Spark NLP for Healthcare
There is a growing need for automated text mining of Electronic health records (EHRs) in order to find clinical indications that new research points to. EHRs are the primary source of information for clinicians tracking the care of their patients. Information fed into these systems may be found in structured fields for which values are inputted electronically (e.g. laboratory test orders or results)but most of the time information in these records is unstructured making it largely inaccessible for statistical analysis. These records include information such as the reason for administering drugs, previous disorders of the patient or the outcome of past treatments, and they are the largest source of empirical data in biomedical research, allowing for major scientific findings in highly relevant disorders such as cancer and Alzheimer’s disease. Despite the growing interest and groundbreaking advances in NLP research and NER systems, easy to use production-ready models and tools are scarce in the biomedical and clinical domains and it is one of the major obstacles for clinical NLP researchers to implement the latest algorithms into their workflow and start using immediately. On the other hand, NLP tool kits specialised for processing biomedical and clinical text, such as MetaMap and cTAKES typically do not make use of new research innovations such as word representations or neural networks discussed above, hence producing less accurate results.
We introduce Spark NLP for Healthcare as the one-stop solution to address all these issues [2].
 Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
 Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Comparison Setup and Methodology
As stated above, Spark NLP for Healthcare can extract and analyse 400+ different clinical & biomedical entities via 100+ NER models, 60+ Entity Resolution models from 10+ medical terminologies (ICD10, CPT-4, UMLS etc.), 50+ Relation Extraction models, 10+ Assertion Status Detection models and 40+ De-Identification models and pipelines. On the contrary, the number of entities and features of the major cloud providers are quite limited. The list of entities that can be extracted from these services vs what Spark NLP can extract can be seen in the image in the next section.
That is, Spark NLP can extract entities at a more granular level and it is tricky to make a 1:1 mapping to evaluate these services fairly. The cloud services also do not support all the taxonomies when it comes to entity resolution (only 3–4 different terminologies are supported at most) and details are not clear from their documentation. That is why we decided to create a set of entities and medical terminologies to run this comparison.
For this study, we had to find an open-source dataset for the reproducibility concerns and mtsamples.com looked like a perfect venue. MTSamples.com is designed to give you access to a big collection of transcribed medical reports and contains sample transcription reports for many specialities and different work types. At the time of writing this article, mtsamples.com hosts 5,003 Samples in 40 types. For this study, we randomly picked 8,000 clinical notes from various types and have human annotators (physicians having substantial experience in each domain) annotate all for NER and entity resolution tasks
Being the only medical terminologies supported by 3 major cloud providers at the same time, we picked ICD10CM, SNOMED CT, and RxNorm terminologies to do the benchmarks. We asked clinical annotators to assign top-5 most appropriate codes from each terminology for each entity that makes sense. For instance, if there is an entity such as ‘ diabetes’ (labelled as a clinical condition), they assigned the most probable five ICD10CM codes (E11, E10, E23.2, Z83.3 etc.) for that entity given the entire context (sentence context). If it’s a medication-related entity such as ‘metformin 100 mg’, they assigned the top five RxNorm codes (861024, 861026, 861025 etc.) for that drug.
Comparison Results
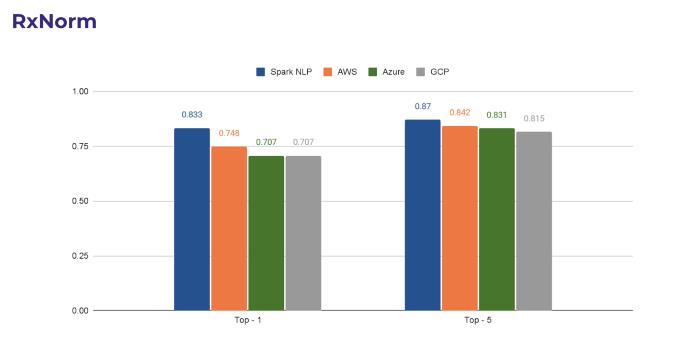
Let’s start with RxNorm, a common drug terminology. RxNorm provides normalised names for clinical drugs and links its names to many of the drug vocabularies commonly used in pharmacy management and drug interaction software.
As you can see from the following chart, Spark NLP can match the top-1 code 83% of the time while its closest competitor AWS can only match 75% of the time. When it comes to matching top-5 terms, the difference between Spark NLP and others narrows down but Spark NLP still leads by a small margin (3%).
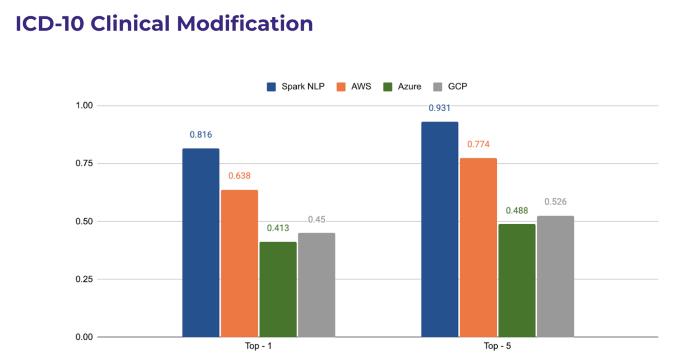
Then we can investigate one of the most popular terminologies out there: ICD10-CM (international classification of diseases). It is a common code schema used in nearly every language via translation and is a highly practical normalisation method, especially for billing and reimbursement purposes between hospitals and insurance providers.
As you can see from the following chart, Spark NLP can match the top-1 code 82% of the time while its closest competitor AWS can only match 64% of the time. When it comes to matching top-5 terms, the difference between Spark NLP and others narrows down but Spark NLP still leads by a large margin (16%) compared to the next best one. The reason for such a large margin can be attributed to the contextual sBert based clustering technique that Spark NLP for Healthcare adopts via various weighting regimes to let the model maps to the right code by checking the entire context that the entity lives in.
Then we can investigate one of the most popular terminologies out there: ICD10-CM (international classification of diseases). It is a common code schema used in nearly every language via translation and is a highly practical normalisation method, especially for billing and reimbursement purposes between hospitals and insurance providers.
As you can see from the following chart, Spark NLP can match the top-1 code 82% of the time while its closest competitor AWS can only match 64% of the time. When it comes to matching top-5 terms, the difference between Spark NLP and others narrows down but Spark NLP still leads by a large margin (16%) compared to the next best one. The reason for such a large margin can be attributed to the contextual sBert based clustering technique that Spark NLP for Healthcare adopts via various weighting regimes to let the model maps to the right code by checking the entire context that the entity lives in.
For instance, imagine a sentence talking about a historical condition of gestational diabetes. If NER returns only ‘gestational diabetes’ and we try to map with ICD10, it will map to O24.4 which corresponds to a 4-char code for‘gestational diabetes’. However, since Spark NLP entity resolution algorithm can read the entire sentence and grab the context, even if NER returns only ‘gestational diabetes’, the embeddings representation of that entity will contain information regarding ‘historical’ condition and it will map to Z86.32 that corresponds to 5-char code (a much granular level) for ‘personal history of gestational diabetes’.
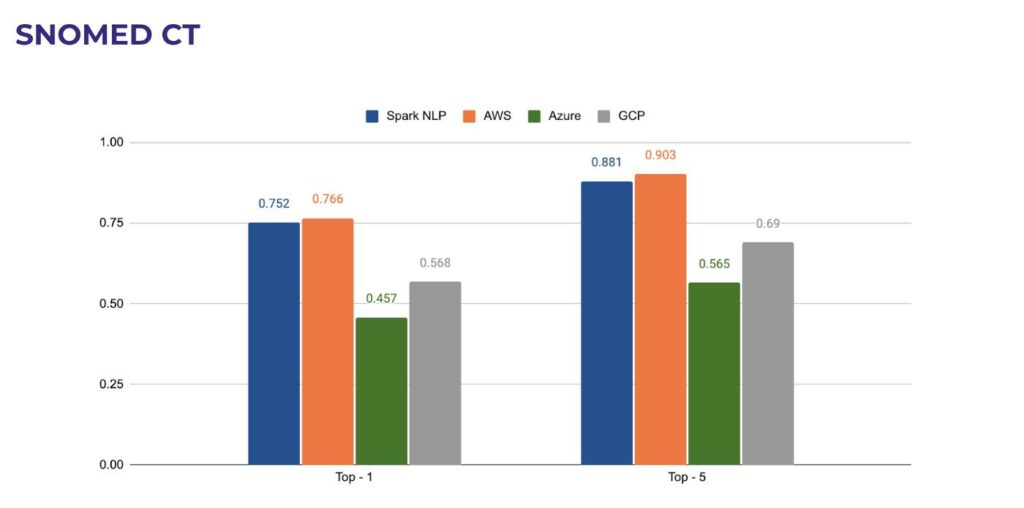
Finally, we can investigate SNOMED-CT (Systematised Nomenclature of Medicine) which is a systematic, computer-processable collection of medical terms. It allows a consistent way to index, store, retrieve, and aggregate medical data across specialities and sites of care.
As you can see from the following chart, t is the only medical terminology that Spark NLP can do a little bit worse only by 1% compared to its closest competitor AWS. It already exceeds Azure by 30% and GCP by 17%. When it comes to matching top-5 terms, the difference between Spark NLP and others still holds true.
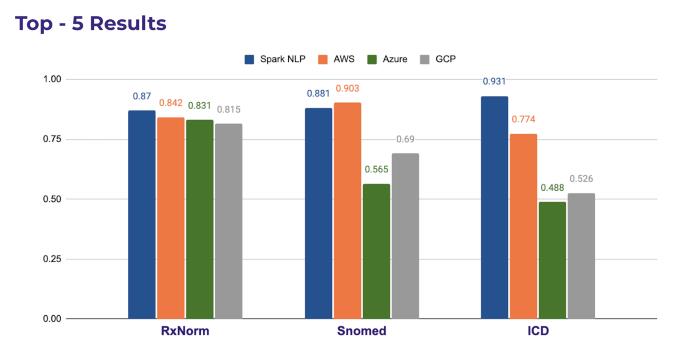
Here is the overall comparison of the top-5 resolutions of common terminologies from all the other cloud APIs.
Conclusion
Spark NLP for Healthcare comes with 600+ pretrained clinical pipelines & models out of the box and is performing way better than AWS, Azure and Google Cloud healthcare APIs by 18%, 12% and 15% (making 4–6x less error) respectively on extracting medical named entities from clinical notes. It’s also doing better consistently on entity resolution to map clinical entities to medical terminologies. Here are the other advantages of using Spark NLP for Healthcare against cloud APIs:
- Spark NLP for Healthcare offers highly customisable models and pipelines that can be shipped within the existing codebase while cloud APIs are basically black-box services that you should be OK with whatever you get in.
- The DL models shipped within Spark NLP for Healthcare can be fine-tuned and extended using the custom terminologies and new datasets annotated in-house.
- Spark NLP is the only NLP library out there that can scale over Apache Spark clusters to process large volumes of data.
- Spark NLP for Healthcare can work in air-gapped environments with no internet connection and requires no other dependency other than Spark itself. Given that Healthcare APIs offered by major cloud providers require an internet connection, this is a highly important aspect when it comes to preserving the privacy of sensitive information (PHI data) while running some analytics.
- Healthcare APIs offered by major cloud providers are pay-as-you-go solutions and can cost too much when it comes to processing a large volume of clinical texts. On the other hand, Spark NLP for Healthcare is licensed once and has no limitation in that regard. So, you can process TBs of clinical notes with the state of the art accuracy without paying anything other than the one-time annual license.
DO YOU WANT TO KNOW MORE?
- Check the example notebooks in the Spark NLP Workshop repository, available here
- Visit John Snow Labsand Spark NLP Technical Documentation websites
- Write to support@johnsnowlabs.com for any additional request you may have