Legal NLP 1.10 comes with a lot of new capabilities added to the 800+ models and 125+ Language Models already available in previous versions of the library. Let’s take a look at each of them!
New Language Models in different languages
We added new Legal Sentence and Word Embeddings for Italian, Portuguese, Spanish and English. This sums up to more than 25 languages available in Legal NLP!
A language model provides you with numerical representations (embeddings) of words or sentences in context. This allows you to:
- If it’s word (token) embeddings, to train word (token) classifiers, as NER.
- If it’s sentence embeddings, to calculate the similarity between different legal texts, train classifiers, and cluster your texts.
Find your models in our Models Hub.
EURVOC taxonomy in different languages (+100 classes)
We include a set of 5 legal multilabel classifiers trained on the MultiEURLEX dataset across 5 different languages(English, German, French, Greek, and Slovak), on 11,000 different documents per language, specifically on EURVOC taxonomy.
Multilabel classification means one classifier can retrieve more than 1 class. EURVOC taxonomy is huge, including many different levels of classes:
 We include levels 1 and 2 law classes, which sum up to more than 100+ classifiers:
We include levels 1 and 2 law classes, which sum up to more than 100+ classifiers:
- Level 1 law sectors:
finance,agriculture, civil law, chemistry, education, politics, prices, etc... - Level 2 law sectors:
social_protection, science, investment, international law, etc
English / German Legal Argument Mining
We include a multiclass (1 text — 1 class) classification model which classifies arguments in legal discourse using one of the following classes subsumption, definition, conclusion, other. Available in two languages: German and English.

New Question & Answering demos
In our demo section you can find examples of usage of our Legal Question & Answering models.
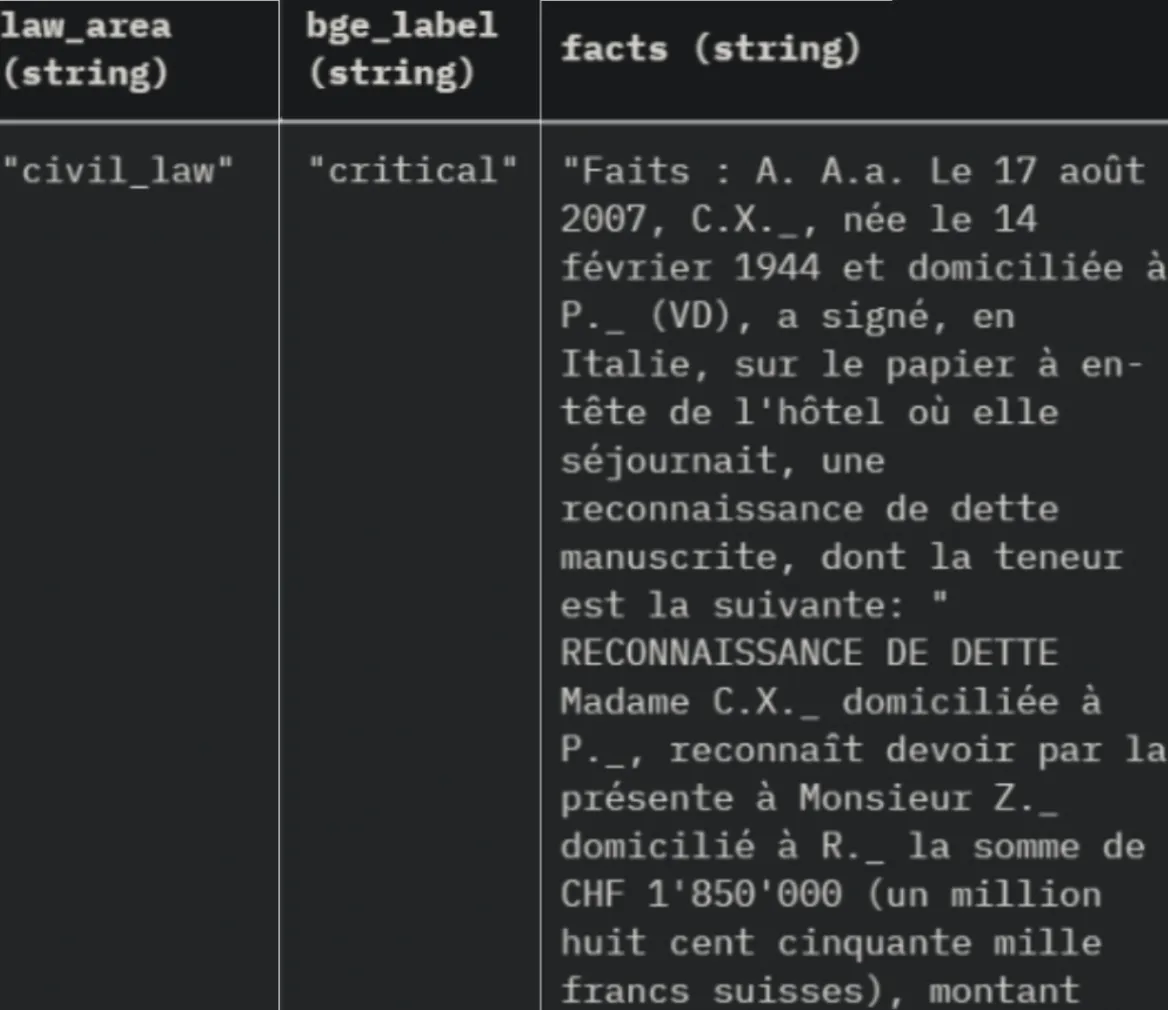
Multilingual Legal Criticality Prediction and Law Area prediction
2 Multilingual models trained on a diachronic dataset of 130K Swiss Federal Supreme Court (FSCS) in French, Italian and German:
criticalornot_criticallabels;- Law area (
civil_law, public_law, penal_law, public_law)
Improved models
We have improved:
- Our Binary Classifier for NDA agreements, which tells if a document is an NDA / MNDA agreement or it is not.
- The detection of Former Names of Parties in agreements.
![]()
- Our ORGANIZATION vs PRODUCT Named Entity Recognition models.

Fancy trying?
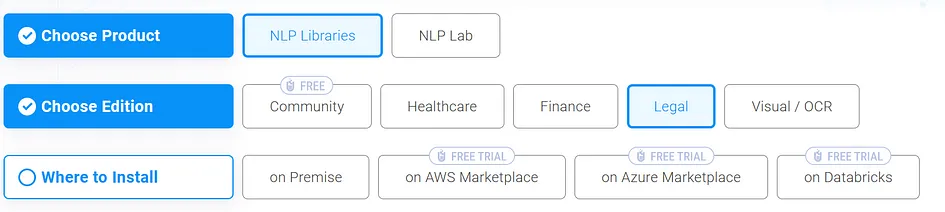
We’ve got 30-days free licenses for you with technical support from our legal team of technical and SME. This trial includes complete access to more than 700 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 120+ legal language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
How to run
Legal NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()