























































We benchmarked OpenAI Privacy Filter against a John Snow Labs de-identification pipeline on 381,959 tokens of real clinical text. The John Snow Labs pipeline reached 0.95 F1 on PHI detection vs. 0.55 for OpenAI Privacy Filter, with 0.98 recall vs. 0.64. It ran 5.8× faster on CPU. The label mapping was deliberately conservative: ambiguous clinical labels were not forced into OpenAI’s taxonomy.
OpenAI recently released openai/privacy-filter, a permissively-licensed token-classification model for detecting personally identifiable information. Because PII detection is the first step in most clinical de-identification pipelines, we ran a head-to-head benchmark: how does a general-purpose privacy model compare with a healthcare-specific pipeline on real clinical text? On 381,959 tokens of clinical notes, the John Snow Labs pipeline achieved 0.95 F1 on PHI detection vs. 0.55 for OpenAI Privacy Filter, and ran 5.8× faster on CPU.
Why PII detection alone is not enough for clinical text
OpenAI Privacy Filter is a general-purpose PII detector. The John Snow Labs pipeline targets clinical PHI. The difference matters because a date, hospital name, doctor name, or insurance number is not always identifying on its own, but becomes PHI when it appears inside a clinical note tied to a specific patient. The real test is whether a model finds those identifiers in the messy, abbreviated language of clinical text.
The Medical Language Models stack at John Snow Labs
John Snow Labs builds Medical Language Models for healthcare and life sciences — covering clinical NER, assertion status detection, entity resolution, relation extraction, and de-identification. The de-identification pipelines combine multiple NER models with rule-based annotators and run on CPU. For this benchmark we used clinical_deidentification_docwise_benchmark_optimized_v2, the most accurate CPU-optimized variant in the current pipeline library.
What OpenAI Privacy Filter is built for
OpenAI Privacy Filter is a bidirectional token classifier released on Hugging Face for general PII detection and masking. It is licensed under Apache 2.0 and designed for high-throughput data sanitization. It detects eight privacy span categories: account_number, private_address, private_email, private_person, private_phone, private_url, private_date, and secret. Architecturally, it labels input tokens in a forward pass and decodes spans using constrained sequence decoding, with a long context window and runtime controls for precision-recall tradeoffs.
Clinical de-identification pipelines available
John Snow Labs provides a library of pretrained clinical de-identification pipelines designed for different environments and use cases. Some pipelines combine multiple NER models with rule-based annotators for higher accuracy, while optimized configurations are built to run efficiently on CPU. Zero-shot variants are also available; these are more generic and easier to adapt, making them a practical option when the entity taxonomy needs to be customized.
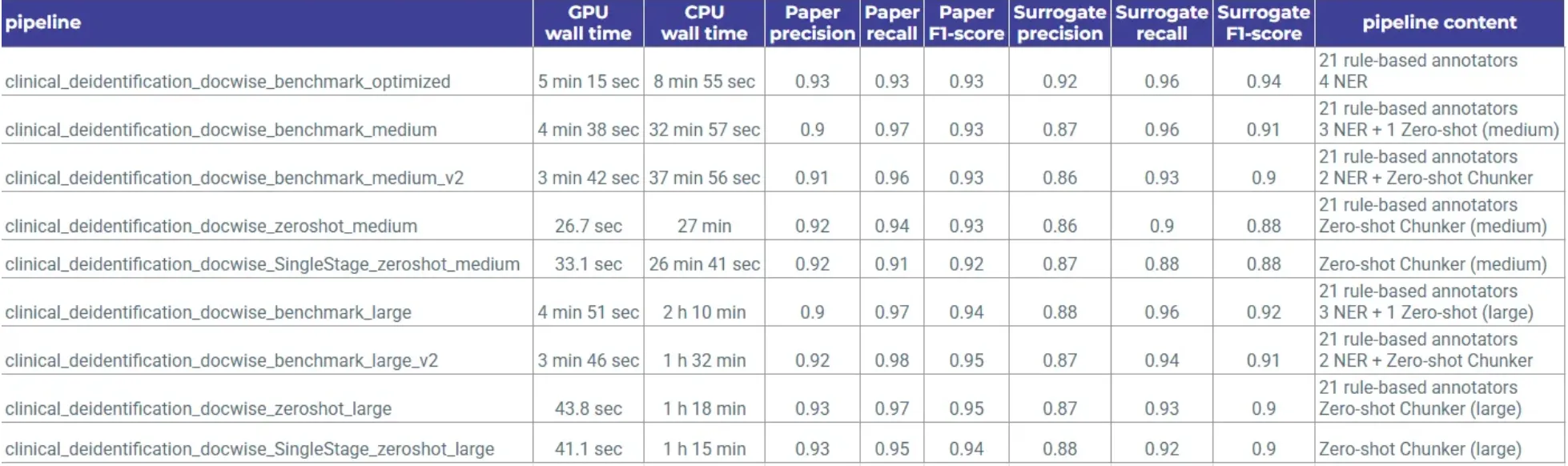
Most Up-to-Date Clinical Deidentification Pipelines
The benchmark dataset: 381,959 tokens, 3.25% PHI density
The dataset is private and contains a mix of clinical note types from public and proprietary sources, annotated by medical experts. Raw text cannot be shared, but aggregate statistics can.
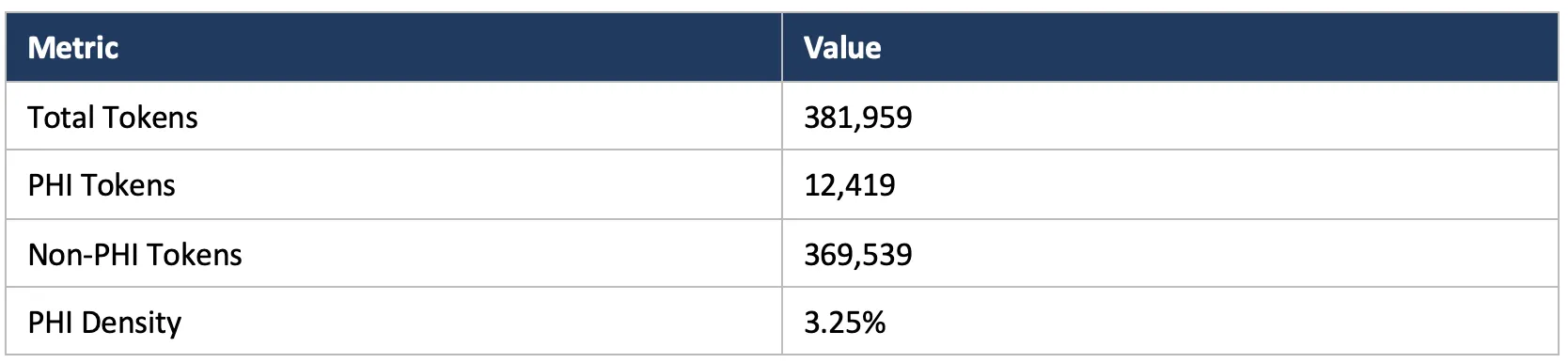
Dataset Overview
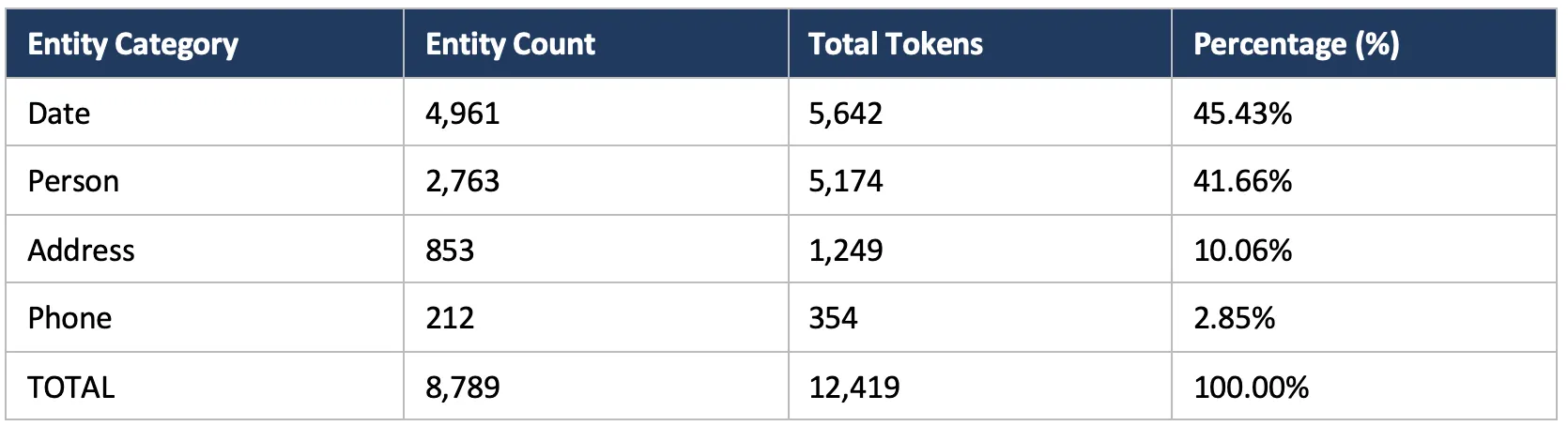
Entity Distribution Analysis
Some OpenAI taxonomy labels — account_number, private_url, and secret — were not present in the final gold set used for this comparison. We did not invent ground truth for them, and we did not force ambiguous clinical labels into them. We did observe that the model tends to predict number-heavy tokens as account_number, even when they do not correspond to actual account identifiers in the clinical context.
How we mapped clinical PHI labels to OpenAI’s taxonomy

The label mapping was intentionally strict. Clear person labels such as DOCTOR, PATIENT, DOCTOR_NAME, PATIENT_NAME, and OTHER_NAME map to private_person. Clear address-like labels such as CITY, STATE, COUNTRY, ZIP, STREET, and LOCATION map to private_address. We avoided forcing identifiers such as medical record numbers or health plan IDs into account_number unless that category existed cleanly in the benchmark target. This keeps the comparison honest.
This methodology extends the evaluation framework in our peer-reviewed paper Can Zero-Shot Commercial APIs Deliver Regulatory-Grade Clinical Text De-Identification? (Kocaman, Santas, Gul, Butgul, Talby), which covers Azure, AWS, and GPT-4o on the same task.
Accuracy: 0.95 F1 vs. 0.55 F1 on PHI detection
Entity-level metrics:
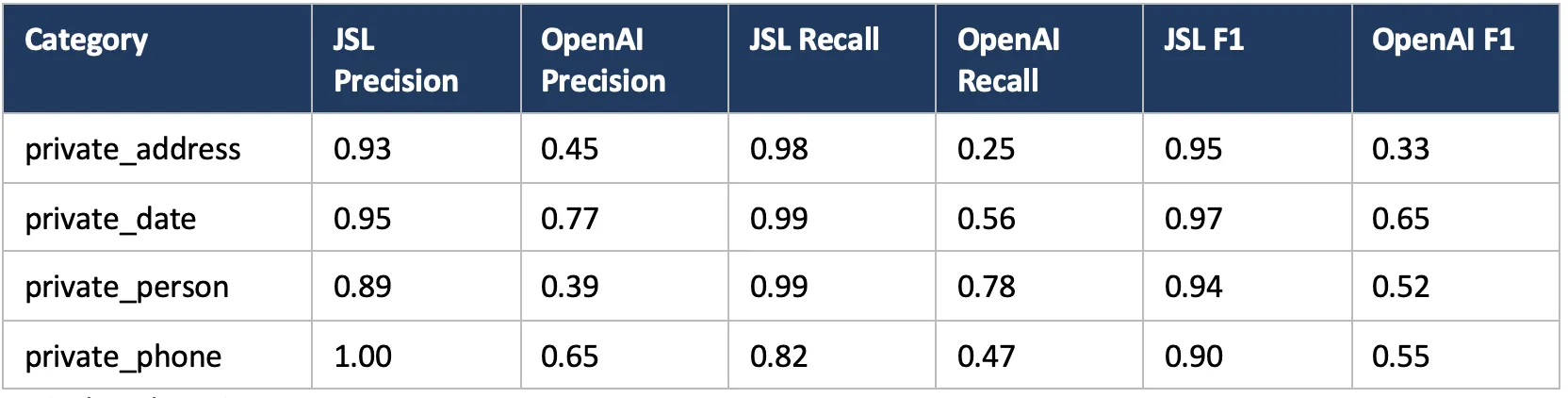
Entity Based Metrics
Binary metrics (PHI vs. non-PHI):

Binary (PHI vs. non-PHI) Metrics
OpenAI Privacy Filter detected a meaningful amount of PII, but it missed a lot and produced many false positives. The John Snow Labs optimized pipeline captured nearly all PHI tokens while keeping precision much higher.
Speed: 5.8× faster on CPU
Speed matters because de-identification is rarely a one-document problem. It is usually thousands, millions, or hundreds of millions of clinical notes. We benchmarked speed on 1,000 text units using a CPU Colab runtime. The sample contained 45,146 characters and approximately 8,738 tokens.

Speed Benchmark
On this CPU benchmark, the John Snow Labs pipeline was about 5.8× faster by mean runtime. This matters in healthcare environments where GPU availability is limited, expensive, or operationally inconvenient. GPU acceleration is great when you have it. A CPU-friendly production pipeline is better when you need the system to run everywhere your data lives, on-premises or in a private cloud.
What each model found in a real clinical note
Numbers tell most of the story; examples make the difference concrete.
OpenAI Privacy Filter:

Healthcare NLP:

On a representative clinical text, OpenAI Privacy Filter detected only the clinician name (Margaret A. Holloway, M.D.) and missed the phone number, hospital name, and address. The John Snow Labs pipeline captured the hospital name, phone number, doctor name, and address, and provided a granular entity breakdown by separating location fields into STREET, CITY, STATE, and ZIP.
Why a domain-specific pipeline still wins
OpenAI Privacy Filter is a useful general-purpose privacy model. It’s permissively licensed and easy to run.
Clinical PHI detection has its own structure, shortcuts, abbreviations, and failure modes that general PII models do not see in training. In this benchmark, that difference showed upclearly. The John Snow Labs optimized pipeline found more PHI, missed less sensitive information, and produced fewer false alarms. It did this while running efficiently on CPU, which matters in real healthcare deployments where GPU access is not always guaranteed.
The practical conclusion is simple. If you are de-identifying clinical text, use a system built for clinical text.
Try it yourself
- Open the clinical de-identification Colab notebookto run the pipeline on your own data.
- Read the peer-reviewed paper Can Zero-Shot Commercial APIs Deliver Regulatory-Grade Clinical Text De-Identification? For the full evaluation framework covering Azure, AWS, and GPT-4o on the same task.
- Schedule a call to discuss your de-identification project, or install the software for free.
Notes and limitations
This benchmark used a private dataset of clinical text, so data cannot be shared. The comparison used a conservative label mapping into OpenAI-compatible categories. Labels that were ambiguous or unsupported in the target taxonomy were not forced into the evaluation. Metrics may change on other datasets, institution-specific note styles, different PII policies, or different mapping choices. As always with PHI detection, evaluate on your own data before production deployment.
Frequently asked questions
What is the difference between PII and PHI for de-identification?
PII is any information that can directly or indirectly identify a person, such as names, emails, phone numbers, addresses, IDs, and URLs. PHI is the subset of PII that becomes protected health information when it is connected to care, diagnosis, treatment, payment, or medical records. A date or hospital nameon its own may be PII; the same value inside a clinical note tied to a specific patient is PHI under HIPAA.
Does OpenAI Privacy Filter satisfy HIPAA Safe Harbor or Expert Determination?
On its own, no. Safe Harbor requires removing 18 specific identifier categories, several of which (medical record numbers, health plan beneficiary numbers, device identifiers, biometric identifiers) are not covered by OpenAI Privacy Filter’s eight categories. Expert Determination requires statistical evidence of low re-identification risk, which depends on the full pipeline, not a single model. A purpose-built clinical de-identification pipeline is the practical path to either standard.
Why does the John Snow Labs pipeline run faster on CPU?
The optimized pipeline combines compact NER models with rule-based annotators and runs across Spark partitions in parallel. It is engineered for high throughput on commodity hardware rather than for GPU-only inference. In healthcare environments where GPU availability is limited or sensitive data must remain in a CPU-only enclave, that design wins on both cost and operational fit.
Can OpenAI Privacy Filter be fine-tuned for clinical text?
It can be fine-tuned in principle because it is permissively licensed and architecturally a standard token classifier. In practice, fine-tuning closes only part of the gap: clinical de-identification needs entity coverage beyond the eight built-in categories (medical record numbers, hospital names, dates relative to age over 89), plus rule-based post-processing for known failure modes. Fine-tuning a general model gets you partway; building for the domain gets you to regulatory-grade accuracy.
What clinical entity types do general PII models miss most often?
In this benchmark, the largest gaps were on addresses (0.25 OpenAI recall vs. 0.98) and dates (0.56 vs. 0.99). General models also struggle with hospital names, doctor names embedded in clinical templates, and abbreviated identifiers (MRN, MR#, PT ID). These categories are common in clinical notes and are exactly where domain-specific training and rule-based annotators add the most value.



