Vector representations of texts longer than a word in natural language processing (NLP) refer to representing a sequence of words, chunks, or sentences as a vector in a high-dimensional space. This approach is often used in tasks such as text classification, sentiment analysis, and machine translation, where the input is typically a sequence of words or sentences rather than a single word.
Embeddings representing texts longer than a word are widely used in Spark NLP because they are a powerful tool for capturing the meaning and context of textual data, which is essential for many natural language processing (NLP) tasks. For example, in tasks such as sentiment analysis or text classification, the use of sentence embeddings can help to capture the overall meaning and context of a sentence, which can lead to more accurate predictions.
Traditionally, NLP models represent words in a sentence using word embeddings, where each word is represented by a vector in a high-dimensional space. However, these methods fail to capture the meaning of the sentence or a group of words as a whole.
Spark NLP is a popular open-source library for building scalable and efficient NLP pipelines, and it provides several methods for generating embeddings for texts longer than a word.
In NLP, sentence embeddings refer to the representation of a sentence as a single vector that captures its meaning and context. They are used to capture the meaning of a sentence and can be generated by using various techniques such as averaging or taking the sum of the word embeddings of the words in the sentence. Sentence embeddings can then be used as input to various downstream tasks such as sentiment analysis, text classification, or question answering.
Doc2Vec is a popular NLP technique for representing documents as vectors in a high-dimensional space. In Doc2Vec, each document is assigned a vector in a high-dimensional space, and each word in the document is also assigned a vector. These word vectors are trained along with the document vectors, and the training process aims to teach vectors that capture the semantic meaning of the words and documents. Once the vectors are trained, similar documents will have similar vectors in this high-dimensional space.
A “chunk” refers to a contiguous sequence of words or tokens that form a syntactic unit, such as a noun phrase or a verb phrase. For example, a noun phrase such as “the big red ball” or a verb phrase such as “running quickly” can be considered as chunks.
Chunk embeddings are vector representations generated for chunks of text, which can be phrases, clauses, or other segments of text that contain multiple words. These embeddings are useful in NLP tasks that require a finer level of granularity than word embeddings. Chunk embeddings can help capture the contextual meaning of a group of words in a more efficient way, as opposed to treating each word separately.
One use case for chunk embeddings is in named entity recognition (NER), where the goal is to identify and classify entities such as people, organizations, and locations in text. In this task, the use of chunk embeddings can help to capture the contextual information around a named entity, which can improve the accuracy of the NER system.
Spark NLP has multiple approaches for producing embeddings for longer pieces of text. In this article, we will discuss:
- Using
SentenceEmbeddings, an annotator that generates vector representations of sentences. - Using various
Doc2Vecmodels to generate a vector representation of a piece of text. - Using
ChunkEmbeddingsto generate vector representations of chunks in text.
Let us start with a short Spark NLP introduction and then discuss the details of producing embeddings techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
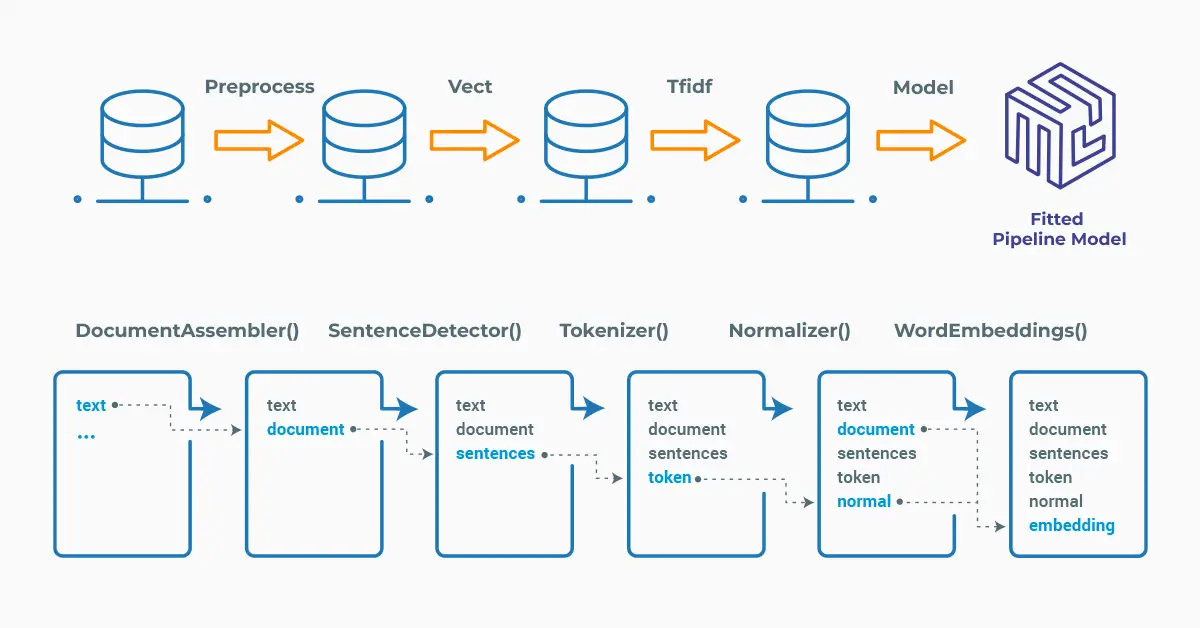
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
SentenceEmbeddings
The SentenceEmbeddings annotator in Spark NLP is a component that is used to generate vector representations of sentences that capture the meaning and context of the sentence in a fixed-length vector. They are generated by transforming a sentence into a numerical vector that preserves semantic information about the sentence, allowing it to be easily processed by machine learning algorithms.
SentenceEmbeddings annotator converts the results from WordEmbeddings, BertEmbeddings annotators into sentence embeddings by either summing up or averaging all the word embeddings in a sentence or a document.
Spark NLP has the pipeline approach and the pipeline will include the necessary stages. Let’s see the use of the annotator in an example, where we produce the sentence embeddings of a short text:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, LightPipeline, EmbeddingsFinisher
from sparknlp.annotator import (
Tokenizer,
WordEmbeddingsModel,
SentenceEmbeddings
)
import pyspark.sql.functions as F
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
glove_embeddings = WordEmbeddingsModel().pretrained() \
.setInputCols(["document",'token'])\
.setOutputCol("embeddings")\
.setCaseSensitive(False)
sentence_embeddings = SentenceEmbeddings() \
.setInputCols(["document", "embeddings"]) \
.setOutputCol("sentence_embeddings")
embeddings_finisher = EmbeddingsFinisher() \
.setInputCols(["sentence_embeddings"]) \
.setOutputCols(["finished_sentence_embeddings"])
pipeline = Pipeline(
stages=[document_assembler,
tokenizer,
glove_embeddings,
sentence_embeddings,
embeddings_finisher])
text = "John has seldom heard him mention her under any other name. In his eyes she eclipses and predominates the whole of her sex."
text_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(text_df)
result = model.transform(text_df)
Now, we will explore the results to get a nice dataframe of the text and the corresponding sentence embeddings:
result_df = result.select(F.explode(F.arrays_zip(result.sentence_embeddings.result,
result.sentence_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("sentence_embeddings"))
result_df.show(truncate=100)

Dataframe showing the text and the sentence embeddings
LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an array of strings instead, to be annotated.
Check this post to learn more about this class.
We can get predictions by running the following code:
light_model_emb = LightPipeline(pipelineModel = model, parse_embeddings=True) annotate_results_emb = light_model_emb.annotate(text)
Light Pipeline results for the first sentence is produced by the following code:
annotate_results_emb['sentence_embeddings'][0]

Doc2Vec
The Doc2Vec annotator in Spark NLP is a component that allows users to generate embeddings for documents or longer pieces of text using the Doc2Vec algorithm.
The algorithm works by training a neural network on a large corpus of documents, such as a collection of articles, books, or websites. During training, the network learns to predict the context of each document, or the words that are likely to appear in the document based on its content.
Once the network has been trained, it can be used to generate a fixed-length vector representation of any document in the corpus. This vector can be used for a variety of tasks, such as document classification, information retrieval, or recommendation systems.
Let’s define the text below first:
text = """John has seldom heard him mention her under any other name. In his eyes she eclipses and predominates the whole of her sex. It was not that he felt any emotion akin to love for Irene Adler. All emotions, and that one particularly, were abhorrent to his cold, precise but admirably balanced mind. He was, I take it, the most perfect reasoning and observing machine that the world has seen, but as a lover he would have placed himself in a false position. He never spoke of the softer passions, save with a gibe and a sneer. """
Now run the pipeline and produce the sentence embeddings using the pretrained Doc2Vec model from the John Snow Lab Model’s Hub:
# Import the required modules and classes
from sparknlp.annotator import (
SentenceDetector,
Normalizer,
StopWordsCleaner,
Doc2VecModel
)
document = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
sentencer = SentenceDetector() \
.setInputCols(["document"])\
.setOutputCol("sentence")
token = Tokenizer()\
.setInputCols("sentence")\
.setOutputCol("token")
norm = Normalizer()\
.setInputCols(["token"])\
.setOutputCol("normalized")\
.setLowercase(True)
stops = StopWordsCleaner.pretrained()\
.setInputCols("normalized")\
.setOutputCol("cleanedToken")
doc2Vec = Doc2VecModel.pretrained("doc2vec_gigaword_wiki_300", "en")\
.setInputCols("cleanedToken")\
.setOutputCol("sentence_embeddings")
pipeline = Pipeline() \
.setStages([
document,
sentencer,
token,
norm,
stops,
doc2Vec
])
Fit the input dataframe and then transform to generate the sentence embeddings:
data = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(data)
result = model.transform(data)
Now, we will explode the results to get a dataframe of the sentences and the corresponding sentence embeddings:
result_df = result.select(F.explode(F.arrays_zip(result.sentence.result,
result.sentence_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("sentence_embeddings"))
result_df.show(30, truncate=100)

Dataframe showing the sentences and their corresponding embeddings
And the Light Pipeline results will be produced by:
light_model_doc2vec = LightPipeline(pipelineModel = model, parse_embeddings=True) annotate_results_doc2vec = light_model_doc2vec.annotate(text) annotate_results_doc2vec['sentence_embeddings'][0]

One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run sentiment analysis with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
doc2vec_nlp = nlp.load("en.embed_sentence.doc2vec.gigaword_wiki_300").predict("""John has seldom heard him mention her under any other name.""")
doc2vec_nlp.head(1)
After using the one-liner model, the result shows sentence embeddings of the first sentence
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
ChunkEmbeddings
The ChunkEmbeddings annotator in Spark NLP is used to generate embeddings of chunks in text data. The embeddings are generated by averaging or taking the sum of the word embeddings for each chunk in the text.
This annotator is particularly useful when we want to capture the meaning of a larger span of text,a chunk, rather than just a single word. The pipeline first identifies the chunks in the input text, and then creates embeddings for each chunk.
One of the advantages of the ChunkEmbeddings annotator is that it allows us to capture the context and meaning of a chunk of text, even when individual words within that chunk may have multiple possible meanings. For example, the word “bank” could refer to a financial institution or the edge of a river. By using the context of the surrounding words in the chunk, the ChunkEmbeddings annotator can help disambiguate the meaning of such ambiguous words.
Let’s produce the chunk embeddings of a short text; first by extracting the named entities by an NER model and then generate the chunks by the NerConverter annotator. We will use the word embeddings and the chunks to produce the chunk embeddings by using the ChunkEmbeddings annotator:
# Import the required modules and classes
from sparknlp.annotator import (
BertEmbeddings,
NerDLModel,
NerConverter,
ChunkEmbeddings
)
documentAssembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
wordEmbeddings = BertEmbeddings().pretrained('bert_base_cased') \
.setInputCols(["document",'token'])\
.setOutputCol("word_embeddings")\
.setCaseSensitive(False)
nerModel = NerDLModel.pretrained("ner_dl_bert", "en") \
.setInputCols(["document", "token", "word_embeddings"]) \
.setOutputCol("ner")
nerConverter = NerConverter() \
.setInputCols(["document", "token", "ner"]) \
.setOutputCol("chunk")
chunkEmbeddings = ChunkEmbeddings() \
.setInputCols(["chunk", "word_embeddings"]) \
.setOutputCol("chunk_embeddings") \
.setPoolingStrategy("AVERAGE")
pipeline = Pipeline().setStages([
documentAssembler,
tokenizer,
wordEmbeddings,
nerModel,
nerConverter,
chunkEmbeddings
])
Make a dataframe of the text, fit and then transform the dataframe to get the embeddings:
text = "Stocks ended slightly higher on Friday but stayed near lows for
the year as oil prices surged past #36;46 a barrel, offsetting a positive
outlook from computer maker Dell Inc. (DELL.O) "
data = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(data)
result = model.transform(data)
Let’s explore to see the chunks extracted by the model and the chunk embeddings:
result.selectExpr("explode(chunk_embeddings) as result") \
.select("result.begin", "result.end", "result.result", "result.embeddings") \
.show(6, 150)

Dataframe showing the chunks and their corresponding embeddings
And the Light Pipeline results will be produced by:
light_model_chunk = LightPipeline(pipelineModel = model, parse_embeddings=True) annotate_results_chunk = light_model_chunk.annotate(text) annotate_results_chunk['chunk_embeddings'][0]

Chunk embeddings of the chunk “DELL.O”
For additional information, please consult the following references:
- Documentation : SentenceEmbeddings, Doc2Vec.
- Python Docs : SentenceEmbeddings, Doc2Vec.
- Scala Docs : SentenceEmbeddings, Doc2Vec.
- For extended examples of usage, see the Spark NLP Workshop repository.
- For LightPipelines, check this post.
Emerging Trends in Healthcare NLP
One of the most transformative trends is the rise of multimodal embeddings that combine textual data with other clinical signals such as medical images, lab results, and wearable sensor data. By integrating these sources into unified vector representations, healthcare NLP models are becoming more capable of understanding patient contexts holistically rather than relying on text alone. This shift allows clinical decision support systems to generate more accurate insights, reduce diagnostic ambiguity, and enable personalized care at scale.
Another major development is the increasing use of adaptive embeddings trained on continuously updated medical corpora. Unlike static embeddings, adaptive models learn from new clinical research, guidelines, and patient records as they are published. This continuous learning loop ensures that embeddings remain clinically relevant, reflect the latest evidence-based practices, and can adapt to changing medical knowledge without the need for complete retraining.
Finally, healthcare organizations are adopting federated and privacy-preserving embedding techniques to ensure compliance with regulatory frameworks while maintaining model performance. Instead of centralizing sensitive patient data, embeddings are generated and fine-tuned locally, then aggregated securely. This approach strengthens data governance, minimizes privacy risks, and accelerates the safe deployment of advanced NLP solutions in hospitals and research institutions.
Conclusion
Embeddings have revolutionized NLP by allowing computers to understand the meaning of words and their context in a text. While embeddings were originally developed for single words, researchers have expanded their use to longer texts such as chunks, sentences, paragraphs, and even entire documents. By representing longer texts as a combination of word embeddings, we can capture their semantic meaning and use this representation for various NLP tasks such as sentiment analysis, text classification, and machine translation.
Embeddings of longer texts have opened up new possibilities for NLP applications and continue to be an active area of research. By representing longer texts as a combination of embeddings, we can capture their semantic meaning and use this representation for various NLP tasks such as sentiment analysis, text classification, and machine translation.
FAQ
What’s the difference between SentenceEmbeddings, Doc2Vec, and ChunkEmbeddings in Spark NLP?
SentenceEmbeddings turn an entire sentence into a single vector, typically by pooling word-level embeddings. Doc2Vec learns document-level vectors directly from context during training and can represent longer passages more robustly. ChunkEmbeddings focus on spans like noun phrases or entities, giving finer-grained vectors that often help tasks such as NER or relation extraction.
When should I use averaging vs sum pooling for sentence or chunk embeddings?
Averaging is the safer default because it normalizes for variable length and reduces magnitude bias. Sum pooling can help when you want longer texts to have proportionally larger signal, but it may skew similarity scores; use it only if your downstream model is length-aware.
How do I evaluate whether my embeddings are “good” for my task?
Use extrinsic evaluation: plug embeddings into the downstream model (classification, retrieval, clustering) and compare metrics like F1, ROC-AUC, or NMI against baselines. For quick intrinsic checks, test cosine similarities on positive/negative pairs, visualize with PCA/UMAP, and verify that semantically close items cluster together.
How can I speed up training and inference in Spark NLP pipelines?
For large datasets, run pipelines on a Spark cluster, cache intermediate stages, and broadcast frequently used models. For small batches or real-time use, prefer LightPipeline (CPU-only, local, low-latency). Keep only essential annotators in the pipeline and reuse fitted PipelineModels rather than refitting.
Are these embeddings suitable for healthcare texts and sensitive data?
Yes, but handle data governance carefully: de-identify text before processing, log pipeline versions, and restrict access to PHI. If you need to adapt models, consider local fine-tuning or federated approaches so raw data stays on-prem while you still improve task performance.