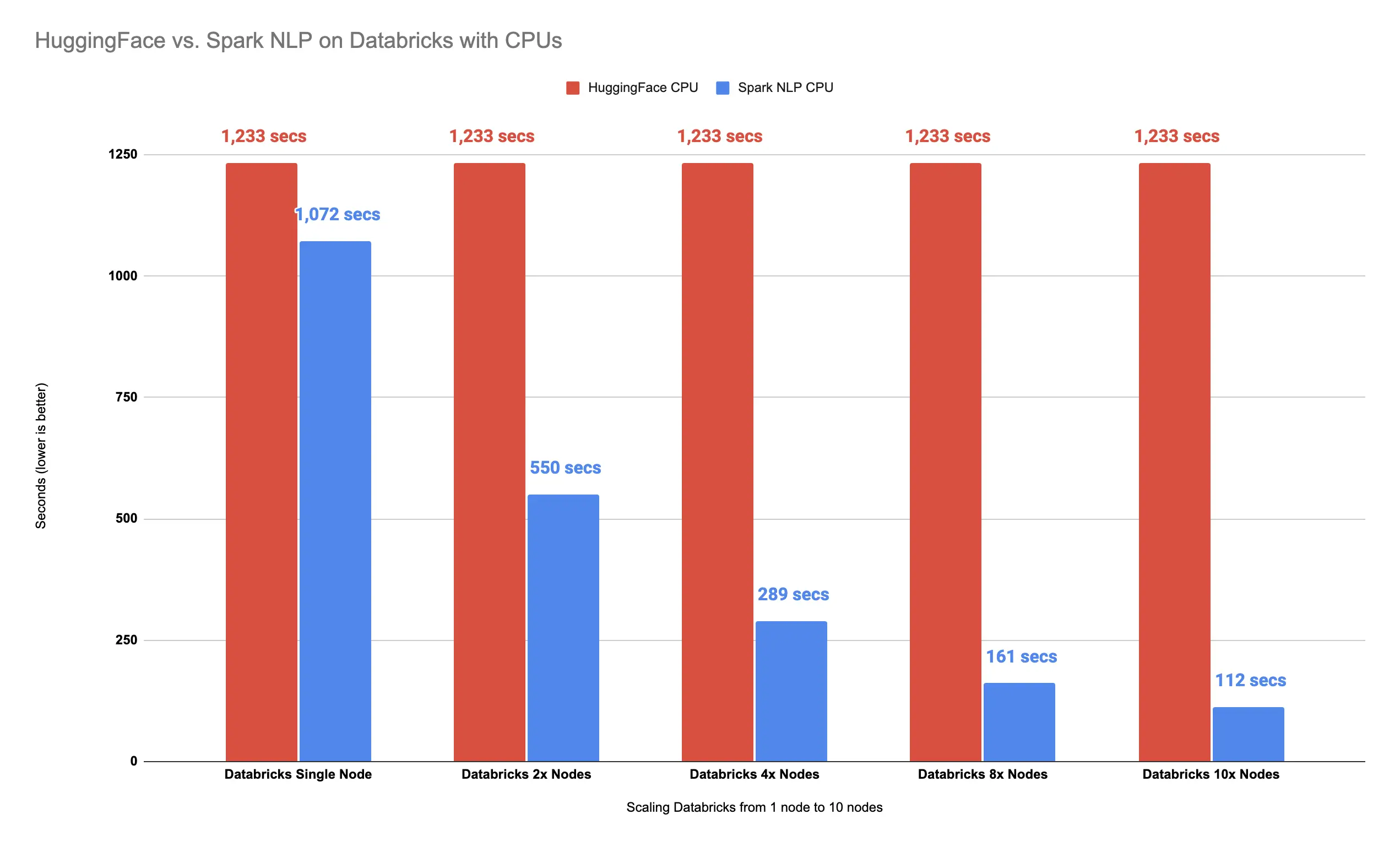
Spark NLP is 1000% faster than Hugging Face with 10x Nodes
And this is how you scale out the Vision Transformer model coming from Hugging Face on 10x Nodes by using Spark NLP in Databricks! Our pipeline now is 1000% faster than Hugging Face on CPUs.
We managed to make our ViT pipeline 1000% faster than Hugging Face which is stuck in 1 single node by simply using Spark NLP, but we only used CPUs. Let’s see if we can get the same improvements by scaling out our pipeline on a GPU cluster.
Databricks Multi-Node with GPUs on AWS
Having a GPU-based multi-node Databricks cluster is pretty much the same as having a single-node cluster. The only difference is choosing Standard and keeping the same ML/GPU Runtime with the same AWS Instance specs we chose in our benchmarks for GPU on a single node.
We also need to install Spark NLP in this new cluster via the Libraries tab. Same as before, you can follow the steps I mentioned in Single Node Databricks with a GPU.
Databricks multi-node (standard) cluster with GPUs
Scale Spark NLP on GPUs with 2x nodes
Our multi-node Databricks GPU cluster uses the same AWS GPU instance of g4dn.8xlarge that we used previously to run our benchmarks to compare Spark NLP vs. Hugging Face on a single-node Databricks cluster.
This is a summary of what it looks like this time with 2 nodes:

Databricks with 2x Nodes — with 1 GPU per node
I am going to run the same pipeline in this GPU cluster with 2x nodes:
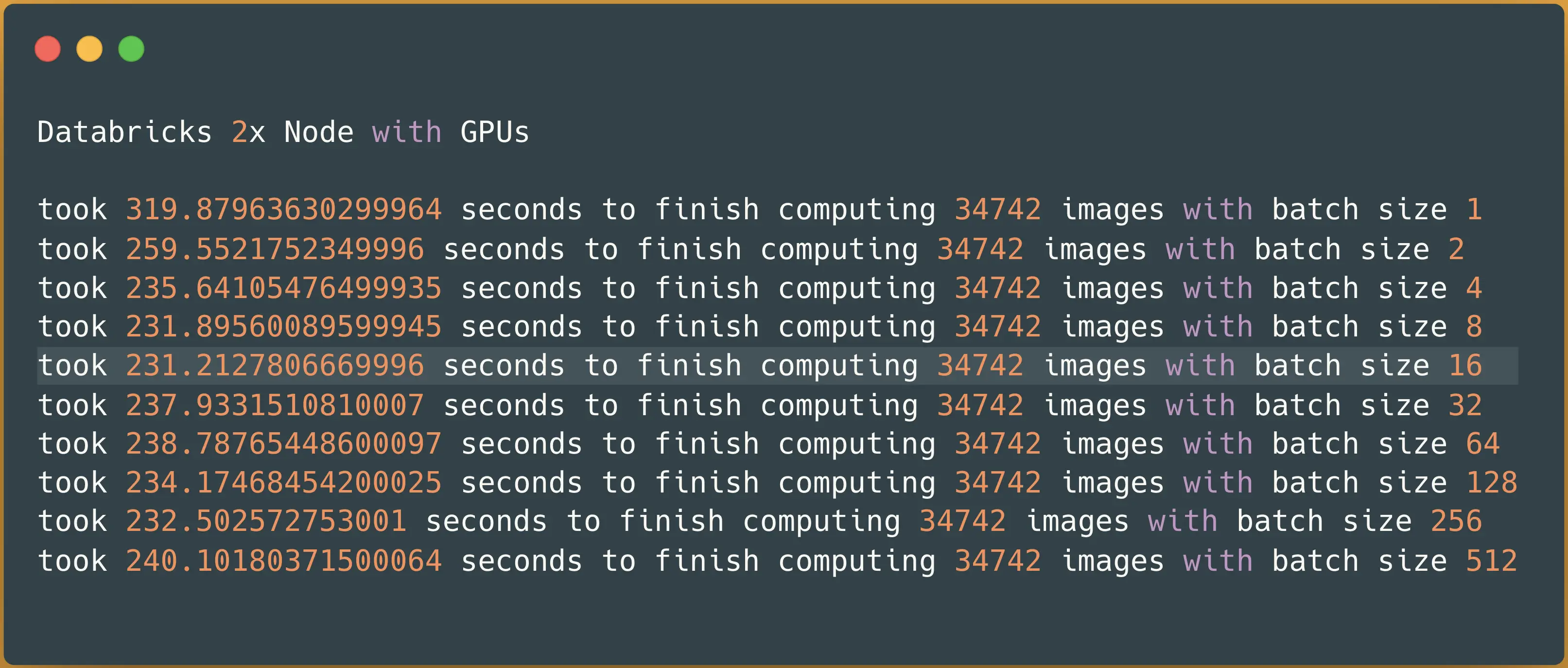
Spark NLP image-classification pipeline on 2x nodes with GPUs — predicting 34742 images
It took 4 minutes (231 seconds) to finish predicting classes for 34K images. Let’s compare this result on 2x Nodes with Spark NLP vs. Hugging Face on GPUs in Databricks:
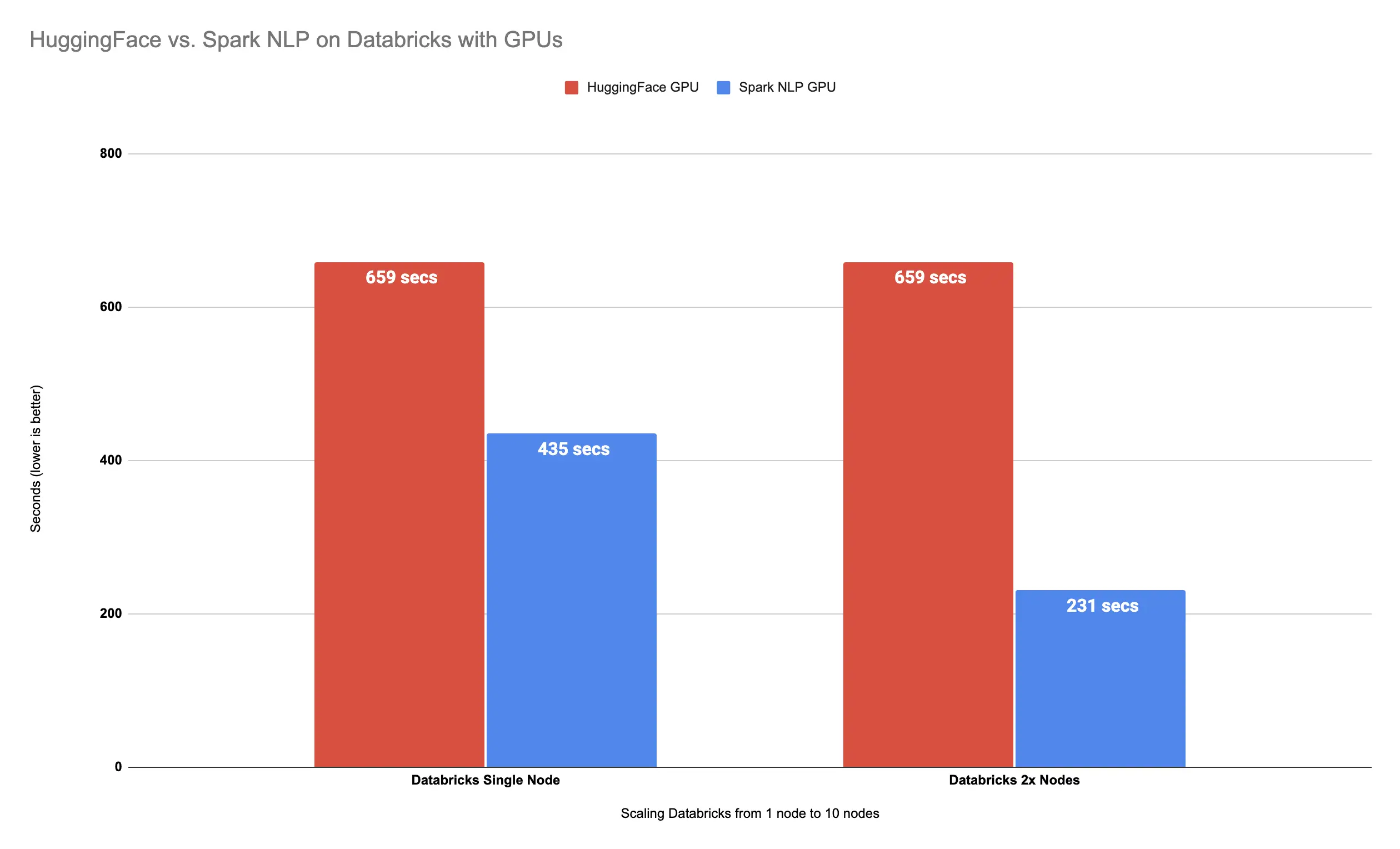
Spark NLP is 185% faster than Hugging Face with 2x Nodes
Spark NLP with 2x Nodes is almost 3x times faster (185%) than Hugging Face on 1 single node while using GPU.
Scale Spark NLP on GPUs with 4x nodes
Let’s resize our GPU cluster from 2x Nodes to 4x Nodes. This is a summary of what it looks like this time with 4x Nodes using a GPU:
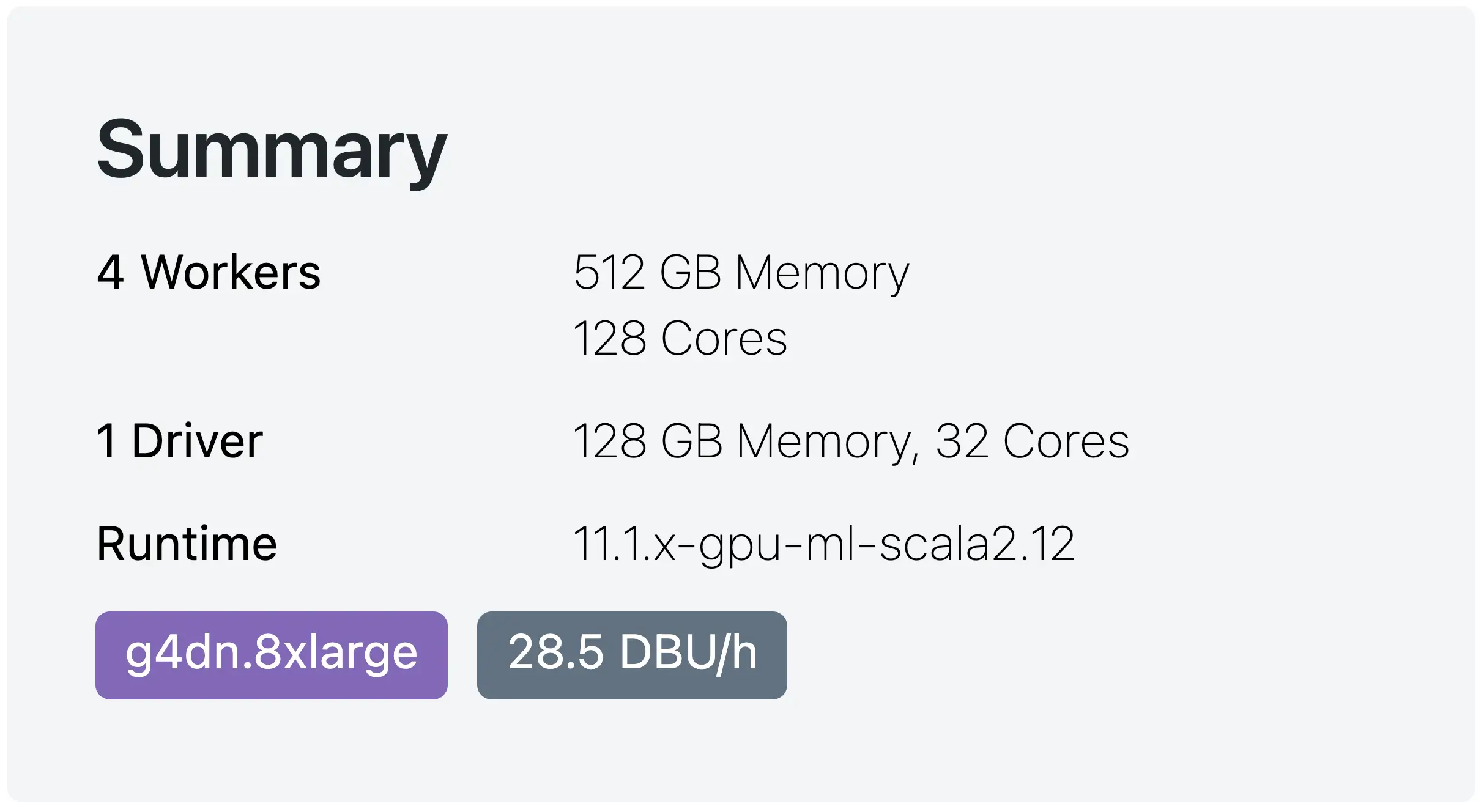
Databricks with 4x Nodes — with 1 GPU per node
Let’s run the same benchmark on 4x Nodes and see what happens:
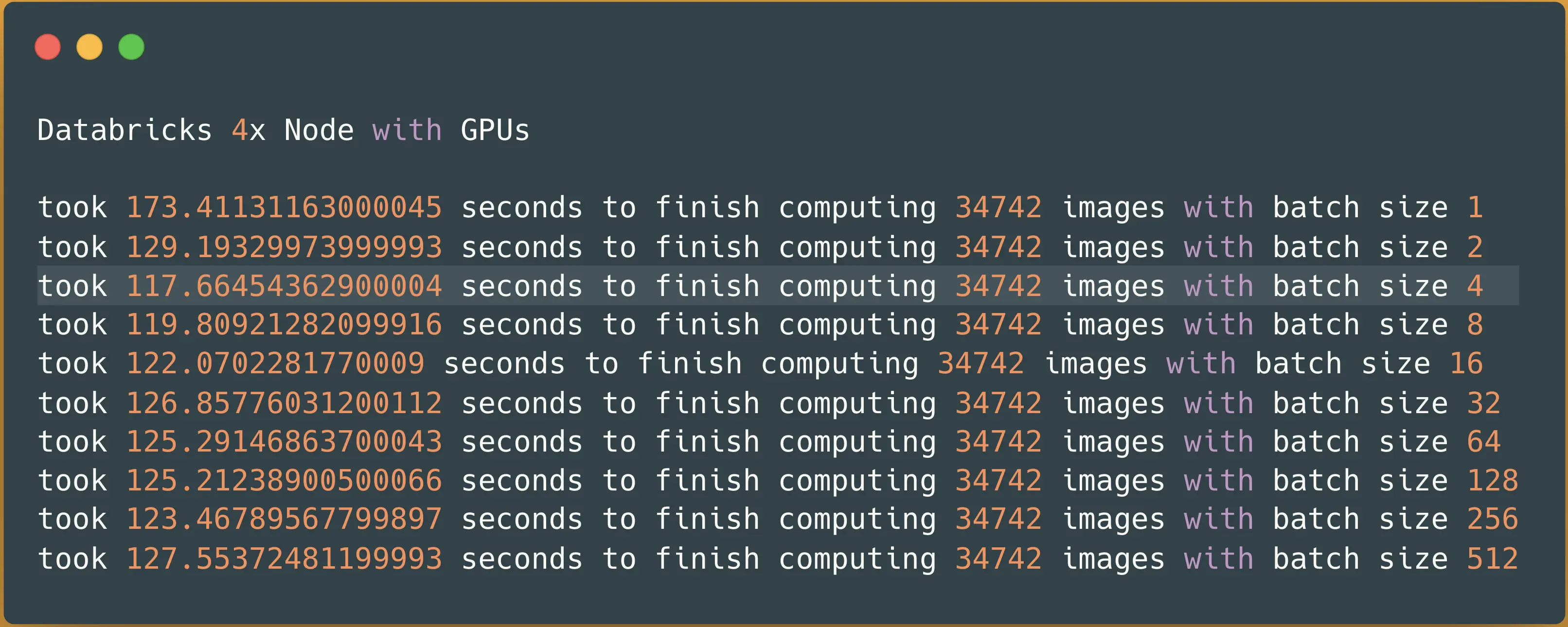
Spark NLP image-classification pipeline on 4x nodes with GPUs — predicting 34742 images
This time it took almost 2 minutes (118 seconds) to finish classifying all 34K images in our dataset. Let’s visualize this just to have a better view of what this means in terms of Hugging Face in a single node vs. Spark NLP in a multi-node cluster:
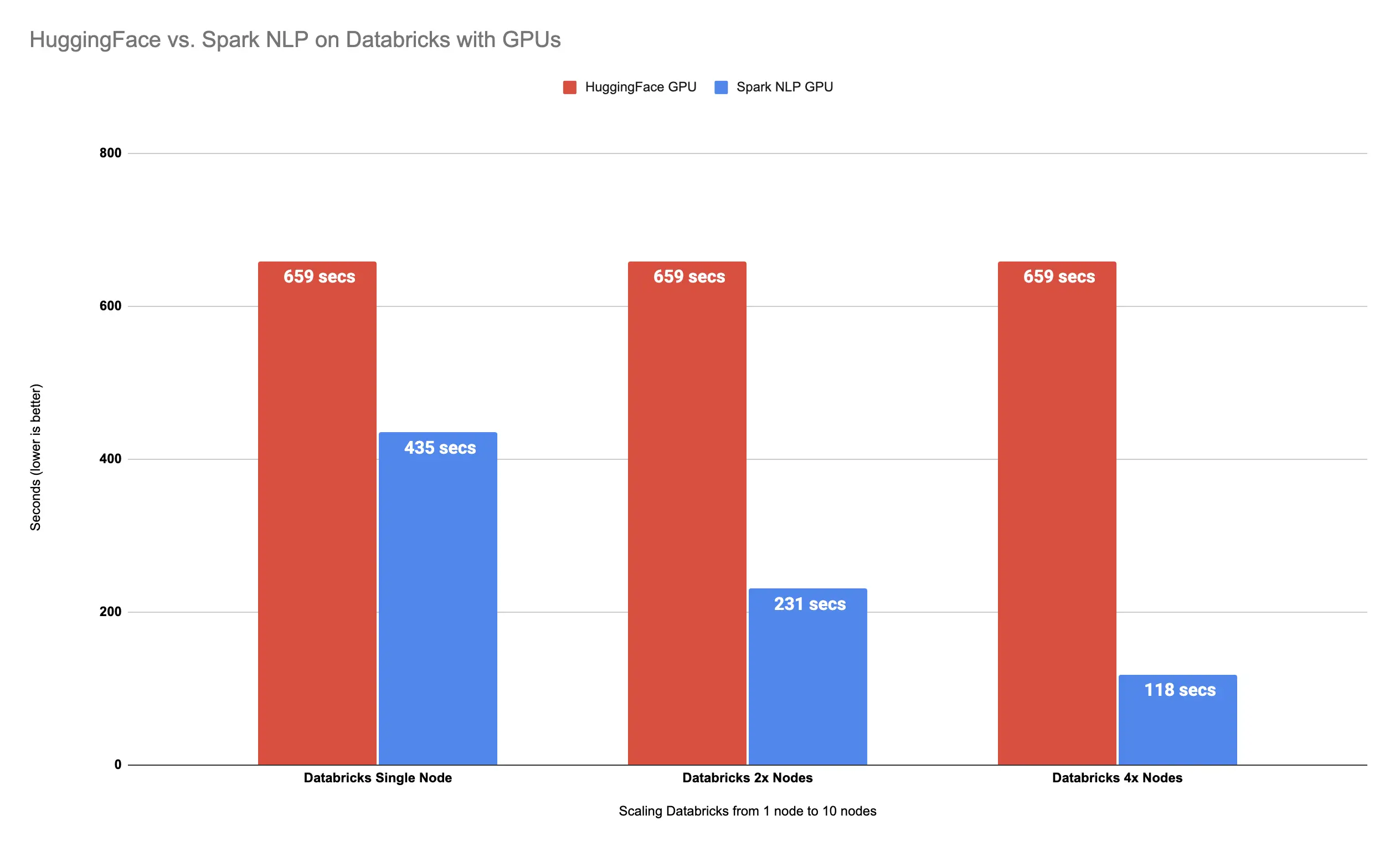
Spark NLP
is 458% faster than Hugging Face with 4x Nodes
That’s a 458% increased performance compared to Hugging Face. We just made our pipeline 5.6x times faster by using Spark NLP with 4x nodes.
Scale Spark NLP on GPUs with 8x nodes
Next, I will resize the cluster to have 8x Nodes in my Databricks with the following summary:
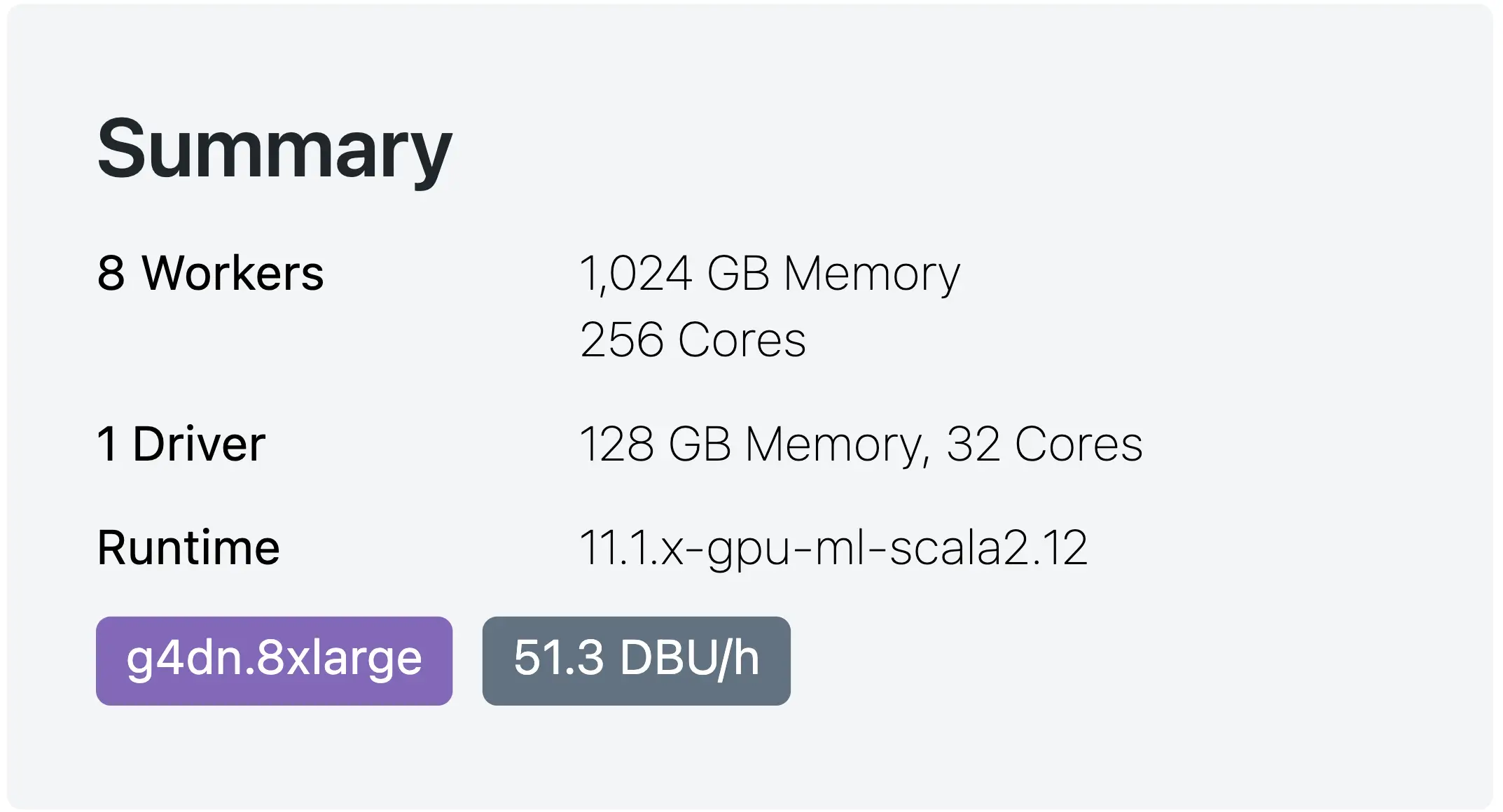
Databricks with 8x Nodes — with 1 GPU per node
Just as a reminder, each AWS instance (g4dn.8xlarge) has 1 NVIDIA T4 GPU 16GB (15GB useable memory). Let’s re-run the benchmark and see if we can spot any improvements as scaling out in any distributed system have its overheads and you cannot just keep on adding machines:
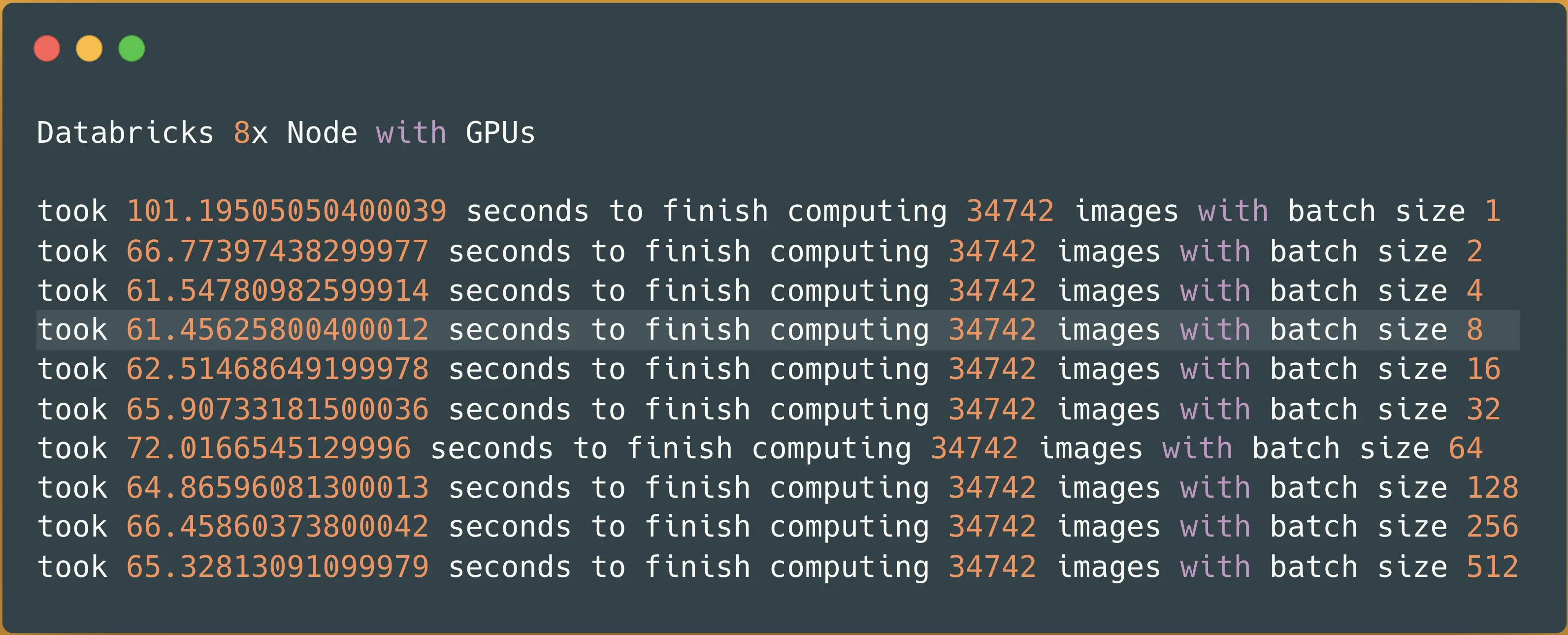
Spark NLP image-classification pipeline on 8x nodes with GPUs — predicting 34742 images
It took almost a minute (61 seconds) to finish classifying 34K images with 8x Nodes in our Databricks cluster. It seems we still managed to improve the performance. Let’s put this result next to previous results from Hugging Face in a single node vs. Spark NLP in a multi-node cluster:
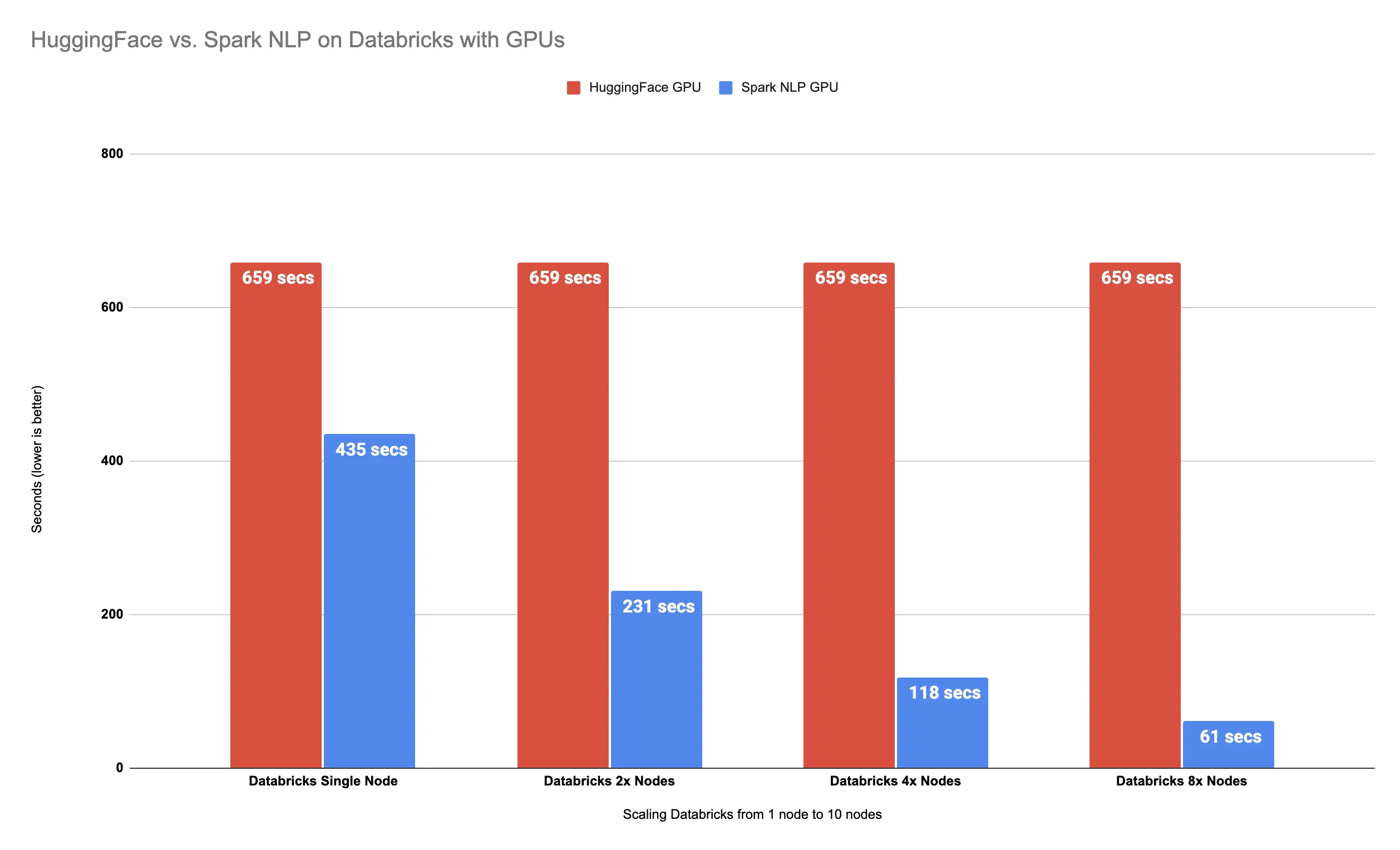
Spark NLP
is 980% faster than Hugging Face with 8x Nodes
Spark NLP with 8x Nodes is almost 11x times faster (980%) than Hugging Face on GPUs.
Scale Spark NLP on GPUs with 10x nodes
Similar to our multi-node benchmarks on CPUs I would like to resize the GPU cluster one more time to have 10x Nodes and match them in terms of the final number of nodes. The final summary of this cluster is as follows:
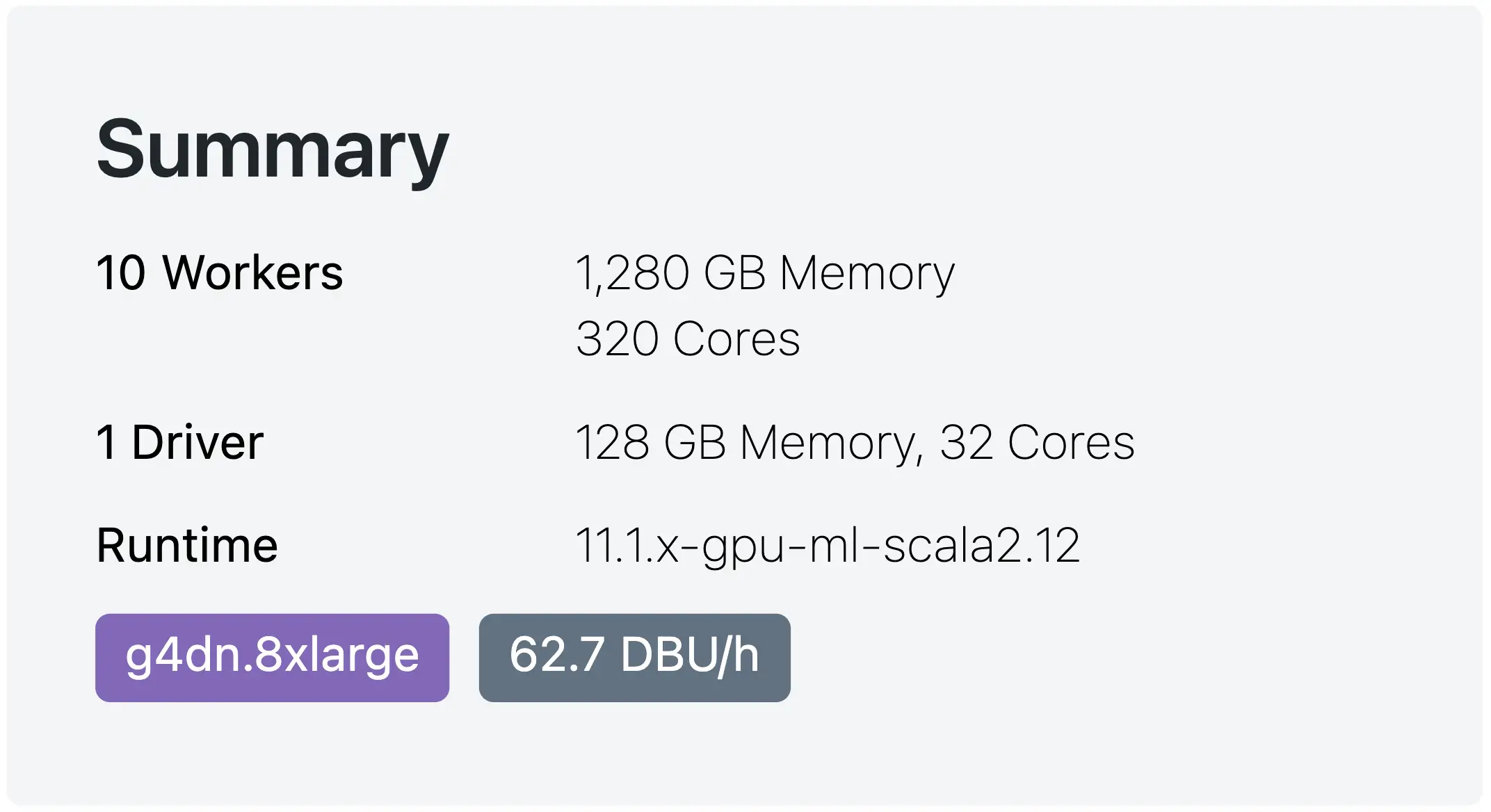
Databricks with 10x Nodes — with 1 GPU per node
Let’s run our very last benchmark in this specific GPU cluster (with zero code changes):
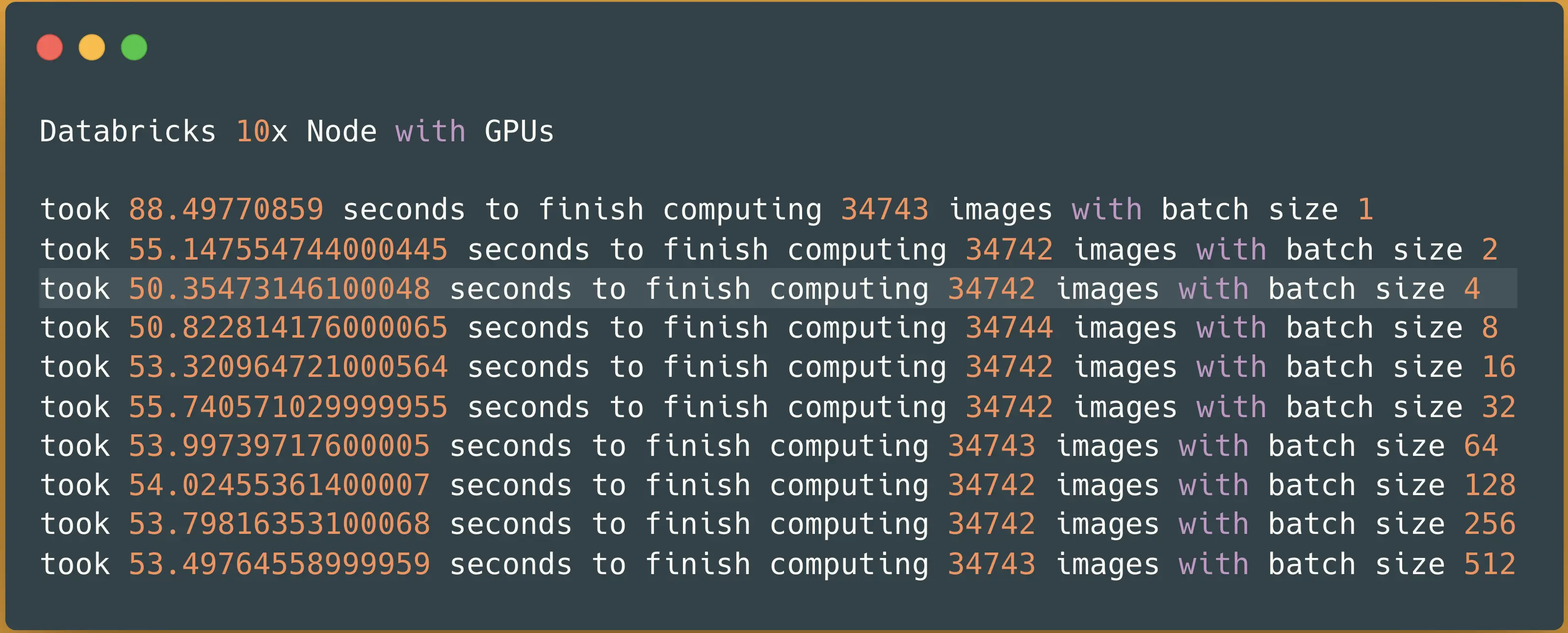
Spark NLP image-classification pipeline on 10x nodes with GPUs — predicting 34742 images
It took less than a minute (51 seconds) to finish predicting classes for over 34743 images. Let’s put them all next to each other and see how we progressed scaling out our Vision Transformer model coming from Hugging Face in the Spark NLP pipeline in Databricks:
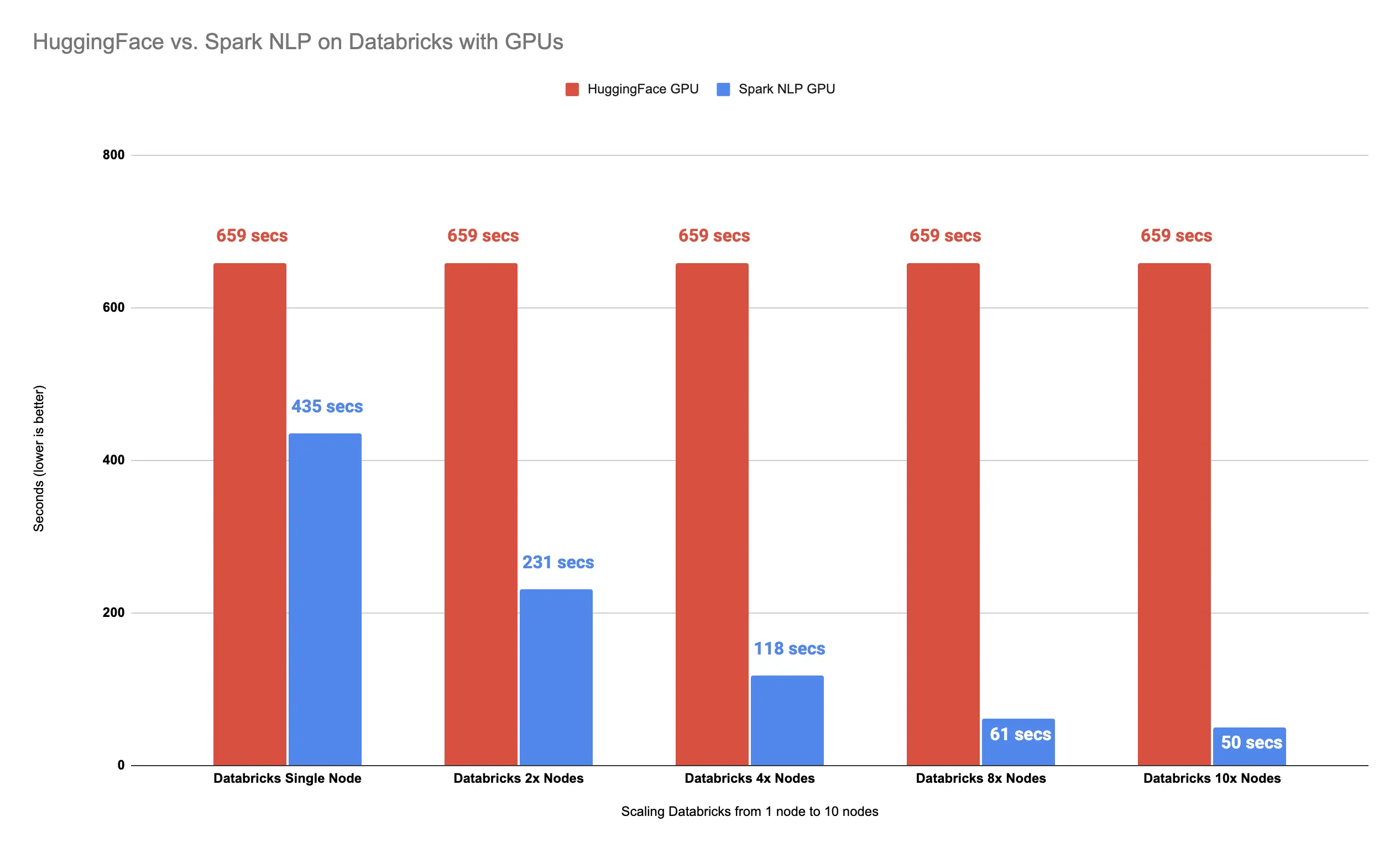
Spark NLP is 1200% faster than Hugging Face with 10x Nodes
And we are done!
We managed to scale out our Vision Transformer model coming from Hugging Face on 10x Nodes by using Spark NLP in Databricks! Our pipeline is now 13x times faster with 1200% performance improvements compared to Hugging Face on GPU.
Let’s sum up all these benchmarks by comparing first the improvements between CPUs, and GPUs, and then how much faster our pipeline can be by going from Hugging Face CPUs to 10x Nodes on Databricks by using Spark NLP on GPUs.
Bringing it all together:
Databricks: Single Node & Multi Nodes
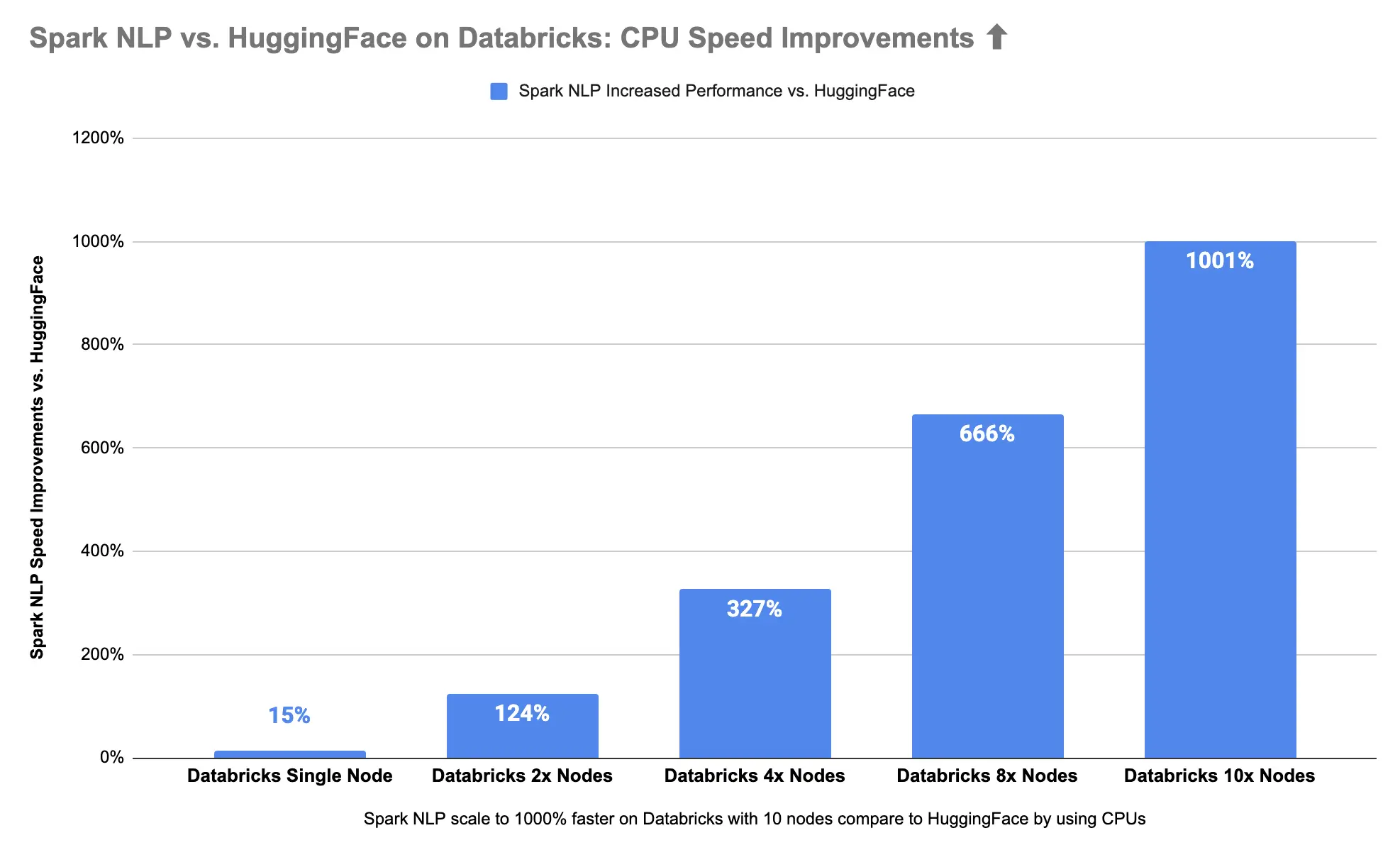
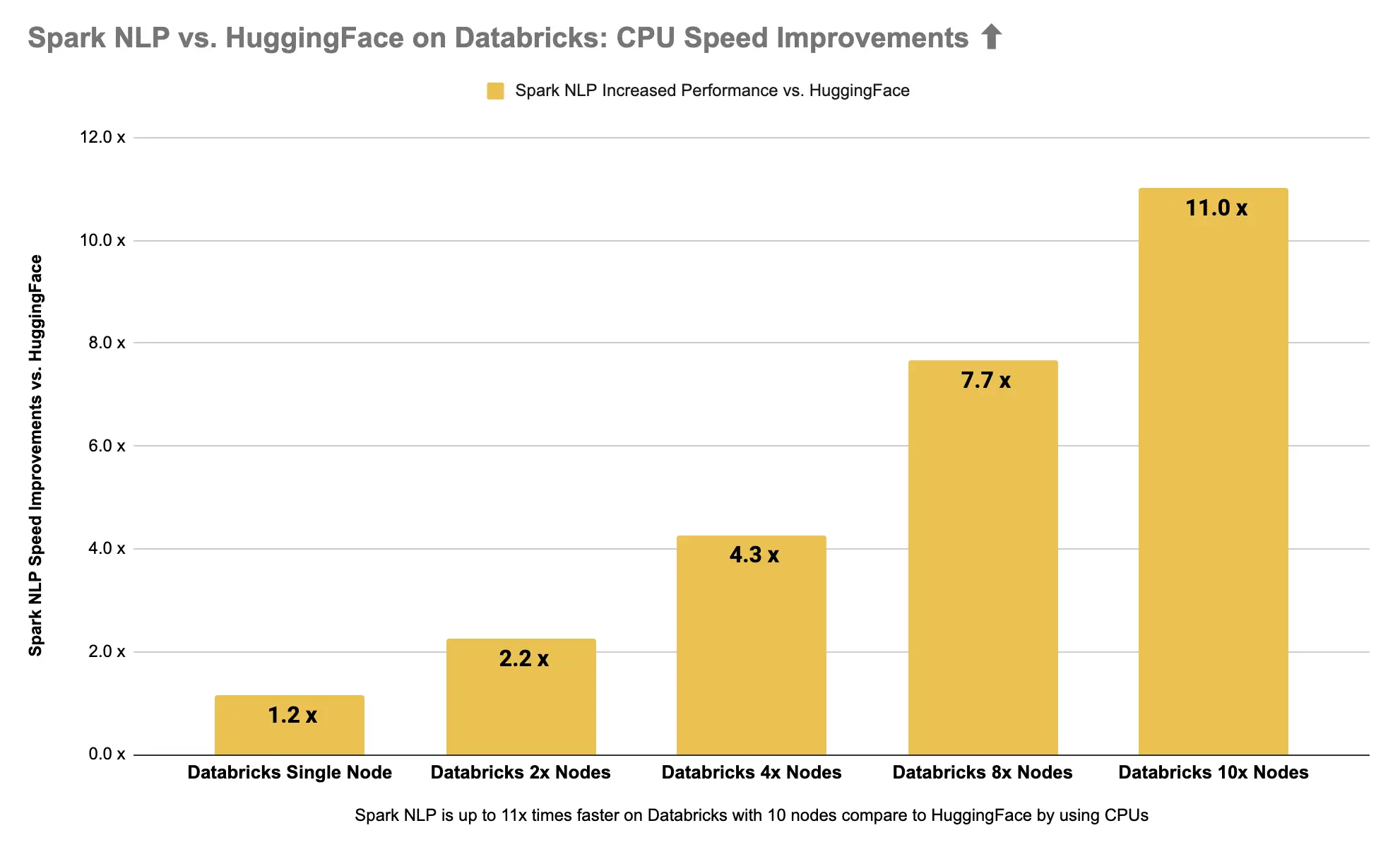
Spark NLP is 11x times (1000%) faster than Hugging Face on CPUs
Spark NLP 🚀 on 10x Nodes with CPUs is 1000% (11x times) faster than Hugging Face 🤗 stuck in a single node with CPUs
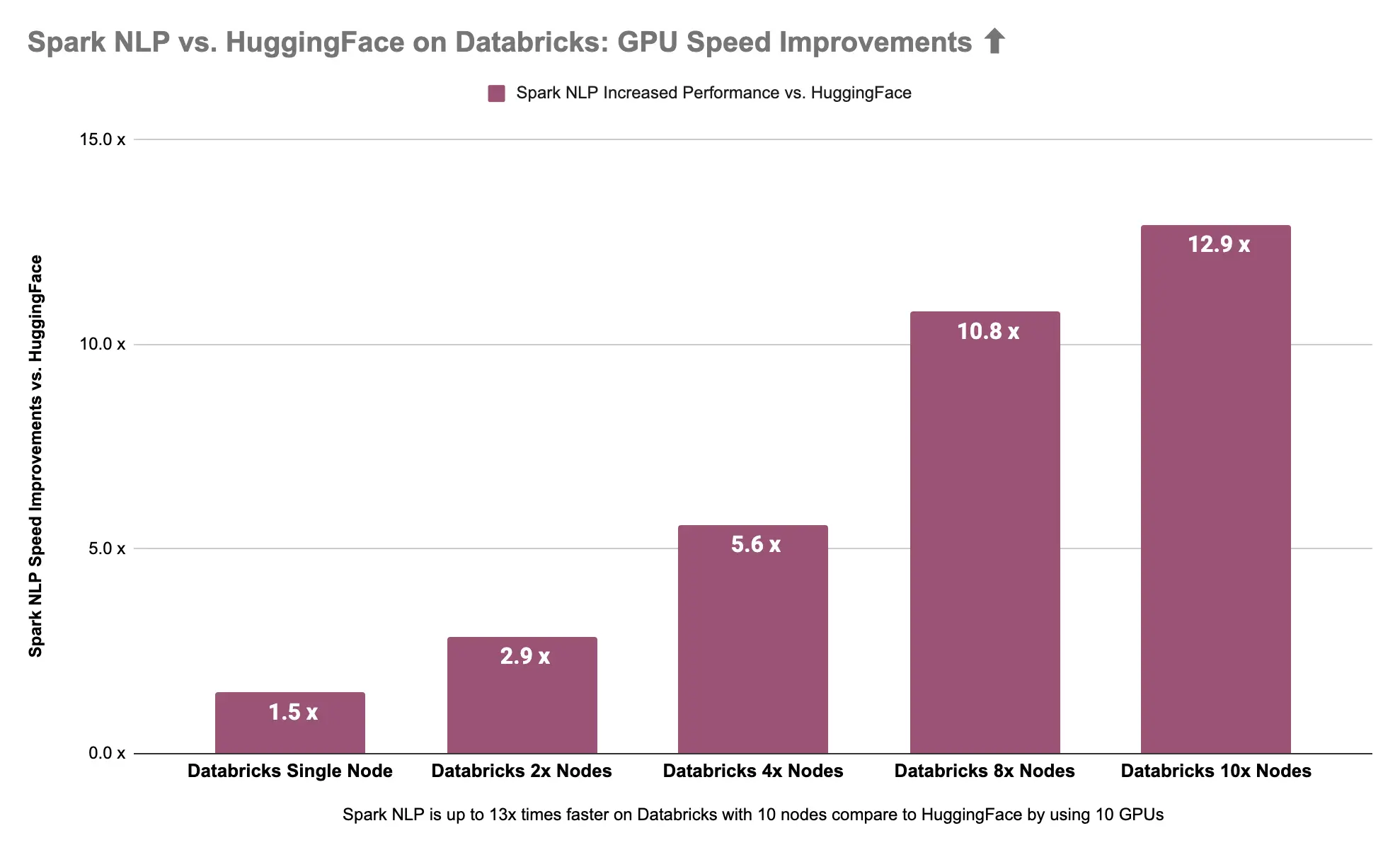
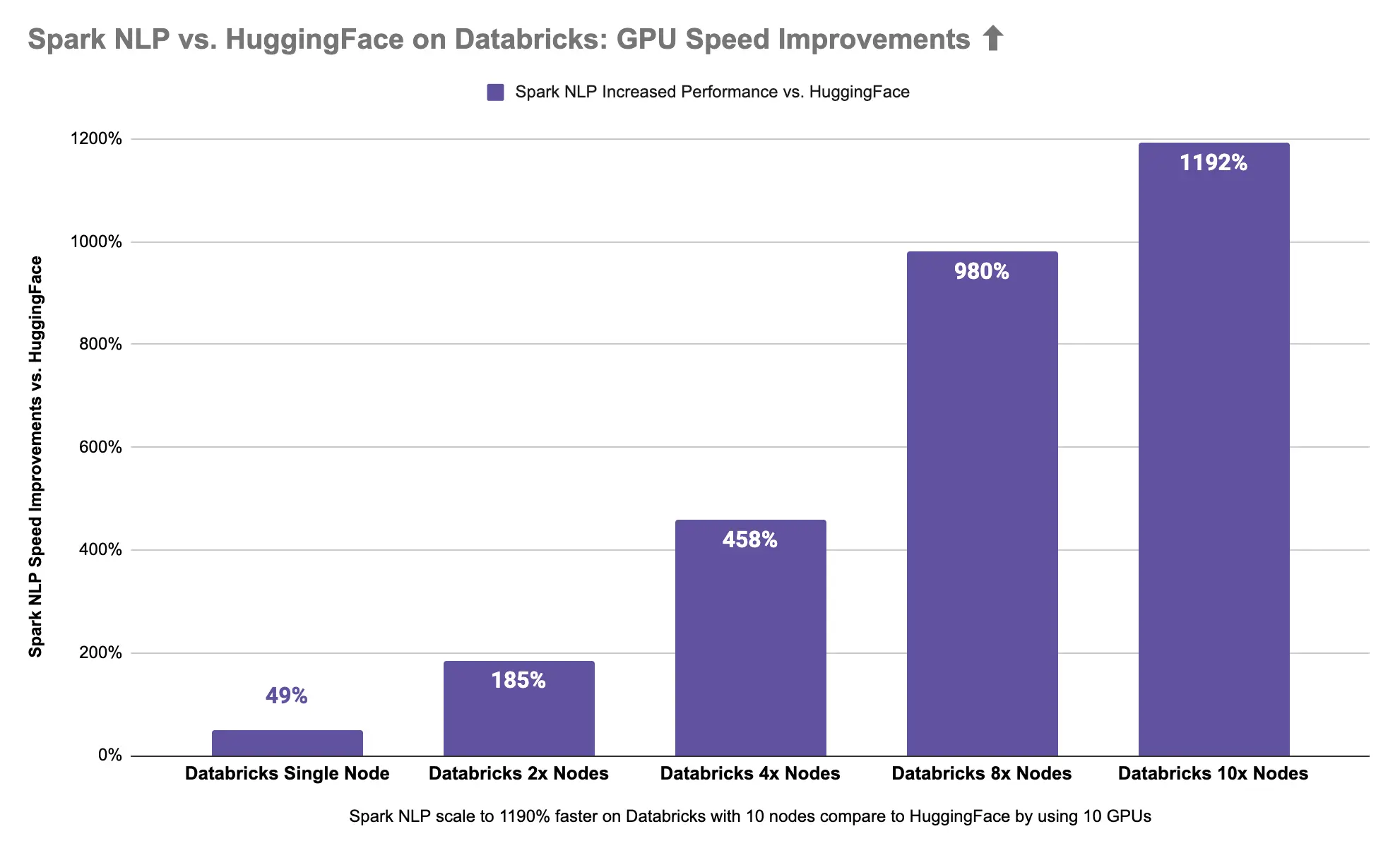
Spark NLP is 13x times (1192%) faster than Hugging Face on GPUs
Spark NLP 🚀 on 10x Nodes with GPUs is 1192% (13x times) faster than Hugging Face 🤗 stuck in a single node with GPU
What about the price differences between our AWS CPU instance and AWS GPU instance? (I mean, you get more if you pay more, right?)
 AWS m5d.8xlarge with CPUs vs. AWS g4dn.8xlarge with 1 GPU and similar specs
AWS m5d.8xlarge with CPUs vs. AWS g4dn.8xlarge with 1 GPU and similar specs
 AWS m5d.8xlarge with CPUs vs. AWS g4dn.8xlarge with 1 GPU and similar specs
AWS m5d.8xlarge with CPUs vs. AWS g4dn.8xlarge with 1 GPU and similar specsOK, so the price seems pretty much the same! With that in mind, what improvements do you get if you move from Hugging Face on CPUs stuck in a single machine to Spark NLP on 10x Nodes with 10x GPUs?
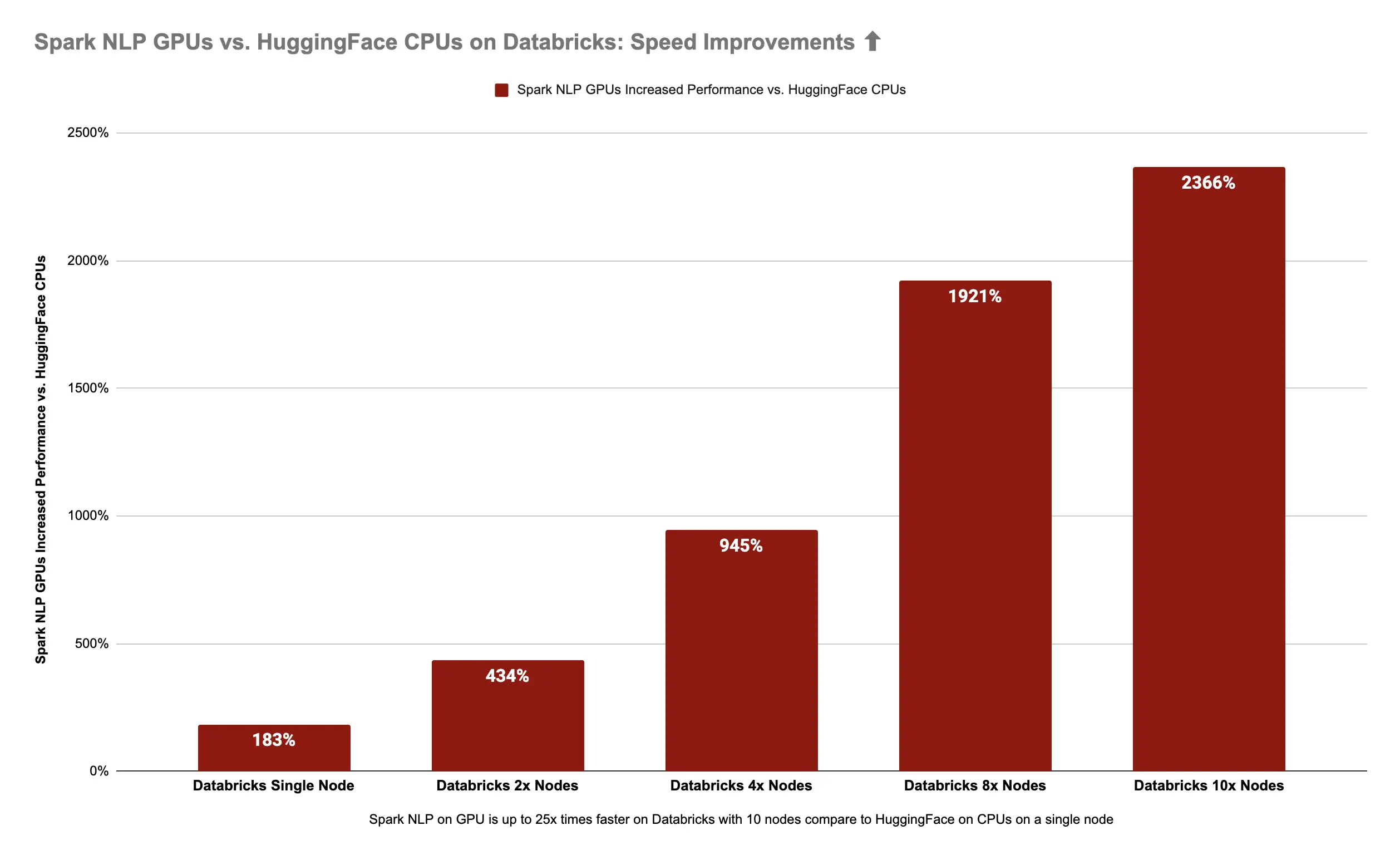
Spark NLP
on GPUs is 25x times (2366%) faster than Hugging Face on CPUs
Spark NLP 🚀 on 10x Nodes with GPUs is 2366% (25x times) faster than Hugging Face 🤗 in a single node with CPUs
Final words
- In the spirit of full transparency, all the notebooks with their logs, screenshots, and even the excel sheet with numbers are provided here on GitHub
- Scaling Spark NLP requires zero code change. Running the benchmarks from a single node Databricks to the 10 nodes meant just re-running the same block of code in the same notebook
- Keep in mind these two libraries come with many best practices to optimize their speed and efficiency in different environments for different use cases. For instance, I didn’t talk about partitions and their relation to parallelism and distributions in Apache Spark. There are many Spark configs to fine-tune a cluster, especially balancing the number of tasks between CPUs and GPUs. Now the question is, would it be possible to speed up any of them within the very same environments we used for our benchmarks? The answer is 100%! I tried to keep everything for both libraries with default values and right out-of-the-box features in favor of simplicity for the majority of the users.
- You may want to wrap Hugging Face and other DL-based Pythonish libraries in a Spark UDF to scale them. This works to a degree as I have done this myself and still do (when there is no native solution). I won’t get into the details of excessive memory usage, possible serialization issues, higher latency, and other problems when one wraps such transformer-based models in a UDF. I would just say if you are using Apache Spark use the library that is natively extending your required features on Apache Spark.
- Throughout this article, I went out of my way to mention Hugging Face on PyTorch and Spark NLP on TensorFlow. This is a big difference given the fact that in every single benchmark done by Hugging Face between PyTorch and TensorFlow, PyTorch was and still is the winner for inference. In Hugging Face, PyTorch just has a much lower latency and it seems to be much faster than TensorFlow in Transformers. The fact that Spark NLP uses the very same TensorFlow and comes ahead in every benchmark compare to PyTorch in Hugging Face is a big deal. Either the TensorFlow in Hugging Face is neglected, or PyTorch is just faster in inference compared to TensorFlow. Either way, I can’t wait to see what happens when Spark NLP starts supporting TorchScript and ONNX Runtime in addition to TensorFlow.
- The ML and ML GPU Databricks runtimes come with Hugging Face installed, that’s pretty nice. But that doesn’t mean Hugging Face is easy to use in Databricks. The Transformer library by Hugging Face doesn’t support DBFS (the native distributed file system of Databricks) or Amazon S3. As you see in the notebooks, I had to download a compressed version of the datasets and extract them to use them. That’s not really how users in Databricks and other platforms in production do things. We keep our data within distributed file systems, there are security measures implemented, and most of them are large enough that cannot be downloaded by a personal computer. I had to download the datasets I already had on DBFS, zip them, upload them on S3, make them public, and re-download them again in the notebooks. A pretty tedious process that could have been avoided if Hugging Face could support DBFS/S3. I think it’s attractive that Databricks comes with Hugging Face pre-installed, but there is more to this than simply running pip install transformerson every single node without being 100% compatible.
References
ViT
- https://arxiv.org/pdf/2010.11929.pdf
- https://github.com/google-research/vision_transformer
- Vision Transformers (ViT) in Image Recognition — 2022 Guide
- https://github.com/lucidrains/vit-pytorch
- https://medium.com/mlearning-ai/an-image-is-worth-16×16-words-transformers-for-image-recognition-at-scale-51f3561a9f96
- https://medium.com/nerd-for-tech/an-image-is-worth-16×16-words-transformers-for-image-recognition-at-scale-paper-summary-3a387e71880a
- https://gareemadhingra11.medium.com/summary-of-paper-an-image-is-worth-16×16-words-3f7f3aca941
- https://medium.com/analytics-vidhya/vision-transformers-bye-bye-convolutions-e929d022e4ab
- https://medium.com/syncedreview/google-brain-uncovers-representation-structure-differences-between-cnns-and-vision-transformers-83b6835dbbac
Hugging Face
- https://huggingface.co/docs/transformers/main_classes/pipelines
- https://huggingface.co/blog/fine-tune-vit
- https://huggingface.co/blog/vision-transformers
- https://huggingface.co/blog/tf-serving-vision
- https://huggingface.co/blog/deploy-tfserving-kubernetes
- https://huggingface.co/google/vit-base-patch16-224
- https://huggingface.co/blog/deploy-vertex-ai
- https://huggingface.co/models?other=vit
Databricks
- https://www.databricks.com/spark/getting-started-with-apache-spark
- https://docs.databricks.com/getting-started/index.html
- https://docs.databricks.com/getting-started/quick-start.html
- See the best of DATA+AI SUMMIT 2022
- https://www.databricks.com/blog/2020/05/15/shrink-training-time-and-cost-using-nvidia-gpu-accelerated-xgboost-and-apache-spark-on-databricks.html
Spark NLP
- Spark NLP GitHub
- Spark NLP Workshop(Spark NLP examples)
- Spark NLP Transformers
- Spark NLP Models Hub
- Speed Optimization & Benchmarks in Spark NLP 3: Making the Most of Modern Hardware
- Hardware Acceleration in Spark NLP
- Serving Spark NLP via API: Spring and LightPipelines
- Serving Spark NLP via API (1/3): Microsoft’s Synapse ML
- Serving Spark NLP via API (2/3): FastAPI and LightPipelines
- Serving Spark NLP via API (3/3): Databricks Jobs and MLFlow Serve APIs
- Leverage deep learning in Scala with GPU on Spark 3.0
- Getting Started with GPU-Accelerated Apache Spark 3
- Apache Spark Performance Tuning
- Possible extra optimizations on GPUs: RAPIDS Accelerator for Apache Spark Configuration



