A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
We are very excited to announce the release of Annotation Lab 1.8.0 which comes with an integration with the NLP Models Hub. Any compatible NER model and Embeddings can be downloaded and made available to the Annotation Lab users for preannotations either from within the application or via manual upload. This release also includes Bring-Your-Own-License (BYOL) feature which allows users to upload their Spark NLP license in order to gain access to any Licensed/Healthcare models and embeddings for preannotation and training. As always we have included optimizations and bug fixes to make the application more robust and stable.
Models Hub Integration
Models Hub page can be accessed via the left navigation menu by users in the UserAdmins group.
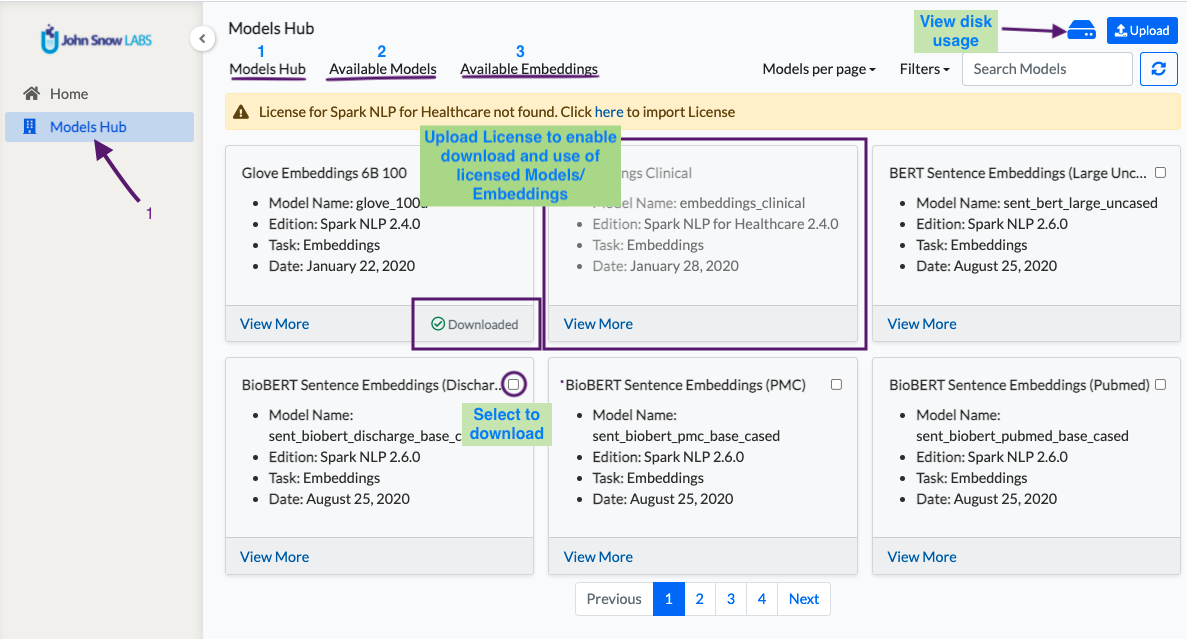
The Models Hub page has three tabs that hold information about models and embeddings.
- Models Hub Tab
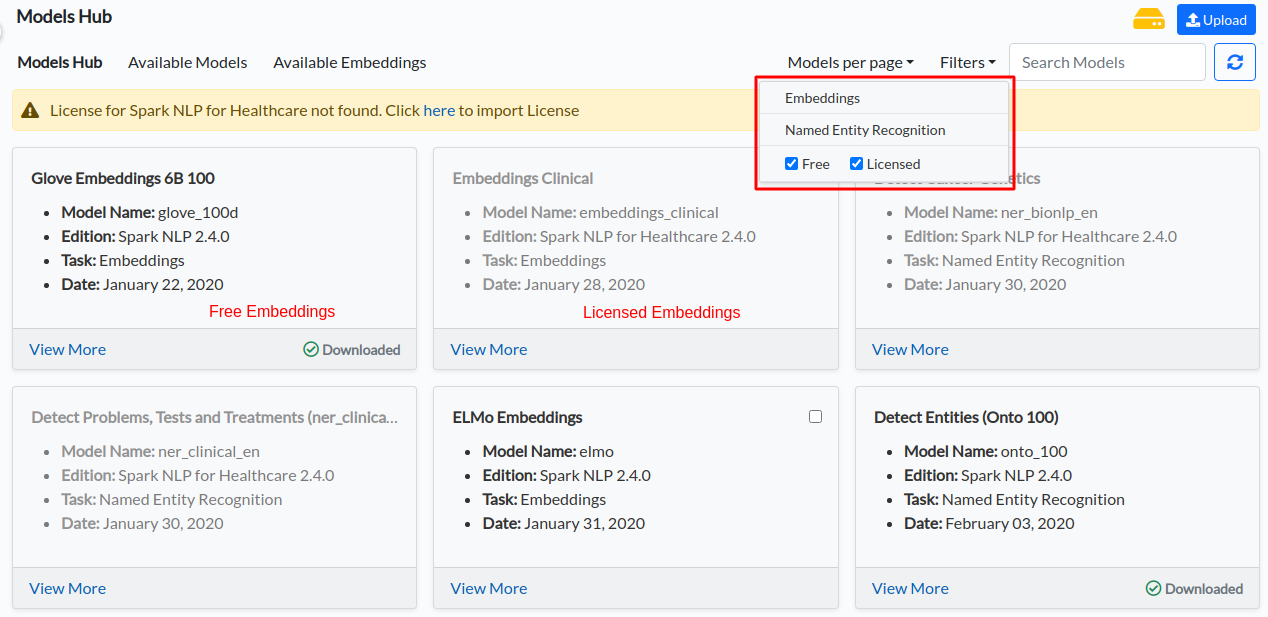
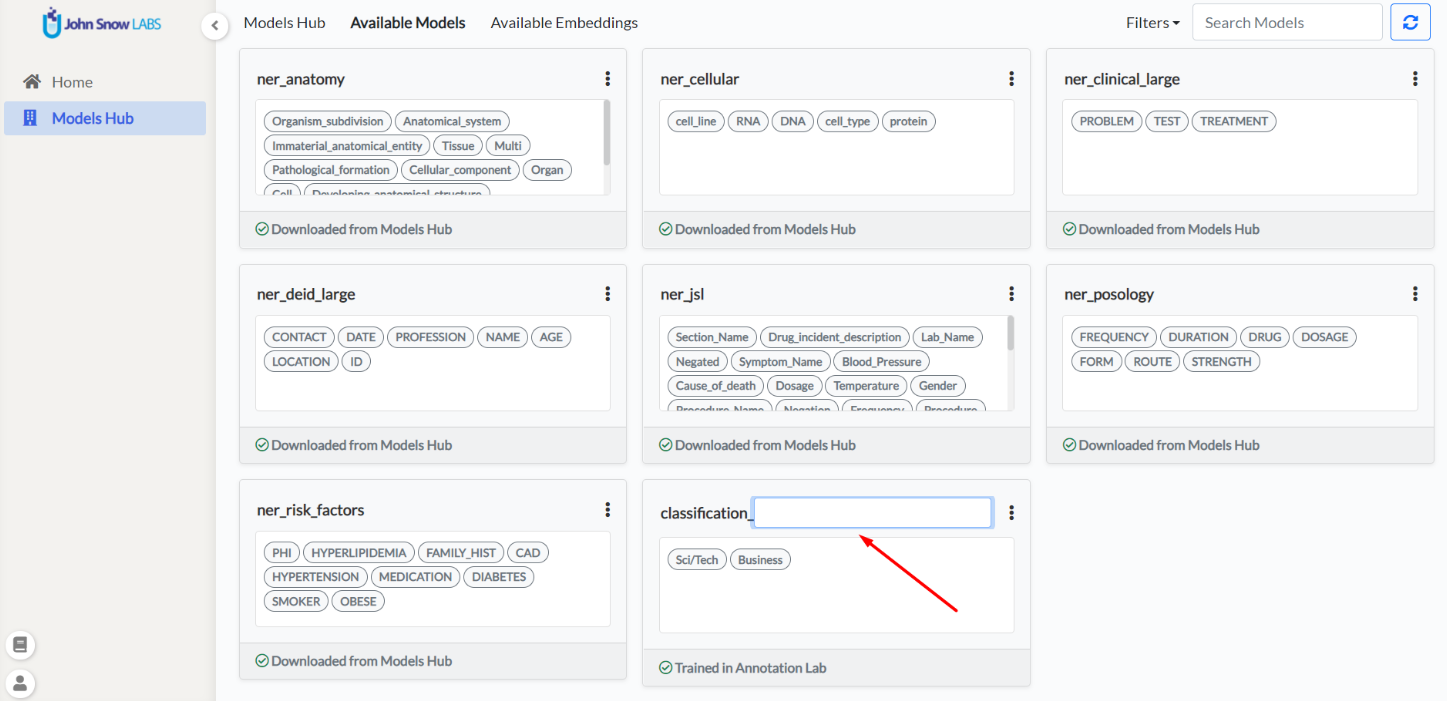
This tab lists all pretrained NER models and embeddings from NLP Models Hub which are compatible with Spark NLP 2.7.5 and which are defined for the English language. By selecting one or multiple items from the grid view, users can download them to the Annotation Lab. The licensed/Healthcare models and embeddings are available to download only when a valid license is uploaded. - Available Models
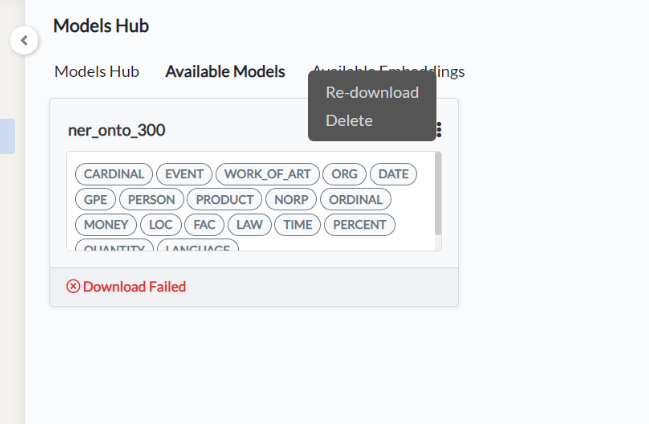
All the models available in the Annotation Lab are listed in this tab. The models are either trained within the Annotation Lab, uploaded to Annotation Lab by admin users, or downloaded from NLP Models Hub. General information about the models like labels/categories and the source (downloaded or trained or uploaded) of the model can be viewed. It is possible to delete any model or redownload failed ones by using the overflow menu on the top right corner of each model.
- Available Embeddings
This tab lists all embeddings available to the Annotation Lab together with information on their source and date of upload/download. Like models, any compatible embeddings can be downloaded from NLP Models Hub. By default, glove_100d embeddings are included in the deployment.
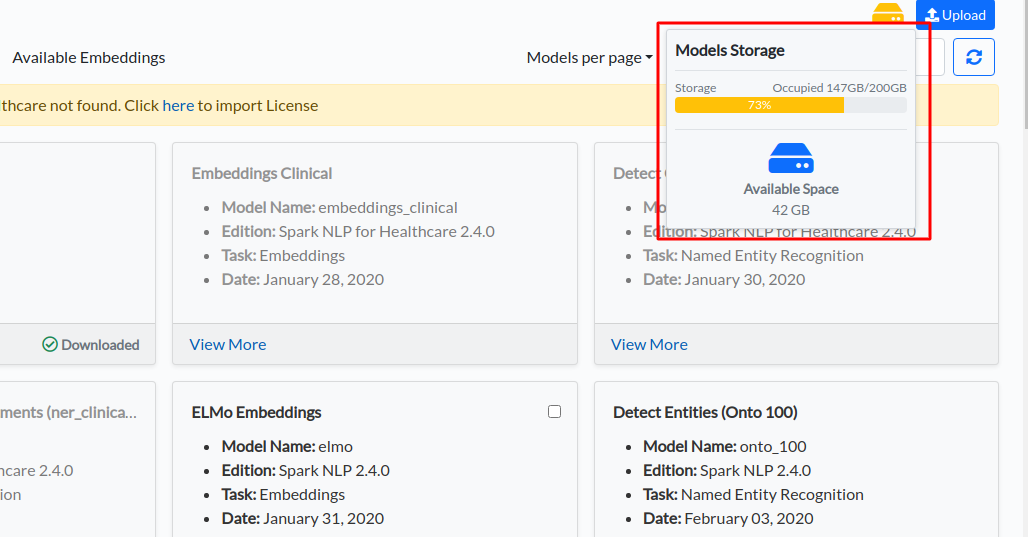
Disk usage view, search, and filter features are available on the upper section of the Models Hub page.
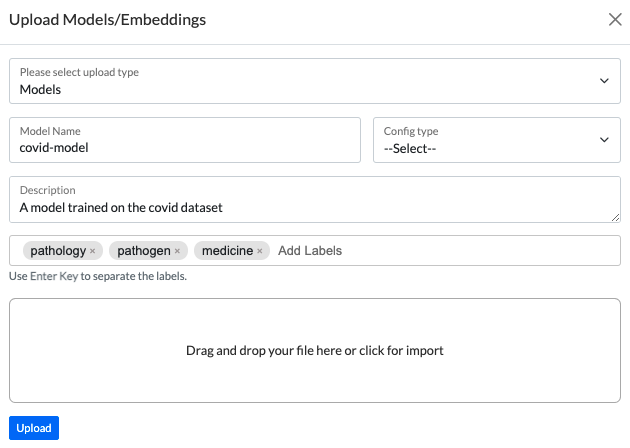
Custom NER models or embeddings can be uploaded using the Upload button present in the top right corner of the page. The labels predicted by the uploaded model need to be specified using the Model upload form.
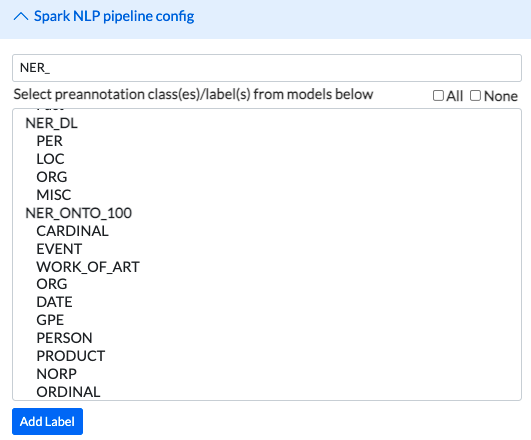
All available models are listed in the Spark NLP Pipeline Config on the Setup Page of any project and are ready to be included in the Labeling Config for preannotation.
Bring Your Own License (BYOL)
Admin users can upload a Spark NLP license by visiting the License page.
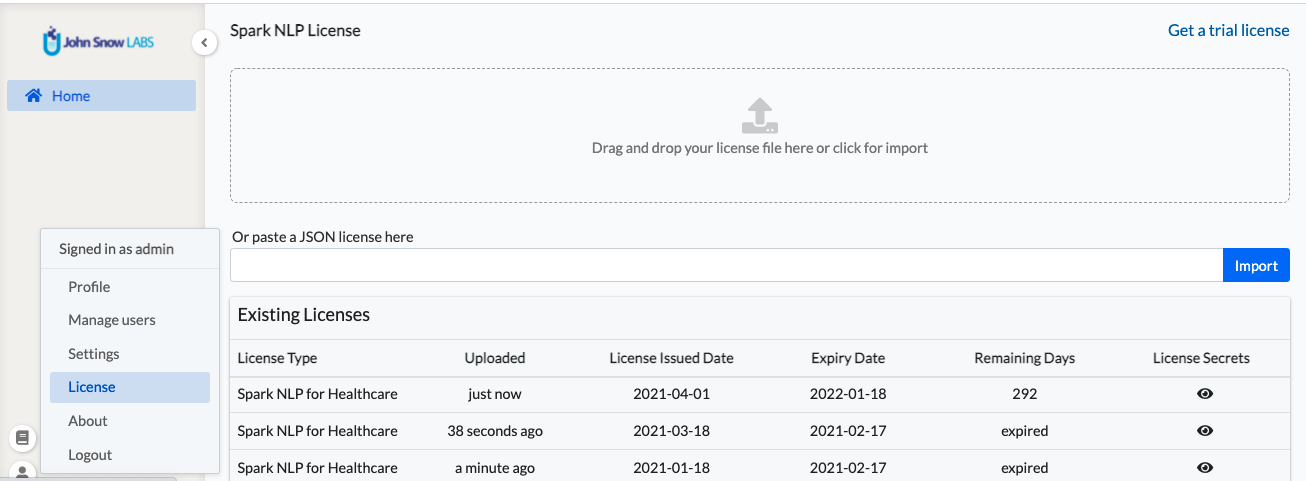
Once a valid license is uploaded, all the licensed/Healthcare models and embeddings become available for download. Unless a valid license is found in the Annotation Lab, training is disabled along with the preannotation of documents using licensed models and embeddings.
The License page shows the history of license uploads with detailed information like License Issued Date, Expiry Date, and Remaining Days of each upload. Admin users will see License expiry warnings in the Menu List if any license is approaching the expiry date or has expired.
Training Models
In previous versions of Annotation Lab, when there were multiple types of annotations in a single project like classifications, NER, and assertion status, multiple pieces of training were triggered at the same time using the same system resources and Spark NLP resources. In this case, the training component could fail because of resource limitations.
In order to improve the usability of the system, we have added a drop-down option to choose which type of training to run next. The project Owner or Manager of a project can go to the “Advanced Options” and choose the training type. The drop-down gives a list of possible training types for that particular project based on defined Labeling Config. Another drop-down also lists available embeddings which can be used for training the model.
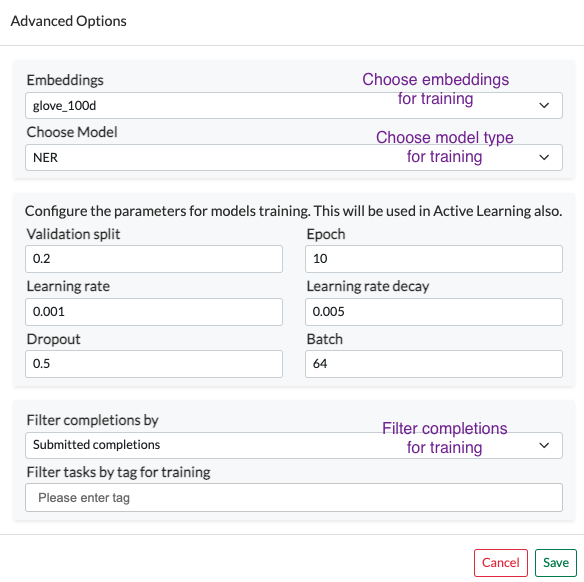
To control the quality of the dataset used for training models, the previous versions of Annotation Lab had the option to filter tasks by tag. The Annotation Lab v1.8.0 includes additional filtering options for the training dataset based on the status of completion, either all submitted completions cab be used for training or only the reviewed ones (a drop-down is added in the “Advanced Options”).
For training an Assertion Status Model, only the licensed clinical embeddings (embeddings_clinical) are supported for the moment.
By default, Annotation Lab uses a naming convention to name any trained models. Users now have the option to rename the trained models by using the rename option on the “Available Models” tab of the Models Hub page.
Preannotation
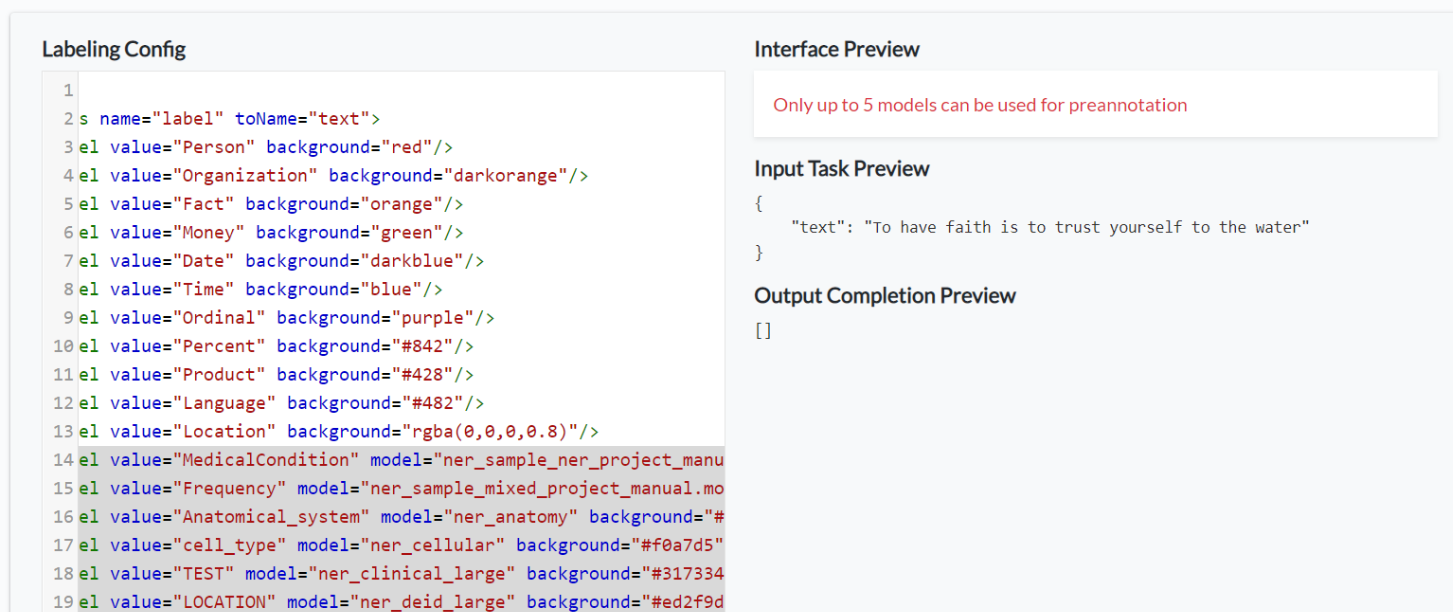
Loading too many models in the preannotation server is not memory efficient and may not be practically required. Going forward the application supports maximum of five different models to be used for the preannotation server deployment.
Another restriction for the server deployment is, two models trained on different embeddings cannot be used together in the same project.
The Labeling Config will throw validation errors in any of the cases above and hence Labeling Config cannot be saved and the preannotation server deployment will fail.

Because of the integration of the BYOL feature, we have removed the previously shipped seven NER models and the clinical embeddings. To continue using them, users can go to Models Hub and download them, given a valid license is available.
More Features
This version introduces a new “View as” feature to the Task page. Users can view task statuses based on their roles, such as Annotator, Manager, or Reviewer, by using the “View as” feature. This option is available only if the currently logged-in user has multiple roles.

In the save completion API, users can now save completions without using the “created_username” and “created_ago” fields. For example, the following JSON can be used saved directly and the Annotation Lab will use currently logged in user and current Date Time for those fields respectively.
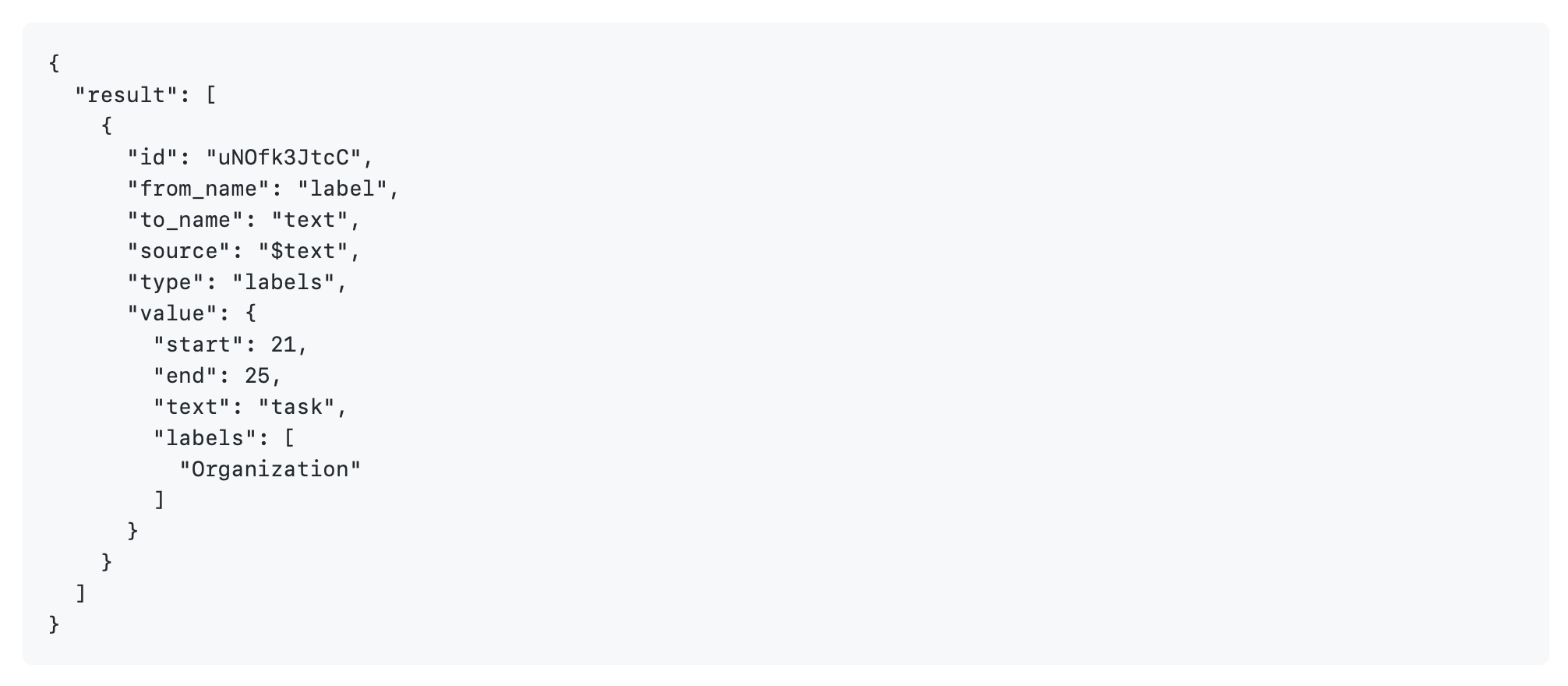
Also if the completion id is missing, a new id is generated.
In previous versions, tasks were imported based on a new line character when importing a text file. However, starting with this release, each text file will be imported as a single task.
Not all characters can be assigned as hotkeys in Labeling Config. The previous version did not have the validation in place for the usage of such illegal characters. Going forward, when any of those characters appear as hotkeys in Labeling Config, an error will be generated preventing the project configuration from being saved.
We have improved and added more APIs in swagger docs. To know the Spark NLP version that drives the current Annotation Lab we have added all info on the “About” page.