
























































Legal NLP 1.12 comes with a lot of new capabilities added to the 926+ models and 125+ Language Models already available in previous versions of the library. Let’s take a look at each of them!

Native Legal Text Generation
With our new Text Generation annotator, you can give the start of a sentence from a legal document and get the model generate the rest.
We have trained 2 models:
1️⃣A generic one, with different legal documents;
2️⃣A specific one, trained specifically on commercial agreements;
Example of the commercial agreements-based model:
Input: This BETA TEST Agreement (“Agreement”) is entered into between …
Output:
… [Company Name] (“Company”), and the individual or entity agreeing to these terms (“Beta Tester”). This Agreement governs Beta Tester’s participation in the beta test of Company’s software product (“Beta Product”) and any related materials or services provided by Company in connection with the beta test (collectively, the “Beta Program”). Beta Tester Obligations. Beta Tester agrees to: a. Participate in the Beta Program, including by testing the Beta Product and providing feedback to Company in a timely and constructive manner. b. Keep all aspects of the Beta Program confidential, including but not limited to the Beta Product and any related materials or services provided by Company in connection with the beta test.
New NER and NDA Sentence Classifiers
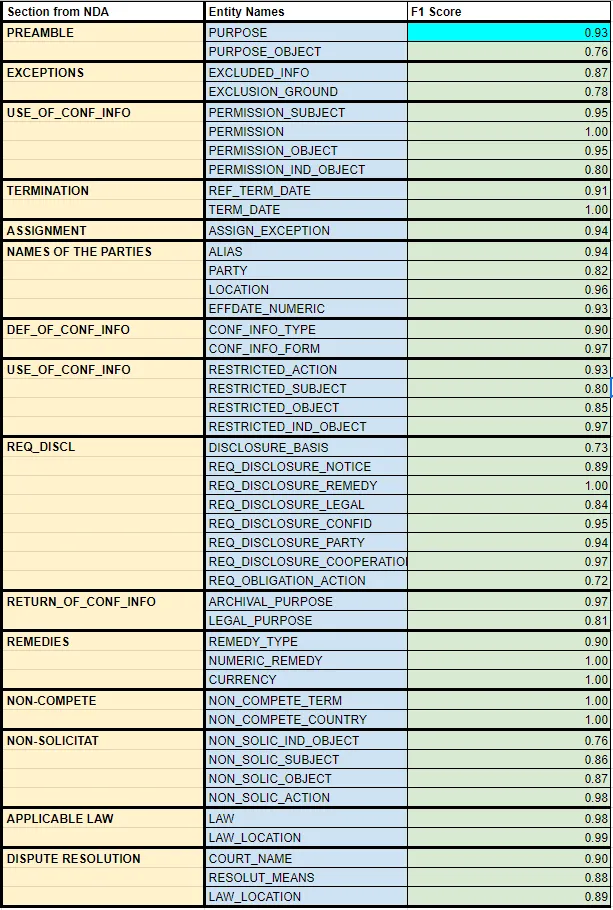
In Legal NLP we have trained 10 new NER and CLF models for NDA agreements (NLP for contracts), which now sum up to 45 models. Here is a list of the entities detecter, with the sections where they should be run in and the F1-scores.
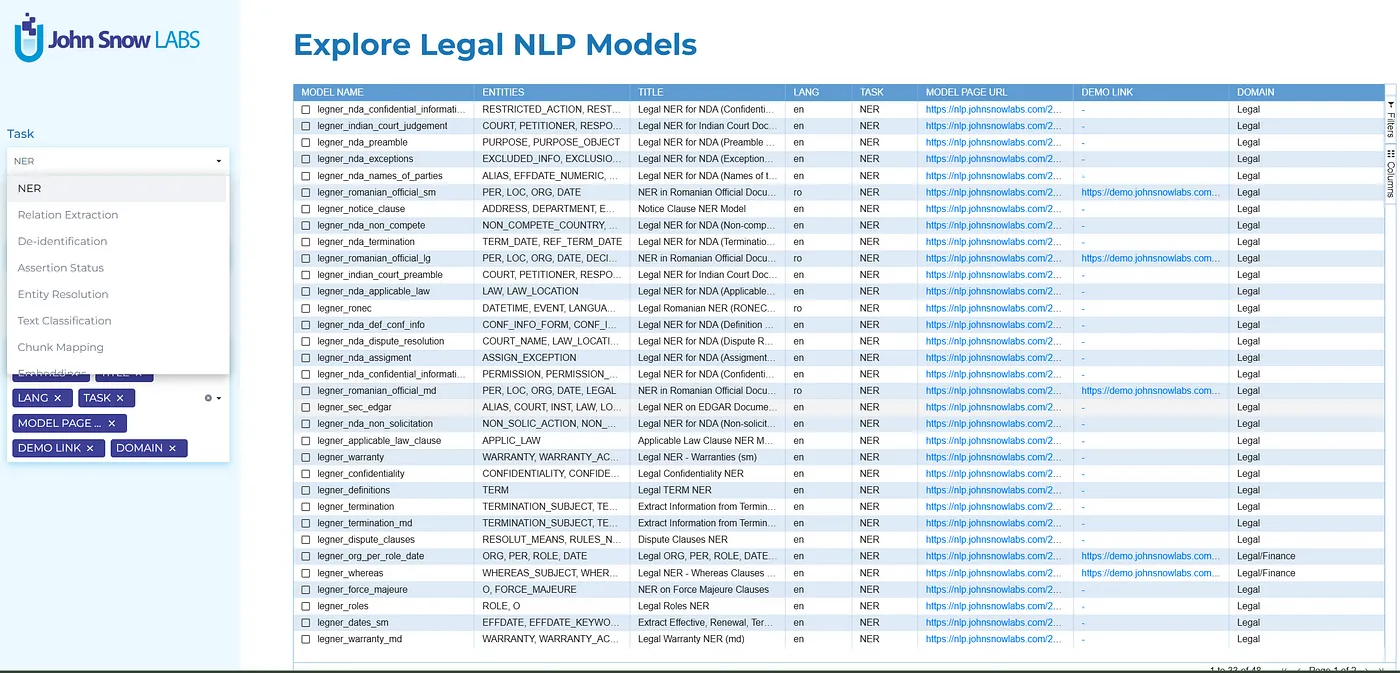
Have a quick glance at everything we have in Legal NLP
Navigating the almost 1000 models available in Legal NLP may be overwhelming. But hey, we’ve got you covered!
Take a look at the demo app we have published for you under or demos section, called Legal NLP Overview.
Legal NER in up to 15 different languages
We have increased the support of other languages in Legal NLP with up to 10 new NER models, which now include representation for Greek, Bulgarian, Danish, Dutch, Slovak, in addition to the languages already present English, Spanish, French, Portuguese, German, Russian, Italian…
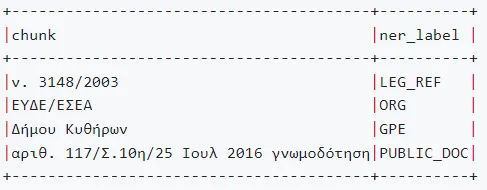
Greek NER
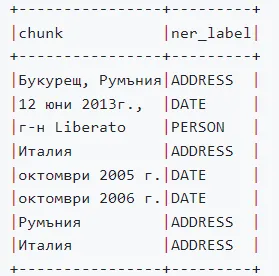
Bulgarian NER
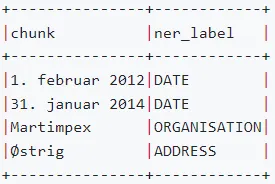
Danish NER
These models were trained on datasets as EURLEX and Online Terms of Services.
Deidentification Helper notebook
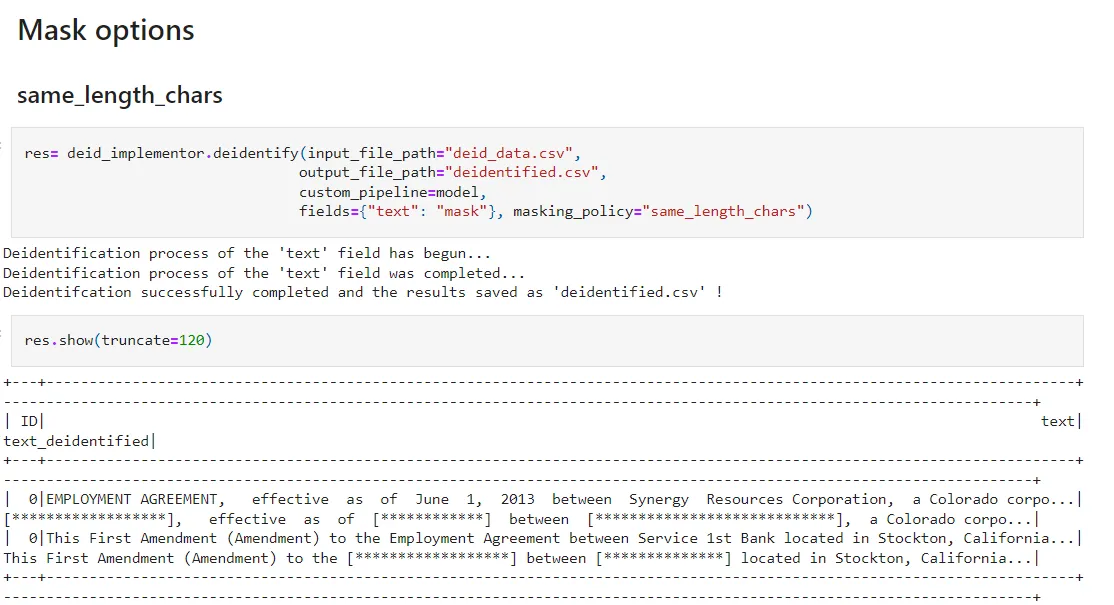
As part of the John Snow Labs’ NLP Library, a new helper module has been included to make your deidentification even more easy to use. You can find it in the workshop repo as Deidentification Utility Module.
It includes examples of how to use masking and obfuscation in unstructured texts, structured tables, how to configure the mask length and symbols, a custom vocabulary for obfuscation, data shifts, and much more!
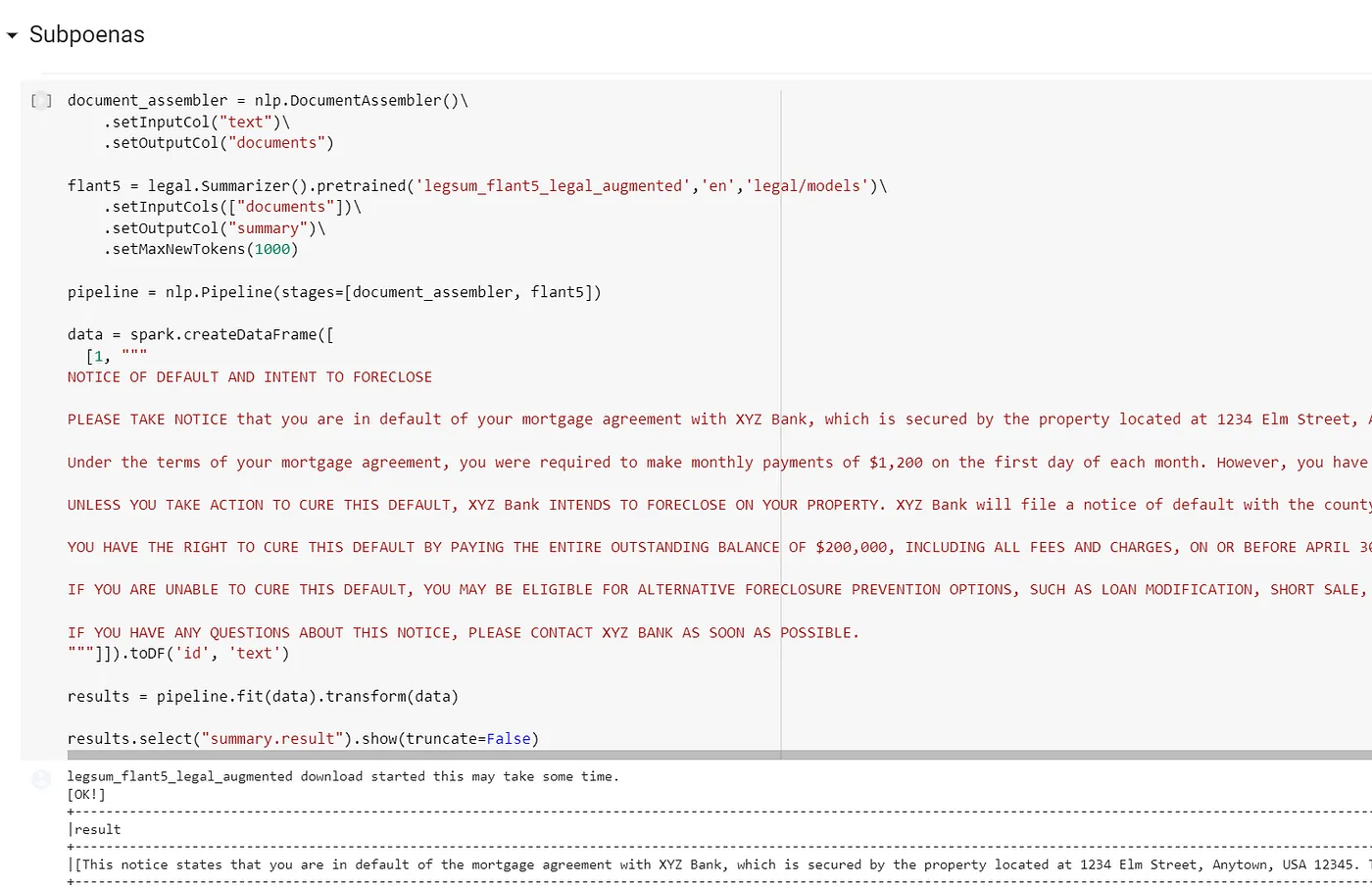
New notebook: Legal Summarization
In our workshop repo, with more than 40 notebooks, you will find our new notebook explaining how to use our new Legal Summarization annotator on different legal information as subpoenas, NDA, commercial agreements, etc.
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our legal team of technical and SME. This trial includes complete access to more than 926 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 120+ legal language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
How to run
Legal NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()




