






















































Automatic Data Insight extraction from documents is a challenging task, and John Snow Labs Spark-OCR is using several different NLP, Computer Vision, and Spark techniques to enhance the user experience, building utilities for the consumers and enhancing efficiency and ease for extracting intelligent data Insights. VisualDocumentNERv21 is a sparkML model developed by John Snow Lab’s Spark-OCR for efficient Visual Document Named Entity Recognition (NER). The process of visual document understanding is quite simple: you give in a PDF document or image and BOOM; you get each word assigned with a label using PDF OCR like it can be a medical entity or anything you want. With JSL Spark-OCR, multiple input documents can be processed to classify each word in the provided input to the custom-defined classes.
Data Preparation
VisualDocumentNERv21 also provides support for fine-tuning this model to perform NER on a custom-labeled dataset. The users can also define their custom classes and can tag each word, which can then be fed to the VIsualDocumentNERv21. John Snow Lab’s annotation tool can be utilized to perform data labeling, where you can specify the input format of your choice, and then with the John Snow Lab’s Annotation Toolkit, you can annotate the dataset and export that dataset to be used with the VisualDocumentNERv21. Here in the dataset annotation, the irrelevant words will be automatically annotated as OTHERS label, the user have to annotate only the words which belong to any specific class.
The data annotated and exported from the Generative AI Lab (see the documentation) is first processed with the dataloader() method which will create a spark dataframe that can be used by the proceeding stages to perform classification/tagging of words. This will prepare all the data for training in the spark_dataframe. The following code block illustrates how to call this method.

Reader Method
In the above code snippet, result.json and images_folder is the data that is exported from the annotation lab.
Training For Correct Visual Document Understanding
With VisualDocumentNERv21, you can train your model by calling the fit method. For training, the fit method is available. For training, the base model has to be defined, which can be defined using 𝑙𝑜𝑎𝑑𝐻𝑢𝑔𝑔𝑖𝑛𝑔𝐹𝑎𝑐𝑒𝑀𝑜𝑑𝑒𝑙() or 𝑙𝑜𝑎𝑑() method. In 𝑙𝑜𝑎𝑑𝐻𝑢𝑔𝑔𝑖𝑛𝑔𝐹𝑎𝑐𝑒𝑀𝑜𝑑𝑒𝑙, only layoutLMv2 variants are supported. The VisualDocumentNERv21 has a number of important parameters for training, which are as follows.
batchSize: set the training batch size.
shuffleBatchTraining: option to either shuffle the training batch or not.
numTrainEpochs: set the number of training epochs.
Whitelist: select which class words should be received.
Labels: define the class labels for training the model, it should be the same as the annotation Lab’s labels.
After defining all the important parameters, the fit() method can be called. The `fit` method takes as input a dataframe, developed by spark_ocr pipeline, which is the output from 𝑑𝑎𝑡𝑎𝐿𝑎𝑏𝑒𝑙𝑒𝑟() method. The fit method will provide(return) an instance method of VisualDocumentNERv21, which can be reused again to perform inferences on single or multiple images. These parameters and the fit method can be used as per the following code block.
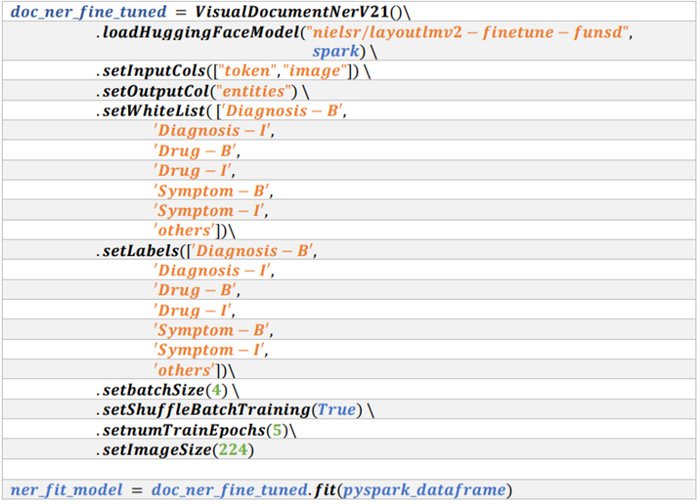
Training Code
Model Save and Load
The models trained can be saved and loaded with the following methods. This utility gives users an option to save and use their trained models, or fine-tune their trained models on any other dataset.

Save and Load
Inference
To use the VisualDocumentNERv21 for inference and obtain tagging on your defined text dataset during the visual document understanding process is illustrated in this section. Following are the steps to use the model and perform word_tagging.
Read the input
Convert the inputs to images
Apply HOCR
HOCR to Tokenizer
Apply VisualDocumentNERv21
Visualize the inference results
Input can be read with the spark read method. And on the basis of the input, you can select any of the JSL spark-ocr transformer models from a wide range of models provided by JSL, to convert the input to image type. Moving forward, these images are applied HOCR and then tokenized. This process is also performed from the JSL spark-ocr transformer models. Then, VisualDocumentNERv21 is applied to obtain the inference. The inference which is tagging of each word in the document is then saved in the spark dataframe, the tagging of words can also be selected by using the setWhiteList(List[str]) method. This will produce results for only those words which are classified as lying in the classes mentioned in the setWhiteList method. Finally, the visualize method can be used to visualize the results obtained via the VisualDocumentNERv21 inference. The results are visualized in an image, where each word is surrounded by a bounding box, and its class is written over the top. Only those word’s bounding boxes are shown, which are mentioned in the setWhiteList(List[str]) method. The following code block explains how to perform the inference using VisualDocumentNerV21 on image input.
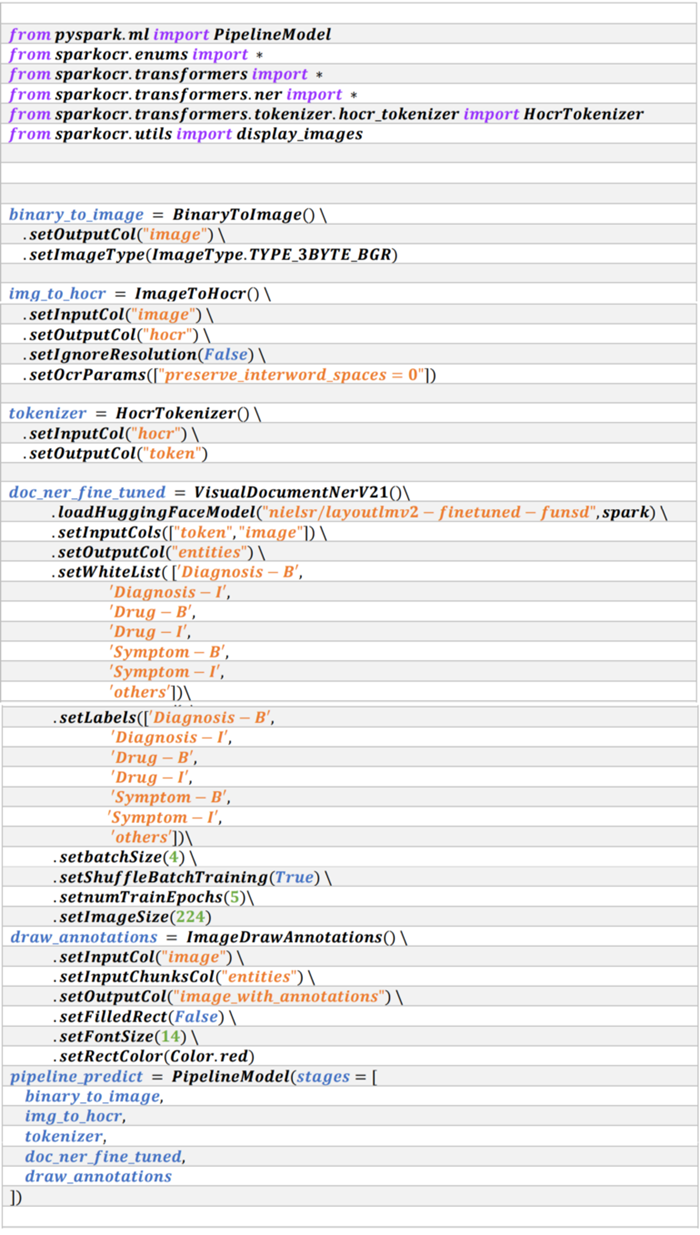
Inference
Sample Results Of Using A Tool For Visual Document Understanding

John Snow Labs is a pioneer in providing outclass visual document understanding and optical character recognition solutions to our noble customers. The complete notebook is available at: https://github.com/JohnSnowLabs/spark-ocr-workshop/blob/master/jupyter/FormRecognition/SparkOcrFormRecognitionFineTuning.ipynb




