
























































What is multimodal de-identification and why is it necessary in healthcare?
Healthcare data is inherently multimodal. It spans unstructured clinical notes, structured lab results, scanned PDFs, DICOM medical images, and more. Traditional de-identification systems often fail to apply consistent logic across these formats, which can result in fragmented or incomplete data processing.
Multimodal de-identification solves this challenge by ensuring that the same PHI is identified and transformed consistently across all formats. Whether a date of birth appears in a typed note, a scanned discharge summary, or a DICOM file, it is obfuscated in the same way. This consistency supports longitudinal studies, outcome tracking, and AI training across datasets with varying structures.
How does John Snow Labs achieve multimodal de-identification?
The John Snow Labs Healthcare NLP integrates OCR, metadata parsing, and semantic entity recognition to ensure PHI is caught wherever it appears. This includes:
- Extracting text from scanned documents and PDFs
- Identifying PHI in structured tables and CSVs
- Parsing DICOM headers and overlays in medical imaging
- Linking all of these through a common de-identification pipeline
As a result, researchers and developers can build and analyze datasets that span multiple modalities while staying fully compliant.
Why is multimodal support critical for AI innovation?
Healthcare AI systems rely on diverse data inputs to learn effectively. For example, an AI model predicting cancer recurrence might need pathology reports, imaging data, genetic information, and treatment notes. If de-identification is not harmonized across these formats, the resulting data may become disjointed or unusable.
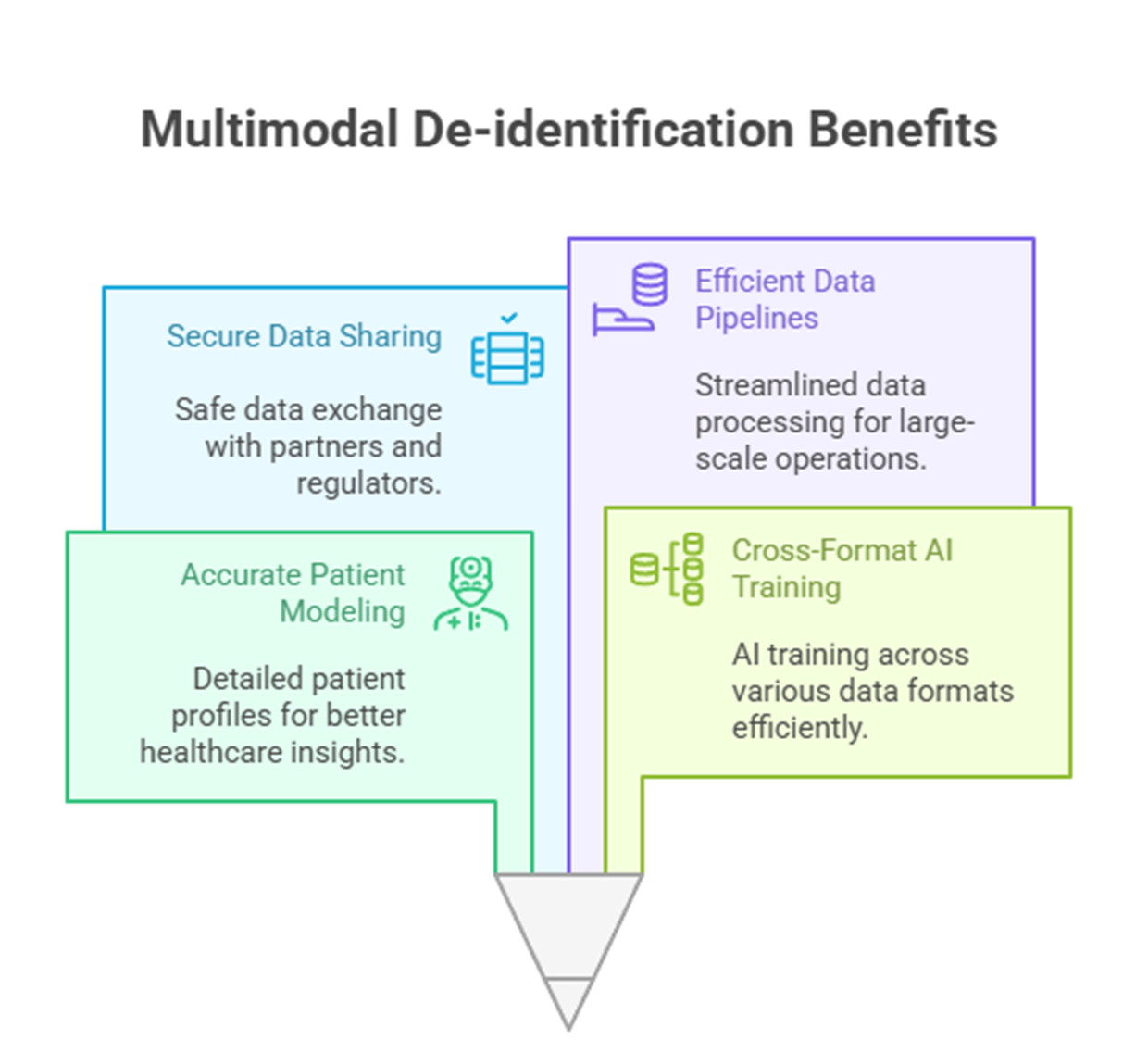
Multimodal de-identification enables:
- Accurate, full-spectrum patient modeling
- Cross-format AI training
- Secure sharing with collaborators or regulatory bodies
- Efficient data pipeline management at scale
How does this approach compare to other de-identification tools?
John Snow Labs’ integrated pipeline not only outperforms top platforms in accuracy but also supports diverse file types natively. Its recent benchmark scores highlight a 0.98 F1 average in PHI removal compared to GPT-4.5’s 0.91. Furthermore, it achieves this at over 100 times less cost per million documents.
How can I learn more?
Dr. Youssef Mellah shared these insights in a detailed webinar focused on scalable, privacy-compliant de-identification. He provided a clear framework for implementing multimodal processing, complete with live demonstrations and practical guidance.
FAQs
What does multimodal de-identification cover?
It addresses PHI across multiple formats including unstructured notes, structured CSVs, scanned PDFs, and DICOM medical images.
Can the same de-identification logic be applied across formats?
Yes. John Snow Labs ensures that the same PHI element (like a birth date or hospital name) is obfuscated identically across all formats, maintaining consistency.
How does this help in AI model training?
Multimodal consistency ensures that diverse data types feed into AI models uniformly, improving training outcomes and accuracy.
Is DICOM metadata handled during de-identification?
Yes. The system parses and de-identifies both image overlays and metadata fields in DICOM files, ensuring complete protection.
Does this support scanned documents like handwritten notes?
Yes. OCR technology is used to extract and de-identify text from scanned images and non-selectable PDFs.
Supplementary Q&A
Can multimodal de-identification be integrated with existing EHR systems?
Yes. The John Snow Labs pipeline is designed for integration with EHR platforms and data lakes via Healthcare NLP, allowing organizations to process data in place without migrating systems.
How does multimodal de-identification reduce risk for healthcare organizations?
By automating PHI removal across all data types, organizations lower the risk of accidental disclosures, strengthen compliance posture, and streamline audit preparation.




