






















































State-of-the-art performance for table-based question answering tasks

Question answering is a field of natural language processing that involves developing algorithms and systems capable of answering questions posed in natural language. TAPAS (Table Parser) is a transformer-based question answering model that is specifically designed to handle natural language questions over tabular data.
Question answering is an important task in natural language processing (NLP) that involves developing systems capable of answering questions posed in natural language. The goal of QA in NLP is to build systems that can understand and reason about natural language questions, and provide accurate and relevant answers.
Natural language questions are questions that are phrased in a way that humans naturally use to communicate with each other in spoken or written language. These types of questions are not structured according to any formal grammar or syntax rules, but rather reflect the way that people actually speak or write in everyday life.
Natural language questions can take many different forms, including open-ended questions that ask for information or opinions (“What do you think about this idea?”), closed-ended questions that require a specific answer (“Do you like this color?”), and rhetorical questions that are meant to make a point rather than elicit a response (“Isn’t that just ridiculous?”).
Question answering (QA) systems have diverse applications in various fields, including customer service, healthcare, education, e-commerce, legal research, news and journalism, and personal assistants. These systems can assist in retrieving information from databases, answering FAQs, providing feedback and explanations, supporting self-directed learning, finding products, summarizing news articles, searching through legal documents, and helping with everyday tasks. Overall, QA systems can increase efficiency, accuracy, and accessibility, making information more readily available and easier to access for everyone.
TAPAS (Table-based Pretraining and Sequential reasoning for Question Answering) is a language model designed for answering natural language questions using tables as the primary source of information. The model was introduced in an academic paper by Google AI researchers in 2020 and is based on the idea of “semantic parsing”, which involves converting natural language questions into executable queries that can be executed on a structured data source such as a table.
TAPAS makes minimal predictions by selecting a subset of the table cells and a possible aggregation operation to be executed on top of them. Consequently, TAPAS can learn operations from natural language, without the need to specify them in some formalism. This is implemented by extending BERT’s architecture with additional embeddings that capture tabular structure, and with two classification layers for selecting cells and predicting a corresponding aggregation operator.
TAPAS is designed to answer natural language questions that require reasoning over structured data in tables, such as “What is the total revenue for each product category?” or “Which countries have a population greater than 100 million?” The model takes a table and a natural language question as input and produces an answer as output.
One of the unique features of TAPAS is its ability to perform multi-faceted analysis of table data. It can handle not only basic question-answering tasks, such as answering simple questions like “What is the capital of France?”, but also more complex tasks, such as answering “What are the three most populous cities in Europe?”
In this post, you will learn how to use Spark NLP to perform question answering using tables by TAPAS. We also have another post for MultiDocumentAssembler and Transformer-based models for question answering.
Let us start with a short Spark NLP introduction and then discuss the details of question answering techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library for Python in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark comes with 17,800+ pretrained NLP models and pipelines in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
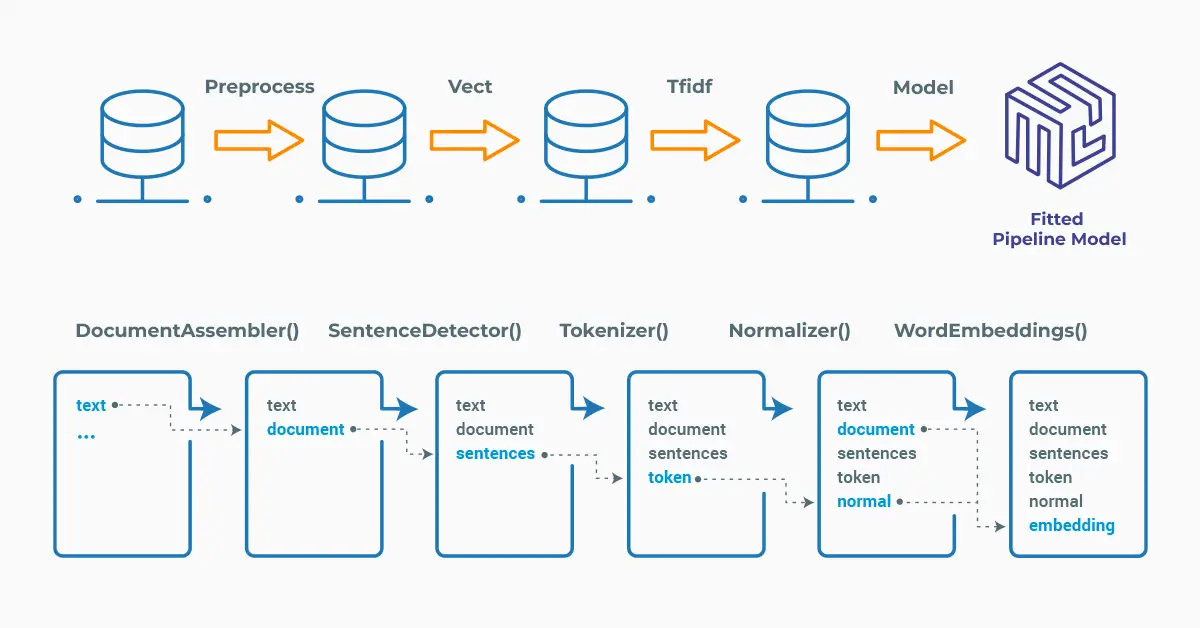
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
TapasForQuestionAnswering
TapasForQuestionAnswering annotator is designed to perform question-answering tasks over tabular data, using TAPAS (Table Parsing for Question Answering) models.
The annotator takes as input a Spark DataFrame containing tabular data and a list of natural language questions, and outputs a new DataFrame containing the answers to these questions. It first parses the tabular data into a format that can be processed by the TAPAS model, and then generates structured queries from the natural language questions using a transformer-based language model. The generated queries are then executed over the parsed table, and the results are returned as answers to the original questions.
TapasForQuestionAnswering annotator is a powerful tool for data analysis and business intelligence, as it allows users to quickly and efficiently extract information from large tables using natural language questions. Its integration with the Spark NLP library also makes it easy to incorporate into larger data processing pipelines, allowing for seamless integration with other NLP and machine learning components.
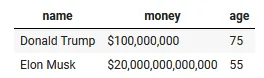
Let’s create files using the table below and then make a Spark dataframe.
json_data = """
{
"header": ["name", "money", "age"],
"rows": [
["Donald Trump", "$100,000,000", "75"],
["Elon Musk", "$20,000,000,000,000", "55"]
]
}
"""
queries = [
"Who earns less than 200,000,000?",
"Who earns 100,000,000?",
"How much money has Donald Trump?",
"How old are they?",
"How much money have they total?",
"Who earns more than Donald Trump?"
]
data = spark.createDataFrame([[json_data, " ".join(queries)]]).toDF("table_json", "questions")
We will use the MultiDocumentAssembler annotator to assemble the table and questions together. Then, use the SentenceDetector and TableAssembler annotators to parse text into tabular representation.
# Import the required modules and classes
from sparknlp.annotator import TapasForQuestionAnswering, SentenceDetector
from sparknlp.base import MultiDocumentAssembler, TableAssembler
from pyspark.ml import Pipeline
from pyspark.sql import functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = MultiDocumentAssembler() \
.setInputCols("table_json", "questions") \
.setOutputCols("document_table", "document_questions")
# Step 2: Getting the sentences
sentence_detector = SentenceDetector() \
.setInputCols(["document_questions"]) \
.setOutputCol("questions")
# Step 3" Get the tables
table_assembler = TableAssembler()\
.setInputCols(["document_table"])\
.setOutputCol("table")
We will use two different TAPAS QA pretrained models;
table_qa_tapas_base_finetuned_wtq, which was trained on the WTQ, Wiki Table Questions by Stanford University dataset.
table_qa_tapas_base_finetuned_sqa, which was trained on the SQA, Sequential Question Answering by Microsoft dataset.
# WTQ TAPAS model
tapas_wtq = TapasForQuestionAnswering\
.pretrained("table_qa_tapas_base_finetuned_wtq", "en")\
.setInputCols(["questions", "table"])\
.setOutputCol("answers_wtq")
# SQA TAPAS model
tapas_sqa = TapasForQuestionAnswering\
.pretrained("table_qa_tapas_base_finetuned_sqa","en")\
.setInputCols(["questions", "table"])\
.setOutputCol("answers_sqa")
#Define pipeline
pipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
table_assembler,
tapas_wtq,
tapas_sqa
])
# Fit and transform data
model = pipeline.fit(data)
result = model.transform(data)
First let’s see the result dataframe for the model trained on the Sequential Question Answering — SQA dataset:
result.select(F.explode(result.answers_sqa)).show(truncate=False)

Now, let’s check the result dataframe for the model trained on the Wiki Table Questions —WTQ dataset:
result.select(F.explode(result.answers_wtq)).show(truncate=False)

Let’s explode to see the question and the results for both models in detail to make a comparison:
result.select(F.explode(F.arrays_zip(result.questions.result,
result.answers_sqa.result,
result.answers_wtq.result)).alias("cols"))\
.select(F.expr("cols['0']").alias("question"),
F.expr("cols['1']").alias("answer_sqa"),
F.expr("cols['2']").alias("answer_wtq")).show(truncate=False)

WTQ models are trained to return aggregation results, as you can see on the third column.
SQA models do not return any aggregation operation, just the answer in human language.
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library.
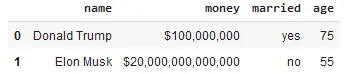
We will first create the array of context;
import pandas as pd
context_df = pd.DataFrame({
'name':['Donald Trump','Elon Musk'],
'money': ['$100,000,000','$20,000,000,000,000'],
'married': ['yes','no'],
'age' : ['75','55'] })
context_df
and the questions:
questions = [
"Who earns less than 200,000,000?",
"Who earns more than 200,000,000?",
"Who earns 100,000,000?",
"How much money has Donald Trump?",
"Who is the youngest?",
]
questions
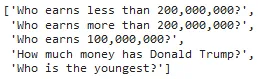
Now we combine both to a tuple and we are done!
tapas_data = (context_df, questions)
To run TAPAS Question Answering with one line of code, we can simply run the following code using a wtq model:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
answers_wtq = nlp.load('en.answer_question.tapas.wtq.large_finetuned').predict(tapas_data)
answers_wtq[['sentence', 'tapas_qa_UNIQUE_answer']]

After using the one-liner model, the result shows the answer to all the questions
There are many more TAPAS models for question answering. Please check the notebook for many more models.
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
For additional information, please consult the following references.
- Documentation : MultiDocumentAssembler, TapasForQuestionAnswering
- Python Doc : MultiDocumentAssembler, TapasForQuestionAnswering
- Scala Doc : MultiDocumentAssembler, TapasForQuestionAnswering
- For extended examples of usage, see the notebooks for MultiDocumentAssembler, TapasForQuestionAnswering.
Conclusion
In this article, we tried to get you familiar with TAPAS (Table Parsing for Question Answering), which is a state-of-the-art language model that has shown great promise in answering complex questions posed over tabular data. John Snow Labs Models Hub also provides a variety of pre-trained TAPAS models, which provide accurate and efficient answers to complex questions.
With its ability to efficiently parse tables and process natural language questions, TAPAS has significantly improved the accuracy and efficiency of question answering over tabular data. Its innovative approach of combining transformer-based language models with structured query generation techniques has made it a valuable tool for various applications, including data analysis, business intelligence, and decision-making processes.




