























































The latest version of the library fixed some relevant errors on the deidentification pipelines on financial documents. With the fixes, the library is fully compatible with newer versions of Spark.
De-identification
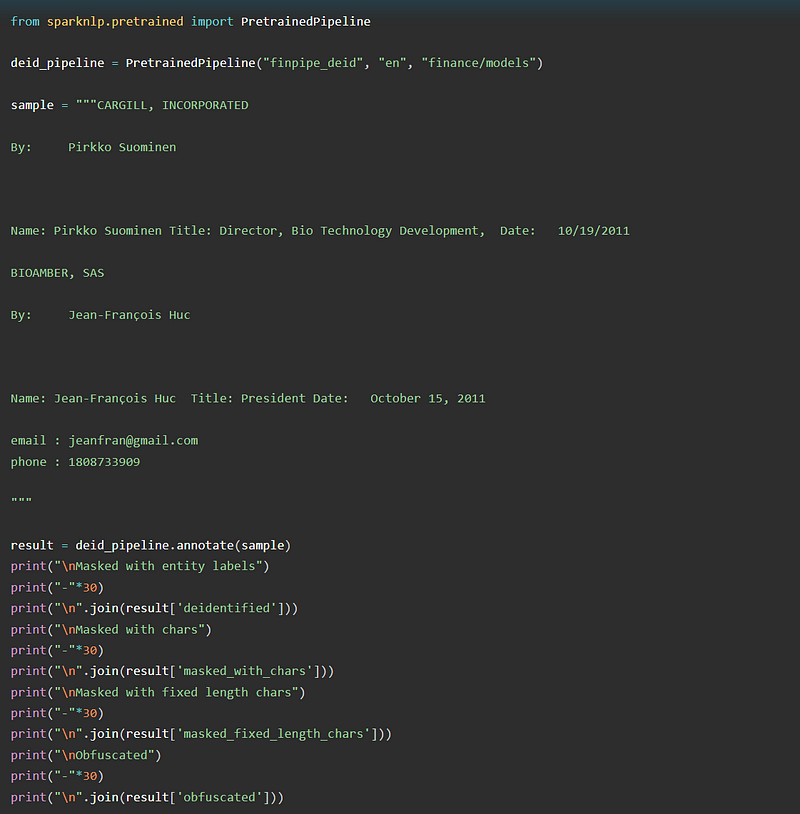
De-identification pipelines can be used to remove private or personal information from financial documents. This pipeline of NLP for financial services can be used to remove the information by masking it with entity labels, special characters, or obfuscating (changing with synthetic data). Use it with the PretrainedPipeline named finpipe_deid :
Obtaining:
Masking with entity labels:
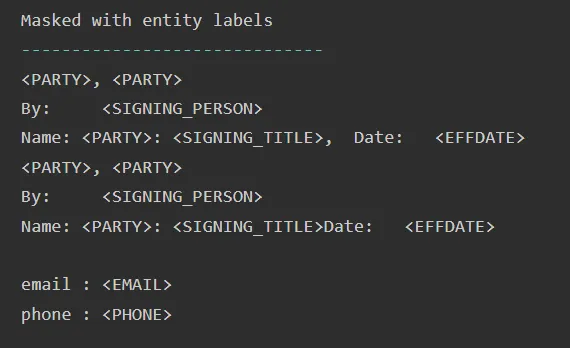
Masking with special chars:
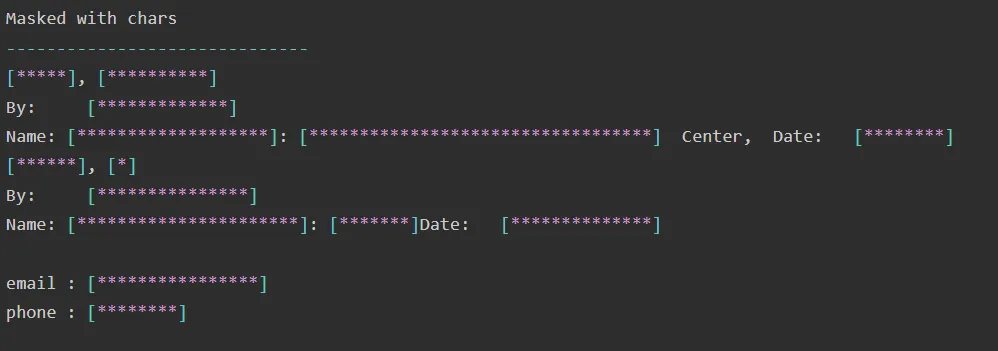
Masking with fixed-length chars:
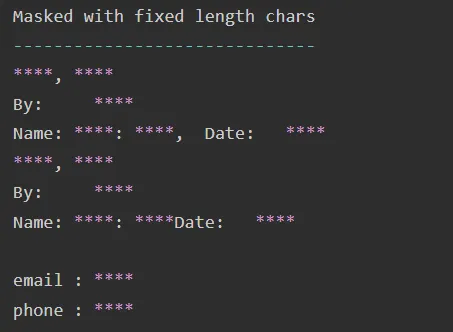
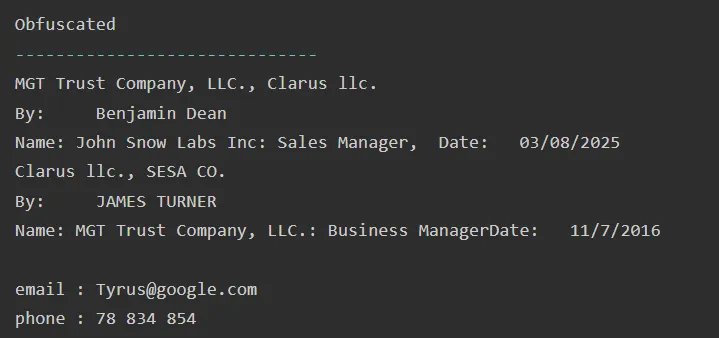
Obfuscated:
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our financial team of technical and SME. This trial includes complete access to more than 150 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 50+ financial language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Finance NLP is quite easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
from johnsnowlabs import nlp
nlp.install(force_browser=True)
Then we can import the Finance NLP module and start working with Spark.
from johnsnowlabs import finance
# Start Spark Session spark = nlp.start()
For alternative installation methods of how to install in specific environments, please check the docs.





