
























































Natural Language Processing in Legal: Introduction

Human language is highly diverse and complex. We have infinite ways to express ourselves, both verbally and non-verbally. There are hundreds of languages, but each language has its grammatical norms, idioms, sentence structure. We often omit punctuation, abbreviate or mispell words. Also, we have regional accents, and we stutter and borrow terms from other languages when we speak. Natural Language Processing (NLP) overcomes ambiguity, adds numeric structure to the data, and teaches computers how to process human languages. Its market size is expected to be worth $27.6 billion by 2026.
Nowadays, businesses are overwhelmed with unstructured data. It is impossible for them to analyze voluminous amounts of data. According to Forbes, unstructured data is growing at 55-65% each year and almost 90% of it has been generated in the recent two years. That’s why NLP for financial services, healthcare, and legal services is developing so dynamically.
NLP benefits the businesses and allows them to process large volumes of data across the digital world (online reviews, reports, news, etc) via various techniques such as:
- Classifying legal texts
- Contract Understanding
- Automatic Contract Redlining
- Recognizing legal entities in clauses
- Understanding entities in context
- Extracting legal relationships
- Normalization and Data Augmentation
- Legal Deidentification
NLP in Legal
Processing unstructured legal documents is, besides a vertical by itself, an implicit component of many other verticals.
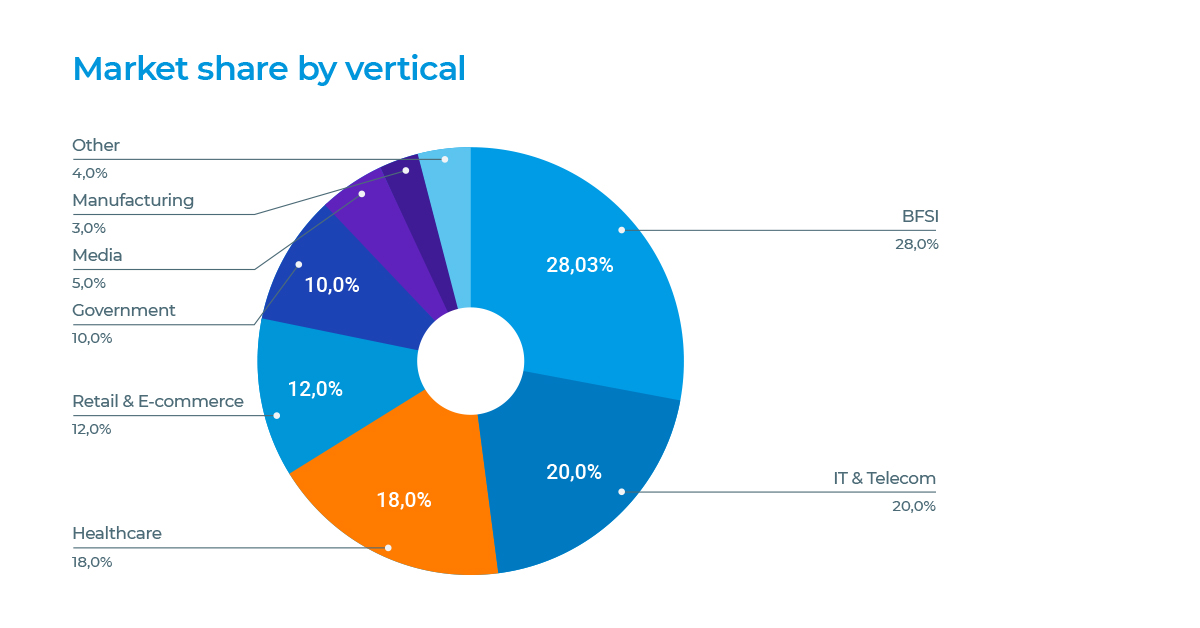
When we talk about the importance of NLP in the Legal space, we are not only talking about processing judgments, court decisions, allowing lawyers to do a better search on big data repositories. We are talking about providing BFSI, Healthcare, Government, HR, Retail sectors with capabilities to process documentation, such as agreements, tenders, contracts, legal clauses, to approve or reject requests, to be compliant with regulations, etc.

NLP reviews and manages documents, supports legal decision-making, and is used in the following major areas of Legal industry:
- Legal Research – Finds information relevant to a legal decision
- Document Automation – Generates routine legal documents
- Contract Review – Checks contract completion and avoids risks
- Legal Advice – Provides tailored advice using question and answer dialogs
Main Tasks
Below are the top tasks of Natural Language Processing for Legal.
Classify Legal Texts
NLP in Legal can classify texts and streamline legal research for all processes. Using text classification, companies structure relevant text data from legal documents, social media, surveys, chatbots, emails etc., in a fast and cost-effective manner. They use Natural Language Processing for:
- Classifying specific clauses in legal texts and returning them (for example, “investments”, “loans”, etc.) or “other” if the clause was not found.
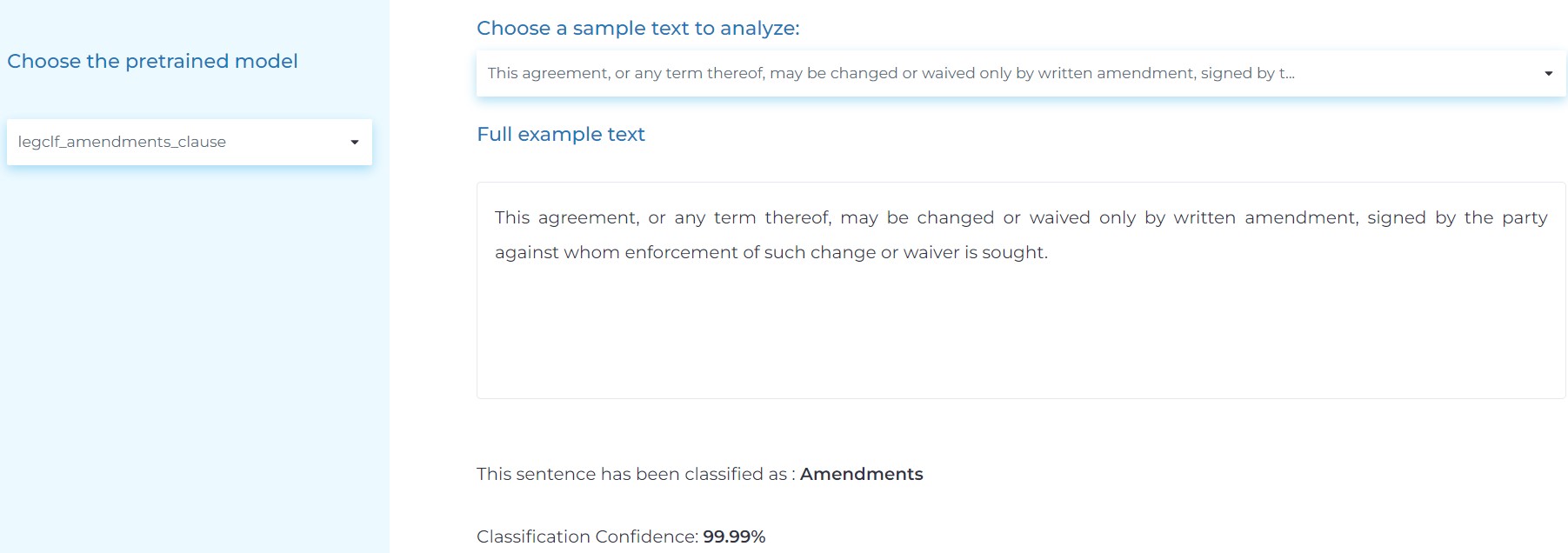
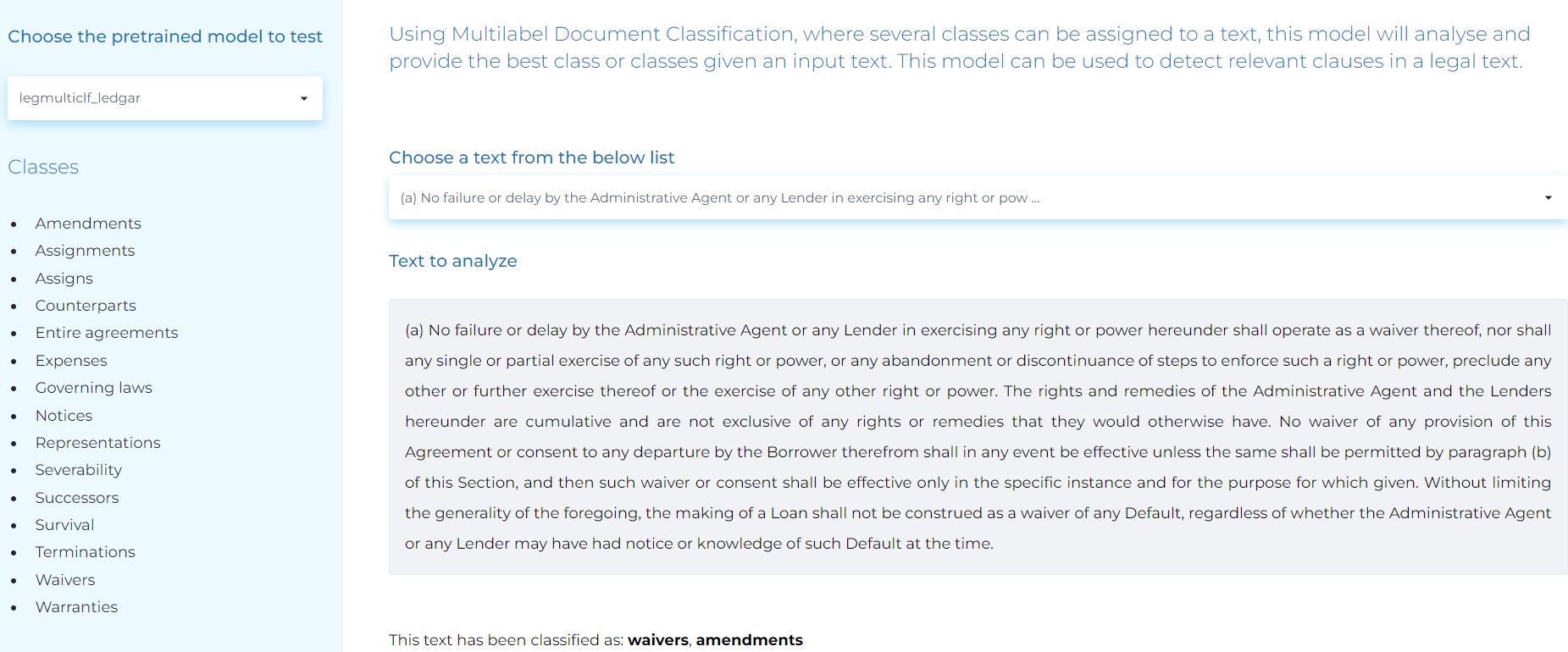
- Classifying various clauses in legal texts using Multilabel Document Classification, where several classes can be assigned to a text.
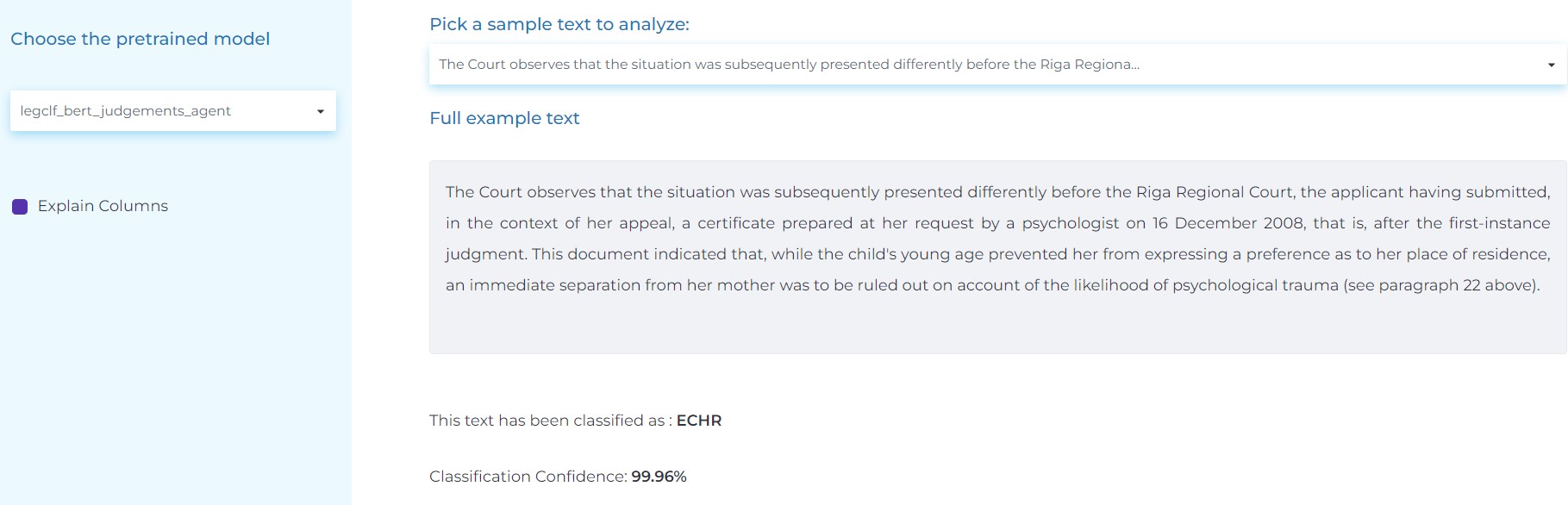
- Classifying judgment documents and identifying if a clause is a decision, talks about a legal basis, a legitimate purpose, etc. and if an argument has been started by the ECHR, Commission/Chamber, the state, third Parties, etc.
- Classifying court documents in multiple languages and of multiple laws.
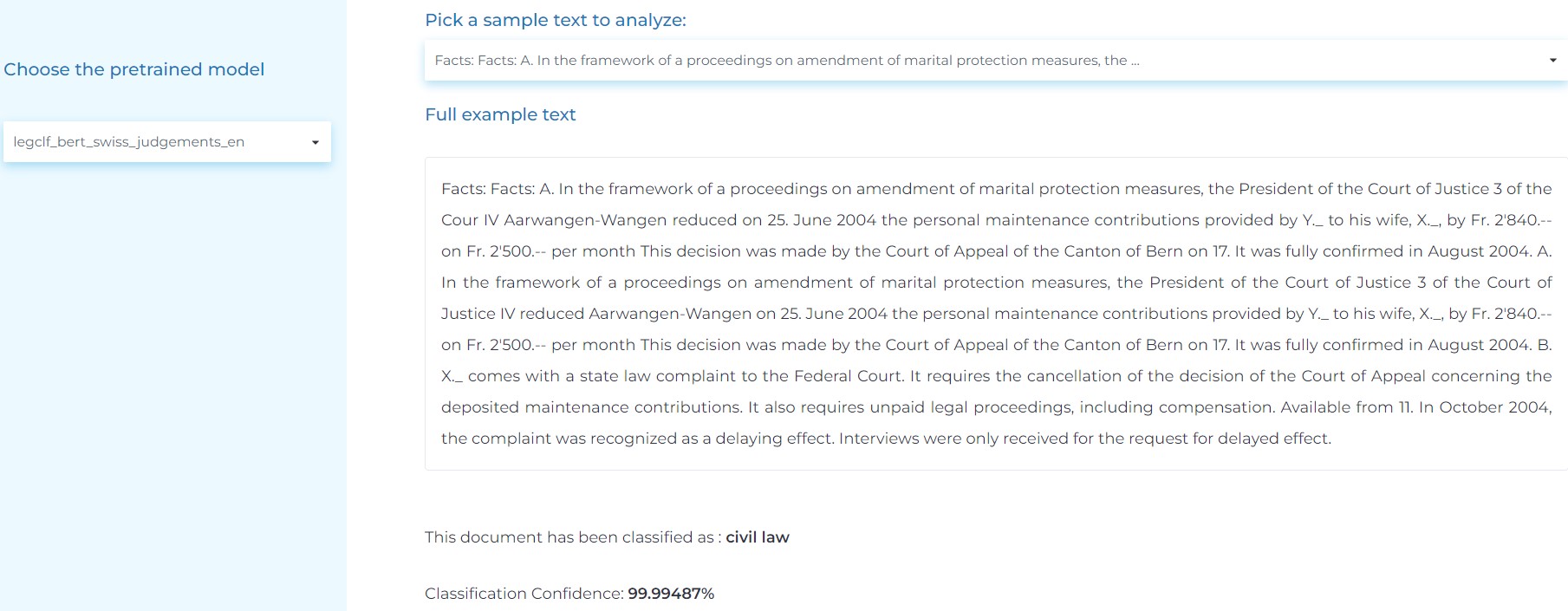
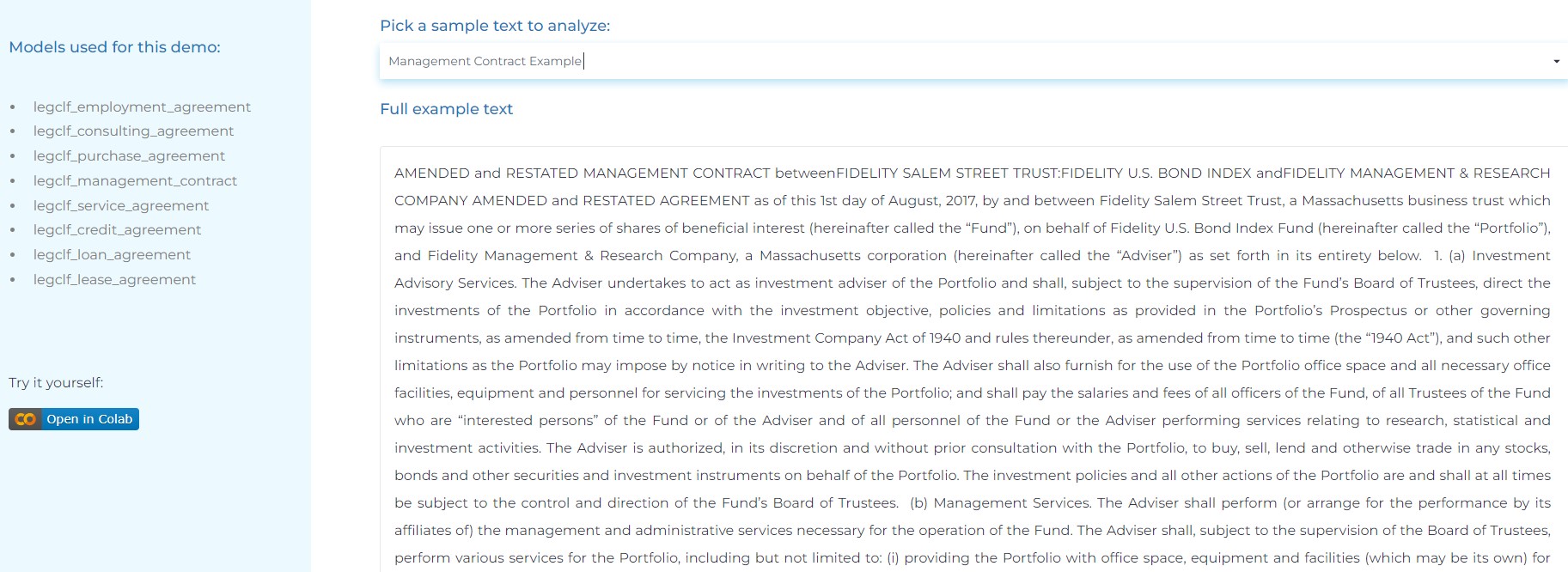
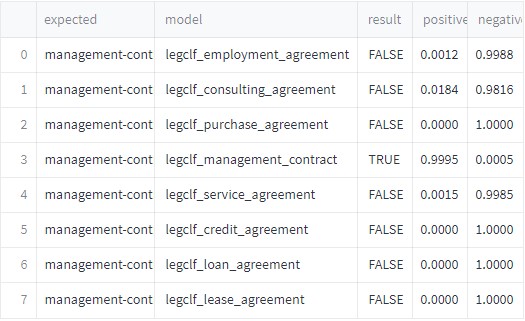
- Classifying long documents/agreements by their types (service agreements”, “loan agreements”, “management contracts”, “credit agreements”, etc).
Recognize Legal Entities
NLP recognizes various legal entities and directs researchers to where specific phrases appear in legal documents. The notable tasks of Natural Language Processing in the Legal space are given below.
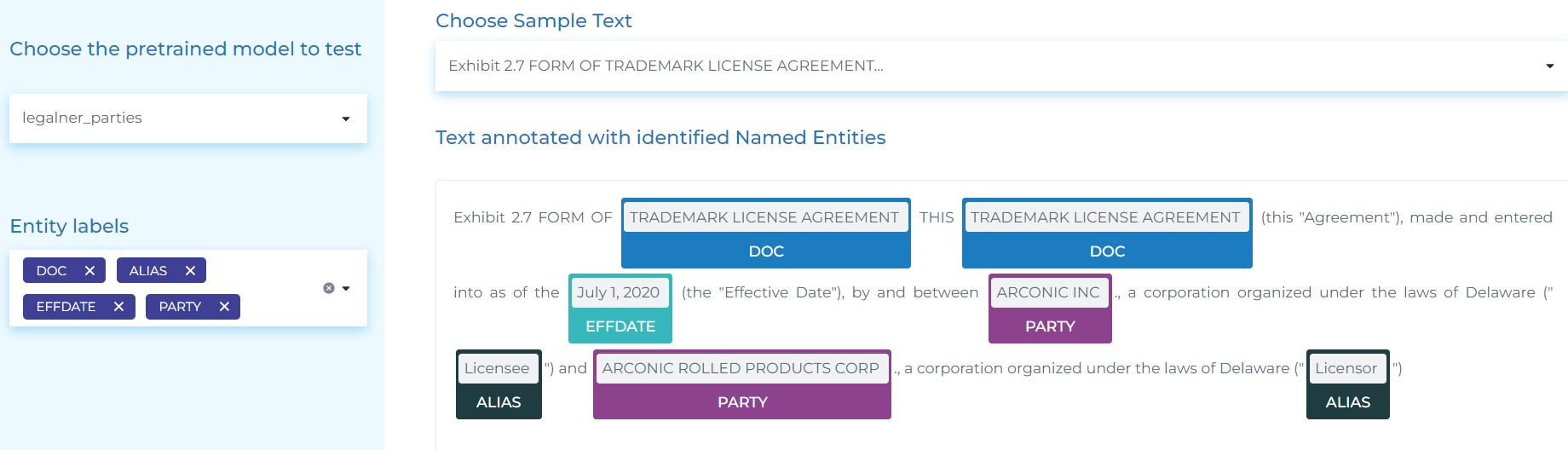
- Extracting DOC (Document Type), PARTY (An Entity signing a contract), ALIAS (the way a company is named later on in the document) and EFFDATE (Effective Date of the contract).
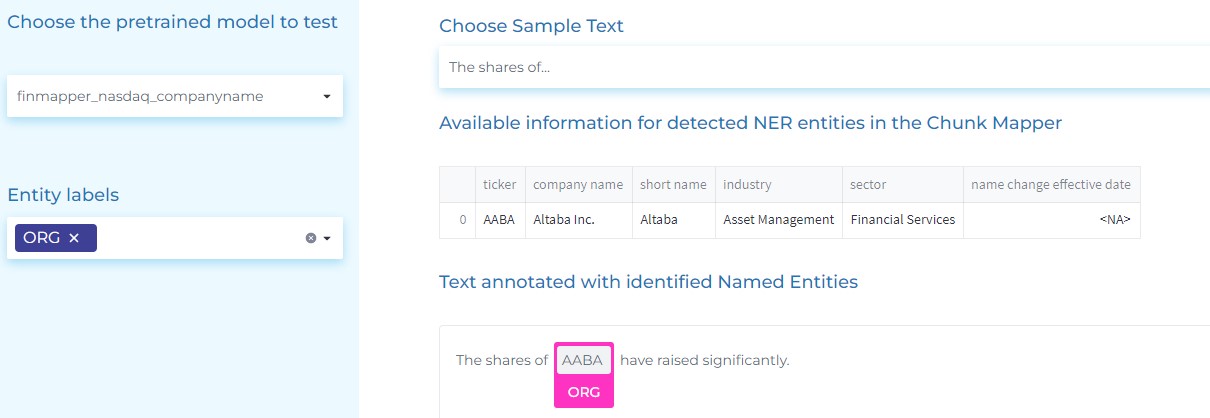
- Identifying ORG (Companies), their ALIAS (other names the company uses in the contract/agreement) and company PRODUCTS.
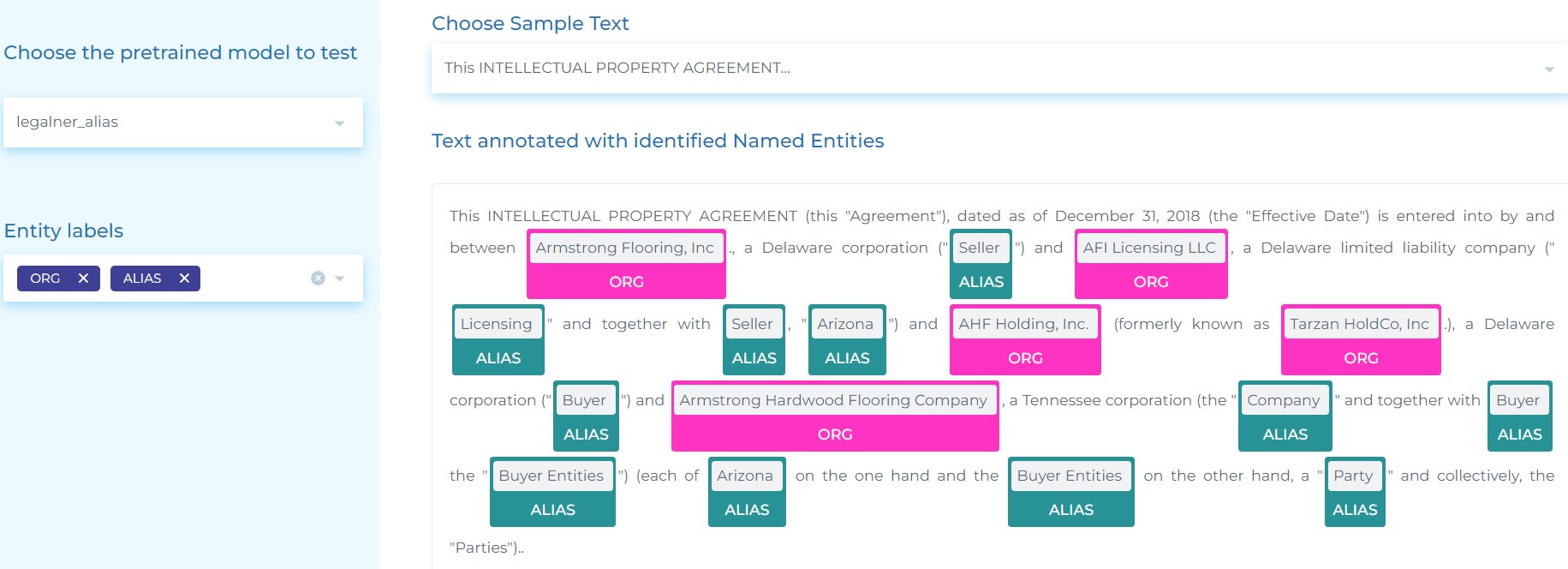
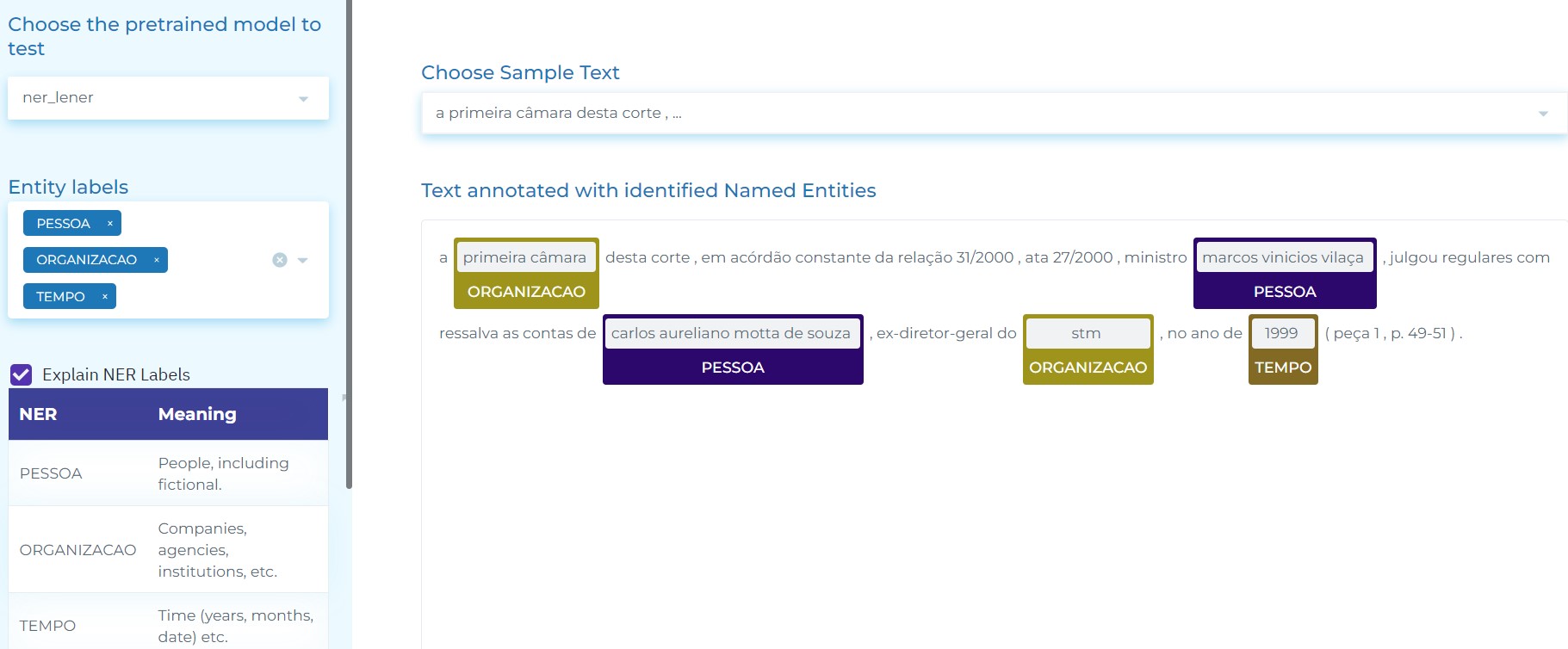
- Automatically identifying entities such as Organization, Jurisprudence, Legislation, Person, Location, and Time, etc. in (Brazilian) Portuguese legal text.
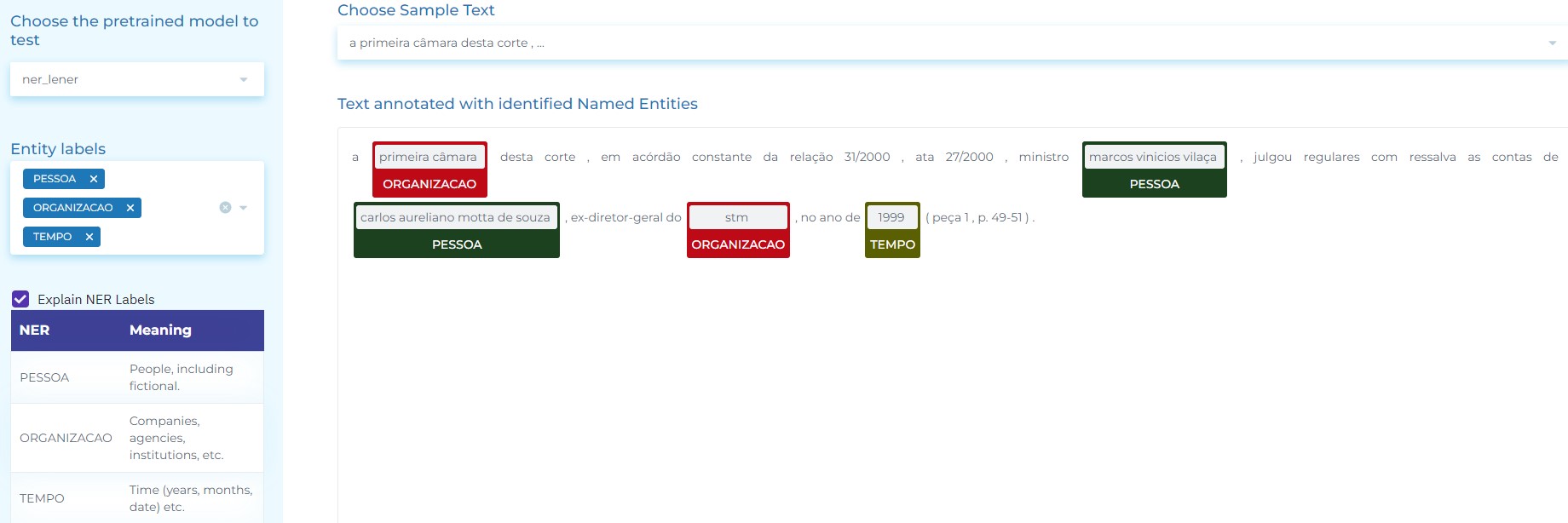
- Using Named Entity Recognition to detect “Whereas” clauses and extract, from them, the SUBJECT, the ACTION and the OBJECT.
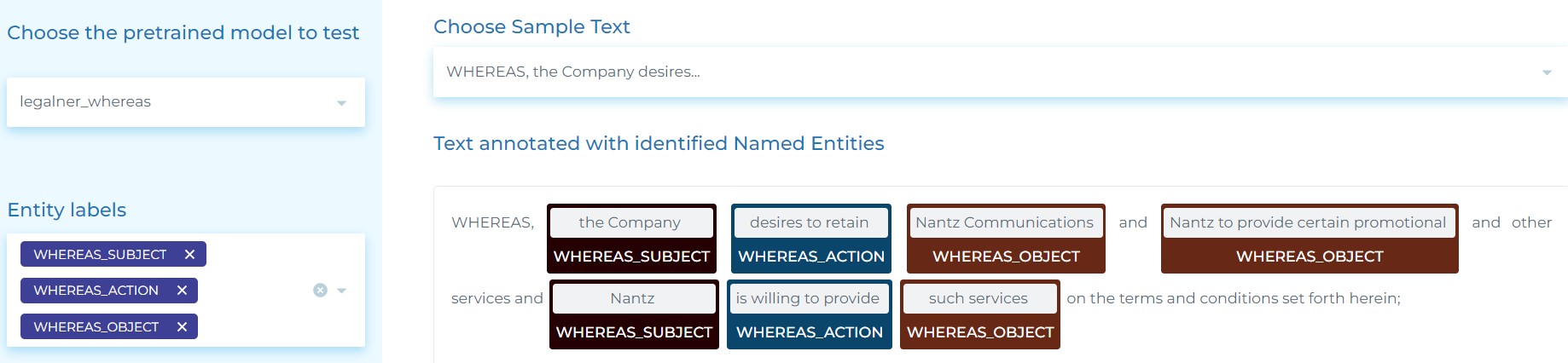
- Using Named Entity Recognition to extract SIGNING_PERSON (People signing a document), SIGNING_TITLE (the roles of those people in the company) and PARTY (Organizations).
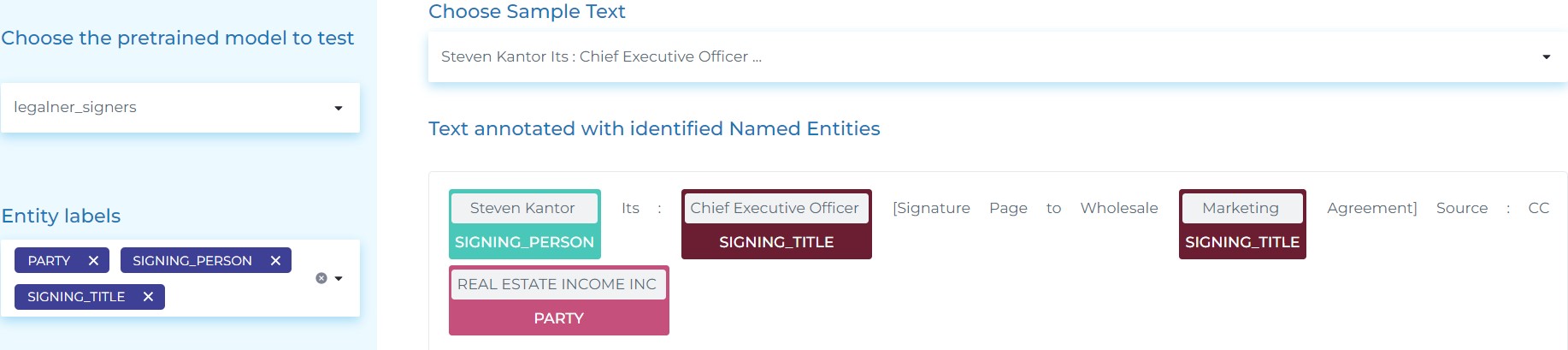
- Detecting legal entities in German – Automatically identifying entities such as persons, judges, lawyers, countries, cities, landscapes, organizations, courts, trademark laws, contracts, etc. in German legal text.

- Detecting legal entities in Portuguese – Identifying entities such as Organization, Jurisprudence, Legislation, Person, Location, and Time, etc. in (Brazilian) Portuguese legal text.
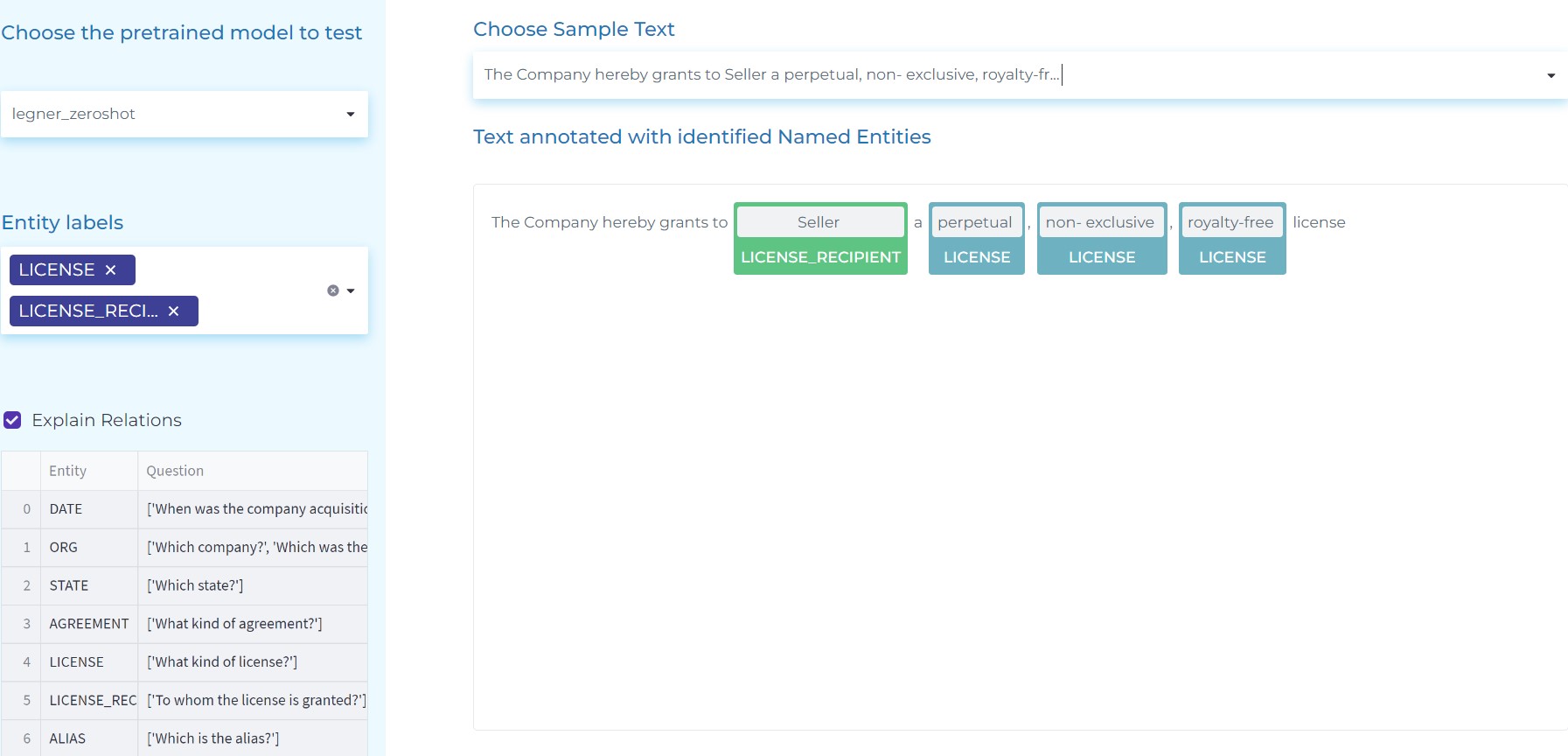
- Carrying out Legal Zero-Shot Named Entity Recognition. When a model is trained with Zero-Shot Named Entity Recognition (NER) approach, it can detect any kind of defined entities with no training dataset. The below figure shows how you can use prompts in the form of questions, to carry our Named Entity Recognition without any pre-trained dataset. You will find a table with the example questions (prompts) used for the different labels on the side menu.
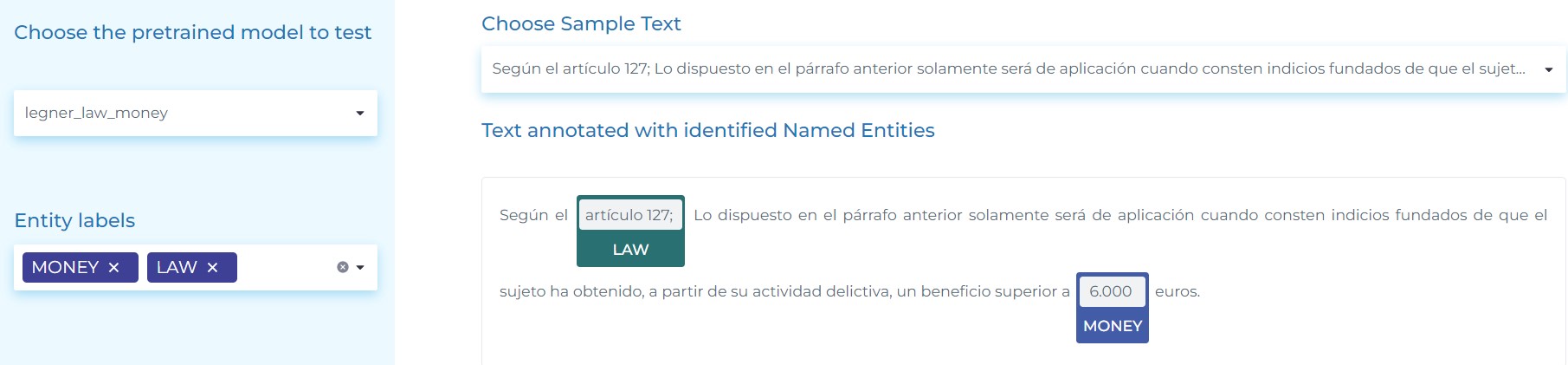
- Detecting law and money entities in Spanish.
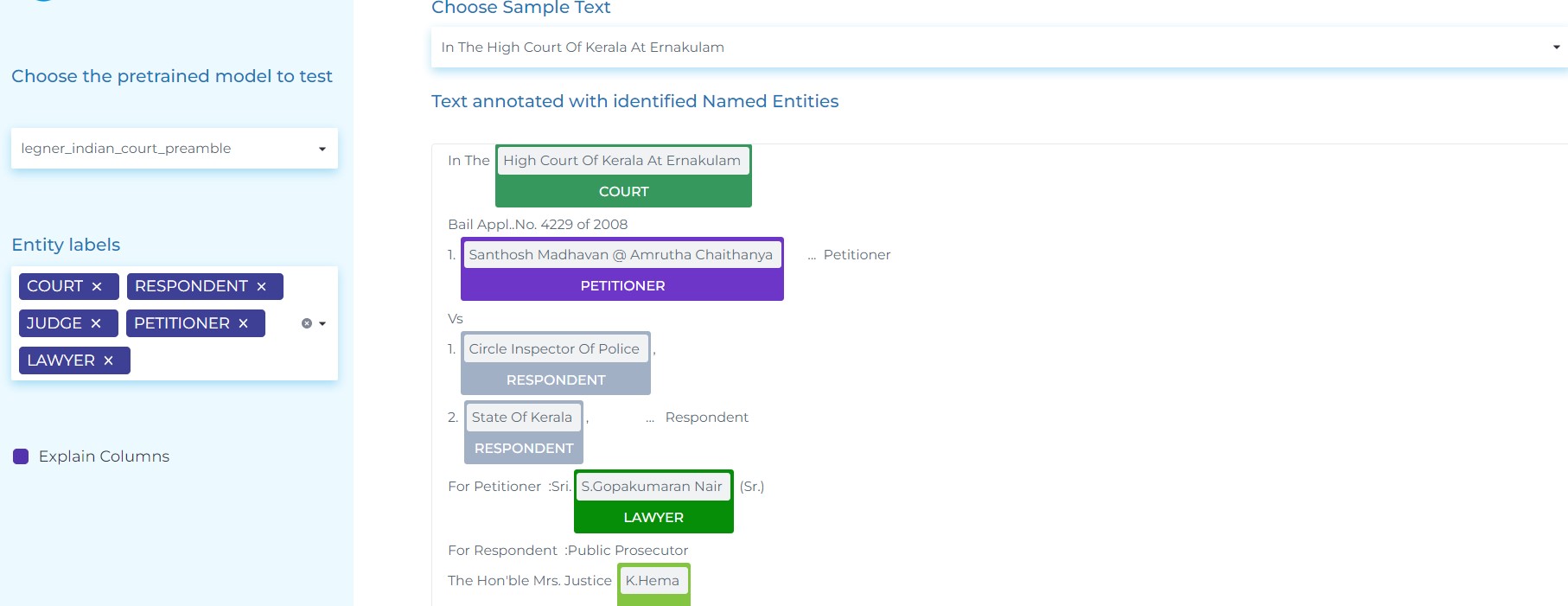
- Extracting entities from Indian Court Preamble and Judgement documents LAWYER, JUDGE, COURT, WITNESS, RESPONDENT, PETITIONER etc.
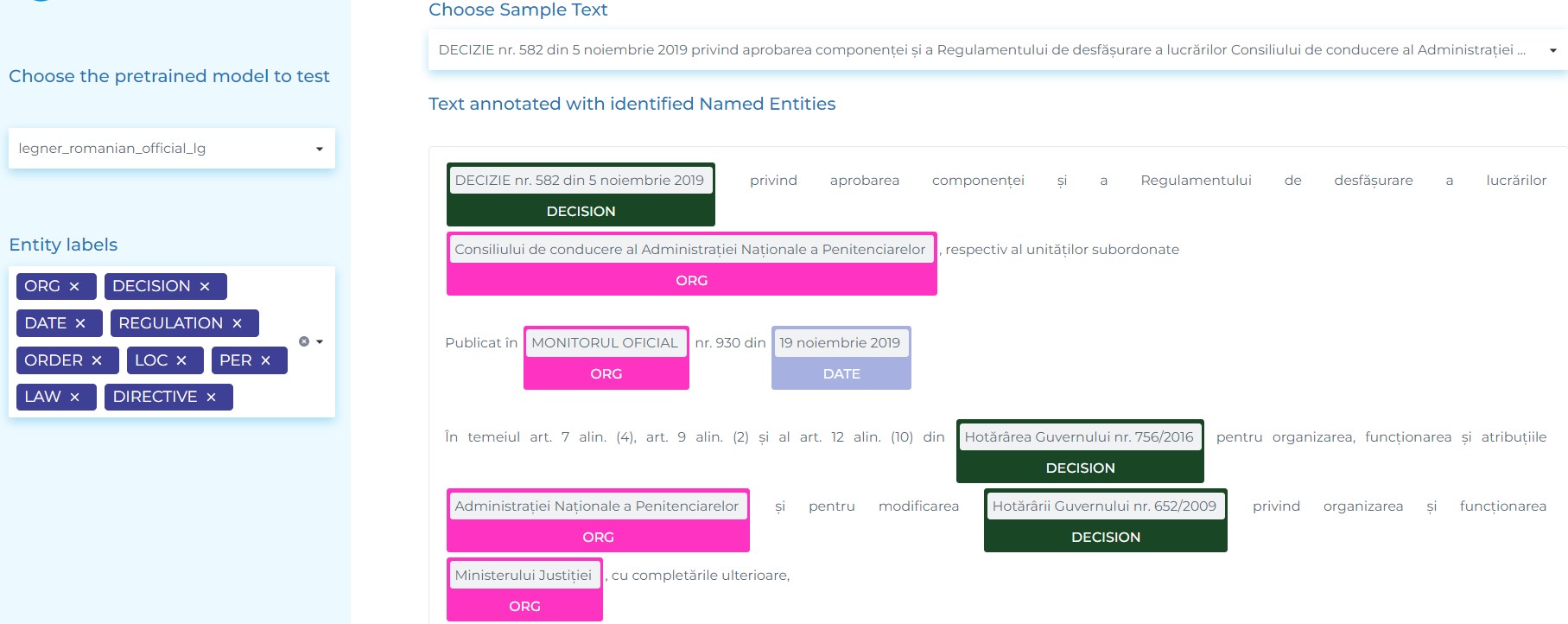
- Extracting the standard four entities (ORG, PER, LOC, DATE) and more 10 entities (DECISION, DECREE, DIRECTIVE, EMERGENCY_ORDINANCE, LAW, ORDER, ORDINANCE, REGULATION, REPORT and TREATY) from Romanian official documents.
Understand Entities in Context
Understand Entities in Context, or Assertion Status, is an NLP Task that analyzes the context of extracted entities from NER, and assesses conditions as negation, possibility, temporality, etc. This step helps to better understand and disambiguate extractions from NER.
The process involves the following steps:
- Decompose the contract into its individual clauses/provisions
- Assess each clause and analyze it
- Extract key information from each clause
- Analyze their context: certainty, temporality, if it’s negated, or any other mentioned factor in the context.
- Make decision
Companies can use Assertion Status to:
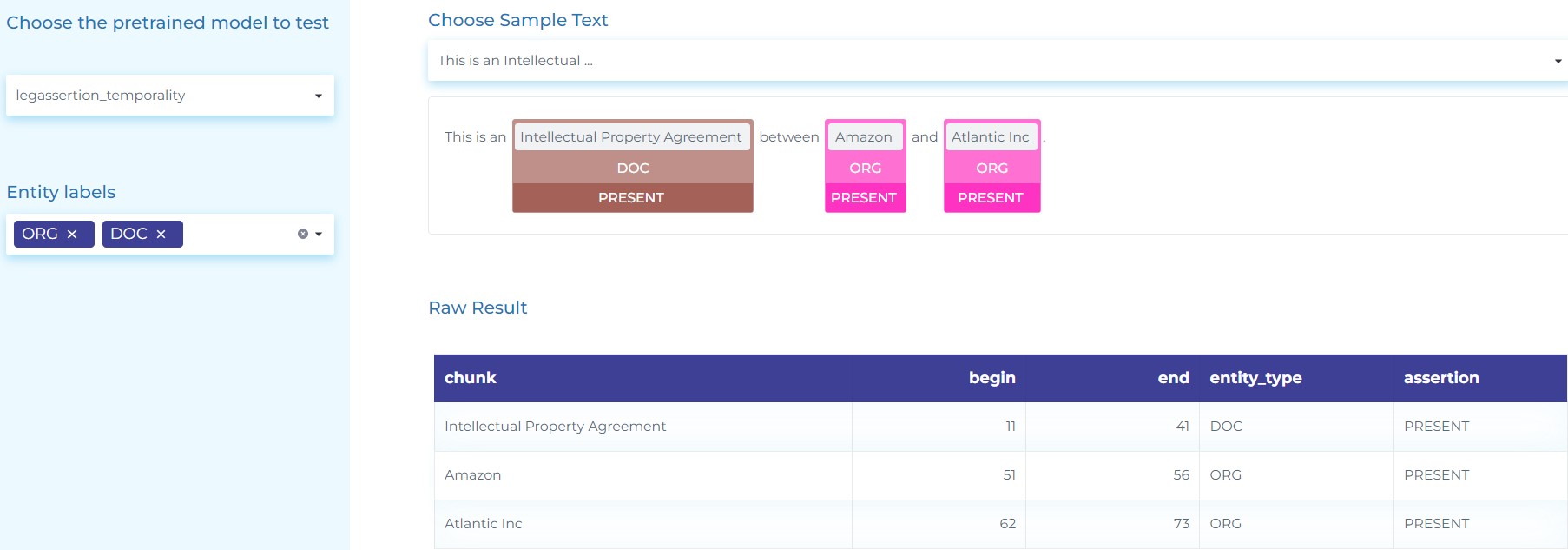
- Identify if legal information is described to happen in the present, past, future or if it’s just possible. The figure below shows how to detect temporality and certainty in Legal texts.
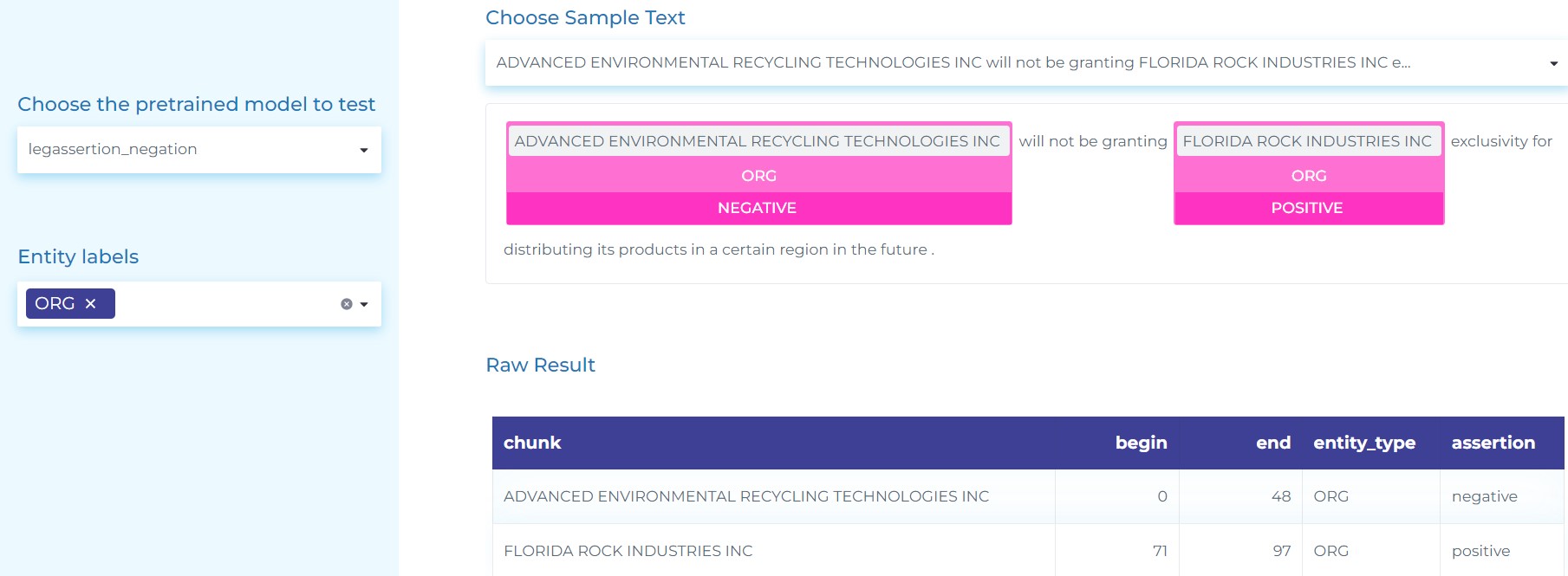
- Identify if an NER entity is mentioned in the context to be negated or not. The figure below shows how we can use the Financial Negation Model for detecting negation in context.
Extract Legal Relationships
Relation Extraction is the ability to infer if two entities are connected.
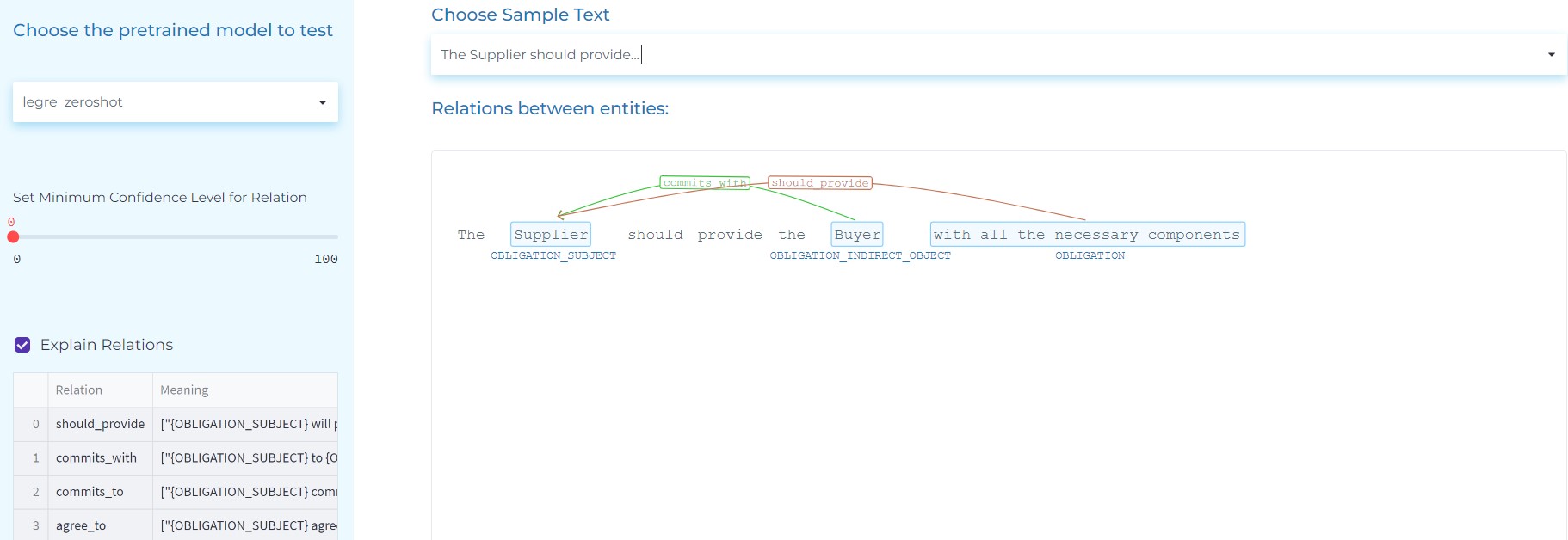
We can carry out Relation Extraction without training any model (Legal Zero-shot Relation Extraction).
Apart from Zero-shot Relation Extraction, we can carry out Non-Zero shot Relation Extraction to:
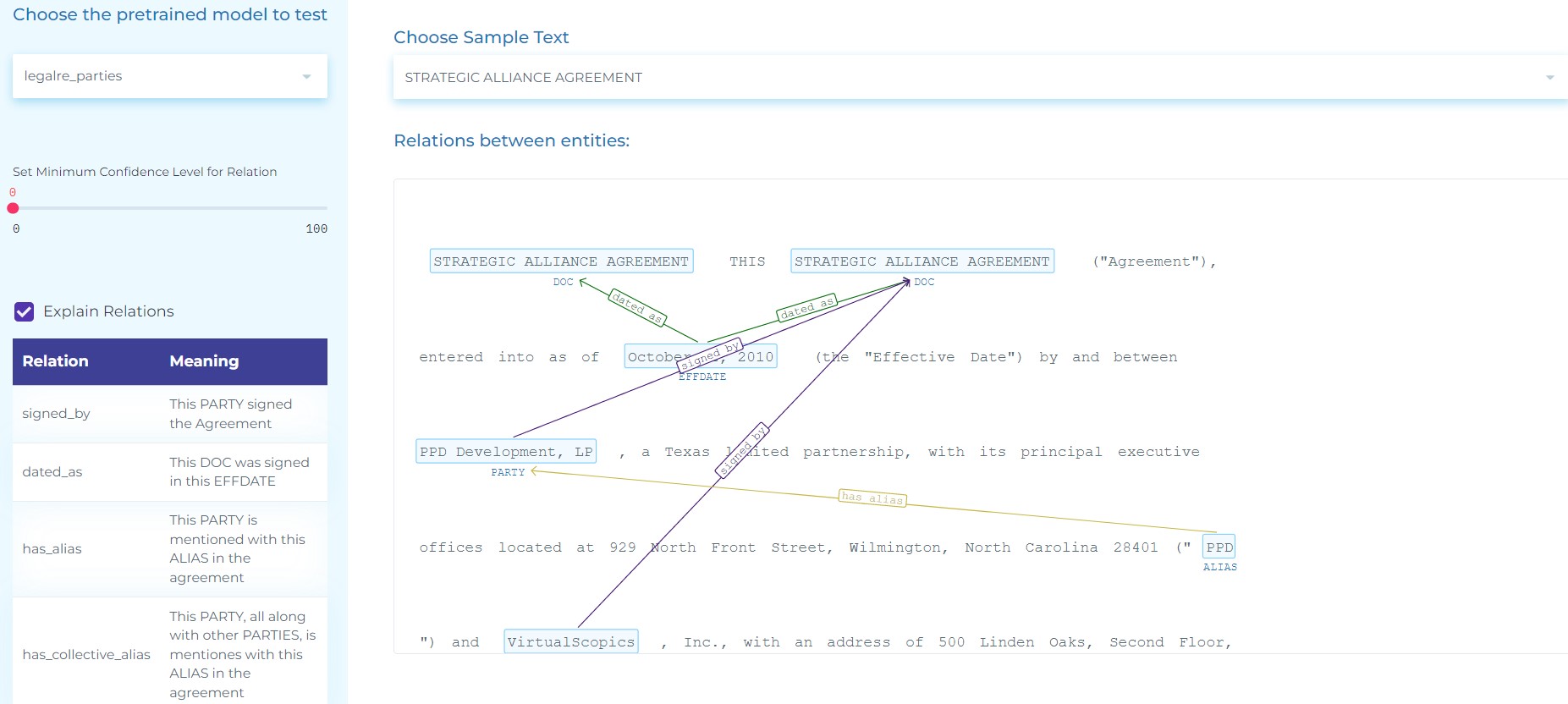
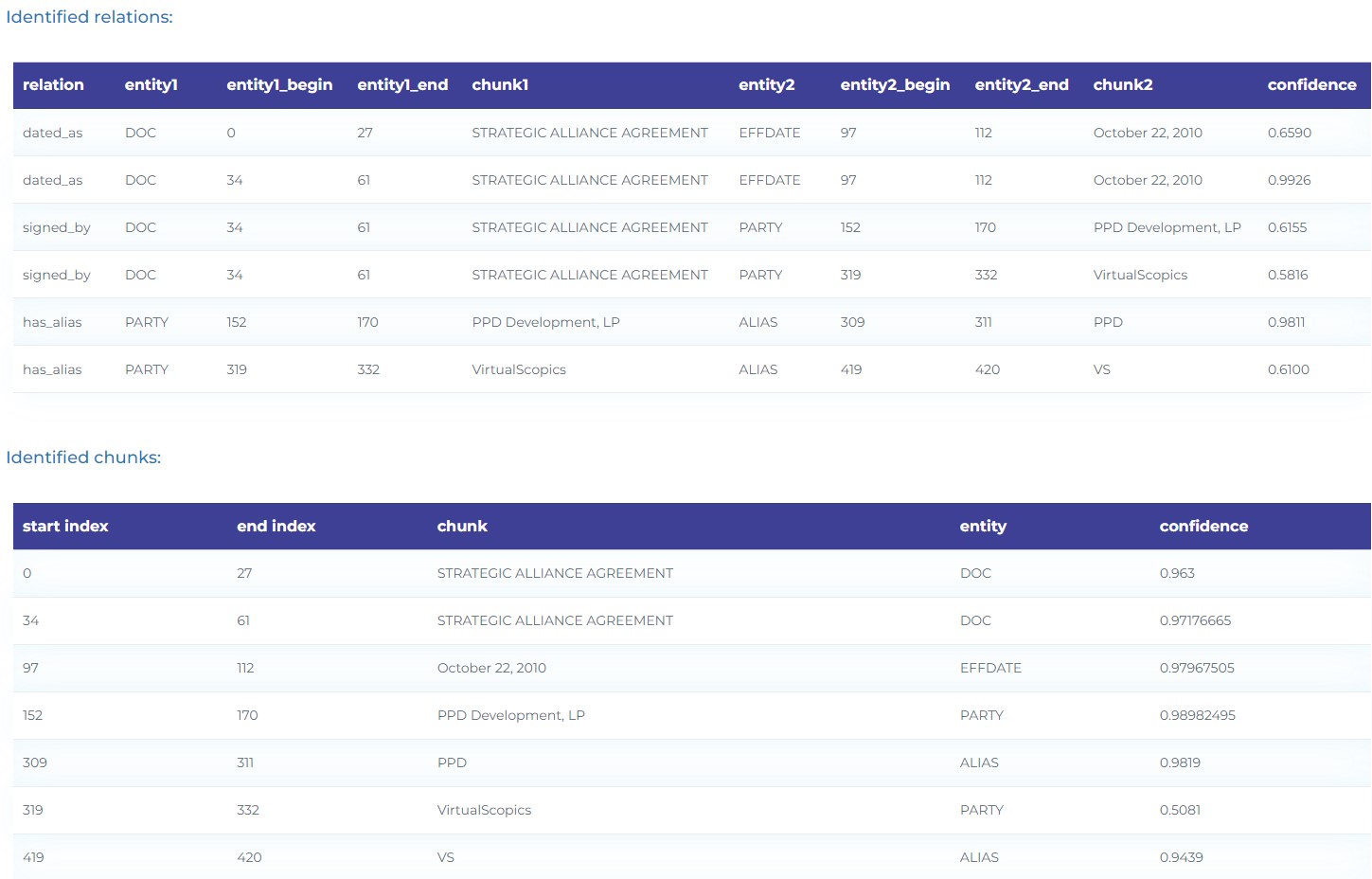
- Extract the document type (DOC), the Effective Date (EFFDATE), the PARTIES in an agreement and their ALIAS (separate and collectively). The diagram below depicts the use of Deep Learning Named Entity Recognition and a Relation Extraction model to extract Relations between Parties in agreements.
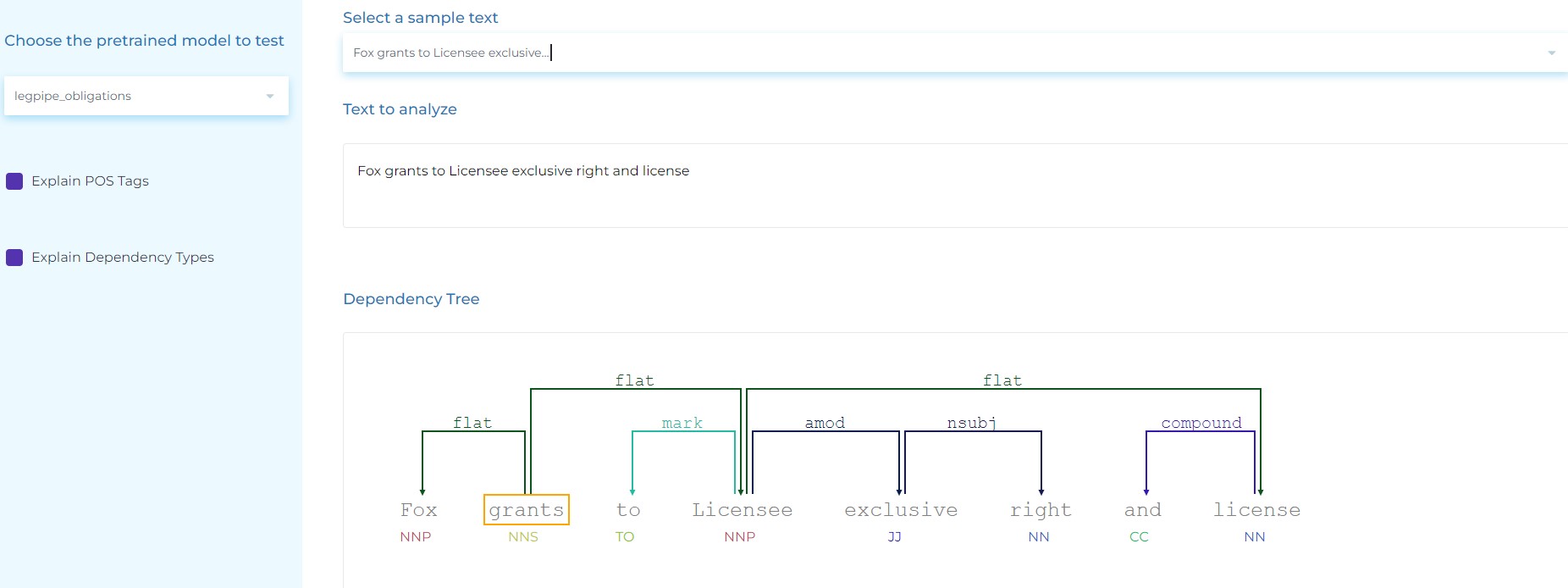
- Extract Syntactic Relationships in Legal sentences.
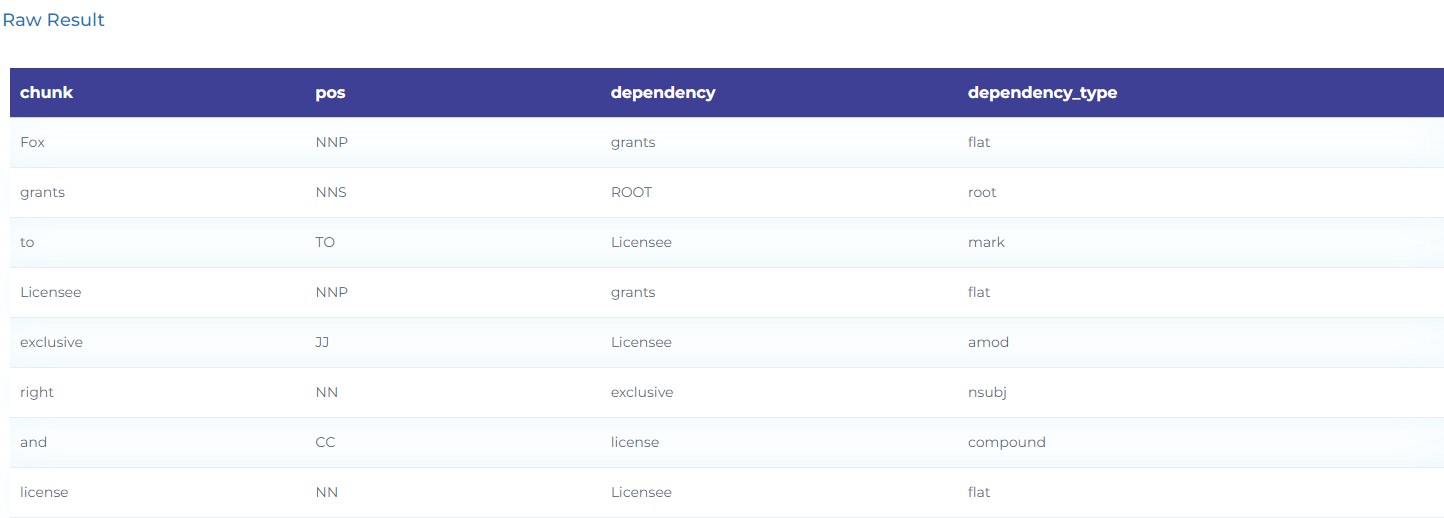
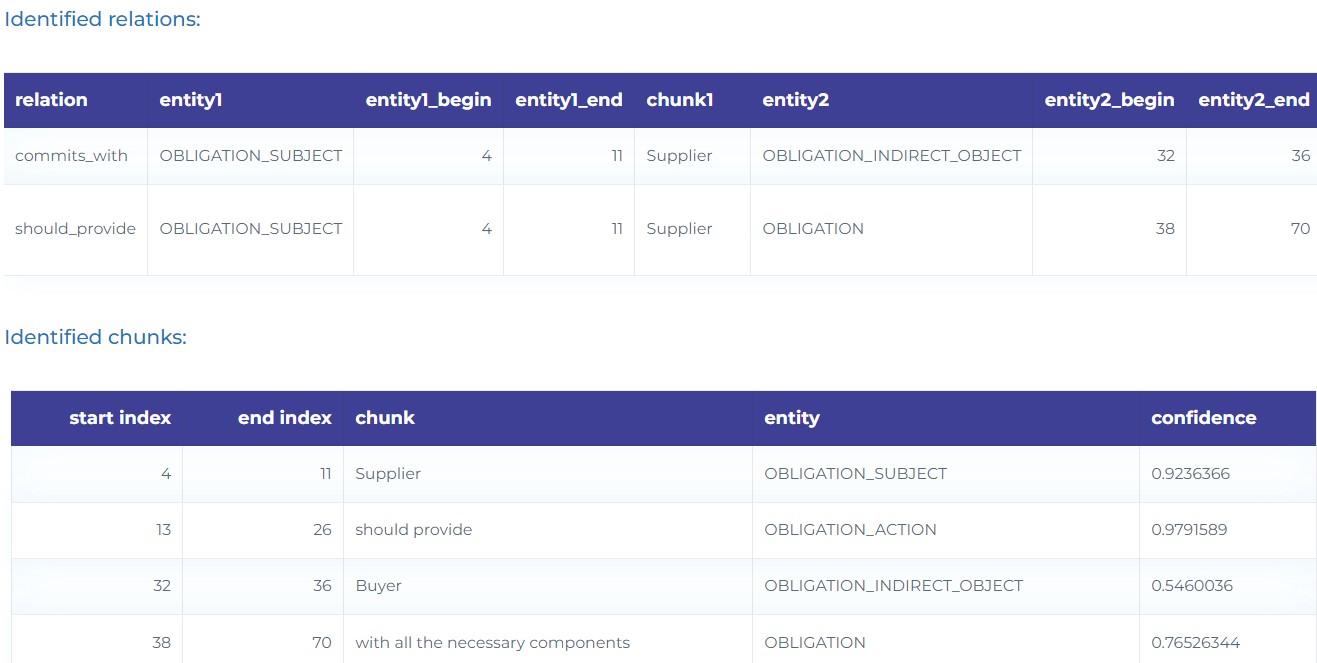
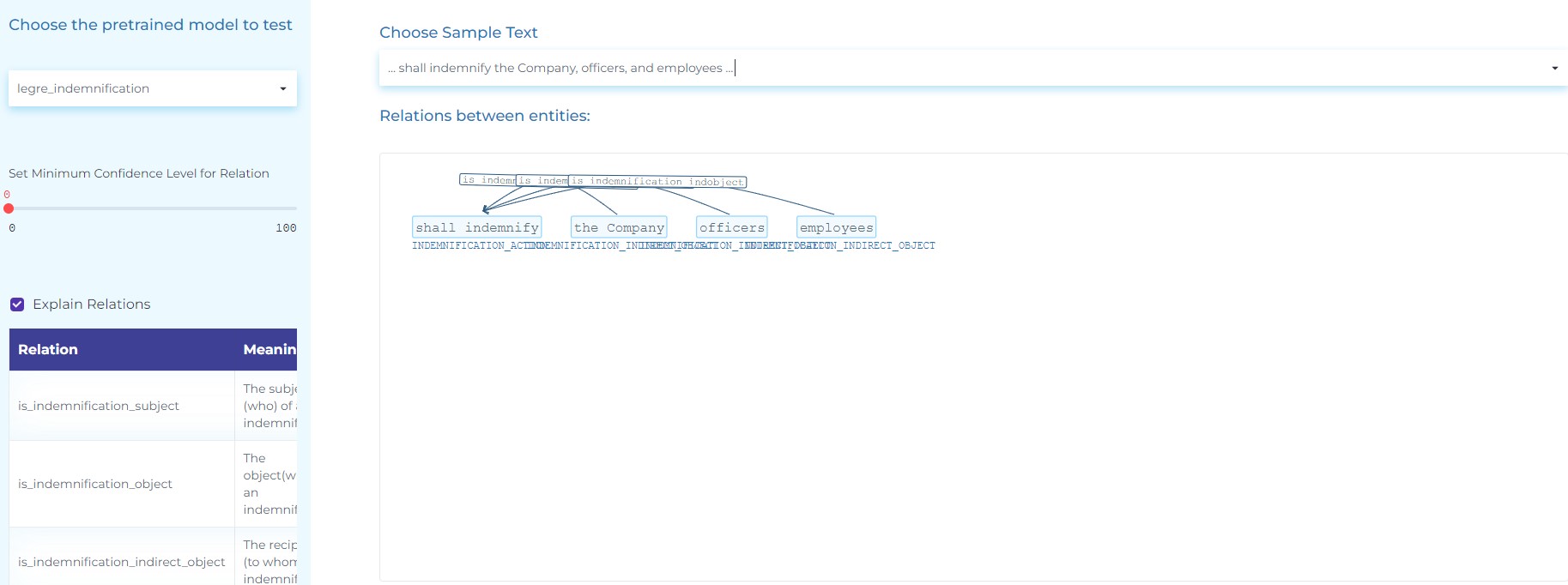
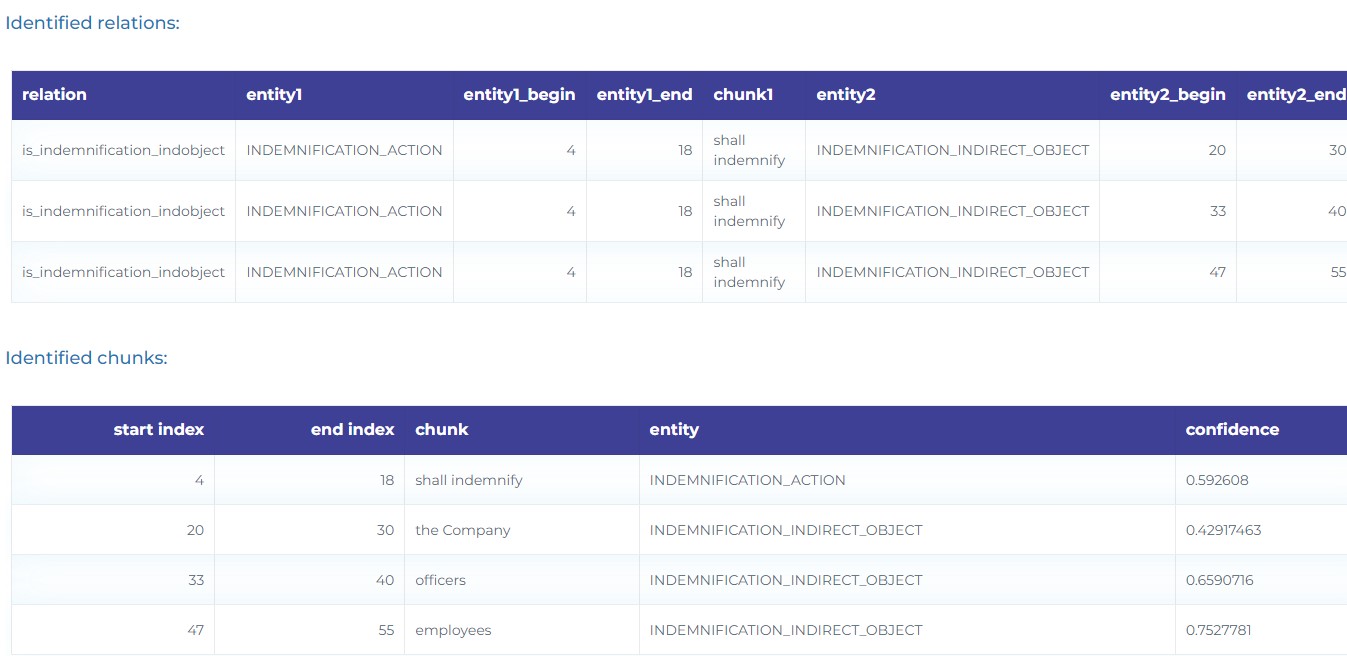
- Extract the Subject (who), Action (verb), Object (what) and Indirect Object (to whom) in Indemnification clauses.
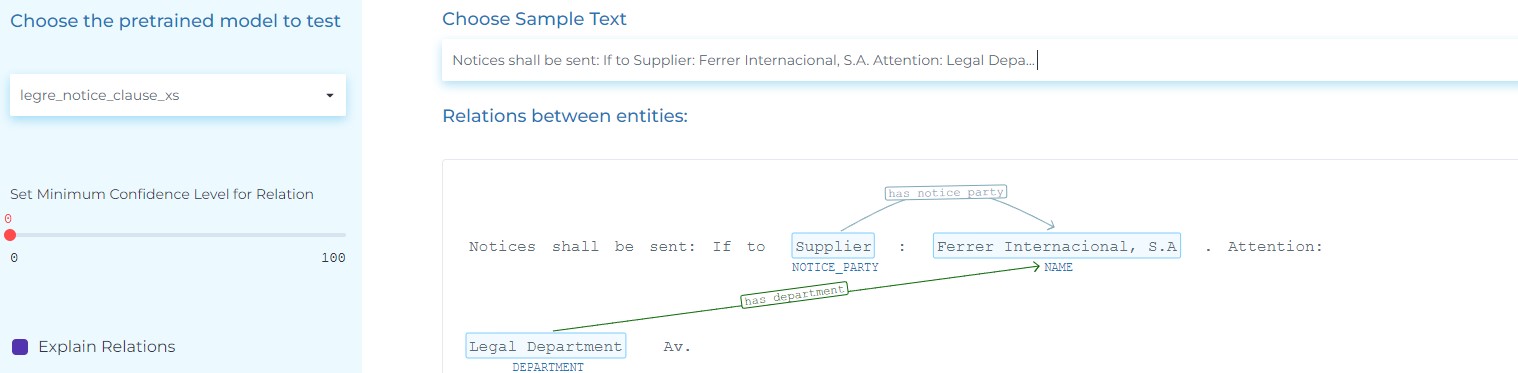
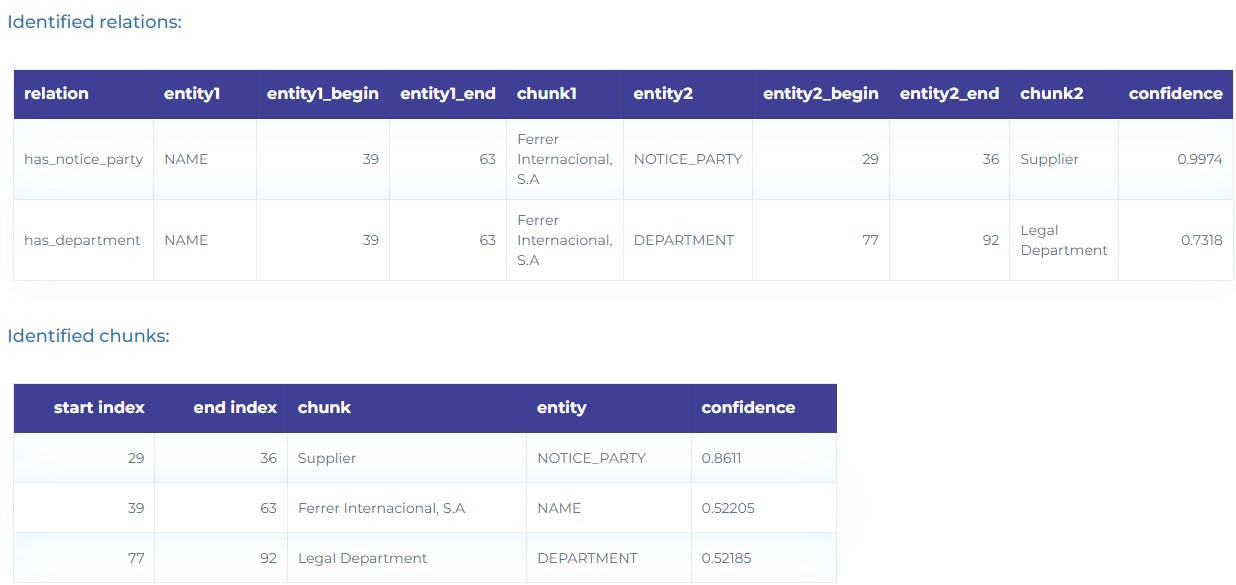
- Extract relations between entities as NOTICE_PARTY, NAME, TITLE, ADDRESS, EMAIL, etc. from notice clauses.
Normalization and Data Augmentation
The text data is preprocessed to a suitable form before it is used in training NLP models. Normalization reduces variations in word forms and improves the model’s performance. When we normalize text, we reduce its randomness and bring it closer to a predefined standard.
For instance, we can use Normalization to:
- Normalize versions of Company Names using Edgar databases conventions.
Data Augmentation
Data Augmentation allows us to use extracted information, such as Company Names, to query data sources and obtain more information, like Company’s SIC code, Trading Symbol, Address, etc.
We can use Data Augmentation to:
- Augment Named Entity Recognition with information from external sources.
Legal Deidentification
De-identification is critical for companies and government agencies seeking to make data available for further processing within the organization or outside.
We can simplify de-identification as a method of removing PII (Personal Identifiable Information) and PHI (Protected Health Information) that the document stores. It can be used to accomplish the following objectives:
- Compliance with privacy regulations, e.g., HIPAA de-identification privacy rule.
- Safeguarding the privacy of people interacting with the organizations
- Reducing risk and minimizing the damage caused to people from a data breach
- Building community trust in how companies and agencies store and handle data
De-identification aims to safeguard the confidentiality of people. A document or record can’t be considered de-identified if it includes any personal data that allows the individual to be re-identified, i.e., personal identity can be inferred from the document. De-identification techniques should preserve as much value in the information as possible and still protect people’s privacy. One of the key reasons to release de-identified data is to allow the study of raw data’s values and characteristics for research purposes without exposing any information about the individuals.
The Legal industry uses Deidentification to mask/deidentify legal data to be compliant with data privacy regulations as GDPR and CCPA.
State of the Art NLP for the Legal Industry
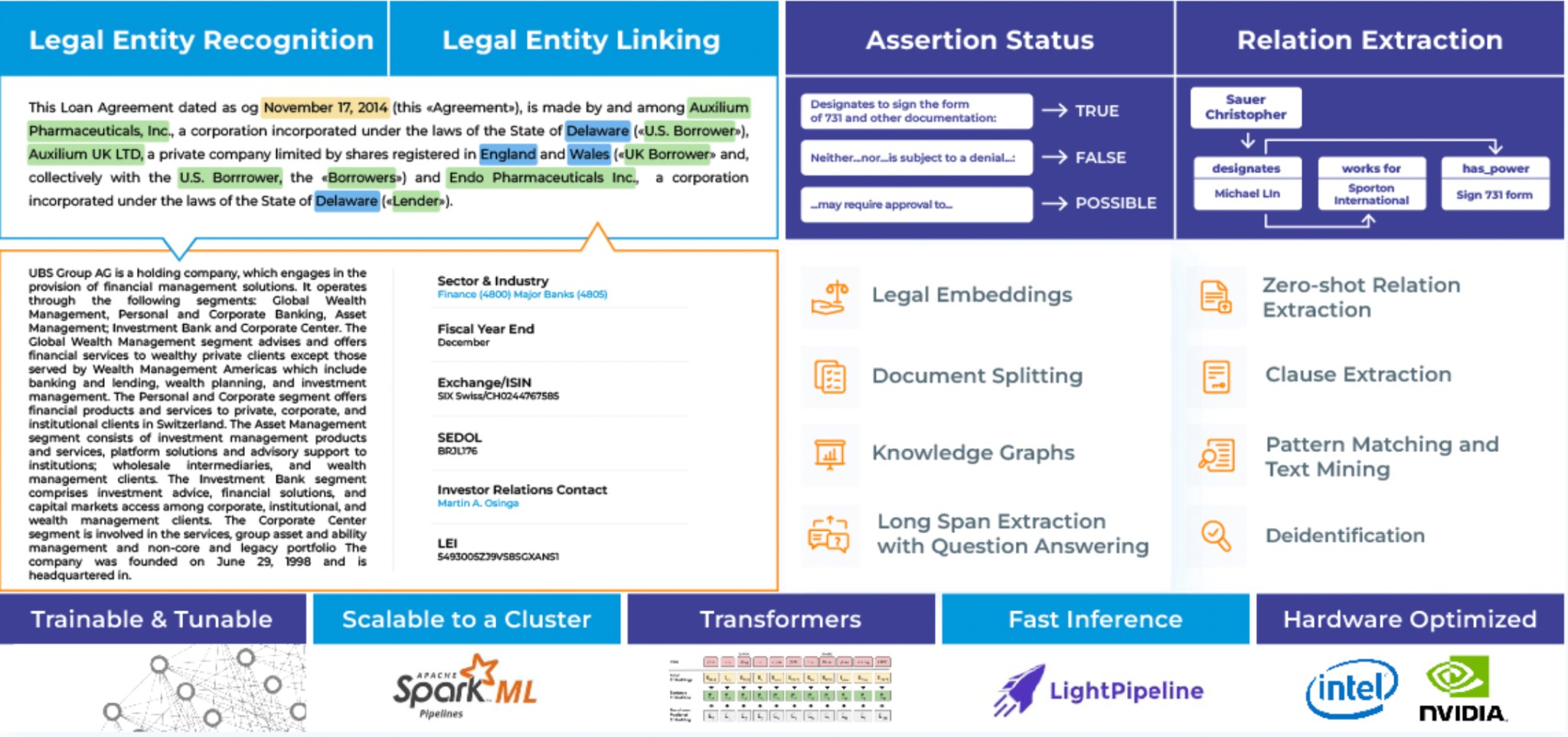
John Snow Labs built Legal NLP – a dedicated library that contains a series of new pretrained models and state-of-the-art algorithms, able to carry out Entity Recognition, Relation Extraction, Assertion Status Detection, Entity Resolution, De-identification, Text Mining, and more.
John Snow Labs commands a 59% market share in Healthcare & Life Science, with customers including half of the world’s top 10 Pharmaceutical companies and the three largest US Healthcare companies, among others. Many of the same challenges within Healthcare—highly domain-specific language, stringent privacy and compliance regulations, and a mix of structured and unstructured data — apply to the Legal industry.
Automatic Prompt Generation and Long Span Extraction
Legal documents are known to have very long sentences, separated by breaks like commas, semicolons, etc, but with no sentence disruption.
Relevant pieces of information often come in those unsplittable spans.
By following a “Divide and Conquer” approach and extracting the short components (subject, action, indirect_object) using NER we can:
- Generate questions on the fly
- Use a Q&A model to retrieve the piece of information which answers to the question, with less length limitations than NER

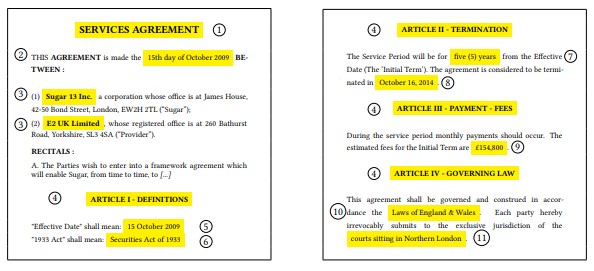
Extract 500+ different types of legal clauses
Split your documents into paragraphs.
Use our 500+ clause classification models to automatically annotate your agreement clauses.
- Extract the relevant
- Compare clauses.
- Analyze for compliance.
- Make decisions
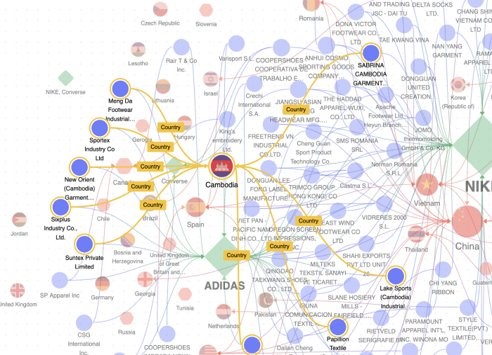
Knowledge Graphs and Data Augmentation
Use our Legal annotators with preloaded information from Public
and Private companies to augment your extracted companies with additional information. Use our models and notebooks to finetune and infer on new documents. Take decisions based not only in the information present in the text, but also with additional information about the entities detected as Companies or People
Legal NLP and Visual NLP- A step forward to Multimodal AI
Many legal documents are multimodal, including unstructured text, tables, forms, and combinations of unstructured and structured information together (text inside tables).
Multimodal scenarios can be solved by using:
- Visual NLP for Table and Form Extraction;
- Legal NLP for Legal Q&A on tables

Contract Understanding with Legal NLP Pretrained Pipelines
Contract understanding is the method of automatically checking an agreement and understanding the information contained in it. Natural Language Processing automates this manual process and extracts key information from the contracts quickly and accurately.
Below are the NLP pipeline stages for legal processing of agreements.
- Classifying the document type
- Identifying the clauses in the documents
- Extracting information from clauses
- Extracting relations
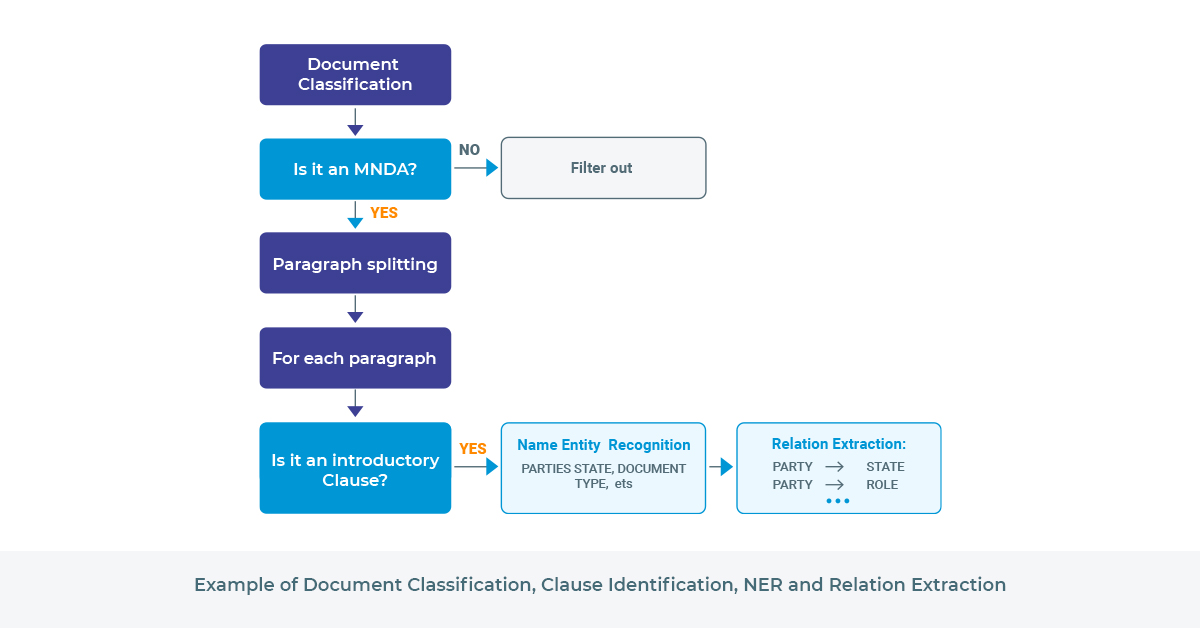
NER and Zero-shot NER Legal NLP Pipeline for Deidentification
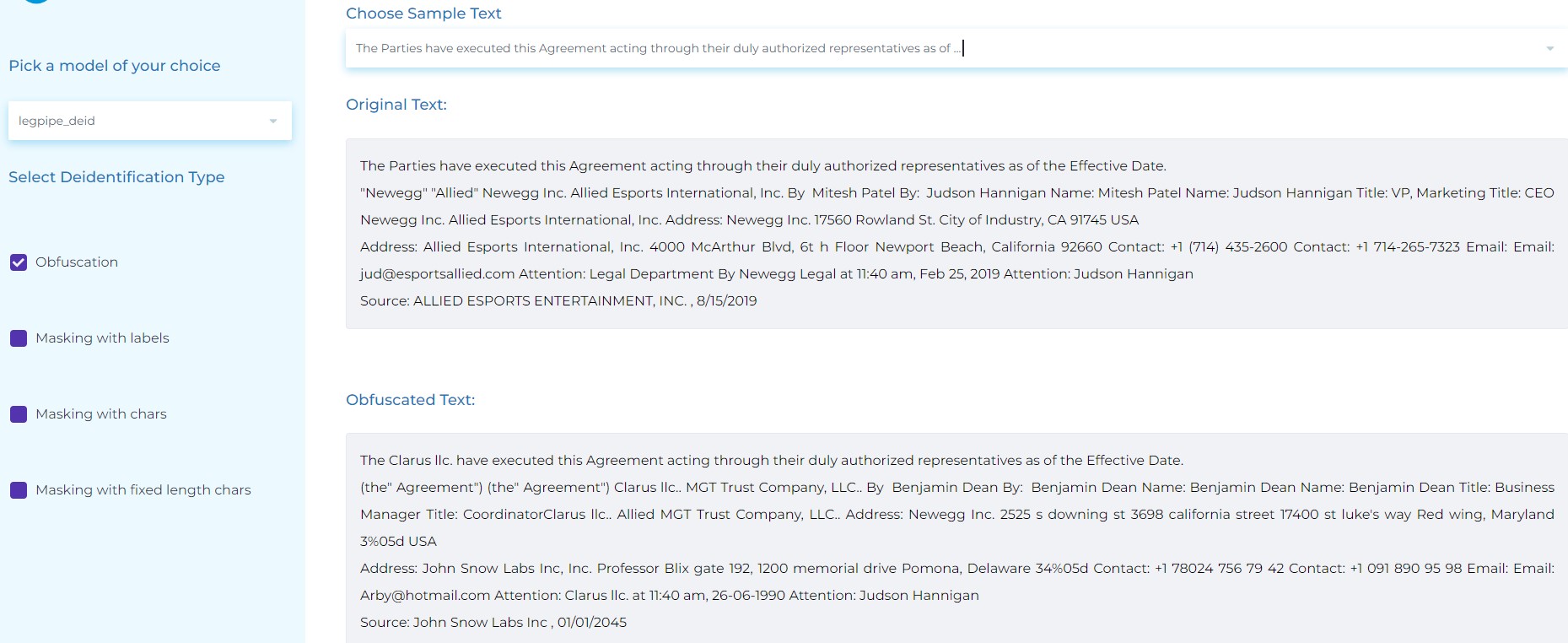
Deidentification detects privacy-related entities in text such as person name, organization name, contact data, etc., and masks them via various techniques. The idea behind deidentifying legal documents is simple, but the mechanisms of masking/obfuscating them are not.
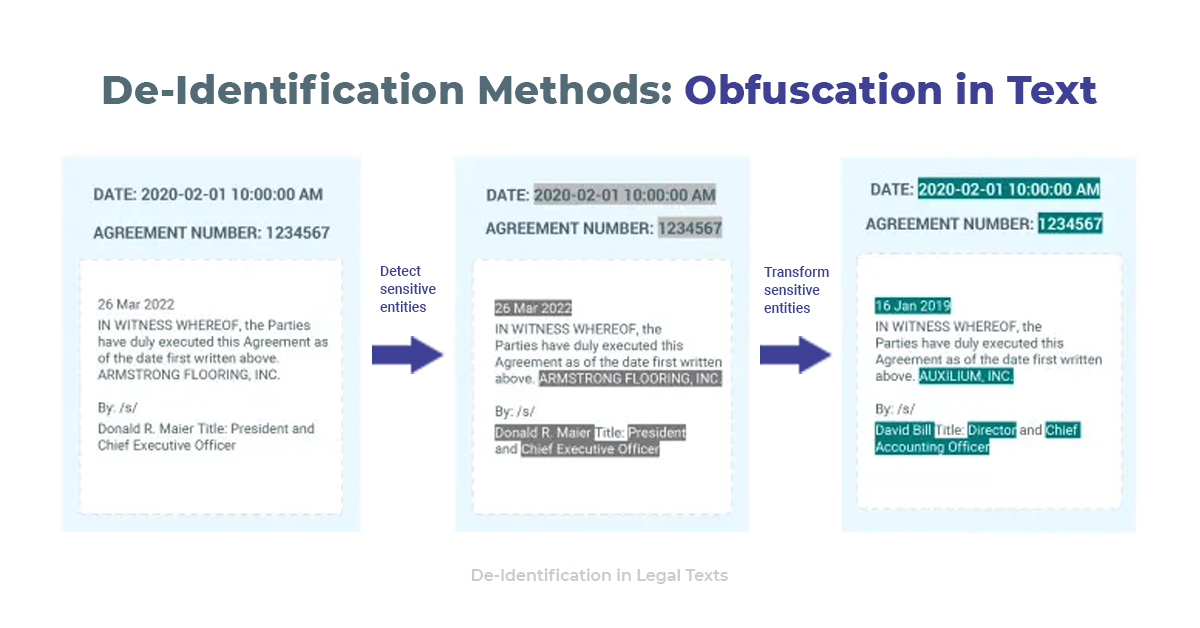 Legal NLP has all the capabilities we need to keep your data secure.
Legal NLP has all the capabilities we need to keep your data secure.Here are the different parts of it.
Step 1: Identification of Legal Entities — Named Entity Recognition
- Legal NLP offers three approaches for Information Extraction:
- Deep-learning NER
- Zero-shot NER
- Rule-based NER
Legal NLP combines all of them into one generic pipeline having:
- DocumentAssembler
- SentenceDetector
- Tokenizer
- Once, text is split into sentences and words, we do Transformer-based NER.
- Use Zero-shot, Transformer-based NER that does not require any training data.
- Use Contextual Parser: a rule-based approach
- Putting them together: ChunkMerger
Step 2: Deidentification
We can use four techniques to deidentify our legal entities.
- Masking the extracted information with the entity name
- Masking the letters of the extracted information with a symbol for each letter
- Masking the extracted information with a fixed amount of symbols of a choice
- Obfuscating: making up new examples, similar to the original ones
Conclusion
Extracting insights from legal documents is highly intensive, so any sort of automation can be a considerable relief for lawyers. Legal NLP model enables that by providing current state-of-the-art accuracy, a broad set of out-of-the-box models for common tasks, and ease of use building them into production systems.
Legal NLP is supported on all major data platforms including public cloud providers, Databricks, Kubernetes, on-premise, or on single machines. One-click installation with a 30-day free trial is available through AWS Marketplace and Azure Marketplace.





