
























































John Snow Labs, the award-winning Healthcare AI and NLP company, announced the latest major release of its Spark NLP library – Spark NLP 5 – featuring the highly anticipated support for the ONNX runtime. The new release delivers material speedups for calculating text embeddings, a critical step in populating vector databases for RAG LLM and Semantic Search applications.
Spark NLP provides the fastest calculation of such embeddings currently available to the open-source community, as well as a set of pre-trained, state-of-the-art models. It comes with highly optimized builds for Intel, Nvidia, Apple, and Amazon processors, eliminating the need to integrate multiple other libraries that provide partial optimizations separately.
State-of-the-Art Accuracy, 100% Open Source
The Spark NLP Models Hub now includes over 500 ONYX-optimized models. These cover the most widely used transformer architectures such as BERT, RoBERTa, DeBERTa, ALBERT, DistilBERT, XLM-RoBERTa, and CamamBERT. The software and the models are open-source under the commercially permissive Apache 2.0 license.
The new release also introduces an array of new LLM models is fine-tuned specifically for chat and instruction: Optimized & quantized versions for the state-of-the-art INSTRUCT and E5 embeddings, which are currently dominating the top of the MTEB leaderboard, positioning themselves above OpenAI’s text-embedding-ada-002.
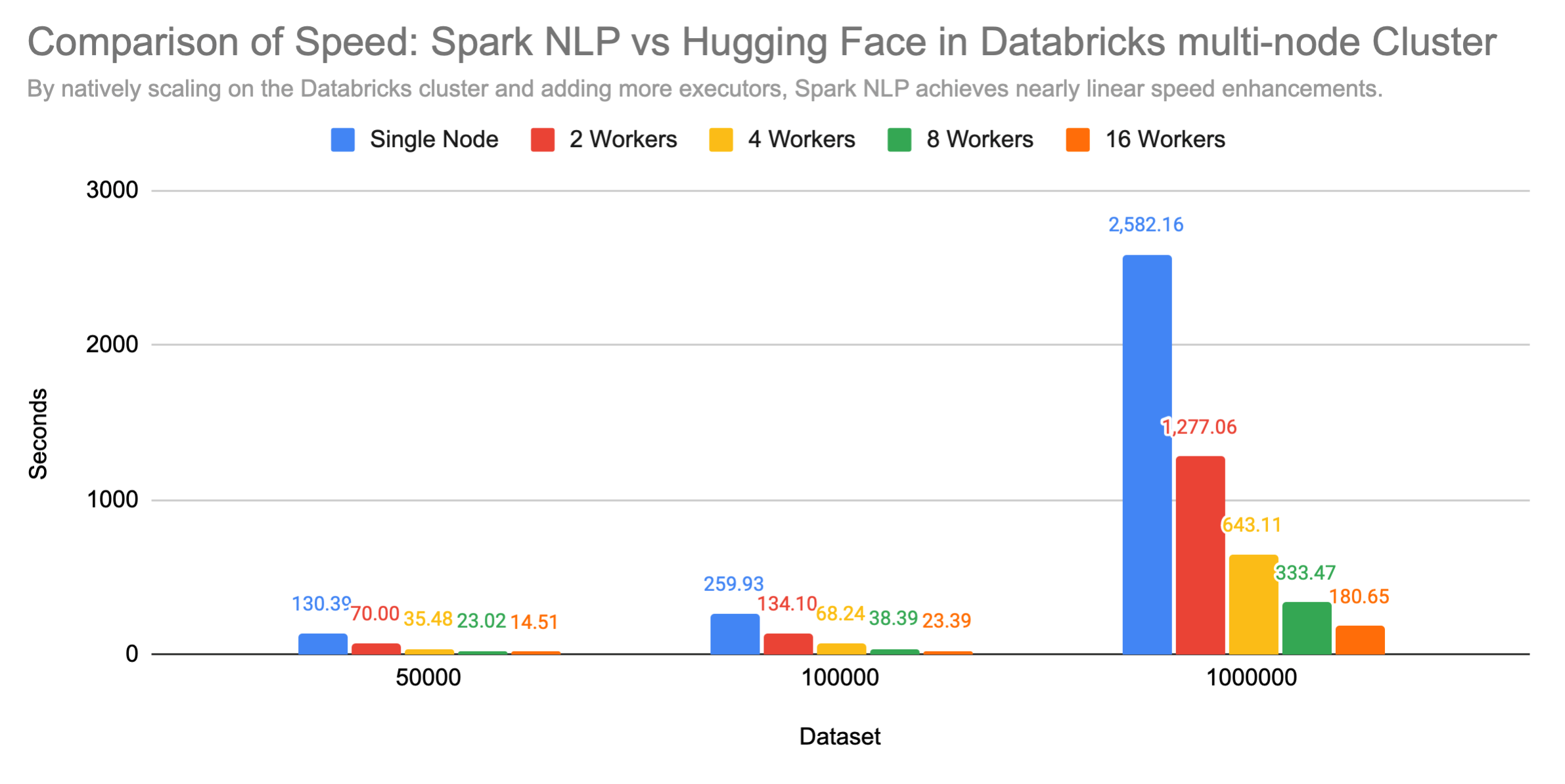
From 43 hours to 3 minutes to process 1 million records with zero code changes
Calculating text embeddings is a critical processing step before documents can be loaded into vector databases, which enables RAG LLM (Retreival-Assisted Generation for Large Language Models). These applications enable companies, for example, to ask a chatbot about their private documents, emails, or other confidential content. Therefore, being able to load a large body of documents into a vector database quickly, and keep it constantly updated, has been a pain point across the AI industry.
Spark NLP 5 delivers a speedup of two orders of magnitude to address this issue: one by speeding up each individual calculation, and the second by natively scaling it. Public benchmarks presented at the recent Data+AI Summit show the combined impact of these optimizations – reducing the time to process 1,000,000 documents from 43 hours to 3 minutes, on a Databricks cluster of 16 servers, compared to the Hugging Face implementation of the same models. Uniquely, scaling a Spark NLP pipeline requires no code changes and no other library.
3X to 7X Speedup for Calculating Document Embeddings on a Single Server
Public benchmarks have been published comparing the runtime of Spark NLP versus Hugging Face on a single server. The results show Spark NLP to be:
- 0 times faster on an HPE Server (32 cores and 80GB of memory)
- 0 times faster on a single Databricks node (32 cores and 64GB memory)
- 3 times faster on the free edition of Google Colab (2vCPU’s and 12GB memory)
This is possible since Spark NLP provides its own implementation of text embeddings calculation, that’s built from the ground up for speed & scale. The production-grade code and models built by John Snow Labs’ team stand in contrast to the academic codebase and models that are often used by the open-source AI community.
Spark NLP also provides quantized versions of each ONYX-optimized model. Quantized models provide another major boost in speed, but at the expense of a small drop in accuracy. For quantized models, the gap between the Spark NLP and Hugging Face implementation on a single server is even more pronounced:
- 4 times faster on an HPE Server (32 cores and 80GB of memory)
- 5 times faster on a single Databricks node (32 cores and 64GB memory)
- 7 times faster on the free edition of Google Colab (2vCPU’s and 12GB memory)
30% Growth in Downloads in 30 days
Downloads of Spark NLP have grown by more than 30% in the first month after the 5.0 release, showing the community’s enthusiasm and need for the new capabilities.
New chatbot applications that require semantic search across a large body of documents are already being built. This includes solutions that query all published medical research, all legal precedents of a state or country, or all regulatory documents related to a clinical trial.
“We are thrilled to present Spark NLP 5.0, a culmination of our team’s dedicated effort, innovative research, and commitment to delivering a comprehensive NLP library,” said Maziyar Panahi, Senior Data Scientist at John Snow Labs. “Our goal is to empower researchers and developers to harness the full potential of NLP, fostering innovation and driving impactful discoveries across diverse domains.”
Maziyar will present the webinar “From GPT-4 to Llama-2: Supercharging State-of-the-Art Embeddings for Vector Databases with Spark NLP” on Wednesday, August 23rd at 2pm ET. The webinar will provide a technical deep-dive of Spark NLP 5 to enhance your LLM’s efficiency, reliability, and scalability, improving your AI application’s overall performance. Join to learn practical strategies to boost retrieval for enterprise search, empowering businesses to take full advantage of technologies like GPT-4 and Llama-2.




