A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
Two new tabs have been added to the Settings page to ease the infrastructure definition for the prediction and training tasks and for defining backup schedules.
Resource allocation for Training and Preannotation
Since release 2.8.0, Annotation Lab gives users the ability to change the configuration for the training and preannotation processes. This is done from the Settings page > Infrastructure tab. The settings can be edited by admin users and they are read-only for the other users. The Infrastructure tab consists of three sections named Training Resources, Prenotation Server Resources, Prenotation Pipeline Resources.
Resources Inclusion:
- Memory Limit – Represents the maximum memory size to allocate for the training/preannotation processes.
- CPU Limit – Specifies this maximum number of CPUs to use by the training/preannotation server.
- Spark Drive Memory – Defines the memory allocated for the Spark driver.
- Spark Kry Buff Max – Specifies the maximum memory size to allocate for the Kryo serialization buffer.
- Spark Driver Maximum Result Size – Represents the total size of the serialized results of all the partitions for spark.
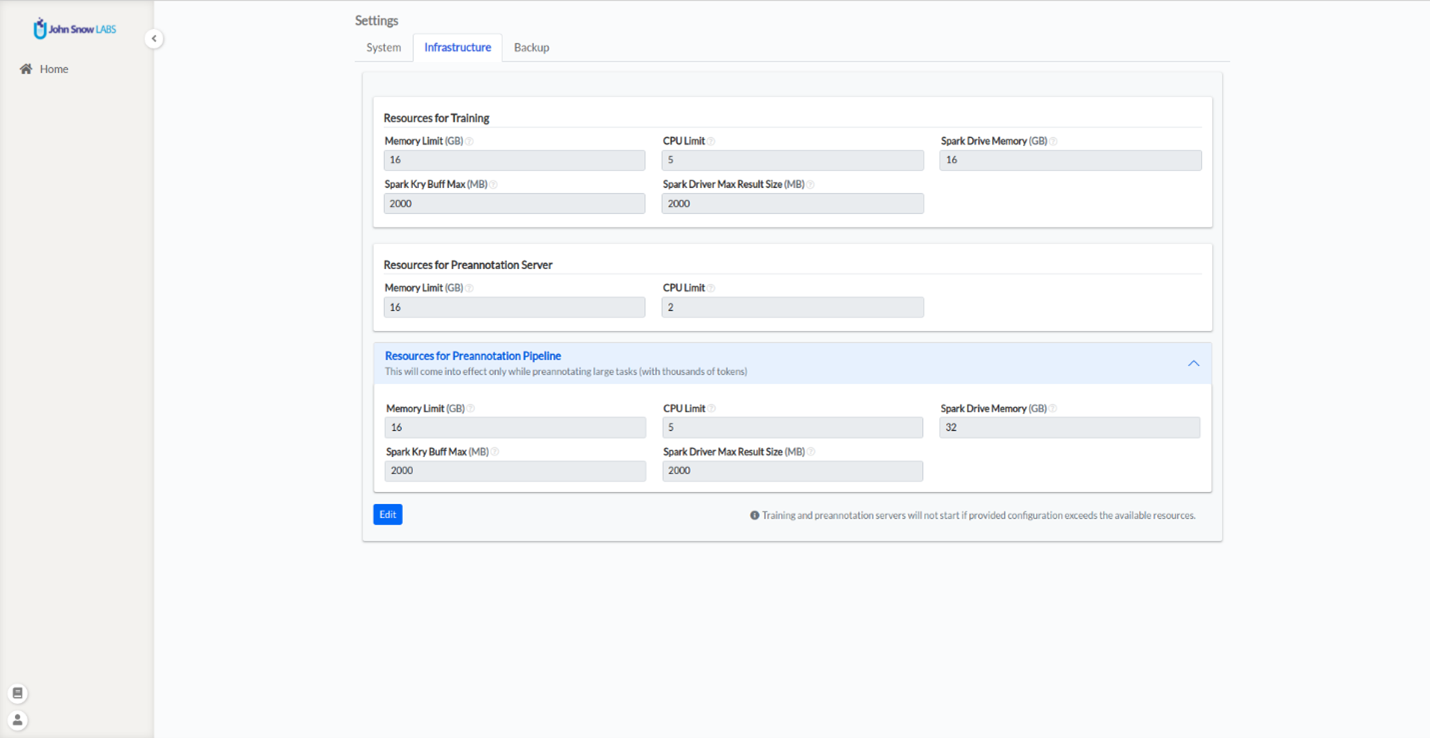
NOTE: If the specified configurations exceed the available resources, the server will not start.
Backup settings in UI
In this release, AnnotationLab adds support for defining database and files backups via the UI. Any user with the admin role can view and edit the backup settings under the Settings tab. Users can select different backup periods and can specify a target S3 bucket for storing the backup files. New backups will be automatically generated and saved to the S3 bucket following the defined schedule.