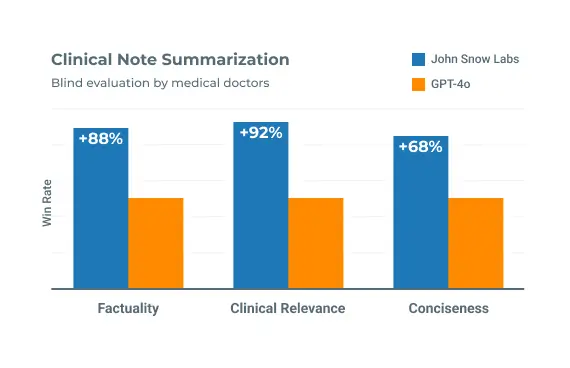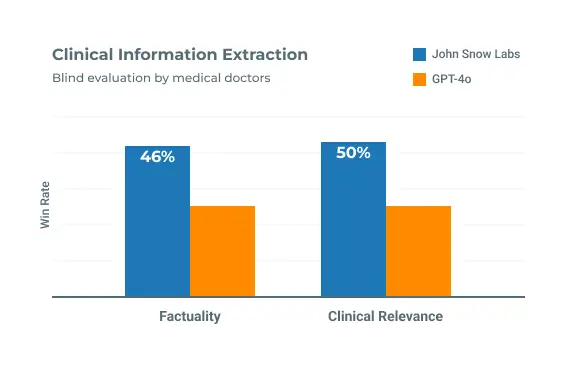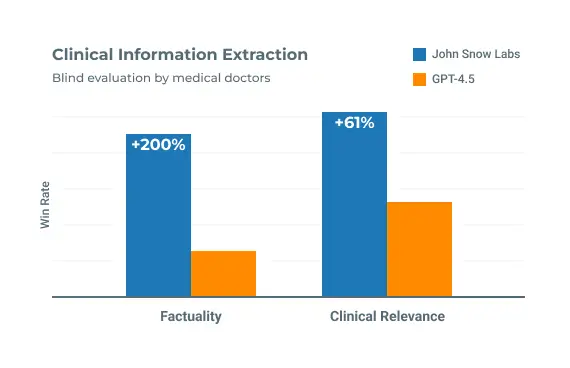

































State-of-the-Art Medical Language Models
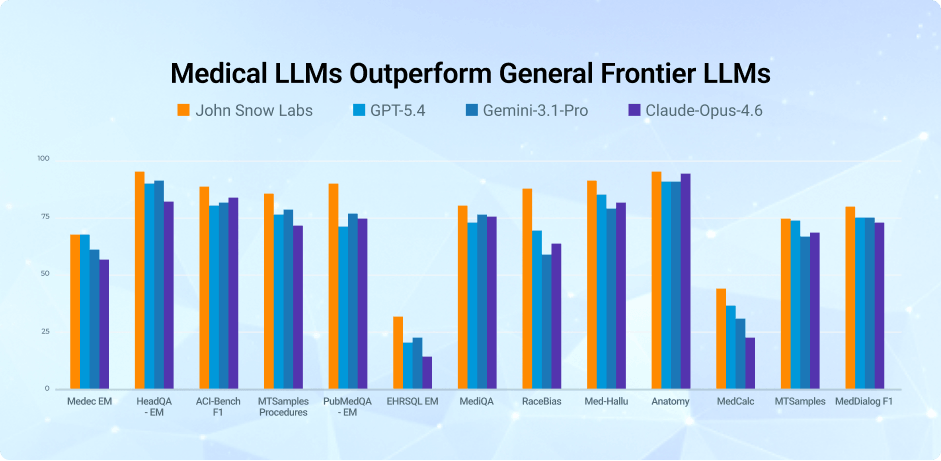
- Delivers up to 8.6 point higher accuracy than leading frontier models – GPT-5.4, Gemini-3.1-Pro, and Claude-Opus-4.6 – across key medical benchmarks
- Purpose-built for medical language, not general text
- Runs privately inside your environment, with no external API dependency
- Single-GPU deployment, enabling predictable performance, and cost control