






















































Healthcare organizations are under growing pressure to operationalize AI. Clinical NLP pipelines extract diagnoses from notes in seconds. Large language models summarize encounters, draft responses, and classify documents at scale. De-identification systems detect protected health information across millions of records automatically.
Yet healthcare AI workflows break down in surprisingly ordinary ways once they move beyond pilot projects.
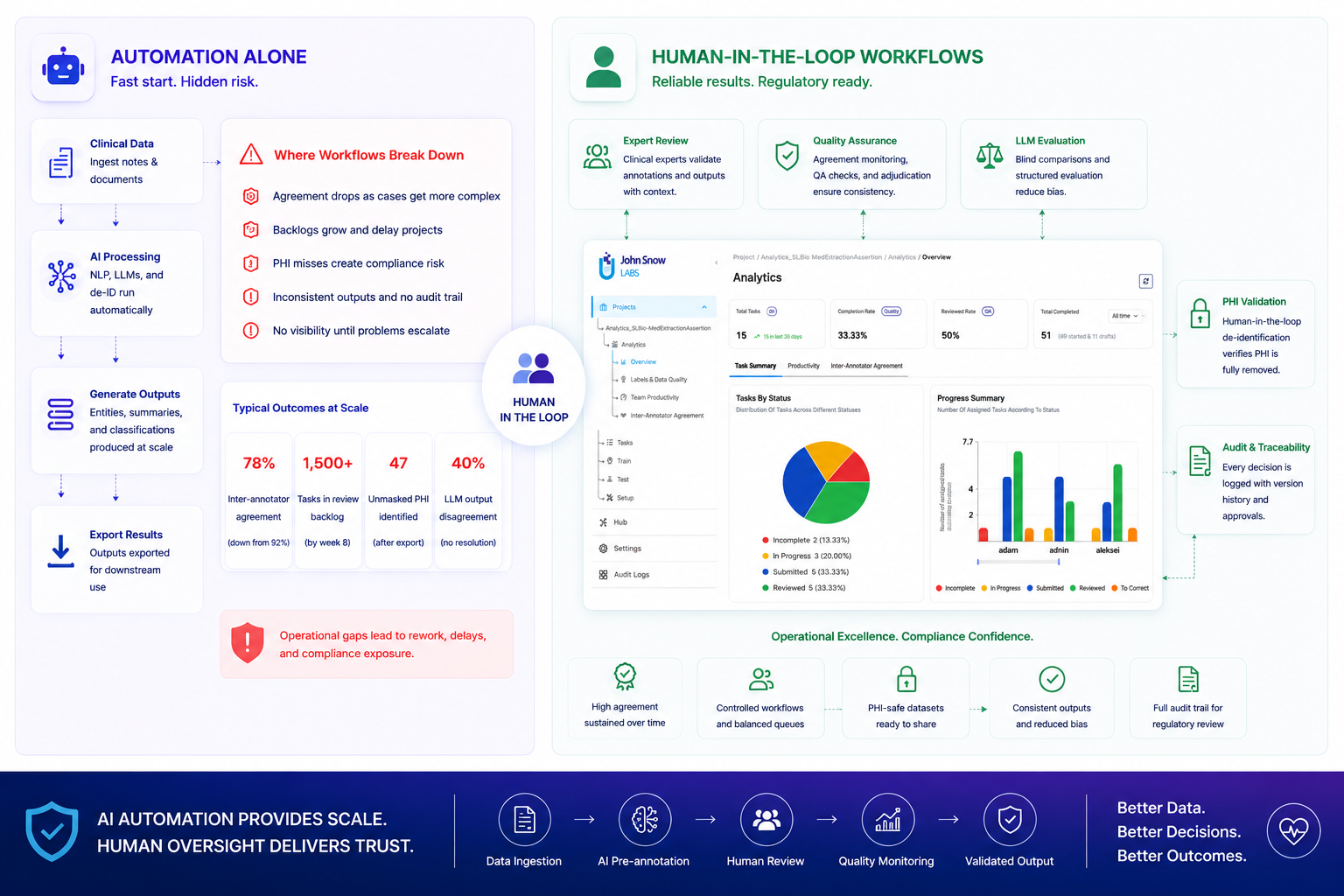
A clinical annotation team launches with 92% inter-annotator agreement on discharge summary entities. Six weeks later, agreement on the same entity types drops to 78%. Nothing changed about the model. The dataset became more complex. Multi-comorbidity patients appeared in the queue. Reviewers started interpreting borderline cases differently. Nobody noticed the drift until hundreds of tasks required rework.
Another organization exports a de-identified dataset after automated PHI detection. The model achieves 99.4% recall. Compliance review discovers that 0.6% miss rate translates to 47 unmasked patient identifiers in the 7,800-record export. The dataset cannot be shared externally. Three weeks of annotation work requires re-validation.
A third team builds an LLM-powered clinical summarization tool. Early evaluations show promising fluency. Production deployment reveals that two reviewers prefer different model outputs for the same encounter 40% of the time, with no systematic way to resolve disagreement or document why one response was approved over another.
These failures do not indicate model inadequacy. They reveal that healthcare AI projects collapse when organizations cannot maintain consistency, accountability, and audit trails once real clinical complexity enters the workflow. In regulated environments, operational failures matter just as much as technical ones.
Human-in-the-loop workflows remain central to healthcare AI operations because automation alone cannot provide the structured oversight, traceability, and clinical judgment that regulatory deployment requires.
The pilot looks successful, then scale breaks the workflow
AI workflows often perform well during small evaluations. A clinical team uploads 200 discharge summaries. Pre-annotation runs cleanly. Reviewers move quickly. Early agreement scores exceed targets.
Operational problems emerge when the project scales to 5,000+ tasks over multiple weeks.
A reviewer notices that different annotators handle multi-word diagnoses inconsistently. One annotator labels “metastatic non-small cell lung cancer” as a single entity. Another separates disease type and staging information into multiple spans. Both interpretations appear clinically reasonable, but they cannot coexist in the same training dataset without creating systematic noise.
The review queue grows. At week 4, the queue contains 680 tasks waiting for validation. Annotation throughput averages 85 tasks per day, but review capacity handles only 44 tasks per day. The backlog accumulates 41 tasks daily. By week 8, the review queue reaches 1,500 tasks, creating a multi-week delay even after annotation completes.
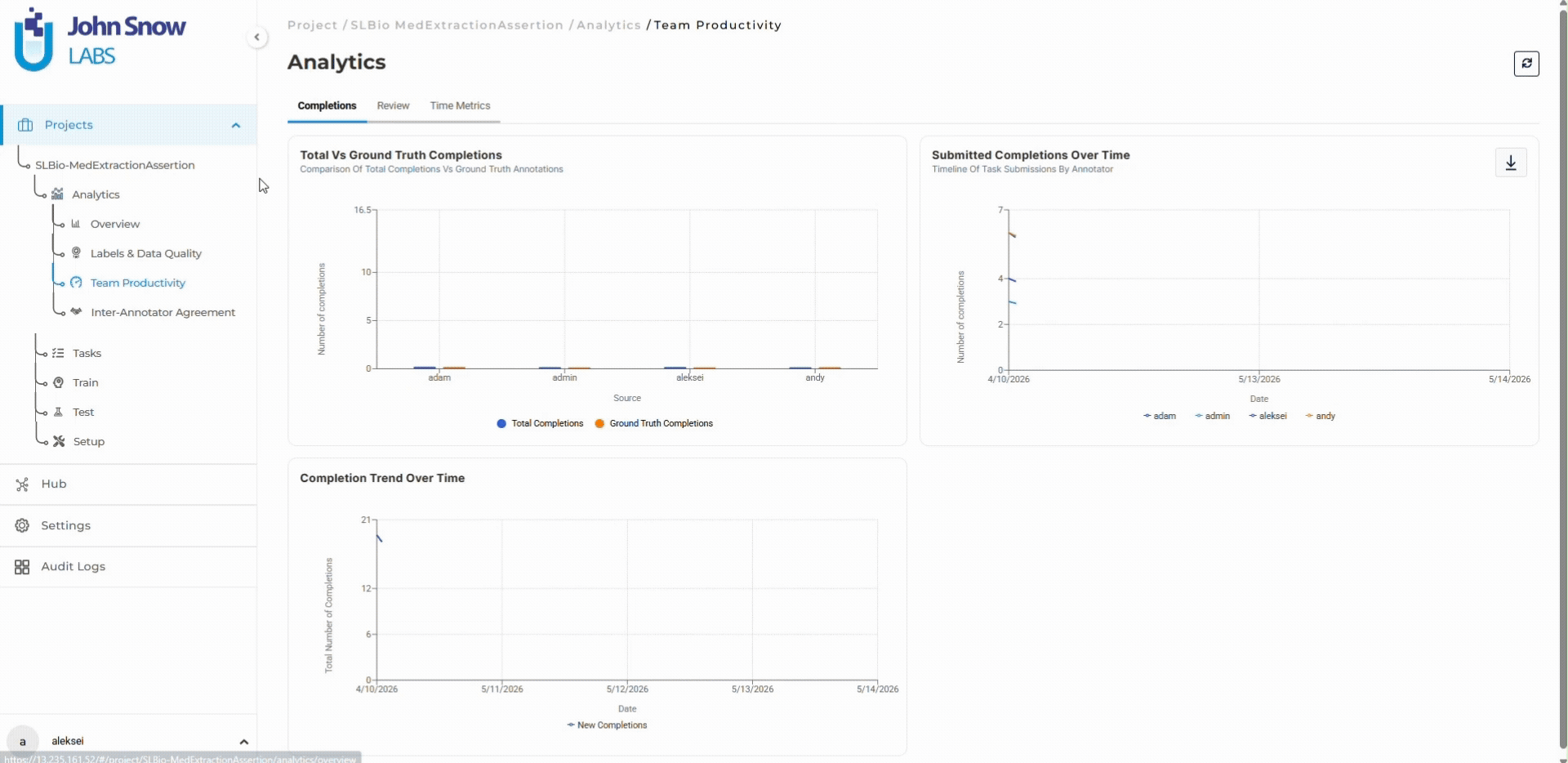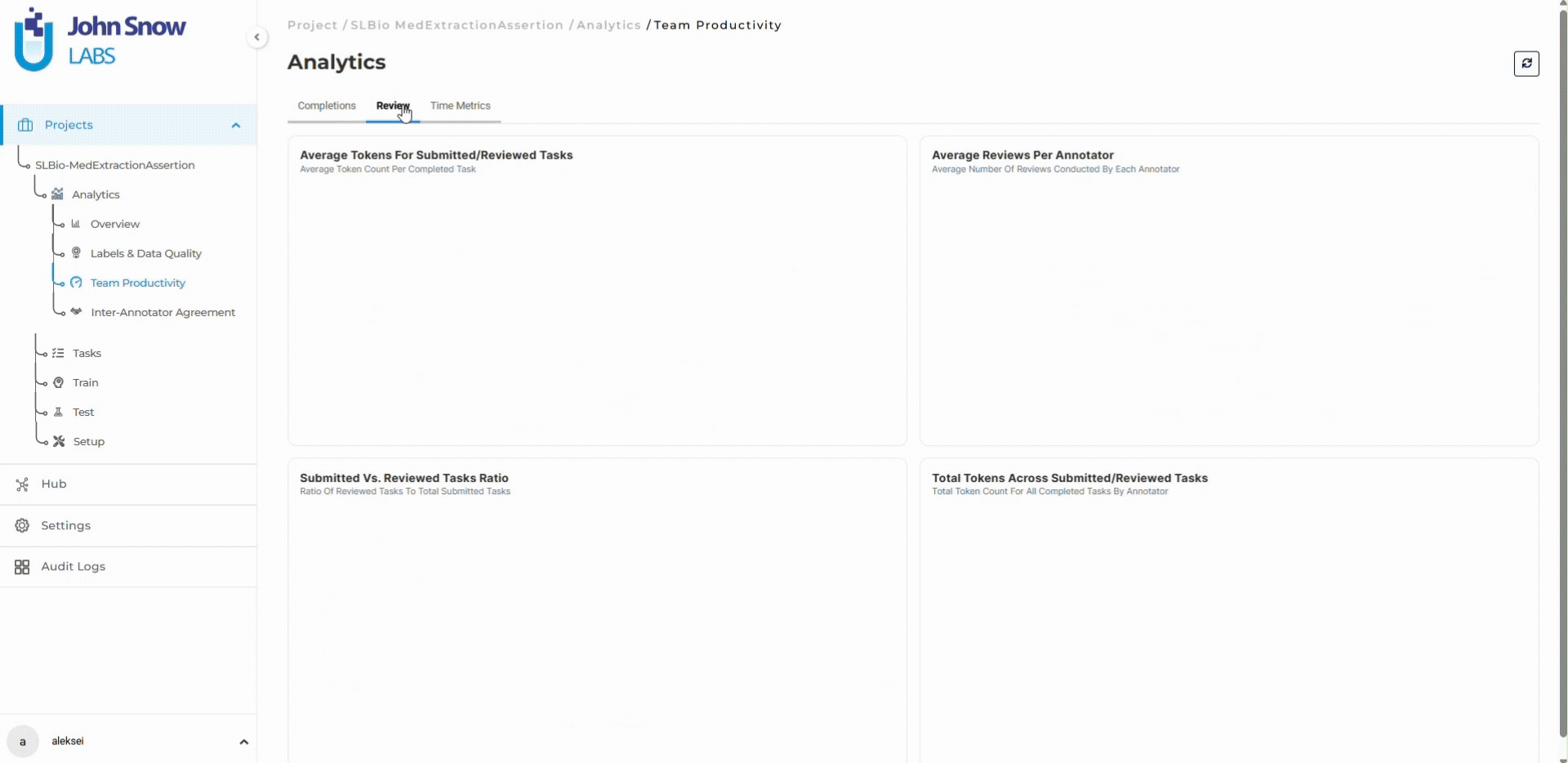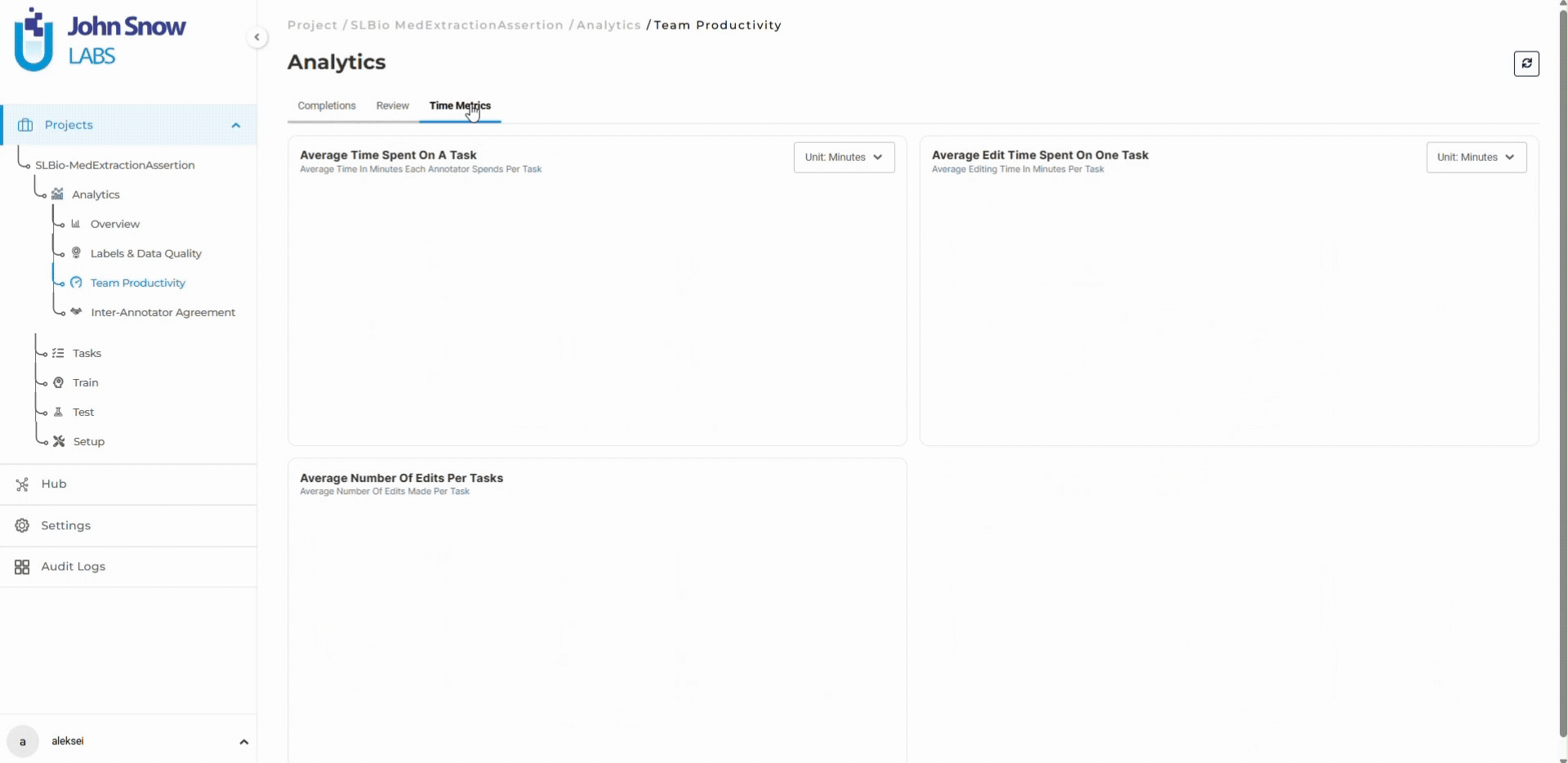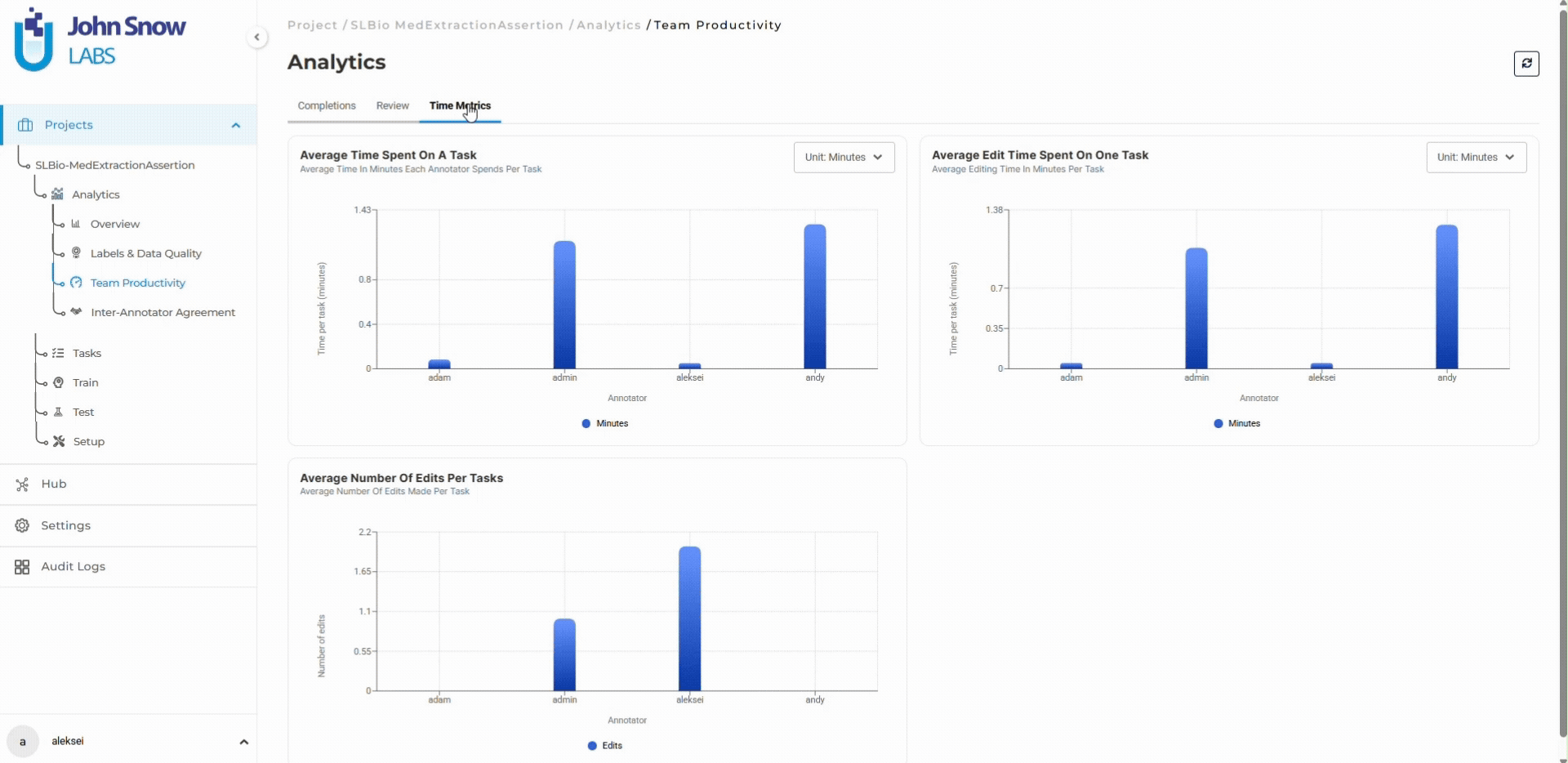
Certain entity types show degrading agreement. Diagnosis annotations that maintained 91% agreement in week 3 drop to 86% by week 7 as complex cases with overlapping comorbidities appear more frequently. Some exported tasks contain manual corrections applied without documentation of why the change was made or who approved it.
The model itself performed adequately. The workflow surrounding the model lacked operational structure. No systematic way to track agreement trends, identify bottlenecks before they compounded, or maintain an audit trail of reviewer decisions.
Healthcare AI projects rarely fail because models cannot generate useful predictions. They fail because organizations struggle to maintain quality control, consistency, and traceability once clinical complexity scales beyond pilot scope. For organizations operating under HIPAA regulations or preparing datasets for FDA submissions, the inability to document how decisions were made creates compliance exposure that prevents deployment.
Clinical ambiguity requires accountable human interpretation
Healthcare data contains inherent ambiguity that NLP models detect but cannot resolve autonomously.
A medication listed in a discharge summary might represent current treatment (atorvastatin 40mg daily), historical exposure (discontinued metformin after renal function declined), ruled-out therapy (patient declined insulin), or future recommendation (start aspirin if chest pain recurs). The clinical context determines which interpretation applies. NLP models extract all medication mentions. Human reviewers determine which medications represent active prescriptions, which represent clinical history, and which represent contingent recommendations.

A diagnosis may appear as confirmed, suspected, family history, or ruled out based on subtle linguistic cues. “Patient has diabetes” differs clinically from “patient’s mother has diabetes” and “rule out diabetes.” Assertion detection models classify these distinctions with high accuracy on clean text. Real clinical notes contain incomplete sentences, inconsistent formatting, copy-paste errors from previous encounters, and specialty-specific abbreviations that create edge cases requiring interpretation.
In one annotation project involving 12,000 clinical documents across 4 annotation batches, the team discovered that 80% of randomly sampled notes were irrelevant to the study (nursing processes for unrelated conditions, school incident reports, administrative documentation). The team shifted from pure random sampling to strategic sampling targeting clinically relevant note types. Without human review determining relevance, the training dataset would have contained majority-irrelevant examples.
Human oversight remains necessary not because AI cannot generate valuable outputs, but because healthcare workflows require accountable decisions in ambiguous situations. Someone must determine whether a prediction is clinically acceptable, operationally consistent with project guidelines, and compliant with regulatory requirements. That determination must be traceable.
Operational memory: The audit trail problem
One of the most dangerous operational failures in healthcare AI is the inability to reconstruct how datasets were validated after the fact.
A dataset undergoes correction over several weeks. Reviewers provide feedback through chat messages, email threads, or spreadsheet comments. Annotators revise outputs manually. Different versions circulate between teams. Months later, nobody can explain which version became the approved ground truth, why certain corrections were made, or who authorized the final export.
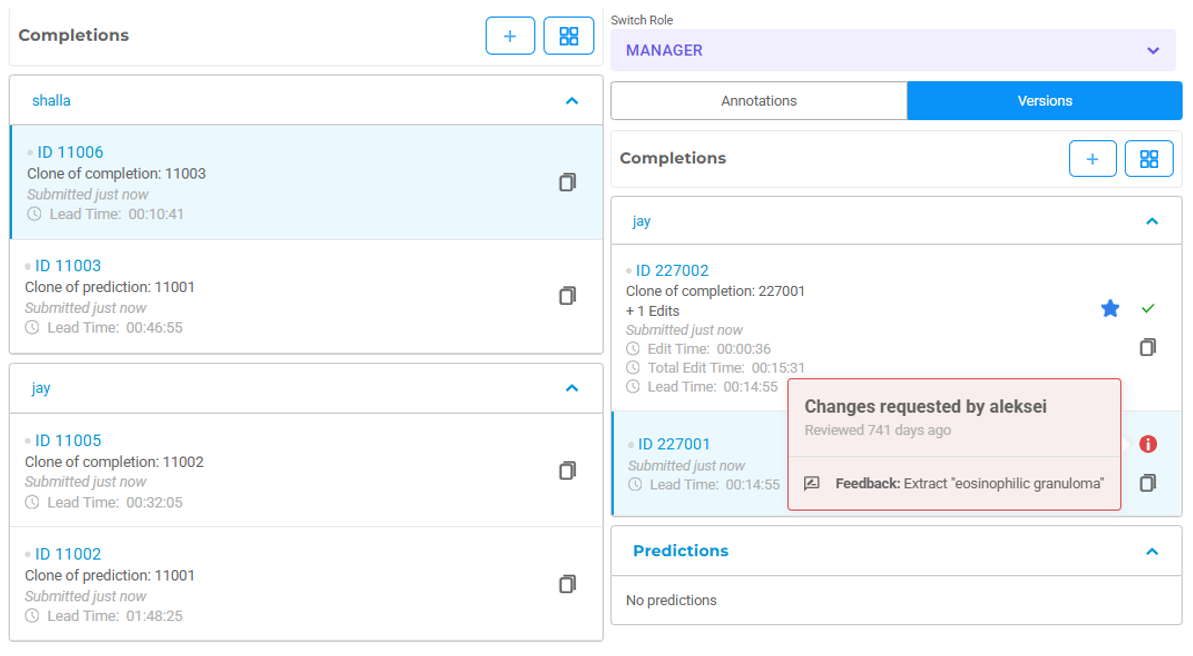
For healthcare organizations, the consequences extend beyond inconvenience. If an organization cannot reconstruct how a dataset was reviewed, validated, and modified, defending the quality of resulting models becomes difficult. The problem is not only compliance. It affects reproducibility, model validation, and regulatory audit preparedness.
Structured human-in-the-loop systems solve this by making review a traceable operational process rather than informal collaboration. In Generative AI Lab, reviewer actions, corrections, approvals, and version history maintain continuous audit trails associated with authenticated users and timestamps. When a compliance officer needs to confirm who approved a de-identified export before external sharing, the system provides complete provenance: which annotator submitted the task, which reviewer validated PHI masking, which project administrator authorized export, and when each action occurred.
For organizations preparing annotated datasets for regulatory submissions, this audit trail is non-negotiable. FDA validation processes expect documented evidence of data quality controls, inter-rater reliability measurements, and systematic review procedures. Informal review processes cannot provide that documentation.
Quality drift develops gradually, then becomes expensive
Agreement drift in annotation projects develops slowly enough to avoid immediate detection, then compounds into expensive rework.
A project begins with 94% inter-annotator agreement, stable throughput, and consistent guidelines. The dataset becomes more difficult. More patients present with overlapping comorbidities. Notes grow longer and less standardized. Reviewers interpret borderline cases differently. Nothing appears broken on any single day.
Over six weeks, inconsistency accumulates inside the dataset. By the time model performance begins degrading during training, 2,400 of 8,000 tasks already contain systematic inconsistencies requiring correction. The rework cost exceeds the original annotation cost.
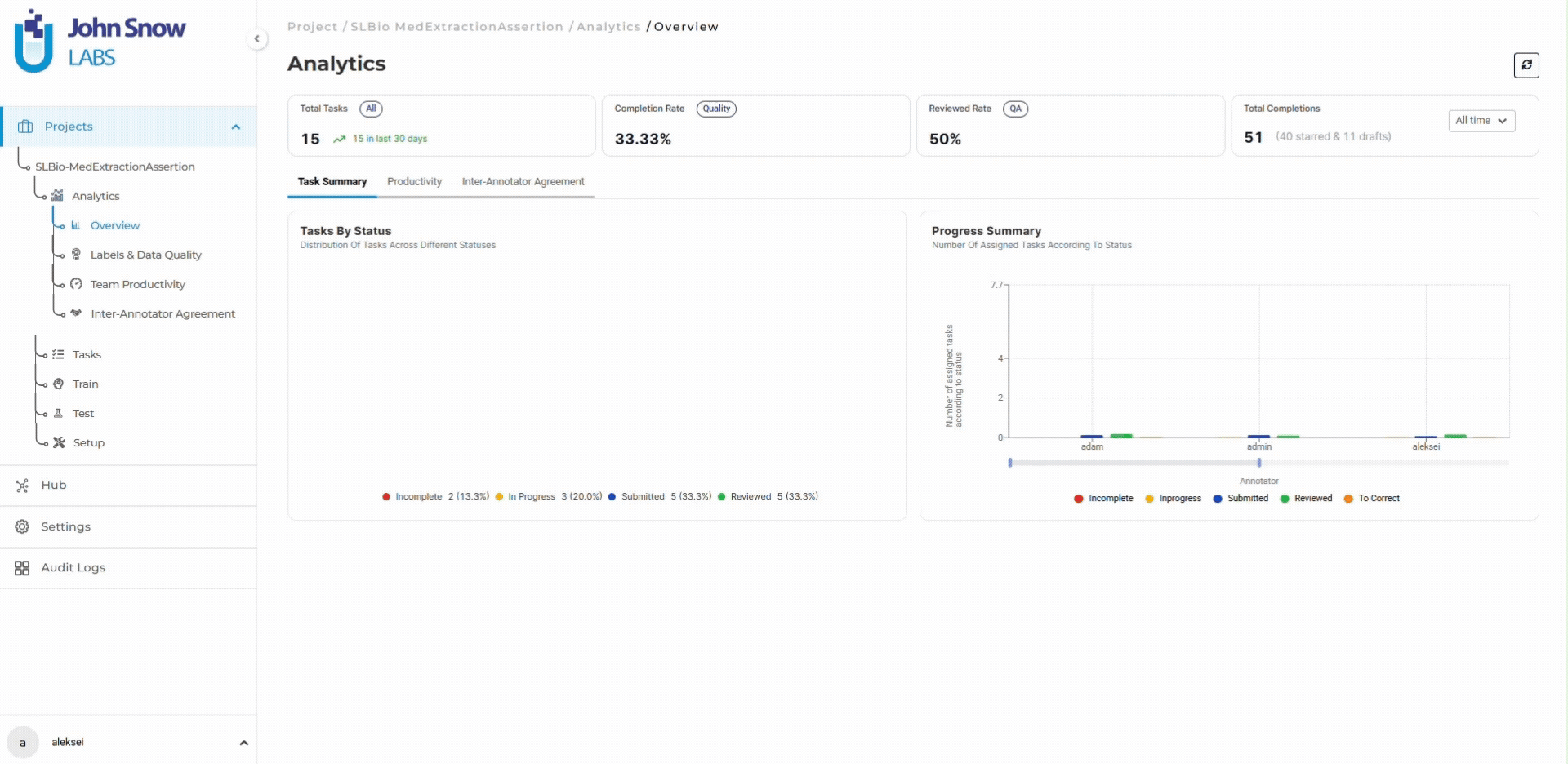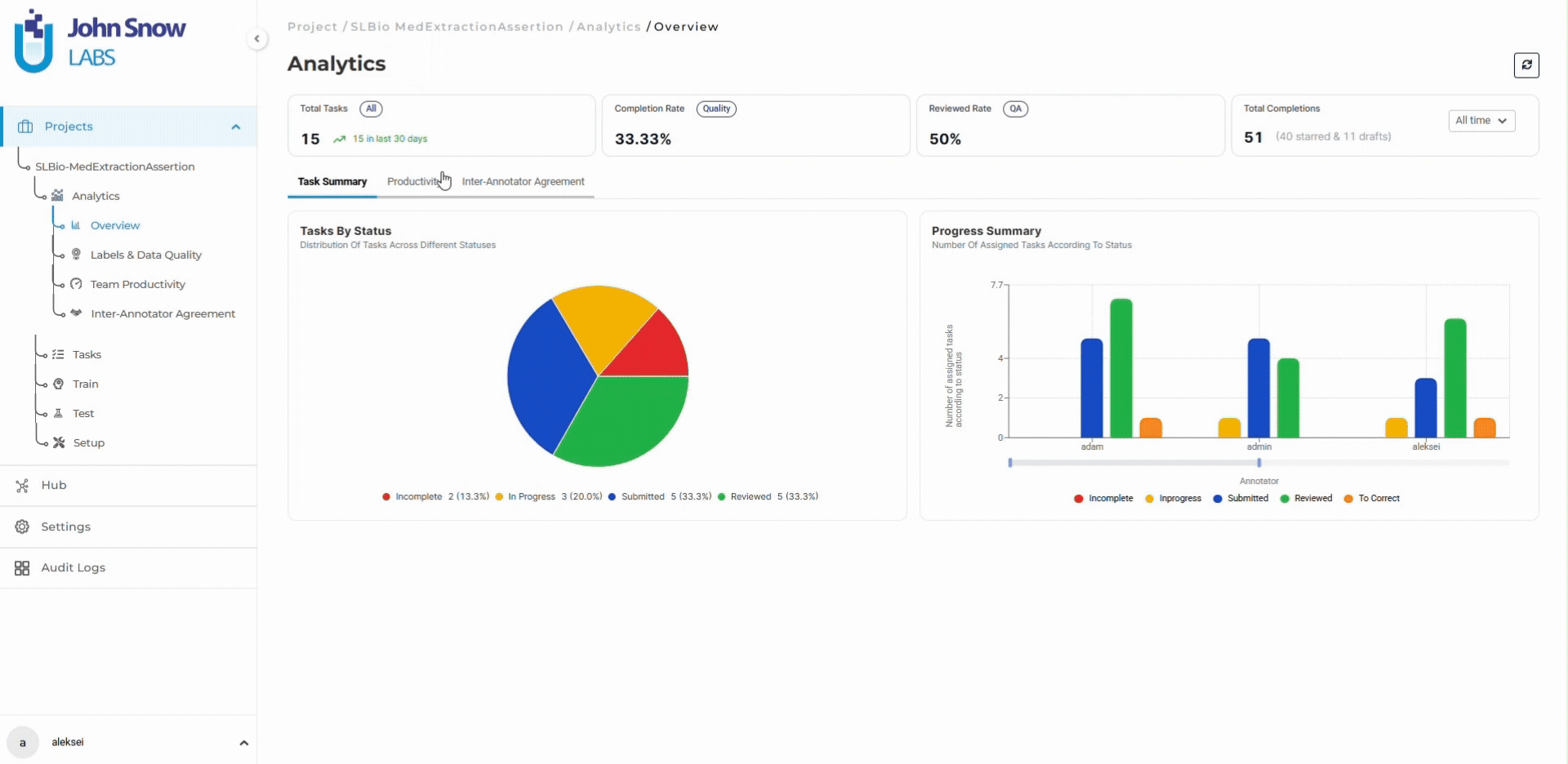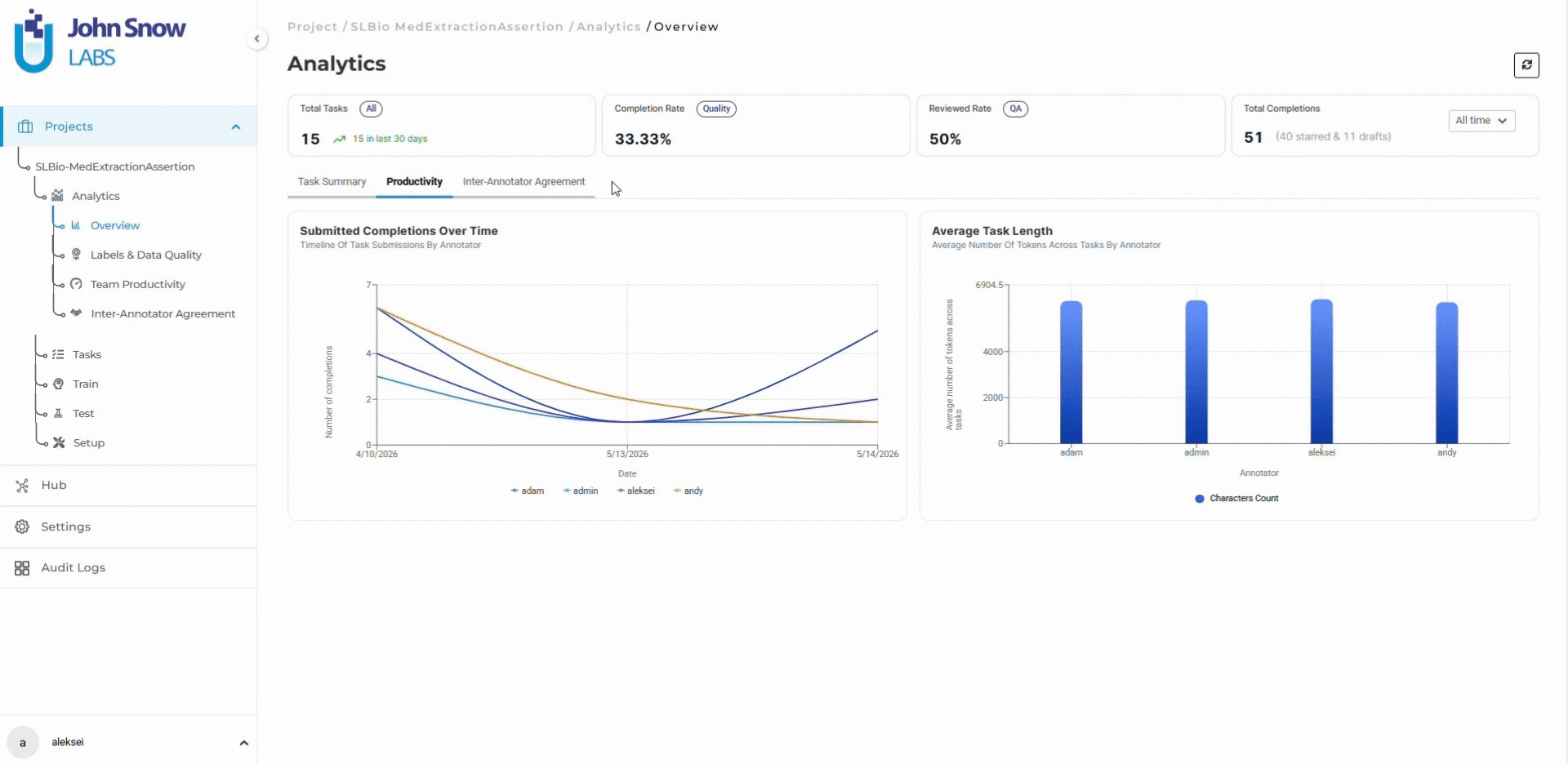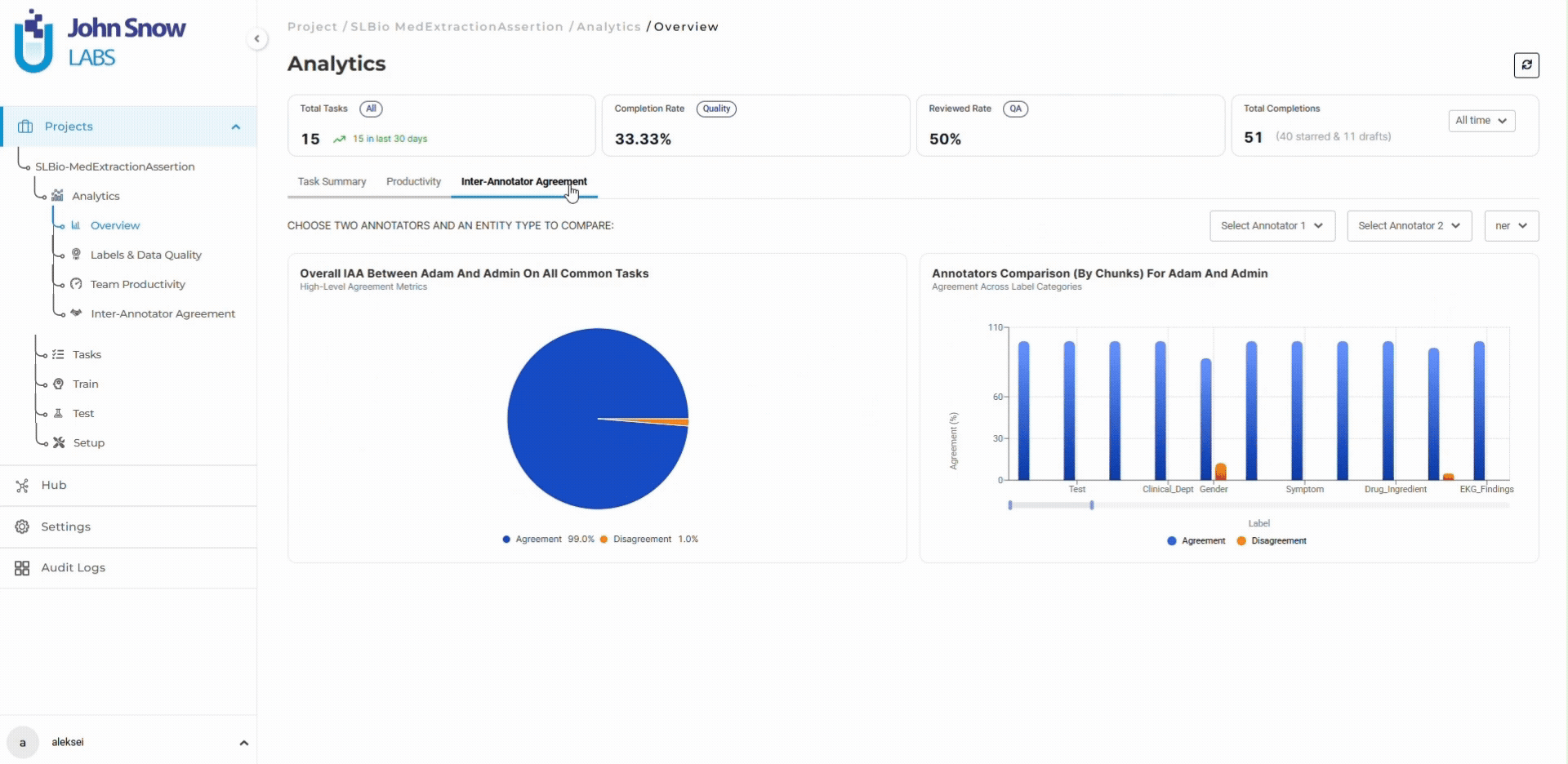
The dangerous characteristic of annotation drift: disagreement patterns change over time in ways that are invisible without continuous monitoring. The important signal is not that reviewers disagree occasionally. Disagreement is expected in complex clinical data. The signal is that disagreement rates increase, that specific entity types show degrading agreement while others remain stable, or that individual annotators diverge from team consensus in systematic ways.
Human-in-the-loop workflows increasingly rely on operational analytics rather than manual review alone. Inter-annotator agreement trends, reviewer activity patterns, review rate decline, and label-specific agreement breakdowns become early indicators of workflow instability. When diagnosis entity agreement drops 5 percentage points while medication and procedure entities remain stable, the dashboard surfaces this trend before it affects thousands of additional tasks.
Organizations can intervene while corrections remain manageable. Guidelines can be clarified with specific examples addressing the ambiguous cases causing drift. Calibration sessions can be repeated with the exact entity types showing disagreement. Problematic entity definitions can be refined before inconsistency spreads across the dataset.
Without real-time visibility into agreement trends, teams discover quality drift only after model training fails or after exported datasets fail validation. At that point, correction costs multiply.
Large language models increase the need for systematic review
Large language models introduce operational challenges distinct from traditional NLP pipelines.
Traditional clinical NER models are deterministic. Given identical input, they generate identical predictions. LLMs behave differently. Small prompt variations, context changes, or model version updates produce significantly different outputs despite appearing equally plausible.
A clinical summarization system generates two responses for the same encounter. Response A is more concise. Response B includes more clinical detail but uses less fluent phrasing. Two reviewers prefer different responses for reasons difficult to quantify consistently. Reviewer A values brevity. Reviewer B prioritizes completeness. When asked to choose the better summary, they disagree 40% of the time.
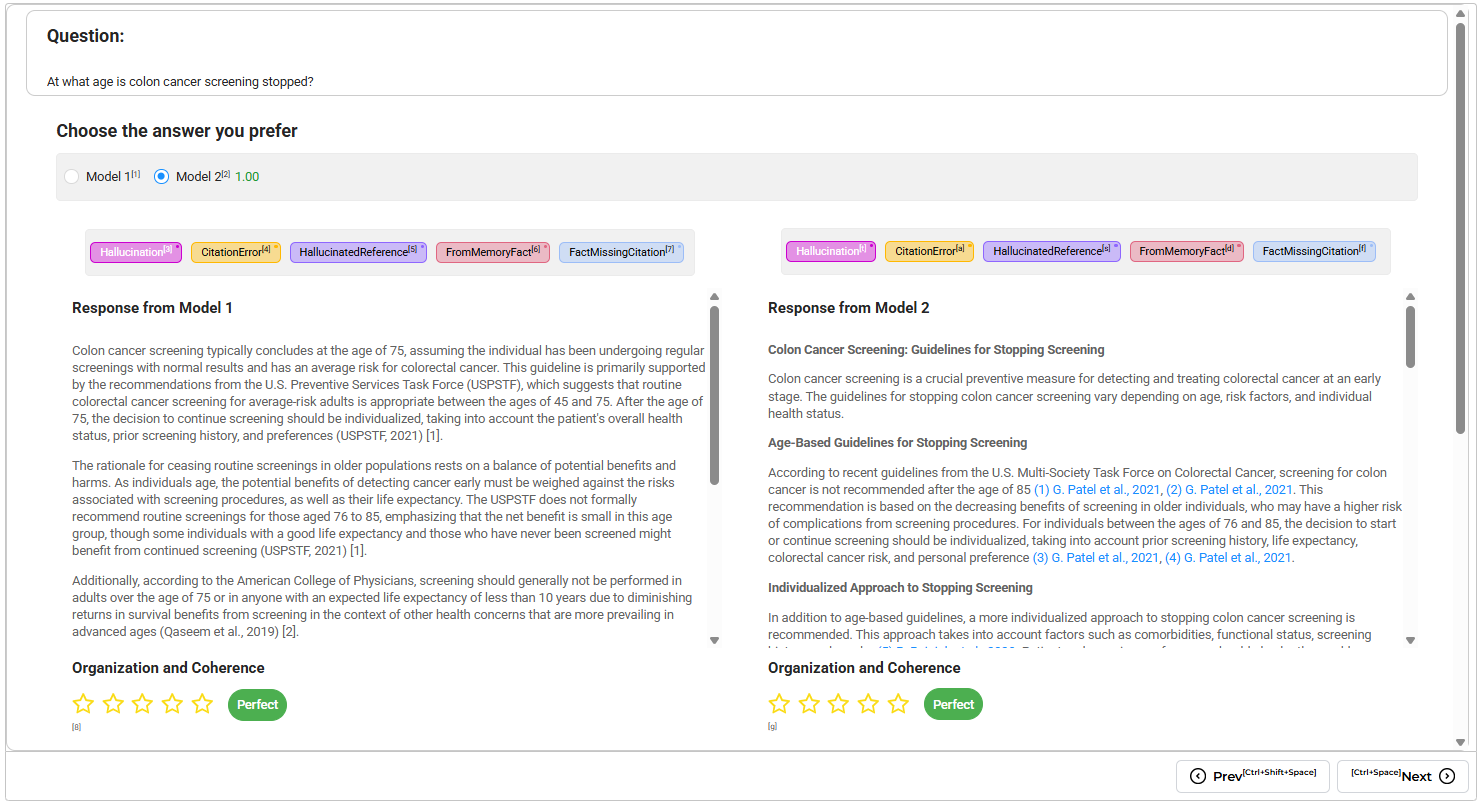
Reviewer bias influences evaluation when model identity becomes visible. A response from GPT-4 might receive more favorable review than an identical response attributed to an open-source model, even when reviewers believe they are evaluating objectively. A more fluently written response appears more convincing even when it omits clinically important details or introduces subtle factual errors.
Healthcare organizations evaluating LLM outputs need systematic review workflows, not informal preference-based assessment. Blinded model comparisons prevent reviewer bias from influencing evaluation. Structured approval criteria replace subjective preference. Audit logging tracks which reviewer approved which outputs and why. Inter-rater reliability metrics reveal when reviewers apply evaluation criteria inconsistently.
The goal is not eliminating human judgment. The goal is making human judgment operationally consistent enough to support deployment decisions and satisfy regulatory expectations for model validation.
Reviewer bias influences evaluation when model identity becomes visible. A response from GPT-4 might receive more favorable review than an identical response attributed to an open-source model, even when reviewers believe they are evaluating objectively. A more fluently written response appears more convincing even when it omits clinically important details or introduces subtle factual errors.
Healthcare organizations evaluating LLM outputs need systematic review workflows, not informal preference-based assessment. Blinded model comparisons prevent reviewer bias from influencing evaluation. Structured approval criteria replace subjective preference. Audit logging tracks which reviewer approved which outputs and why. Inter-rater reliability metrics reveal when reviewers apply evaluation criteria inconsistently.
The goal is not eliminating human judgment. The goal is making human judgment operationally consistent enough to support deployment decisions and satisfy regulatory expectations for model validation.
De-identification shows why full automation remains insufficient
De-identification provides one of the clearest examples of why healthcare AI requires structured human validation despite high model accuracy.
Modern NLP systems detect names, dates, addresses, medical record numbers, and provider information with 99%+ recall. De-identification errors are operationally asymmetric in ways that prevent fully automated review.
Over-masking reduces data utility by removing clinically relevant context. Under-masking creates HIPAA compliance exposure by allowing protected health information to leak into shared datasets. A 0.5% recall error rate sounds negligible until it translates to 40 unmasked patient identifiers in an 8,000-record export destined for external research collaboration.
The difference between acceptable and unacceptable masking often depends on subtle contextual interpretation. A hospital name represents protected information in one document and medically relevant context in another. A date requires full masking in one workflow but only temporal shifting (preserving time intervals while changing absolute dates) in another. “Dr. Smith” might reference the treating physician (requires masking) or a medication brand name (should not be masked).
Human reviewers remain essential because organizations need controlled processes for validating ambiguous masking decisions before data leaves secured infrastructure. In Generative AI Lab, annotators validate AI-detected PHI, reviewers approve corrections, and audit systems maintain records of who accessed, modified, and exported sensitive data.
The value extends beyond accuracy. Organizations can demonstrate how de-identification decisions were made, who reviewed them, and how compliance requirements were enforced throughout the project lifecycle. When compliance officers or institutional review boards audit the de-identification process, the system provides complete documentation: which PHI detection model was used, what confidence thresholds were applied, which human reviewers validated outputs, and which administrator authorized the final export.
For healthcare organizations sharing de-identified data externally, this documentation is not optional. HIPAA Safe Harbor and Expert Determination methods both require documented validation processes. Fully automated de-identification cannot provide that documentation without structured human oversight.
Human-in-the-loop as the operational foundation of deployable Healthcare AI
There is a persistent narrative that mature AI systems will eliminate the need for human review. Healthcare organizations moving AI into production operations trend in the opposite direction.
As models become more capable, operational expectations increase. Organizations need stronger auditability, clearer approval structures, more reproducible workflows, and better visibility into how outputs evolve over time. Regulatory bodies expect documented validation processes. Compliance officers require audit trails. Clinical stakeholders demand explainable decisions.
The most successful healthcare AI deployments design workflows where automation and human expertise reinforce each other operationally rather than attempting to remove humans entirely.
AI systems accelerate extraction, classification, and pre-annotation. Human reviewers provide calibration, contextual interpretation, escalation handling, and accountability. Analytics platforms surface workflow instability (agreement drift, queue growth, label distribution imbalances) before problems become expensive. Audit systems preserve traceability for regulatory review.
Taken together, these components create deployable healthcare AI rather than just accurate models. A clinical NER model that achieves 95% F1 score on benchmark data but cannot document how training data was validated, who reviewed outputs, or why certain corrections were made remains difficult to deploy in regulated environments. A model with 92% F1 score supported by complete audit trails, systematic review workflows, and documented quality controls becomes operationally deployable.
That distinction matters as healthcare organizations move from experimentation toward operational adoption at scale. The technical challenge of building accurate models is increasingly solved. The operational challenge of deploying those models safely, maintaining quality over time, and satisfying regulatory requirements determines which projects reach production.
Build traceable, auditable annotation workflows
Human-in-the-loop workflows in Generative AI Lab provide the operational infrastructure healthcare AI projects need to move from pilots to production deployment.
Track inter-annotator agreement trends in real time and identify quality drift before it compounds:
👉 Explore the Analytics Dashboard
Maintain complete audit trails for regulatory review and compliance validation:
👉 Learn about annotation governance
Deploy human-reviewed de-identification workflows with documented PHI validation:
👉 Schedule a technical walkthrough
Questions about building HITL workflows for HIPAA-compliant environments?
👉 Contact our team





