
























































We are delighted to announce the release of Spark NLP 5.0, featuring the highly anticipated support for ONNX!
We are delighted to announce the release of Spark NLP 5.0, featuring the highly anticipated support for ONNX! From the start of 2023, we have been working tirelessly to ensure that the integration of ONNX is not just possible but also seamless for all our users. With this support, you can look forward to faster inference, automatic optimization, and quantization when exporting your LLM models. Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP.
We have introduced two state-of-the-art models for text embedding, INSTRUCTOR and E5 embeddings. Currently, these models are leading the way on the MTEB leaderboard, even outperforming the widely recognized OpenAI text-embedding-ada-002. These cutting-edge models are now being utilized in production environments to populate Vector Databases. In addition, they are being paired with LLM models like Falcon, serving to augment their existing knowledge base and reduce the chances of hallucinations.
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines.
Spark NLP ❤️ ONNX
Introducing support for ONNX Runtime in Spark NLP🚀. Serving as a high-performance inference engine, ONNX Runtime can handle machine learning models in the ONNX format and has been proven to significantly boost inference performance across a multitude of models.
Our integration of ONNX Runtime has already led to substantial improvements when serving our LLM models, including BERT. Furthermore, this integration empowers Spark NLP users to optimize their model performance. As users export their models to ONNX, they can utilize the built-in features provided by libraries such as onnx-runtime, transformers, optimum, and PyTorch. Notably, these libraries offer out-of-the-box capabilities for optimization and quantization, enhancing model efficiency and performance.
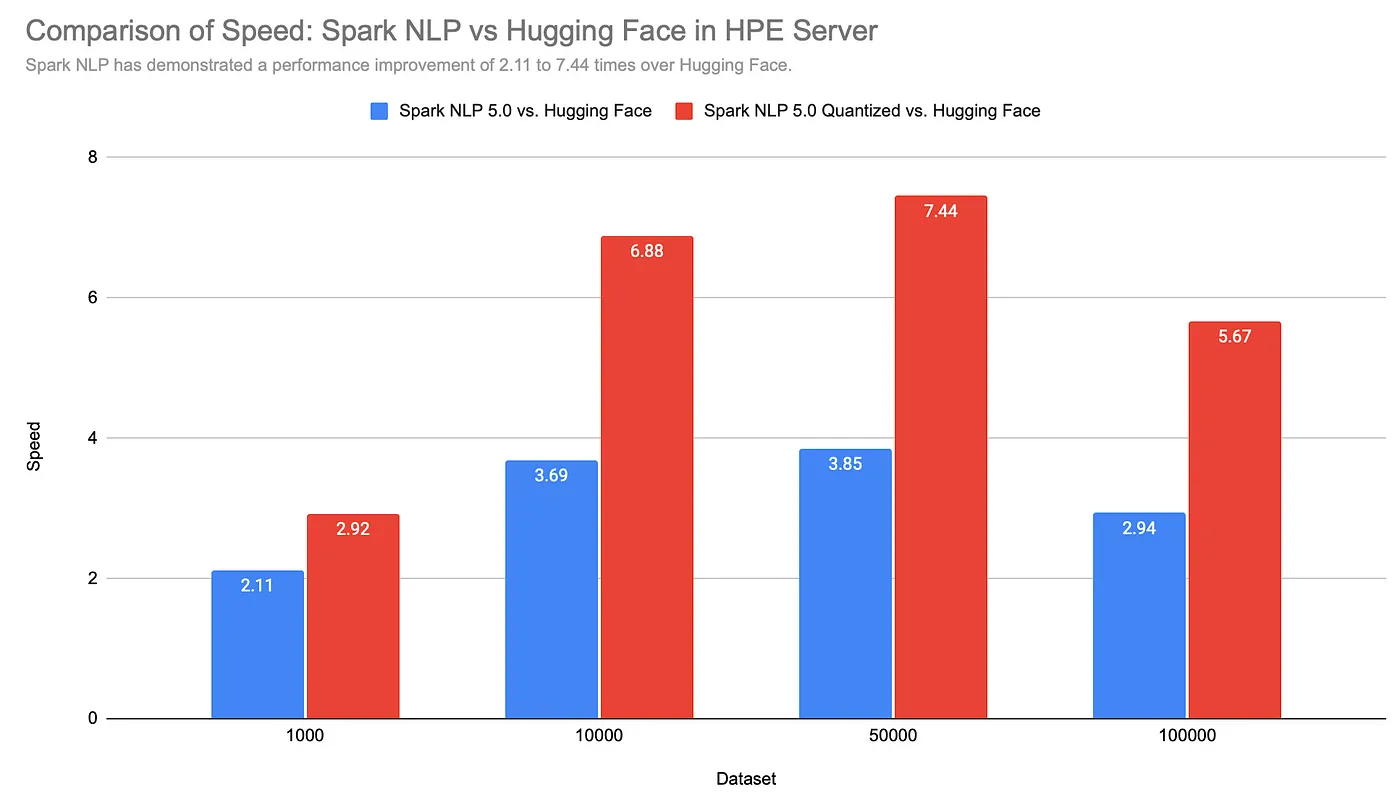
Spark NLP has demonstrated a performance improvement of 2.11 to 7.44 times over Hugging Face
In the realm of Vector Databases, the quest for faster and more efficient Embeddings models has become an imperative pursuit. Models like BERT, DistilBERT, and DeBERTa have revolutionized natural language processing tasks by capturing intricate semantic relationships between words. However, their computational demands and slow inference times pose significant challenges in the game of Vector Databases.
In Vector Databases, the speed at which queries are processed and embeddings are retrieved directly impacts the overall performance and responsiveness of the system. As these databases store vast amounts of vectorized data, such as documents, sentences, or entities, swiftly retrieving relevant embeddings becomes paramount. It enables real-time applications like search engines, recommendation systems, sentiment analysis, and chat/instruct-like products similar to ChatGPT to deliver timely and accurate results, ensuring a seamless user experience.
Keeping this in mind, we’ve initiated ONNX support for the following annotators:
- We’ve introduced ONNX support for the
BertEmbeddingsannotator. Approximately 180 models of the same name have already been converted to the ONNX format to automatically benefit from the associated performance enhancements. - We’ve added ONNX support for the
RoBertaEmbeddingsannotator. Roughly 55 models of the same name have been imported in the ONNX format, thus allowing for automatic speed improvements. - ONNX support has been initiated for the
DistilBertEmbeddingsannotator. Around 25 models with the same name have been converted to the ONNX format, facilitating automatic speed enhancements. - We’ve incorporated ONNX support into the
DeBertaEmbeddingsannotator. About 12 models bearing the same name have been imported in the ONNX format, enabling them to automatically reap the benefits of speed improvements.
We have successfully identified all existing models for these annotators on our Models Hub, converted them into the ONNX format, and re-uploaded them under the same names. This process was carried out to ensure a seamless transition for our community starting with Spark NLP 5.0.0. We will continue to import additional models in the ONNX format in the days ahead. To keep track of the ONNX compatibility with Spark NLP, follow this issue: #13866.
INSTRUCTOR: Instruction-Finetuned Text Embeddings
NEW: Introducing InstructorEmbeddings annotator in Spark NLP 🚀. InstructorEmbeddings can load new state-of-the-art INSTRUCTOR Models inherited from Google T5 for Text embedding.
This annotator is compatible with all the models trained/fine-tuned by using T5EncoderModel for PyTorch or TFT5EncoderModel for TensorFlow models in HuggingFace
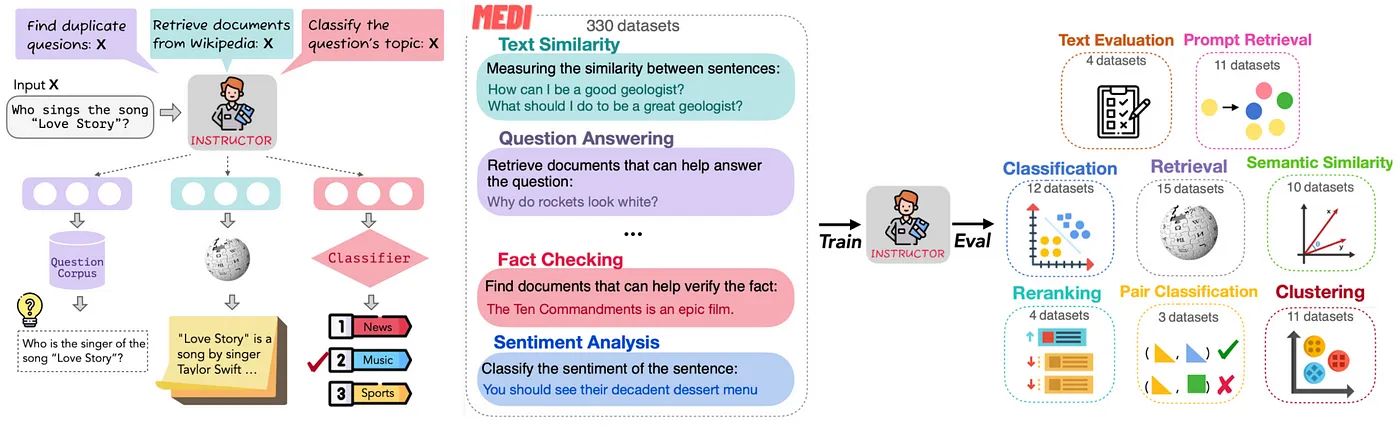
Instructor👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) by simply providing the task instruction, without any finetuning. Instructor👨 achieves sota on 70 diverse embedding tasks!
For more details, check out the official paper and the project page!
E5: Text Embeddings by Weakly-Supervised Contrastive Pre-training
NEW: Introducing E5Embeddings annotator in Spark NLP 🚀. E5Embeddings can load new state-of-the-art E5 Models based on BERT for Text Embeddings. Text Embeddings by Weakly-Supervised Contrastive Pre-training.
Text Embeddings by Weakly-Supervised Contrastive Pre-training.
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
Our new state-of-the-art annotators for Text Embeddings are currently dominating the top of the MTEB leaderboard positioning themselves above OpenAI text-embedding-ada-002
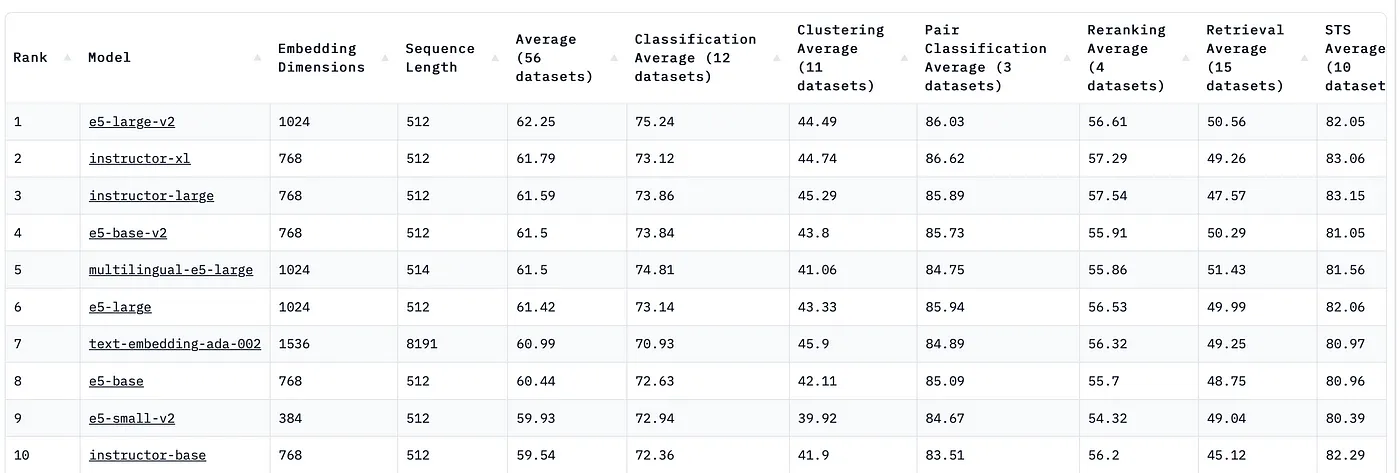
Massive Text Embedding Benchmark (MTEB) Leaderboard. To submit, refer to the MTEB GitHub repository
Document Similarity Ranker by LSH techniques
NEW: Introducing DocumentSimilarityRanker annotator in Spark NLP 🚀. DocumentSimilarityRanker is a new annotator that uses LSH techniques present in Spark ML lib to execute approximate nearest neighbors search on top of sentence embeddings, It aims to capture the semantic meaning of a document in a dense, continuous vector space and return it to the ranker search.
- Welcoming 6 new Databricks runtimes to our Spark NLP family:
- Databricks 13.1 LTS
- Databricks 13.1 LTS ML
- Databricks 13.1 LTS ML GPU
- Databricks 13.2 LTS
- Databricks 13.2 LTS ML
- Databricks 13.2 LTS ML GPU
- Welcome AWS EMR 6.11 version to our Spark NLP family
- Fix BART issue with input longer than the
maxInputLength
Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
Community Support
- Slack for live discussion with the Spark NLP community and the team
- GitHub bug reports, feature requests, and contributions
- Discussions engage with other community members, share ideas,
and show off how you use Spark NLP! - YouTube Spark NLP video tutorials




