
























































This blog article delves into the exciting synergy between the T5 model and Spark NLP, an open-source library built on Apache Spark, which enables seamless integration of cutting-edge NLP capabilities into your projects. We explore how the T5Transformer annotator in Spark NLP can be harnessed for two essential NLP tasks: text summarization and question answering.

Introduction
In the rapidly evolving world of Natural Language Processing (NLP), the combination of powerful models and scalable frameworks is paramount. Resource-intensive tasks in NLP such as Text Summarization and Question Answering especially benefit from efficient implementation of machine learning models on distributed systems such as Spark.
In the NLP world, Spark NLP is the top choice on enterprises that build NLP solutions. This open-source library built in Scala with a Python wrapper library implements state-of-the-art machine learning models to perform, in an easy-to-use pipeline design compatible with Spark ML.
The Text-to-Text Transformer (T5) model was released in 2019 by Google researchers and achieve impressive results in different NLP tasks. The novelty of the model was in its design, allowing multiple NLP tasks to be performed by the same model by adding a prefix on the inputs that indicates what task the model should perform. For example, to use text summarization with T5, we need to add the prefix “summarize:” to the input text. Other tasks have different prefix requisites, and an overall description of all tasks and their prefixes can be found here.
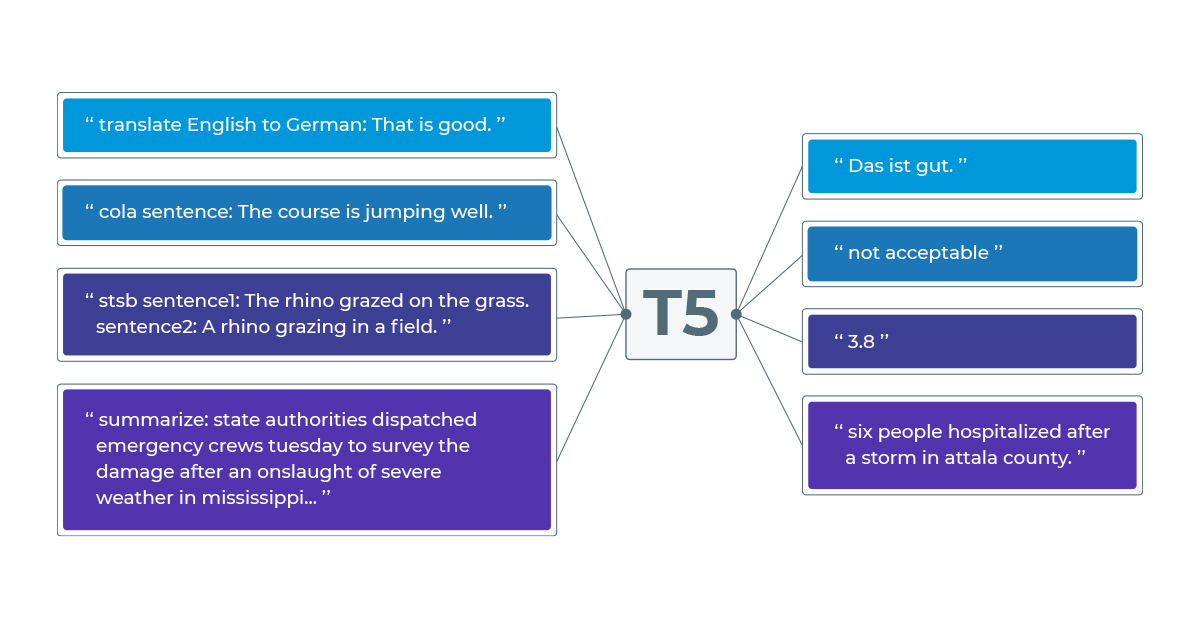
Diagram of the T5 model, from the original paper
In Spark NLP, the T5 model is implemented in the T5Transformer annotator. In the following sections, we will show how to use Spark NLP in Python to perform text summarization and question answering.
Using T5 with Spark NLP for Text Summarization
Text summarization is a critical component of NLP, offering the ability to distill lengthy documents into concise and informative summaries. To use the T5Transformer annotator in Spark NLP to perform this task, we need to create a pipeline with two stages: the first construct transforms the input text into an annotation object, and the second stage contains the T5 model. If you are not familiar with annotation concept, you can review it and other general concepts in Spark on this page.
For text summarization, as mentioned, we need to add the prefix summarize: in the input texts, and we can easily do that in the T5Transformer annotator by setting the parameter task to summarize:. In this article, we will use a pretrained T5 model, “t5_small”, for illustration purposes. Other pretrained models can be found on Spark NLP Models Hub. To use pretrained models in Spark NLP, we can simply use the .pretrained() methos from the corresponding annotator.
To start working with Spark NLP, all we need is to install the library:
pip install spark-nlp
Then, we import the libraries and start the spark session.
import sparknlp from sparknlp.base import DocumentAssembler, PipelineModel from sparknlp.annotator import T5Transformer # Start the Spark Session spark = sparknlp.start()
Now we can define the pipeline to use the T5 model. To do that, we use the PipelineModel object, since we are using the pretrained model and don’t need to train any stage of the pipeline.
# Transforms raw texts into `document` annotation
document_assembler = (
DocumentAssembler().setInputCol("text").setOutputCol("documents")
)
# The T5 model
t5 = (
T5Transformer.pretrained("t5_small")
.setTask("summarize:")
.setInputCols(["documents"])
.setMaxOutputLength(200)
.setOutputCol("t5")
)
# Define the Spark pipeline
pipeline = PipelineModel(stages = [document_assembler, t5])
To employ the model, just establish a Spark DataFrame containing the input data. In this illustration, we will work with a single sentence, but the framework can handle multiple texts for simultaneous processing. As per our defined pipeline, the initial input column from the DocumentAssembler annotator necessitates a column labeled as “text.” Therefore, we’ll structure the Spark DataFrame with a sole column named “text.”
example = """ Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled data sets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new Colossal Clean Crawled Corpus, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our data set, pre-trained models, and code. """ spark_df = spark.createDataFrame([[example]])
Finally, use the pipeline to summarize this example.
result = pipeline.transform(spark_df)
result.select("t5.result").show(truncate=False)
Obtaining:
transfer learning has emerged as a powerful technique in natural language processing (NLP) the effectiveness of transfer learning has given rise to a diversity of approaches, methodologies, and practice .
Please note that we defined the maximum output length to two hundred. Depending on the length of the original text, this parameter should be adapted. Longer texts will generate longer summaries, and shorter texts can be summarized in small sentences.
Using T5 with Spark NLP for Question Answering
There are two types of question answering that the T5 model can perform: open-book QA (a context is given, the model should extract the answer from the context) and closed-book QA (the model must answer based on his own knowledge). The open-book QA is useful if you know what information you want to extract from the text, while closed-book QA is useful for common and widely known concepts.
To answer questions with T5 in Spark NLP, we set the task parameter to question.
Open-book QA in Spark NLP
For open-book QA in Spark NLP, we need to prepare the input text following the pattern: question: {question} context: {context}. Let’s see an example:
context = 'context: Peters last week was terrible! He had an accident and broke his leg while skiing!' question1 = 'question: Why was peters week so bad? ' question2 = 'question: How did peter break his leg? '
We first prepare the input to the pattern above and then send them to spark DataFrame.
data = [[question1+context], [question2+context]]
spark_df = spark.createDataFrame(data).toDF('text')
We use the same objects as before on the summarization task, only update the task to question, then we redefine our pipeline model:
pipeline = PipelineModel(stages=[document_assembler, t5.setTask("task")])
result = pipeline.transform(spark_df)
result.select("t5.result").show(truncate=False)
Obtaining the answers:
- He had an accident and broke his leg while skiing
- skiing
These answers were present in the context, so the model was able to identify the part of the given text that contains the answer to the specific questions.
Closed-book QA in Spark NLP
For closed-book QA, all we need are the questions, without any context. The model will try to use its learned information to answer the questions. Note that if the model was trained with outdated information, then probably the answers will also be outdated.
questions = [
["Who is president of Nigeria? "],
["What is the most common language in India? "],
["What is the capital of Germany? "],
]
spark_df = spark.createDataFrame(questions).toDF("text")
result = model.transform(spark_df)
result.select(["text", "t5.result"]).show(truncate=False)
Obtaining:
+-------------------------------------------+------------------+ |text |result | +-------------------------------------------+------------------+ |Who is president of Nigeria? |[Muhammadu Buhari]| |What is the most common language in India? |[Hindi] | |What is the capital of Germany? |[Berlin] | +-------------------------------------------+------------------+
These answers were contained in the knowledge the model obtained during the training phase, and if the answers change over time (e.g., a new president is elected), then the model needs to be re-trained with updated data.
Conclusion
In the ever-expanding landscape of NLP in healthcare, legal, and other fields, the amalgamation of cutting-edge models and scalable frameworks is a game-changer. Spark NLP, built on the foundation of Apache Spark, opens doors to a world of possibilities by enabling seamless integration of the T5 model. From text summarization to question answering, the T5Transformer annotator provides a user-friendly interface for harnessing the power of T5.
In this article, we showed how to perform text summarization, open-book question answering, and closed-book question answering tasks in Spark NLP in Python, showing how to create the pipeline and make inference using pretrained models. By exploring this powerful combination, you can unlock innovative NLP solutions that are not only accurate but also scalable, thanks to the underlying Spark architecture.




