
























































Finance NLP 1.1.0 for Spark NLP has been released!

“Positive” sentiment analysis on Financial Texts, taken from Prosus FINBERT
We are happy to welcome the new 1.1.0 version of Financial NLP, including the following new capabilities. New models include:
Relation extration

finre_has_ticker:Bert-based Relation Extraction connecting Tickers with their Company names in a text;
Name Entity Recognition

NER models on Financial Annual Reports
finner_financial_small: A small version of a Financial NER model, retrieven financial information about revenues, losses, profits increases, decreases, expenses, amounts, fiscal year, dates, currencies, etc. Trained on SEC 10K filings. Demo available here.finner_financial_medium: A bigger version of the same model, trained with more data and more entities, including cash flow operations and liabilities.finner_financial_large: A bigger version of themediummodel, trained with twice the data.finner_sec_10k_summary: A better version of our NER model to extract information from the first page of 10k filings. Now with better embeddings. Demo available here.
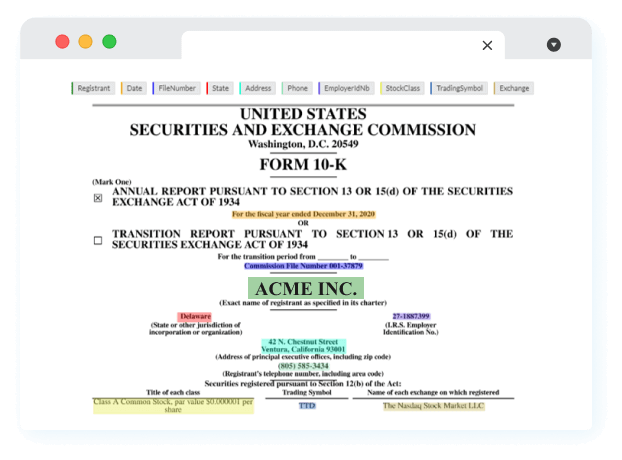
finner_sec_10k_summary model inference
Data Normalization and Augmentation
finel_nasdaq_data_company_name: Normalize company names to the official name using Nasdaq database.finel_nasdaq_data_ticker: Translate company names to tickers using Nasdaq database.finmapper_nasdaq_data_company_name: Extract company names using NEER, normalize them and then, use this model to retrieve publicly available information about them in Nadsaq, including: section, industry, ticker, category, sic codes, location, currency, previous name, and many more.finmapper_nasdaq_data_ticker: Extract tickers using NER and augment them with publicly available information about them in Nadsaq, including: section, industry, ticker, category, sic codes, location, currency, previous name, and many more.
Sentiment Analysis
We wanted to support non-majoritary languages by providing finclf_bert_sentiment_analysis, a Financial Sentiment Analysis model using in Lithuanian 🇱🇹 language.
Support for AWS, Azure and Databricks

Finance NLP on AWS, Azure or Databricks
All Finance NLP notebooks can be run in AWS, Azure and Databricks. If you use our ready to use versions of Spark NLP in AWS, Azure or Databricks, please find the notebooks here.If you are running on Google Colab, our notebooks are here.
Solution: Companies Ecosystem Graph
We have created a solution notebook: a ready-to-use series of Spark NLP commands to create a graph of companies ecosystem, and store it in networkX to then carry out Link or Node Prediction with Graph Embeddings.
A version for Databricks, and a reduced version of the notebook using Neo4j as graph databases can be found here.He are happy to announce too that we have been working with the Financial area of Databrick to get a “Solution Accelerator” inside Databricks, using Financial NLP library. A Solution Accelerator is a ready-to-use series of notebooks, available and ready to spin up inside Databricks.Our Companies Ecosystem Solution notebooks include:
- Extracting Company’s information, including name, ticker, address, phone, exchange, fiscal year, state, etc.
- Extracting other Companies in the supply chain;
- Extracting mention to Products;
- Extracting People working on that companies and their positions;
- Extracting previous positions of those people in other companies;
- Extracting Competitors;
- Extracting relationships between entities;
- Assert Future, Past, Present tense and Certainty of events and affirmations.
- etc.
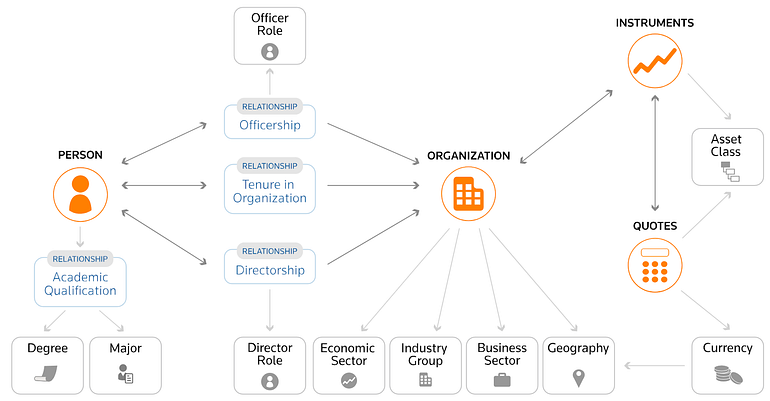
Different data extracted from SEC 10K filings and Wikidata
All of that information is processed and stores in form of a graph…
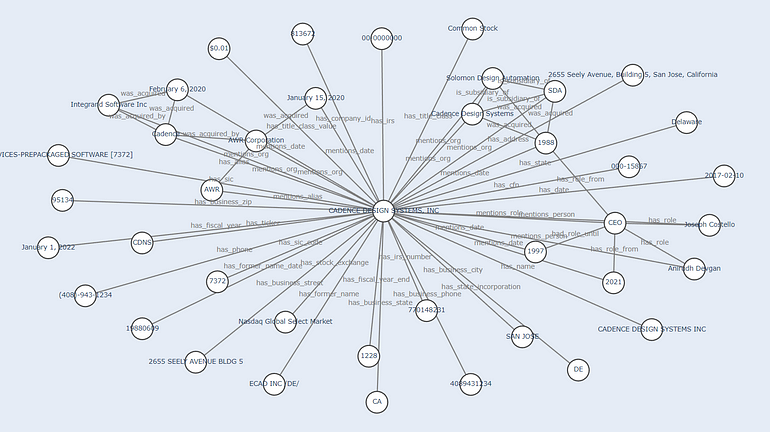
Plotly visualization of the graph extracted with Spark NLP for Finance
… to be properly exploited by your favourite graph engine, or even use graph embeddings to infer new latent connections!
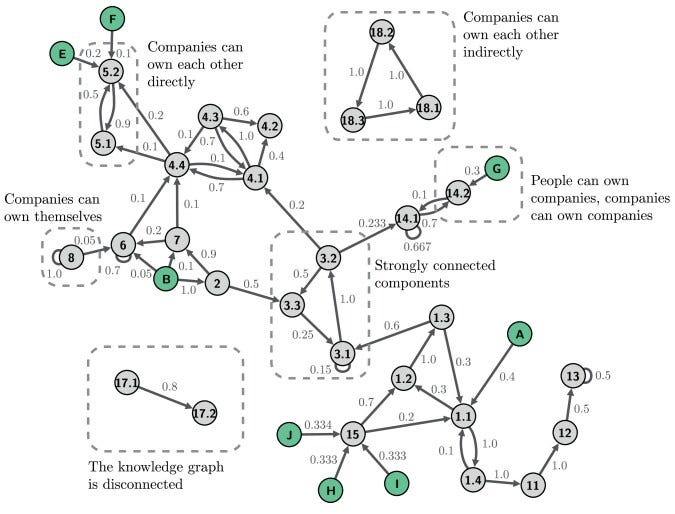
New node / link prediction (in green)
Finetuning Zero-shot Table Understanding
This release includes a notebook to finetune your own Zero-shot Table Understanding models on your own aggregation operations and import it to Spark NLP to run it at scale with all your other favourite Spark NLP models!
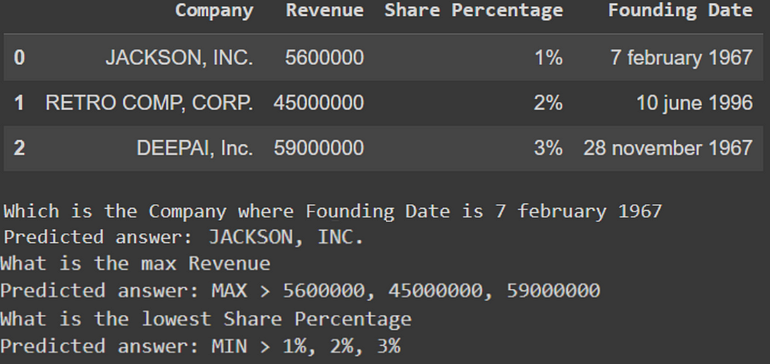
Result of TAPAS finetuned with in-house operators running in Spark NLP
TAPAS, besides returning the cells or cells answering to your questions, it can retrieve for you an operation to apply on those cells. This is called strong supervision. Base models include NONE ( just returning the cell), SUM, AVERAGE and COUNT.
New Docker Image
In here you will find how to run Finance NLP inside Docker.
New Medium Articles
- Series 1 of 2 articles about Financial Graph Creation using Finance NLP, available here. Stay tuned about version 2/2 about operations on Financial Graphs using Graph Embeddings.
Want to see more?
- Check our NLP Models
- Check our Notebooks
- Check our Demos
How to install
!pip install johnsnowlabs from johnsnowlabs import *
jsl.(json_license_path=[your_finance_license_path])start
jsl.(json_license_path=[your_finance_license_path])
Do you want to request a free trial?
Go to our self-service installation page here and request a trial. Write to support@johnsnowlabs.com if you have enquiries, or find us at our Slack Channel (#finance)





