
























































Clinical NLP teams regularly deploy pre-annotation servers across multiple project types: NER for text extraction, Visual NER for document processing, classification models for categorization. Each project type requires compatible pipelines. Each deployment needs clear status feedback. When either visibility or compatibility breaks down, teams lose time troubleshooting issues that shouldn’t have occurred.
Two specific friction points can emerge in pre-annotation workflows: knowing which pipelines are compatible with the current project, and knowing whether a deployment is still initializing or ready to use.
These aren’t catastrophic failures. They’re operational friction. A team accidentally selects a Visual NER pipeline in an NER project and wonders why pre-annotation fails. Someone triggers deployment and isn’t sure if they should wait or if the server is ready. Each incident requires investigation. Each wastes time that should go toward actual annotation work.
Generative AI Lab addresses both issues with pipeline scoping that prevents incompatible selections and continuous deployment feedback that eliminates guesswork.
The Compatibility and Visibility Gaps
Pre-annotation servers are project, type specific. An NER pipeline processes plain text and extracts entities. A Visual NER pipeline processes documents with layout awareness. They’re fundamentally different tools built for different data structures.
Without project, type scoping, the pre-annotation modal doesn’t reflect that distinction. When a team deploys a Visual NER server for document processing, that server can appear as an available option in NER projects as well, suggesting compatibility that doesn’t exist.
This creates two problems.
Accidental incompatible selections. A user working in an NER project sees multiple pre- annotation servers listed. Some are NER, compatible. Some were deployed for Visual NER. Without clear filtering, nothing in the interface distinguishes them. Selecting an incompatible server means pre-annotation fails, and the failure isn’t immediately obvious, it just doesn’t produce results.
Unclear deployment status. When a team triggers pre–annotation deployment, a server spins up and loads the pipeline. That initialization takes time. Without continuous visibility into that process, teams face uncertainty: is deployment still running, or is the server ready? Without explicit signals, the interface provides no clear answer.
Both scenarios force teams to infer system state from indirect signals. Check server status manually. Try pre-annotation and see if it works. Wait longer than necessary to avoid timing issues. That inference work is overhead that slows workflows and erodes confidence in the tooling.
Pipeline Scoping: Only Show Compatible Resources
The pre-annotation modal filters pipeline visibility based on project type. When working in an NER project, only NER, compatible servers appear in the deployment list. Visual NER projects show only Visual NER pipelines. Classification projects show only classification resources.
The filtering happens automatically. Teams don’t configure it or manage compatibility manually. The system enforces project, type boundaries at the interface level, preventing incompatible selections before they can happen.
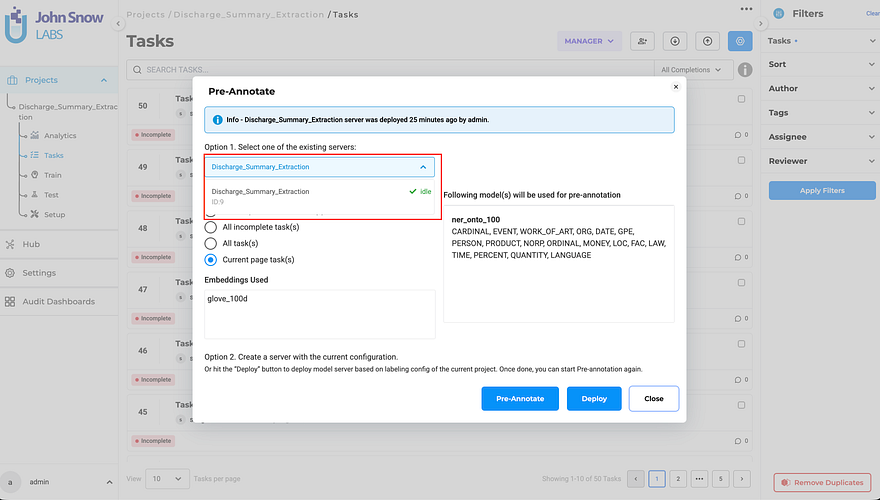
This matters because it removes a category of configuration errors. Teams no longer need to remember which servers were deployed for which project types. They don’t need to verify compatibility before selecting a pipeline. The interface only presents valid options. Invalid selections become impossible.
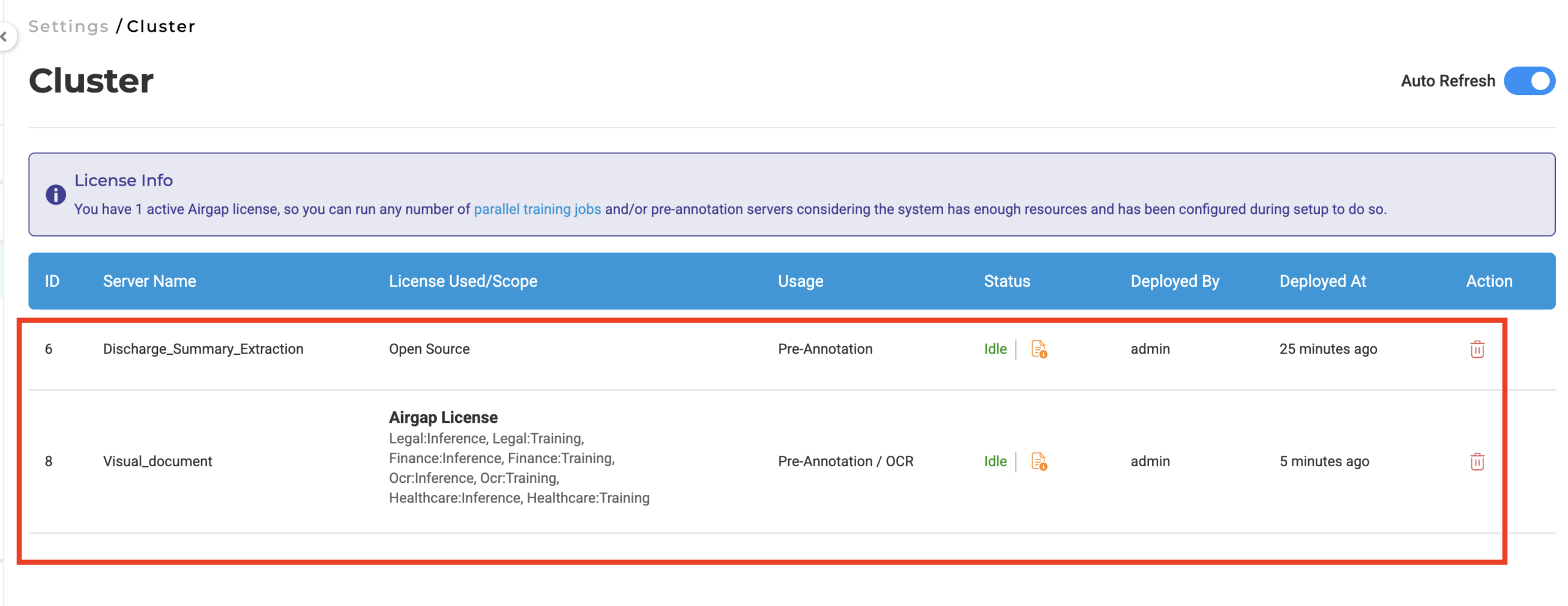
The Cluster page still shows all deployed servers across project types, administrators need that global view for resource management. But the pre-annotation modal shows only what’s relevant to the current workflow context.
Continuous Deployment Feedback: Visible Progress, Clear Status
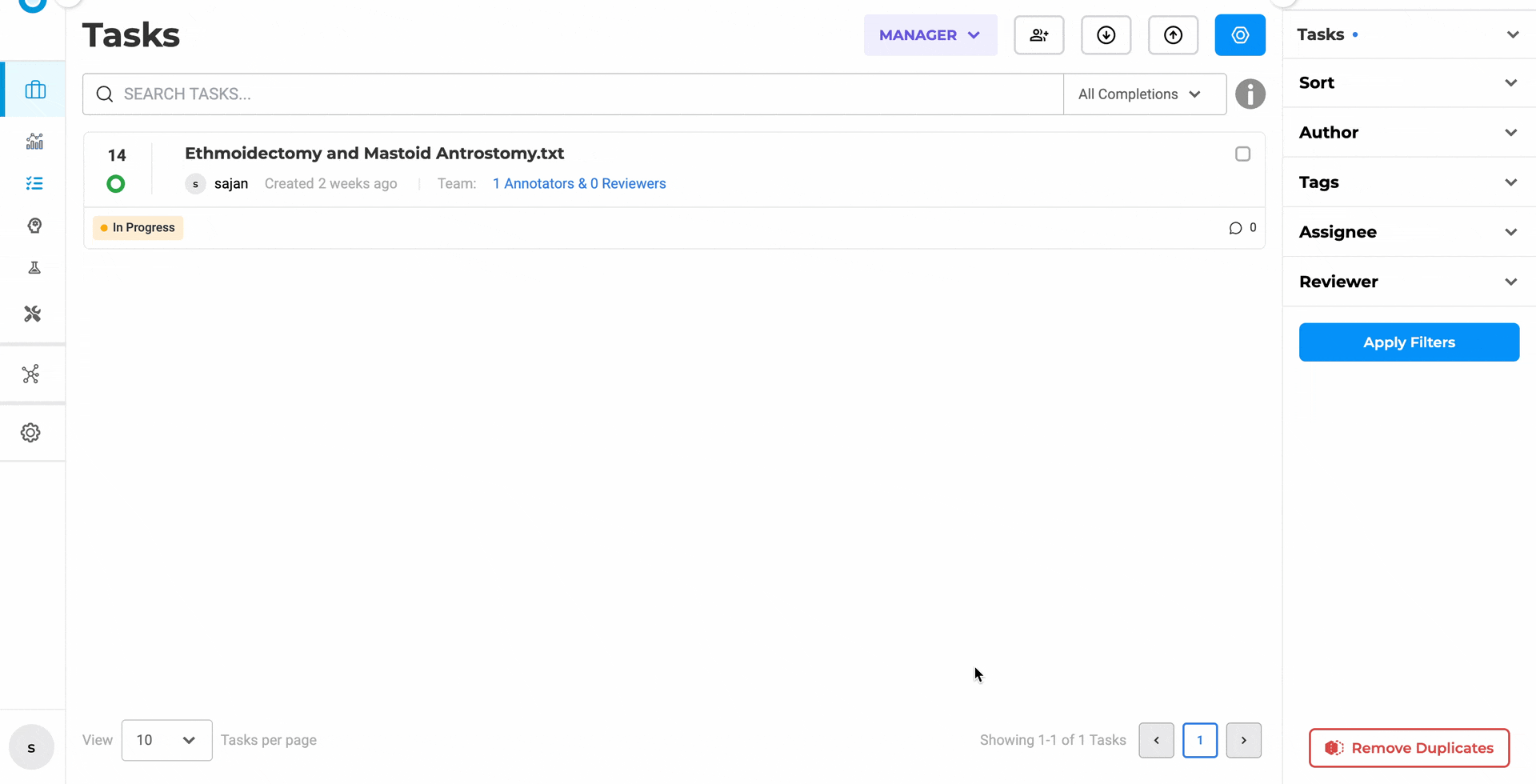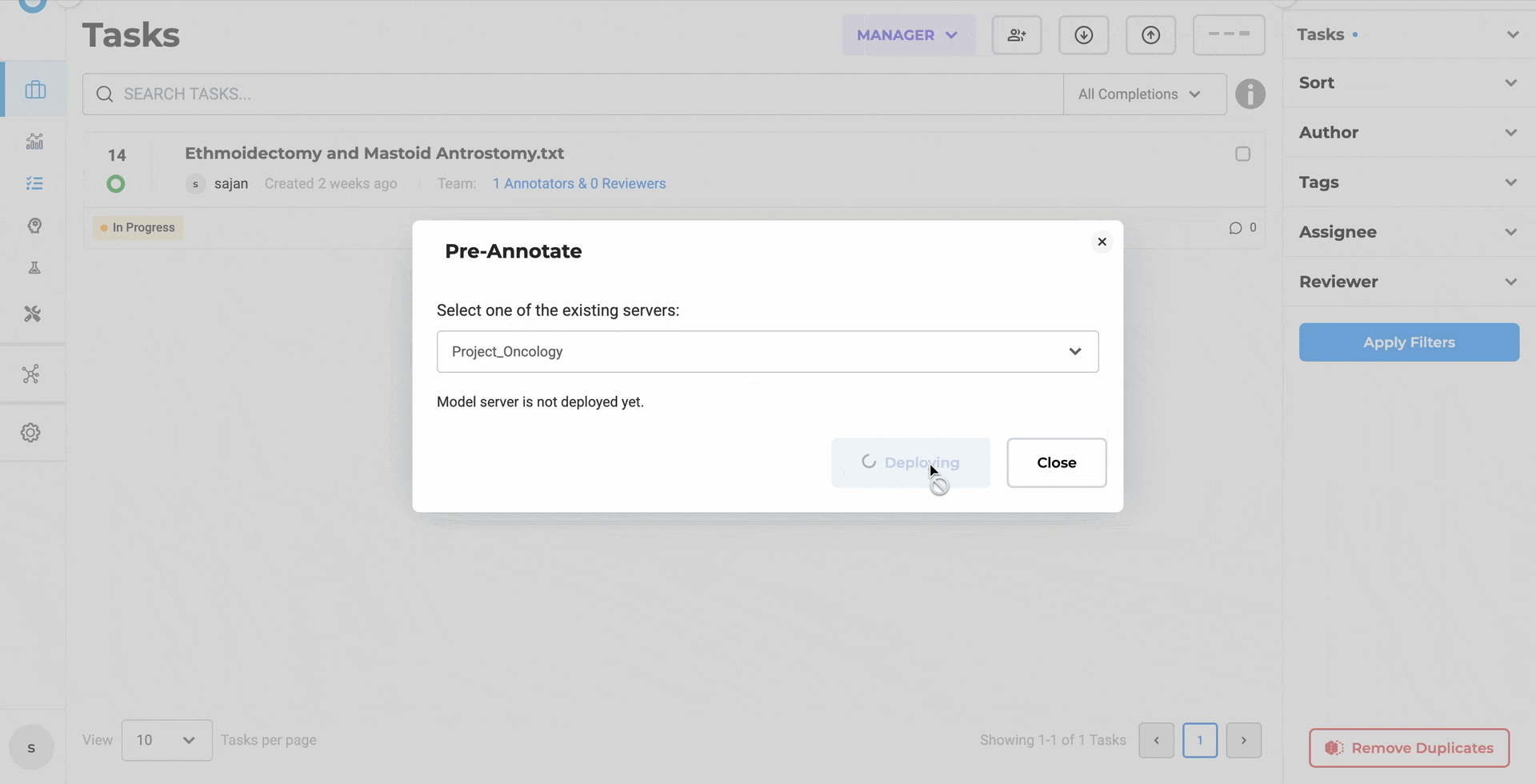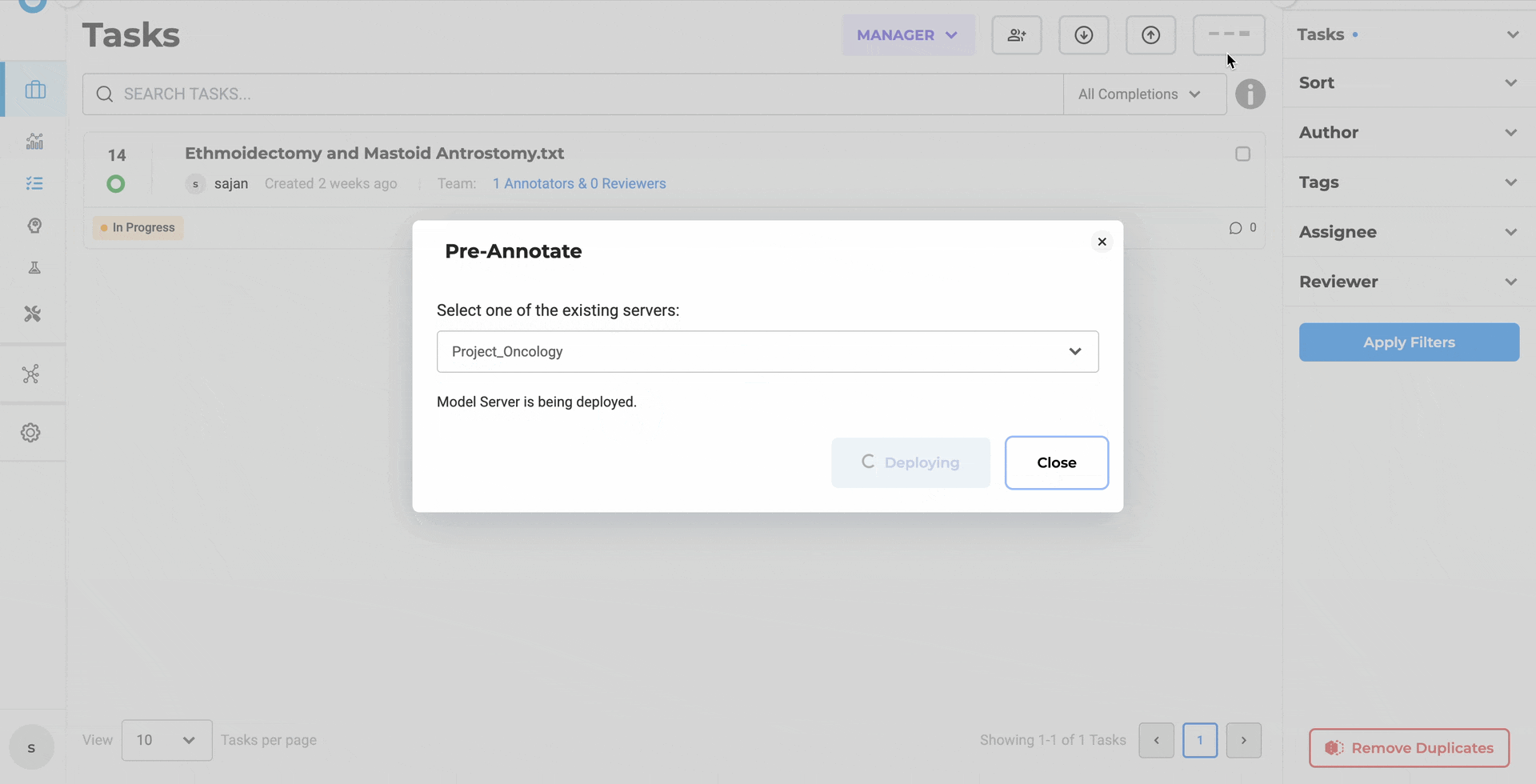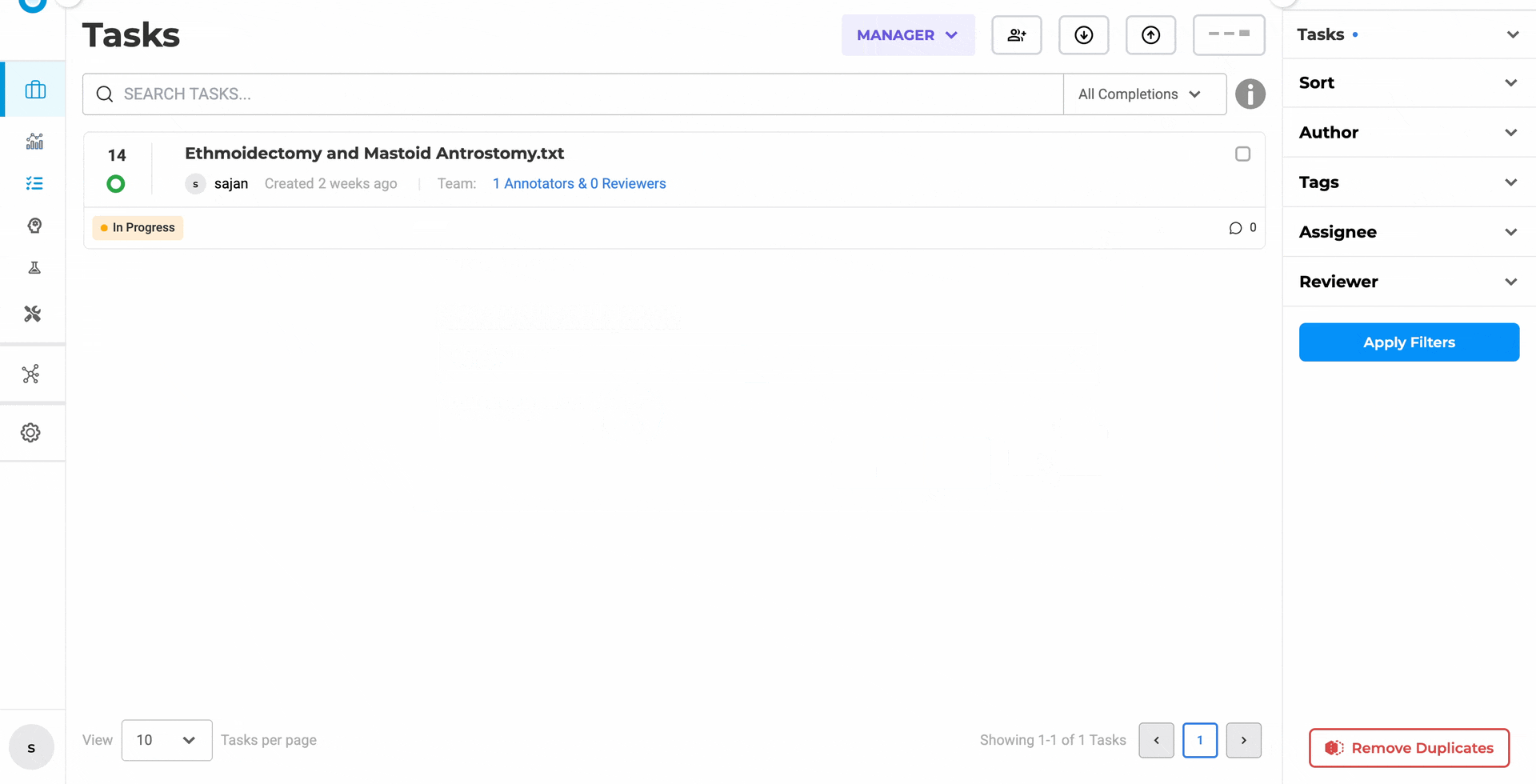
When pre-annotation deployment is triggered, the deployment modal remains open throughout server initialization, displaying real, time status updates. The interface shows what’s happening: server starting, pipeline loading, deployment progressing.
If the modal is closed during deployment, the Pre-Annotate button reflects the ongoing state with a loading indicator. The button updates automatically when the server becomes ready, transitioning to its active state to signal availability.
This eliminates the uncertainty that previously surrounded deployment. Teams don’t estimate how long initialization takes. They don’t refresh to check status separately. The interface communicates deployment progress explicitly. When the server is ready, the system says so unambiguously.
What Changes for Clinical NLP Teams
Fewer deployment errors. Teams working across multiple project types no longer accidentally select incompatible pipelines. An NER project shows NER resources. A Visual NER project shows Visual NER resources. The distinction is automatic and enforced.
Faster troubleshooting when issues do occur. If pre–annotation fails, teams know the pipeline was compatible, the problem is elsewhere. That eliminates one entire category of investigation. Debugging becomes more efficient because configuration errors are prevented structurally.
No more deployment guesswork. The interface shows deployment progress. The button state reflects server readiness. Teams can proceed confidently when deployment completes rather than waiting arbitrarily or trying operations before the server is ready.
The Iteration Factor
Healthcare AI workflows depend on iteration. Teams deploy pipelines to test configurations, evaluate results on sample data, refine settings, and redeploy. Each cycle should take minutes, not hours.
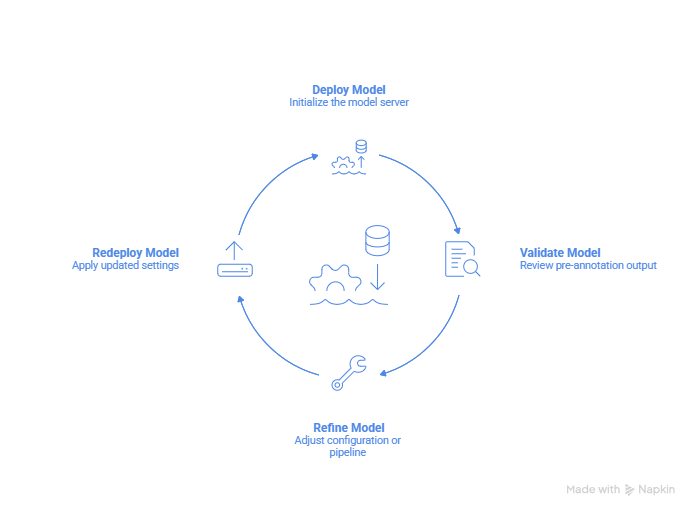
That iteration is productive when the system communicates clearly: which pipelines are compatible, whether deployment is complete, whether the configuration is ready for testing. It becomes friction when teams spend time diagnosing compatibility issues or waiting for deployments that may have already finished.
Pipeline scoping and deployment feedback remove that friction. Compatible resources are visible. Deployment status is explicit. Teams focus on improving models and configurations rather than verifying system state or troubleshooting preventable errors.
This is infrastructure that respects the reality of clinical NLP work: iteration is constant, and every cycle where the system forces interpretation rather than providing clarity is wasted time.
Learn More
Full technical details on pre-annotation enhancements and deployment workflows:
Questions about pre-annotation configuration, Playground testing, or server deployment? Our team is here to help.




