
























































The Internet was revolutionized by a book store named Amazon and search engines du jour. Google ushered in the storage paradigm Amazon Web Services unleashing the 16 digits-to freedom-to-compute era of 1,000 startups a day.
Computing is now being pushed to the edge with decisions generated using artificial intelligence (AI). Google Search and Google Ads began using Hadoop as implemented by Yahoo to be consumable on a massive scale. Apache Spark has made the movement of data a tad more palatable from a latency standpoint. Streaming players like Confluent’s Kafka, Flink, and Druid have rendered fog computing a reality. Telco is now more than just a tunnel owner and can create different offers to Northbound and Southbound traffic. Data swamps and big data lakes no longer worry about arrival latencies, but give degrees of caps as service level agreements. They have given way to A/B testing anything imaginable, moving us from a data-centric to model-centric world.
The same AI (reinforcement learning) that defeated Lee Sedol is Automated Machine Learning (AutoML) that learned and created an intermediate language on its own from the translation of human language A to human language B. It has been democratized and is offered from a class of libraries that are ASIC aware (TPUs, GTX 2080s, D-Wave) from a set of world class companies (Tensorflow, Kaldi, PyTorch, MXNet, CNTK, cuDNN, spaCy, and CoreML from Google, Facebook, Amazon, Microsoft, Nvidia, Salesforce, Apple, etc.).
With this plethora of democratized AI available, remaining a data-centric enterprise without models is literally leaving money on the table. It used to be that throwing any data away was unthinkable because one might find the gold bullet from mining that data in future decades. But now with online learning, transfer and seq2seq models can help find meaning from data almost momentarily.
No one firm has a monopoly on the variety of available algorithms, libraries, and frameworks, and it’s almost foolhardy to think one can harness the beast all in-house. Agency specialists with domain knowledge make the difference between the winners and the losers.
Myth 1: Build it all in-house
Your pedigree can be your strength or weakness depending on how you deploy it. Very often, the technologist is attracted to the shiny new toy on the block while the bottom-line check writer is left scratching their head when they realize the lost dollar value in what is being built. The length of capital expenditure and operating expense debates are often indicators of analysis paralysis. The savvy engineering stakeholder sees the value in dividing large undertakings into tractable milestones tied to business use. This also forces organizations to review their in-house skills matrix and map to the requirements as well as augment efforts with first-class vendors and partners across the milestones. When staff augmentation is based on partnerships, build versus buy ceases to be a debate.
Myth 2: All the data must be harnessed before building the first model

The classic chicken and egg problem manifests itself when stories are blocked across sprints. The time tested solution is to buildmodular; build in small steps. Data wrangling for modeling is usually about whittling down to that small, meaningful, needle dataset from the big data haystack. Using agile groups that deliver in parallel is one tactic to solve the syndrome of forever data blocked.
Myth 3: Learning in production is risky

Building for observability is just beginning to gain a foothold in engineering operations. Web-scale application developers quickly learned that observability had to be a feature for uses such as Parse or Tango. The same applies when taking models to production. In reality, the model is exercised only in production
Online learning in production is the norm in the current generation of hyper-growth companies like Airbnb, Lyft and Uber; taking web-scale Amazon and Google A/B testing to a new level in the machine learning era. This implies building observability, interpretability, and reproducibility into models as first-class features.
Myth 4: Interpretability is undefined
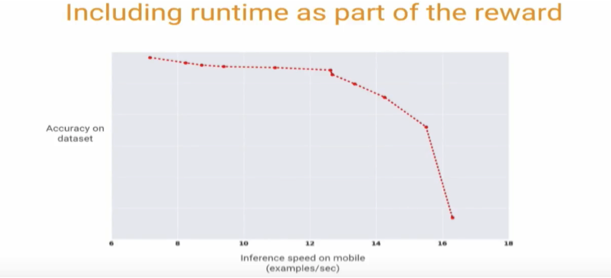
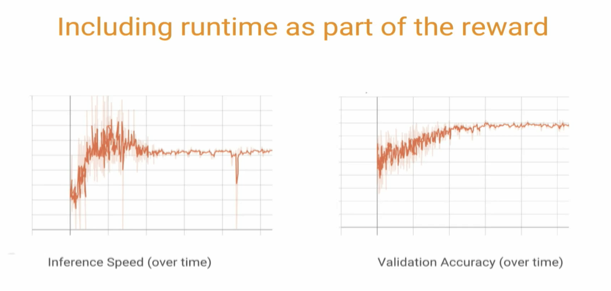
Projects like LIME are initial baby steps into the black box of why a neural network works the way it does.
As machine learning applications increasingly fall into the realm of everyday regulation, interpretability is a first-class feature for model building. TensorfFlow debugging is another step in the right direction.
Myth 5: This is a money pit

Reconciling the AI pipe dream with the realities of a quantifiable return is best achieved by good old agile and lean chunking of projects into measurable units. A goal that goes hand in hand with chunking is systematically killing projects that do not show promise. Common counterexamples are Boston Dynamics robots and autonomous driving. Moonshots have had enough of their arms and legs being chopped off to get them back on track. One gets there by being methodical about measuring progress and resetting goals. This is also why vendors and partners on these journeys are key. Not only do they function to provide a diversity of ideas and solutions, but they also share in the economic burden of the outcomes. When you tie a project to business outcomes and pick partners based on well-defined criteria and process, the money pit issue is definitely put to question if not to bed.
About Us
John Snow Labs Inc. is a DataOps company accelerating progress in analytics and data science by taking on the headache of managing data and platforms. A third of the team have a Ph.D. or M.D. degree and 75 percent have at least a master’s degree in multiple disciplines including data research, data engineering, data science, and security and compliance. We are a corporation based in Delaware, run as a global virtual team located in 15 countries around the globe. We believe in being great partners, making our customers wildly successful, and in using data philanthropy to make the world a better place.
Learn more about us on Twitter, LinkedIn, or our blog. Contact us for help on your next cutting-edge journey.
Discover how solutions like Generative AI in Healthcare and Healthcare Chatbot technology are empowering organizations to build scalable AI/ML capabilities while balancing innovation and practical deployment.
References
Tensorflow™ (2018). TensorFlow Debugger, [online] Available at: https://www.tensorflow.org/programmers_guide/debugger [Accessed 9 Apr. 2018]
Tulio Ribeiro, M., Singh, S., Guestrin C. (2016). Introduction to Local Interpretable Model-Agnostic Explanations (LIME), O’Reilly Media, Inc., [online] Available at: https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime [Accessed 9 Apr. 2018]



