A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
We’re happy to announce the release of the Annotation Lab 1.7 which brings several performance improvements and a more consistent and easy-to-use interface, an improved general look & feel, and better behavior and application responsiveness.
Preannotation and Models Training
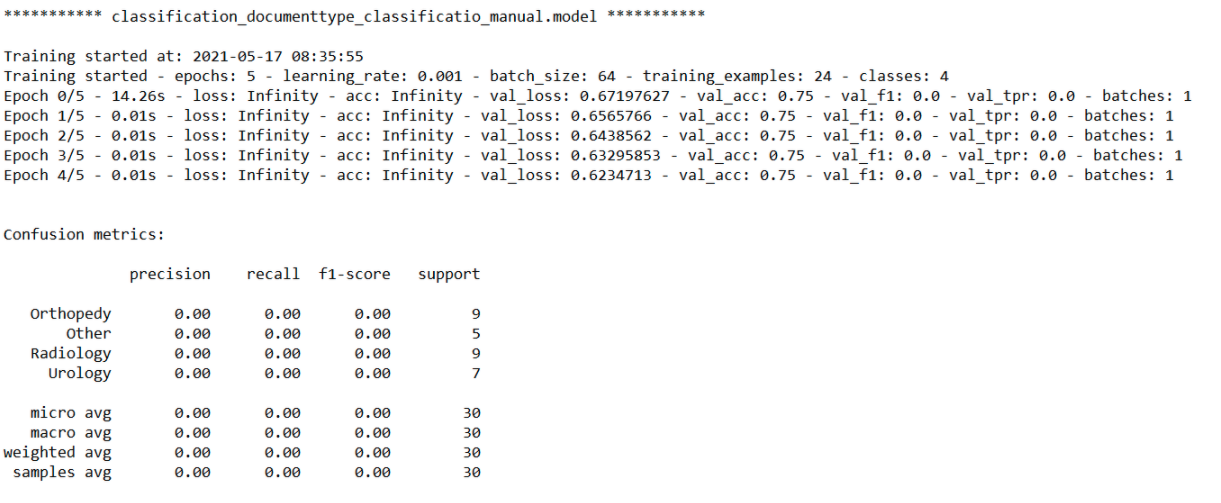
Classification training logs now contain the Confusion matrix along with other metrics.
Preannotation of large documents was not supported for Classification and Assertion Status projects in the previous release. With the release of 1.7, users are able to use the preannotation feature for any task belonging to a NER, Classification, or Assertion Status project, regardless of how large it is.
More dialog boxes and pop-ups for a better workflow
Going forward we will continue to improve consistency on the UX side for confirmation dialog boxes, pop-ups, message boxes, etc.
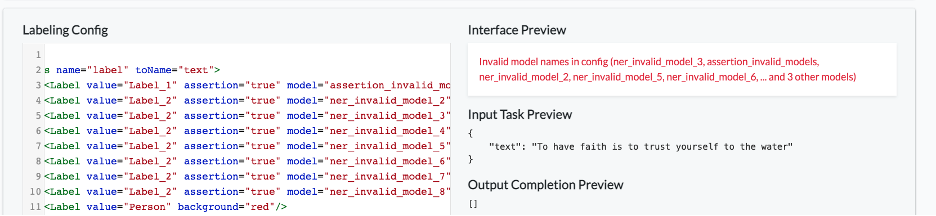
Until now, a reference to an invalid model name in the Labeling Configuration would generate a general error message. In version 1.7 the exact list of invalid models is provided in the error message.
Improved User Experience
The labeling page was not displaying the task content when invalid/incompatible tasks were imported for a project – for example, Classification tasks imported into a NER type of project. Annotation Lab 1.7 improves the user experience in this situation by showing a proper and more detailed error message.
When deploying multiple models at a time, the preannotation status was not showing properly. We have fixed that bug.
It’s now easier to store and transfer data
To improve the efficiency of the data transfer/storage, we have removed unwanted and deprecated fields from different data structures. One such example is the exported completions.

Other smaller features included in this release
- Remove unwanted fields in import/export
- Add confusion matrix in training logs
- Ask the user for model deployment when a user saves the project configuration on the setup page
- Support Large Document Preannotation for Classification and Assertion Status models
- UI Improvements
- Create a minified file for the Custom CSS files
- Validate assertion models based on name
- Return a list of invalid models along with Label in error message while validating assertion Labels
- Limit the task title max length while import new tasks
- Change alert message when user remove projects from a group
- Filter not working properly for Spark NLP pipeline List on Setup Page
- Consistent alert messages and popup dialogs