
























































The latest version of the library comes with a better embedding model and a new demo app for Aspect-Based Sentiment Analysis

BGE Sentence Embedding Model
The new model adds to the library’s capabilities to create vector representations of financial texts aimed at performing Retrieval Augmented Generation (RAG) applications. BAAI General Embeddings (BGE) is one of the top open-source models for retrieval applications, according to MTEB.
To use the model in Legal NLP, add the BertEmbeddings annotator with the legembeddings_bge_base pretrained model. This annotator requires document and token columns:
documentAssembler = (
nlp.DocumentAssembler().setInputCol("text").setOutputCol("document")
)
tokenizer = nlp.Tokenizer().setInputCols("document").setOutputCol("token")
bge = (
nlp.BertEmbeddings.pretrained(
"finembeddings_bge_base", "en", "finance/models"
)
.setInputCols(["document", "token"])
.setOutputCol("bge")
)
pipeline = nlp.Pipeline(stages=[documentAssembler, tokenizer, bge])
Then, we can create an example sentence to transform using the pipeline:
example = spark.createDataFrame(
[["""What is the best way to invest in the stock market?"""]]
).toDF("text")
result = (
pipeline.fit(example)
.transform(example)
.selectExpr("explode(bge.embeddings) as bge_embeddings")
The obtained result contains word embeddings with the BGE vectors. If we want to transform it into a sentence embedding, we can use the SentenceEmbeddings annotator to apply a pooling strategy (currently AVERAGE and SUM are available.
sent_embedding = (
nlp.SentenceEmbedings()
.setInputCols(["document", "bge"])
.setOutputCol("sentence_bge")
.setPoolingStrategy("AVERAGE")
)
New ABSA demo app
The new demo app shows the capabilities of the previously released ABSA model, which can identify financial entities in the text and classify them on financial sentiments. The demo is available at this link.
For example, the sentence:
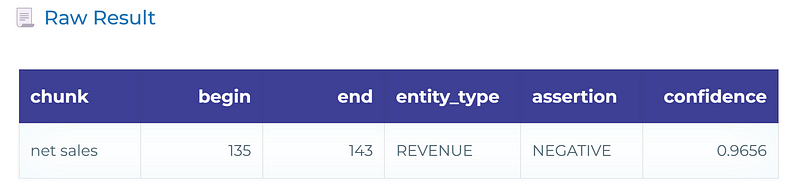
Very few regions were immune from the harsh winter, but our segregation focused on those stores where we believe the adverse impact on net sales was significant
The model can identify net sales as a financial entity (REVENUE), with a NEGATIVE sentiment associated with it.
Fancy trying?
We’ve got 30-day free licenses for you with technical support from our financial team of technical and SMEs. This trial includes complete access to more than 150 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc., and 50+ financial language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Finance NLP is relatively easy to run on both clusters and driver-only environments using johnsnowlabs library:
Install the johnsnowlabs library:
pip install johnsnowlabs
Then, on Python, install NLP for finance with
from johnsnowlabs import nlp nlp.install(force_browser=True)
Then, we can import the Finance NLP module and start working with Spark.
from johnsnowlabs import nlp, finance # Start Spark Session spark = nlp.start()
methods of how to install in specific environments, please check the docs.





