Most annotation platforms restrict teams to a single LLM provider. For healthcare and life sciences organizations, this creates compliance risk, cost inefficiency, and limits the use of domain-specific models required for regulatory-grade workflows. Teams cannot deploy fine-tuned biomedical models, cannot guarantee data sovereignty for PHI-containing prompts, and cannot optimize costs by routing simple tasks to smaller models while reserving premium models for complex medical reasoning.
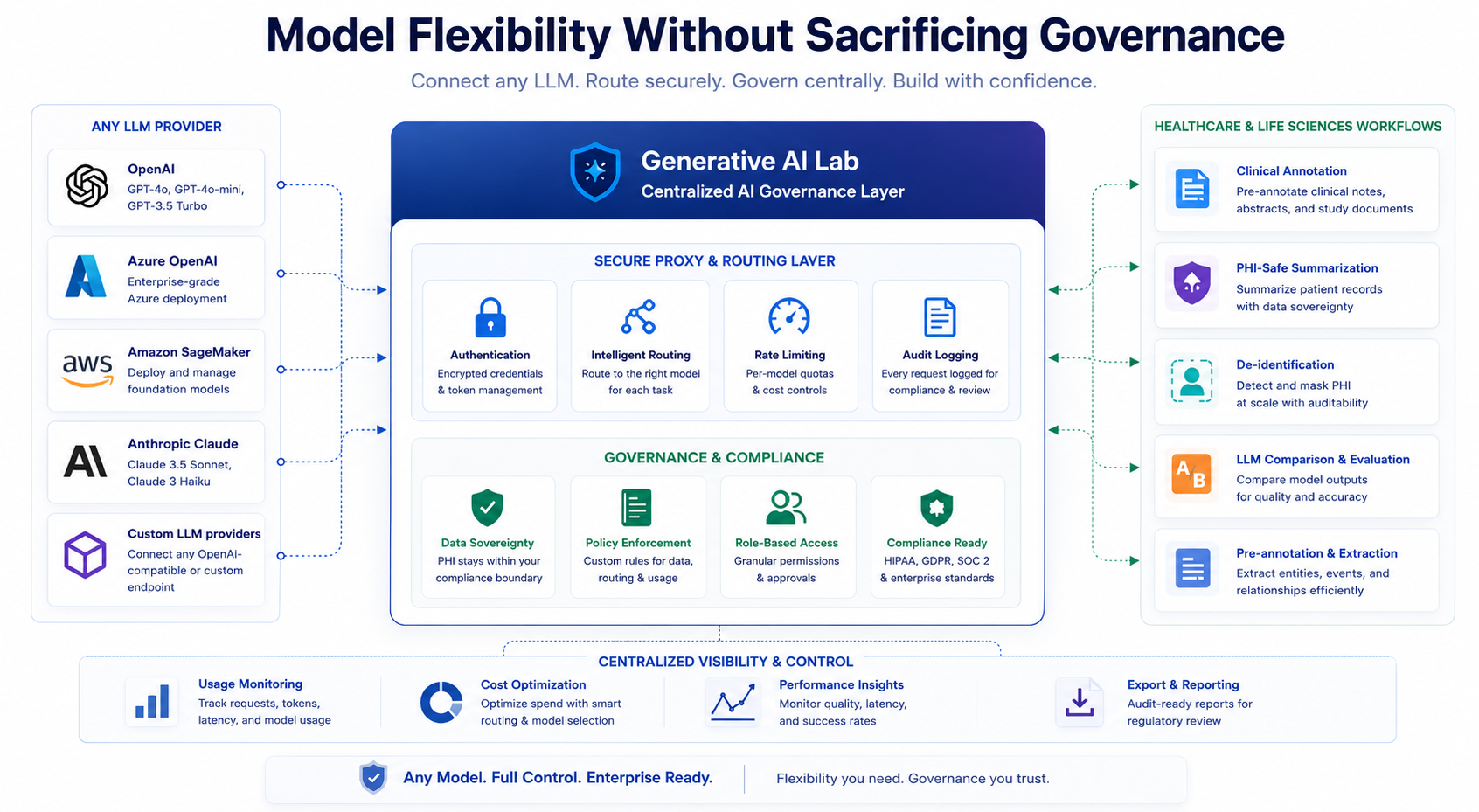
Generative AI Lab enables teams to connect any LLM endpoint (OpenAI, Anthropic Claude, organization-specific fine-tuned models, or locally hosted open-source models) through a secure proxy that handles authentication, routing, and rate limiting. The platform provides model flexibility while maintaining centralized governance. All LLM calls route through infrastructure the organization controls, where data never leaves the compliance boundary and all LLM activity is fully auditable.
Teams choose the right model for each annotation task based on cost, performance, and compliance requirements, while administrators maintain centralized control over API credentials, usage monitoring, and data flow.
The model lock-in problem in annotation workflows
Annotation platforms that support LLM-powered pre-annotation typically integrate with one or two major providers. For standard use cases, this works. But enterprise requirements diverge from standard configurations in predictable ways.
A pharmaceutical company running pre-annotation on 50,000 clinical trial documents does not need GPT-4 for every task. Entity extraction on structured sections might perform adequately with a smaller, cheaper model. Complex medical reasoning in unstructured narratives justifies premium models. Forcing all tasks through the same model means either overpaying for simple extractions or accepting lower quality on complex ones. Organizations processing 100,000+ documents monthly report cost reductions of 40-60% when they can route simple extraction tasks to optimized models while reserving premium models for complex medical reasoning.
Healthcare organizations operating under HIPAA, GDPR, or jurisdiction-specific data protection regulations need guarantees about where prompts and responses are processed. When the annotation platform routes all LLM calls through a third-party API, the organization loses control over data flow. Audit logs show “LLM call made” but cannot prove which infrastructure processed the PHI-containing prompt or where temporary copies exist. Unlike platforms that hardcode a single provider or require separate pipelines for custom models, regulatory-grade annotation requires centralized LLM routing where all prompts and responses flow through infrastructure the organization controls.
Domain-specific model performance creates another constraint. A life sciences company annotating adverse event reports from clinical trials might have fine-tuned a biomedical language model on their proprietary data. That model outperforms general-purpose LLMs on their specific entity types and medical terminology. But if the annotation platform only supports general models, the team cannot leverage their custom work.
When annotation workflows depend on a single LLM provider, pricing changes, API deprecations, or service interruptions directly impact production timelines. The common workaround is running separate annotation pipelines: one using the platform’s integrated LLM, another using custom tooling for organization-specific models. This creates operational overhead, quality control gaps, and makes it harder to maintain consistent annotation guidelines across workflows.
Custom LLM integration: how it works
Generative AI Lab’s custom LLM integration enables teams to connect any LLM endpoint to their annotation projects while maintaining centralized control over authentication, routing, and compliance.
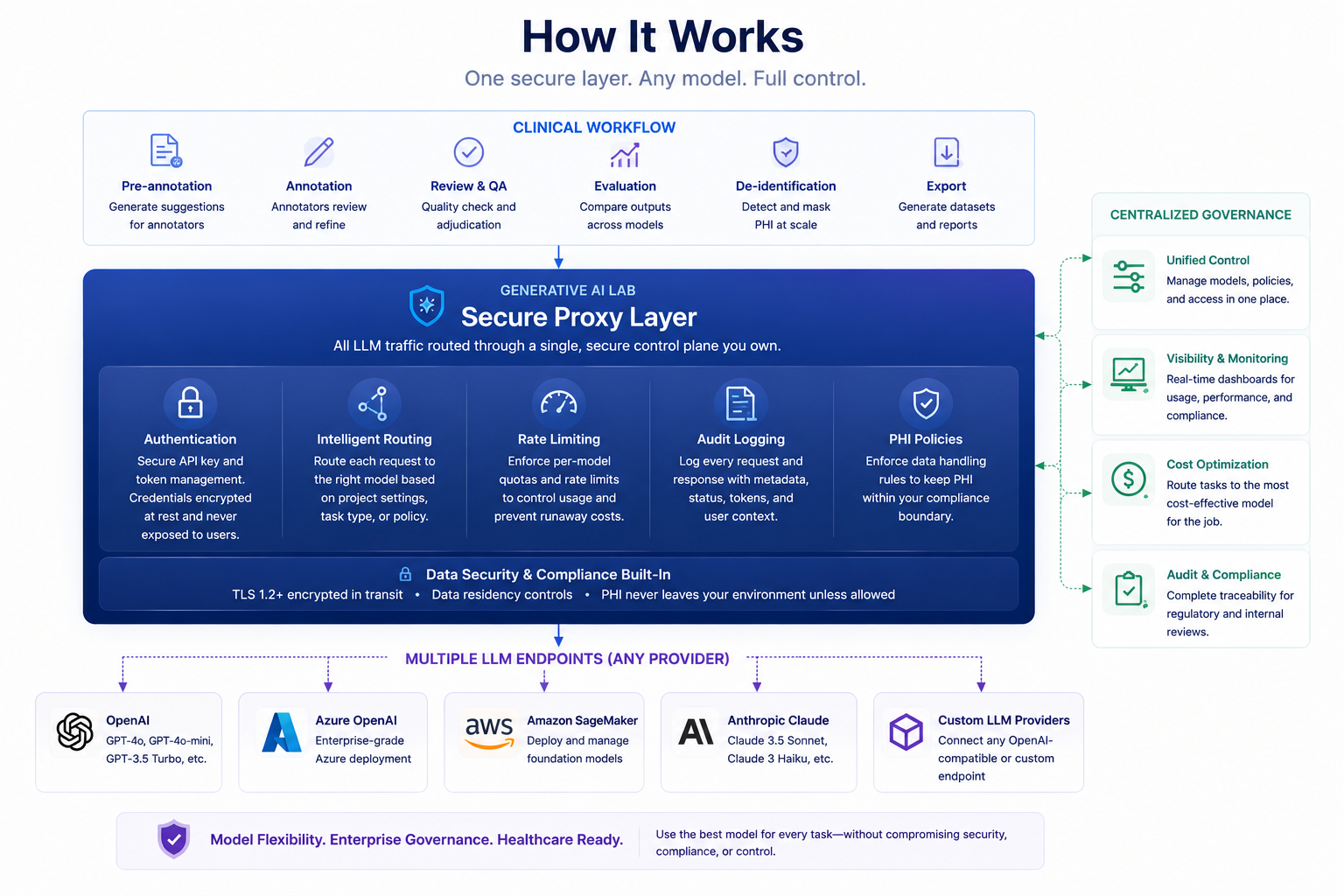
Configure any LLM provider. Project administrators add custom LLM endpoints through the Integrations interface, providing the base URL, authentication credentials, and model-specific parameters (temperature, max tokens, model type). The platform supports OpenAI-compatible APIs, Anthropic’s Claude API, Azure OpenAI, and any custom endpoint that implements a standard request/response format.
Teams can use organization-specific fine-tuned models hosted internally, route certain annotation tasks to cost-optimized open-source models, leverage domain-specific commercial models from specialized providers, or maintain local model deployments for HIPAA and GDPR compliance requirements.
Route all LLM calls through a secure proxy. The proxy-based architecture acts as the control plane for all LLM traffic. Every request from an annotation workflow passes through this layer, which handles authentication and credential management (API keys and tokens stored encrypted, never exposed to end users), request routing (determines which LLM endpoint receives each request based on project configuration), rate limiting (per-model quotas prevent runaway costs), and audit logging (every LLM call logged with request metadata, response status, and token consumption for regulatory review).
The proxy architecture solves the data sovereignty problem for PHI-containing workflows. Organizations can deploy the proxy within their own infrastructure, ensuring all prompts containing protected health information remain inside their compliance boundary even when using external LLM providers. The proxy can enforce policies like “only route to on-premises models for clinical data” or “sanitize PHI from prompts before sending to external APIs.”

Project-level model selection. Each annotation project can reference multiple LLMs: default platform-integrated models plus any custom endpoints the team has configured. When setting up pre-annotation or evaluation workflows, users select which model to use for each task type.
High-value complex annotations use premium models, high-volume simple extractions use cost-optimized models, sensitive clinical data projects route only to on-premises endpoints, and model performance can be compared across providers within the same annotation workflow.
Role-based access control. Only users with Project Admin or Owner roles can add, edit, or delete custom LLM configurations. This prevents unauthorized model usage, accidental exposure of API credentials, or circumvention of cost controls. Regular annotators can select from available models but cannot modify configurations or add new endpoints.
Technical architecture: proxy-based routing for security and compliance
The custom LLM integration uses a proxy-based architecture rather than direct API calls from the annotation platform. This design choice addresses security, compliance, and operational requirements that direct integration cannot satisfy.
Credential isolation. API keys and authentication tokens for custom LLMs are stored encrypted in the platform’s credential vault. The proxy retrieves these credentials at request time, authenticates with the target LLM endpoint, and proxies the response back to the annotation workflow. Annotation users never see credentials and cannot extract them from the platform.
Standardized request/response format. Different LLM providers use different API schemas. The proxy normalizes requests and responses into a common format, allowing the annotation platform to work with any provider without custom integration code for each one. When a team adds a new LLM endpoint, they specify the model type (completion, chat, embedding), and the proxy handles format translation.
Rate limiting and cost control. The proxy enforces per-model rate limits configured by administrators. If an annotation workflow exceeds its quota, the proxy returns a rate limit error rather than making unbounded API calls that could consume budget unexpectedly. Usage metrics flow into the platform’s analytics dashboard, giving administrators visibility into which projects, users, and annotation tasks consume the most LLM capacity.
Compliance and audit trails. Every LLM request passes through the proxy, which logs request timestamp and originating user, project and annotation task context, model endpoint and parameters used, response status and token consumption, and any errors or policy violations.
For healthcare organizations where annotation involves protected health information (PHI), these audit logs provide the defensibility regulatory review requires. When compliance officers ask “where did this patient data go during annotation,” the logs show which LLM endpoints processed which prompts, whether clinical data stayed on-premises, and who authorized the model usage. This level of provenance is non-negotiable for organizations operating under HIPAA regulations or preparing annotated datasets for FDA submissions.
Infrastructure deployment flexibility. Organizations can deploy the proxy in their own cloud environment, on-premises infrastructure, or use the hosted proxy service included with Generative AI Lab. For teams with strict data residency requirements, self-hosted proxy deployment ensures all LLM traffic remains within their compliance boundary. The proxy can enforce policies like “block all requests to external APIs” or “sanitize PHI from prompts before external routing.”
Use cases: when custom LLM integration delivers value
Domain-specific model deployment. A pharmaceutical company fine-tuned a biomedical language model on their clinical trial data and adverse event terminology. The model outperforms general-purpose LLMs on drug-drug interaction extraction and adverse event classification by 15-20 percentage points in F1 score. With custom LLM integration, they deploy this model alongside general models, using it for domain-specific annotation tasks while falling back to general models for common entity types.
Cost-optimized annotation at scale. A healthcare analytics company processes 100,000 clinical documents monthly for NER annotation. They use GPT-4 for complex medical reasoning tasks (diagnosis extraction from unstructured narratives) and a smaller open-source model for structured data extraction (medications from formatted lists). This hybrid approach reduces annotation costs by 60% while maintaining quality where it matters.
Data sovereignty for PHI-containing workflows. A European health system must comply with GDPR requirements that prohibit sending patient data to US-based cloud services. They deploy a locally hosted LLM within their on-premises infrastructure and configure the proxy to route all annotation traffic to this endpoint. The annotation platform operates as usual, but all prompts containing protected health information stay within their compliance boundary.
Multi-provider redundancy for production workflows. A clinical research organization runs time-sensitive annotation workflows for regulatory submissions. They configure multiple LLM providers (primary and fallback) and implement automatic failover in the proxy. When the primary provider experiences an outage or rate limiting, the proxy routes requests to the backup provider without workflow interruption.
Model performance comparison in annotation evaluation. A data science team evaluating pre-annotation quality needs to compare GPT-4, Claude Sonnet, and their fine-tuned biomedical model on the same annotation tasks. With custom LLM integration, they run parallel annotation workflows using different models and compare inter-annotator agreement, entity coverage, and annotation speed across providers within the same project.
Operational impact: governance without sacrificing flexibility
Custom LLM integration changes how teams think about model selection in annotation workflows. Instead of “which annotation platform supports the model we need,” the question becomes “which annotation platform gives us control over model routing and governance.”
Administrators gain centralized visibility. The platform’s audit dashboard shows LLM usage across all projects: which models are consuming the most capacity, which annotation tasks drive costs, which users are making the most requests. This visibility enables informed decisions about model procurement, capacity planning, and cost allocation.
Teams optimize for task requirements. Annotation workflows can mix model selection based on task complexity, data sensitivity, and budget constraints. High-value annotations justify premium models. High-volume routine extractions use cost-optimized endpoints. Sensitive data routes to on-premises models. This granularity was not possible when the platform enforced a single provider.
Compliance posture improves. When LLM calls route through a proxy the organization controls, compliance officers can audit exactly where prompts and responses flow. For healthcare organizations, this means defensible answers to regulatory questions about PHI handling. For enterprises with data residency requirements, this means provable control over cross-border data movement.
Vendor lock-in risk decreases. Organizations are not dependent on a single LLM provider’s pricing, availability, or API stability. If one provider becomes too expensive or unreliable, administrators can add an alternative endpoint and migrate annotation workflows without platform changes.
Frequently asked questions
Can custom LLMs be used for all annotation tasks, or only specific workflows?
Custom LLMs can be used anywhere the platform supports LLM-powered functionality: pre-annotation, zero-shot prompting, evaluation workflows, and annotation assistance. Teams select which model to use at the project level.
How does the proxy handle authentication for models that require different credential types?
The proxy supports multiple authentication schemes: API keys in headers, bearer tokens, OAuth flows, and custom authentication methods. When configuring a custom LLM, administrators specify the authentication type, and the proxy handles credential injection at request time.
Can the same custom LLM be shared across multiple projects, or does each project need its own configuration?
Custom LLMs are configured at the organization or workspace level and can be shared across projects. Administrators control which projects have access to which models through role-based permissions.
Does the proxy add latency to LLM requests compared to direct API calls?
The proxy adds minimal overhead (typically under 50ms) for credential injection, logging, and request forwarding. For annotation workflows where LLM response time dominates (1-5 seconds), this overhead is negligible.
Deploy custom LLM integration in your workflow
Custom LLM integration is available in Generative AI Lab for teams that need model flexibility, cost optimization, or data sovereignty in their annotation workflows.
Deploy a pilot with your own LLM endpoints and validate connectivity:
👉 Schedule a technical walkthrough
Configure the proxy server in your infrastructure for full control over LLM routing:
👉 Review deployment documentation
Questions about proxy architecture, model compatibility, or compliance requirements?
👉 Contact our team