























































De-identification is detecting privacy-related entities in text, such as person, organization names, emails, and other contact data, and masking them with different techniques. This task, also called anonymization or redaction, can help you:
- Keep a copy of your documents without any privacy-related information;
- Use those documents to train your own NLP models without having the model seeing any private data;
- Share your documents with third parties for analytical, statistical, or data science purposes;

De-identification in Legal Texts
Original data and de-identified data are similar in terms of their informativity and value, allowing deidentified documents to be analyzed as if they were the originals but without any potential privacy risk.
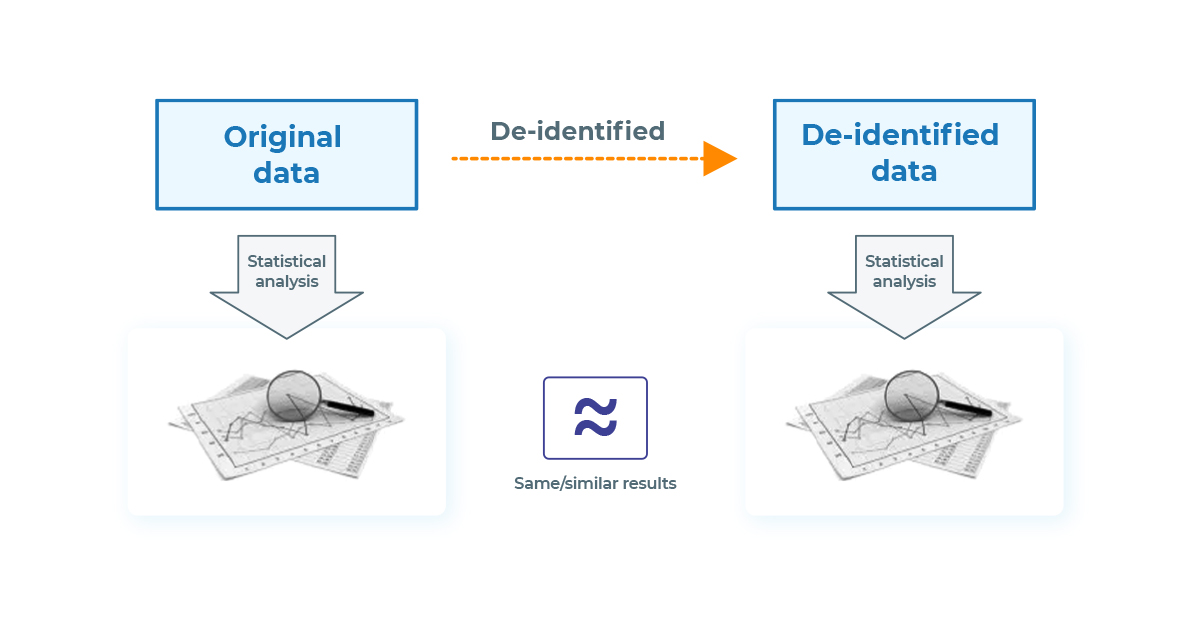
Legal NLP for De-identification purposes
Legal documents have much private information in them. Some documents may be public and available, especially if they are about public companies or transactions which need to be publicly announced (you can find thousands of those in SEC Edgar database), but others may not be.
This is a list of entities you may be interested in deidentifying:
- Names of the parties of a private agreement, organizations;
- Names of people involved in those transactions, signers and their roles;
- Effective dates or any other date;
- Addresses, including streets, cities, states, and countries;
- Contact information: phones, emails, etc.
The idea behind de-identification is simple, but the mechanisms of detecting and masking or obfuscating information are not. Fortunately, Legal NLP, an enterprise library developed by John Snow Labs, has all the necessary capabilities to keep your data secure. Let’s see the different parts of it.
Step 1: Identification — Name Entity Recognition
The first required step to carry out data masking or obfuscation of private information is being able to detect those entities. That means Information Extraction, or more specifically, Named Entity Recognition, is required as a first step.
Name Entity Recognition (NER) is the NLP task of processing texts and identifying pieces of information (entities) relevant to our use case. In our scenario, these are private data.
Legal NLP offers up to three approaches for NER:
- Deep-learning NER: using state-of-the-art Transformer-based architectures to train models to detect those entities, which can be consumed during processing (inference) time.
- Zero-shot NER: a novel approach that requires no training, just a series of questions defining the information you want to retrieve and a state-of-the-art Legal NLP language model (as Legal Bert).
- Rule-based NER: a classic approach that allows you to define rules, regular expressions, vocabulary, prefixes, suffixes, context, etc., to identify your entities.
Let’s see how a Legal NLP can combine all of them in one pipeline!
First, we need the DocumentAssembler, which creates documents from our texts. After, the SentenceDetector will split our texts into sentences, and the Tokenizer will divide them into words. Those are three typical components of a generic NLP pipeline.
documentAssembler = nlp.DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
sentenceDetector = nlp.SentenceDetector()\
.setInputCols(["document"])\
.setOutputCol("sentence")
tokenizer = nlp.Tokenizer()\
.setInputCols(["sentence"])\
.setOutputCol("token")
Transformer-based NER
After we have split our texts into sentences and words, we are ready to do Transformer-based NER. In our case, we will use state-of-the-art Legal Roberta Embeddings, loading a pretrained model which extracts Document Types, Parties, Aliases/Roles of the parties, Effective Dates, etc., from agreements, called legner_contract_doc_parties_lg and which is available in our Legal NLP Models Hub.
embeddings = nlp.RoBertaEmbeddings.pretrained("roberta_embeddings_legal_roberta_base","en") \
.setInputCols(["sentence", "token"]) \
.setOutputCol("embeddings")
ner_model = legal.NerModel.pretrained('legner_contract_doc_parties_lg', 'en', 'legal/models')\
.setInputCols(["sentence", "token", "embeddings"])\
.setOutputCol("ner")
# This annotator merges all tokens of NER into NER Chunks
ner_converter = legal.NerConverterInternal() \
.setInputCols(["sentence", "token", "ner"])\
.setOutputCol("ner_chunk")

Results of NER
Depending on your use case, you may want to extract or not extract entities as the State or Location of those companies (is it a Delaware corporation?). That pretrained model does not have that!
Zero-shot, transformer-based NER
Imagine you don’t have a model or enough data to train one for the entities you want to identify. Worry not! We can use a Zero-shot NER approach, which does not require any training data, but only a state-of-the-art Legal NLP Language Model.
Using it, you can define a series of questions you will ask the model. If the model understands any information as an answer to that question, it will be retrieved as a NER entity.
zero_shot_ner = legal.ZeroShotNerModel.pretrained("legner_roberta_zeroshot", "en", "legal/models")\
.setInputCols(["sentence", "token"])\
.setOutputCol("zero_shot_ner")\
.setPredictionThreshold(0.4)\
.setEntityDefinitions(
{
"STATE":["Which state?"],
"ADDRESS": ["Which address?", "What is the location?"],
"PARTY": ["Which LLC?", "Which Inc?", "Which PLC?", "Which Corp?"]
})
# This annotator merges all tokens of NER into NER Chunks
zeroshot_ner_converter = legal.NerConverterInternal() \
.setInputCols(["sentence", "token", "zero_shot_ner"])\
.setOutputCol("zero_ner_chunk")\
As you see, in setEntityDefitions we have included a dictionary where the keys are the NER entities you want to extract, and the values are an array of questions that trigger the extraction. As easy as that!
You can even combine Zero-shot NER to extract entities detected by our previous NER approach. For example, PARTY. If our last model missed any entity, maybe Zero-shot NER can catch it!
NOTE: Please always configure correctly the confidence threshold to prevent retrieving many false positives.
Contextual Parser: a rule-based approach
Zero-shot models are usually heavy since they are built on top of big Language Models. Always consider efficiency: maybe your problem can be solved more easily?
Indeed, for State, we could have a list of the states of the US, or Countries in the World, as a vocabulary. For emails or phone numbers in the US, we have regular expressions. There is an extensive range of capabilities that are flexible, very high level, and much more efficient than using big deep learning models. Let’s see some examples of Contextual Parser in action.
Let’s define an EMAIL and a PHONE regular expressions with ContextualParser JSON format, including the name of the entity, scope (document, sentence…), etc.
email = {
"entity": "EMAIL",
"ruleScope": "document",
"completeMatchRegex": "true",
"regex":'[\w-\.]+@([\w-]+\.)+[\w-]{2,4}',
"matchScope": "sub-token"
}
phone = {
"entity": "PHONE",
"ruleScope": "document",
"completeMatchRegex": "true",
"regex":'(\+?\d{1,3}[\s-]?)?\(?\d{3}\)?[\s.-]?\d{3}[\s.-]?\d+',
"matchScope": "sub-token"
}
Let’s save them to disk.
with open('email.json', 'w') as f:
json.dump(email, f)
with open('phone.json', 'w') as f:
json.dump(phone, f)
And now, we are ready to import them into our ContextualParsers (1 entity per annotator):
email_parser = legal.ContextualParserApproach() \
.setInputCols(["sentence", "token"]) \
.setOutputCol("email")\
.setJsonPath("email.json") \
.setCaseSensitive(False)
phone_parser = legal.ContextualParserApproach() \
.setInputCols(["sentence", "token"]) \
.setOutputCol("phone")\
.setJsonPath("phone.json") \
.setCaseSensitive(False)
Look at this article to show other ContextualParser capabilities as vocabulary lists in CSV, context, prefixes, suffixes, etc.
Putting them together: ChunkMerger
Now, different NER approaches will retrieve different NER entities for us. Let’s put all of them together!
chunk_merger = legal.ChunkMergeApproach()\
.setInputCols("email", "phone", "ner_chunk", "zero_ner_chunk")\
.setOutputCol('merged_ner_chunks')
Step 2: De-identification
After we have identified our legal entities, we need to de-identify them. For that, we have four different techniques:
- Masking the extracted information with the name of the entity. For example, ARCONIC, INC. with <PARTY>.
# Previous Masking Annotators
#deid model with "entity_labels"
deid_entity_labels= legal.DeIdentification()\
.setInputCols(["sentence", "token", "merged_ner_chunks"])\
.setOutputCol("deidentified")\
.setMode("mask")\
.setMaskingPolicy("entity_labels")
- Masking the letters of the extracted information with a symbol for each letter. For example, for ARCONIC, INC. with *, we will get
*************
#deid model with "same_length_chars"
deid_same_length= legal.DeIdentification()\
.setInputCols(["sentence", "token", "merged_ner_chunks"])\
.setOutputCol("masked_with_chars")\
.setMode("mask")\
.setMaskingPolicy("same_length_chars")
- Masking the extracted information with a fixed amount of symbols of a choice. For example, for ARCONIC, INC. with * and 3, we will get ***.
#deid model with "fixed_length_chars"
deid_fixed_length= legal.DeIdentification()\
.setInputCols(["sentence", "token", "merged_ner_chunks"])\
.setOutputCol("masked_fixed_length_chars")\
.setMode("mask")\
.setMaskingPolicy("fixed_length_chars")\
.setFixedMaskLength(3)
- Obfuscating: making up new examples similar to the original ones so that we feel an actual document. For instance, for ARCONIC, INC., we may get CORVIN APPS, L.L.C.
# Obfuscation
obfuscation = legal.DeIdentification()\
.setInputCols(["sentence", "token", "merged_ner_chunks"]) \
.setOutputCol("obfuscated") \
.setMode("obfuscate")\
.setObfuscateDate(True)\
.setObfuscateRefFile('obfuscate.txt')\
.setObfuscateRefSource("both")
There are several libraries you can use to create obfuscate.txt a file with custom vocabulary to be used in your obfuscation. We even have our own pretrained faker for entities such as EMAIL, PHONE, AGE, etc. But this is how we can quickly generate new ones with Faker:
!pip install faker
from faker import Faker fk = Faker()
obs_lines = ""
for _ in range(25):
obs_lines += f"\n{fk.name().strip()}#PERSON"
obs_lines += f"\n{fk.date().strip()}#DATE"
obs_lines += f"\n{fk.company().strip()}#PARTY"
obs_lines += f"\n{fk.phone_number().strip()}#PHONE"
obs_lines += f"\n{fk.email().strip()}#EMAIL"
with open ('obfuscate.txt', 'w') as f:
f.write(obs_lines)
The file obfuscate.txt looks like this:
John Smith#PERSON Maggy Andrews#PERSON 2023-02-01#DATE 2023-04-21#DATE john@corvin.com#EMAIL maggy@corvin.com#EMAIL Corvin Apps, L.L.C#PARTY John Snow Labs, Inc.#PARTY California#STATE Delaware#STATE ...
And with that, you can go from this original text…
text = """This Commercial Lease (this “Lease”) dated February 11, 2021, but made effective as of January 1, 2021 (the “Effective Date”), is made by and between 605 NASH, LLC, a California limited liability company (“Landlord”) and NANTKWEST, INC., a Delaware corporation (“Tenant”).
NASH, LLC, NANTKWEST, inc.,
a California limited liability company a Delaware corporation
By: /s/ Charles Kenworthy By: /s/ Richard Adcock
Name: Charles N. Kenworthy Name: Richard Adcock
Title: Manager Title: CEO
Address:
9922 Jefferson Blvd.
Culver City, CA 90232
Attention: Chuck Kenworthy Attention: Chief Financial Officer cfo@johnkopkins.com (0031) 913-123"""
… to this obfuscated one…
This Commercial Lease (this "Alias") dated August 28, 2009, but made effective as of September 28, 2009 (the "Alias"), is made by and between Nixon-Barton, a California limited liability company ("Alias") and Coffey, Murray and Moore., a California corporation ("Alias").
Nixon, Barrow and Coffey, Murray and Moore, Inc.
a California limited liability company a California corporation
By: /s/ Emily Munoz By: /s/ Mrs. Lisa Cannon
Name: Emily Munoz Name: Mrs. Lisa Cannon
Title: CEO Title: Chief Legal Officer
Address:
Kellyshire, PW 97568
5648 Scott Course Apt. 351 90232
Attention: Charles Estes Attention: Chief Legal Officer charles@hotmail.com (001) 912-134-133
Demo
You can see more examples of Legal NLP de-identification, with all the techniques, here.
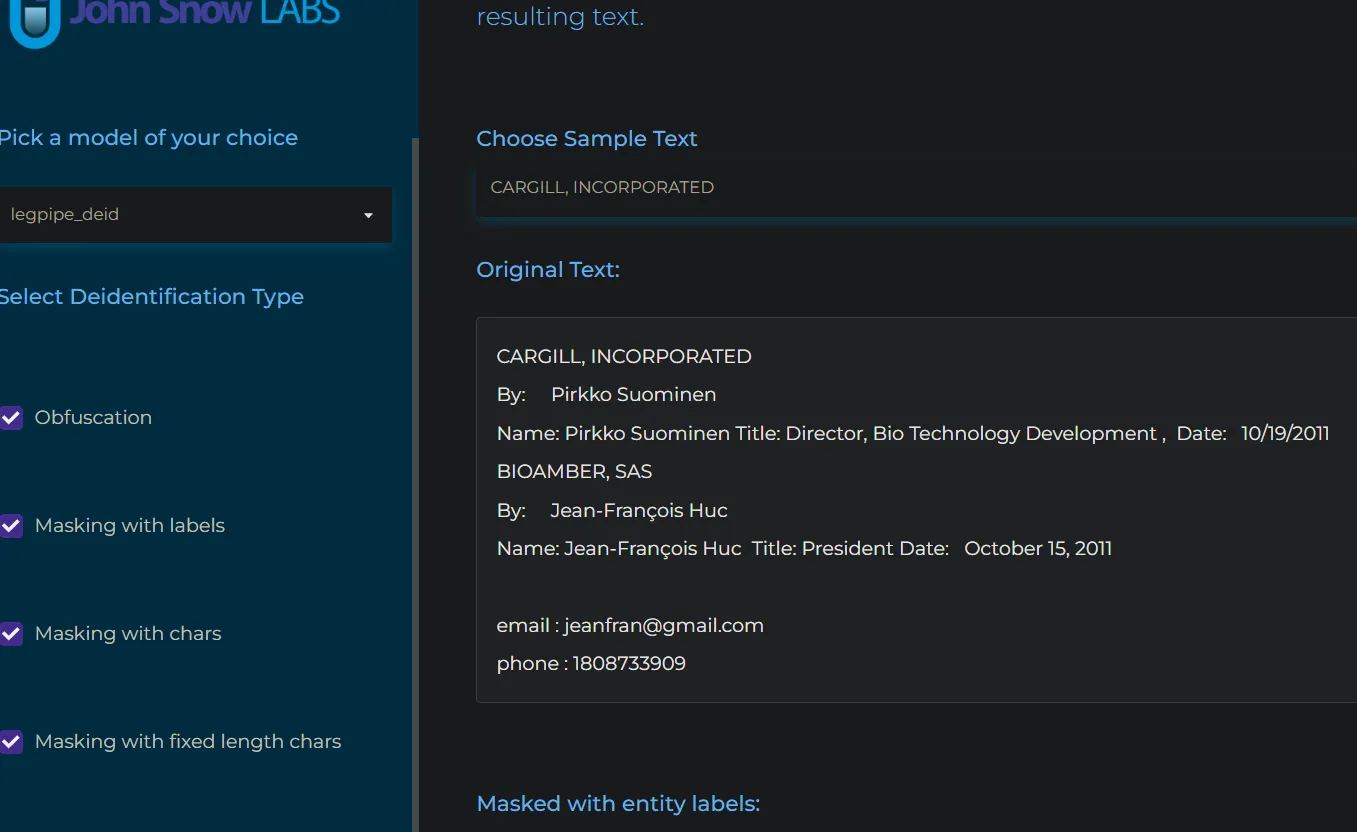
Notebook
The notebook to experiment with Legal NLP Deidentification is available in our Legal NLP workshop repo here.
FAQ
- Can I add new Entities? Yes, either training NER models, using Zero-shot NER, or with your patterns / regular expressions/vocabulary lists.
- Can I use my own vocabulary to obfuscate data? Yes, as shown above, you can use a simple syntax to generate or manually add examples for your data obfuscation.
- Do you maintain consistency if the same entity is found? Yes, absolutely! You can maintain consistency inside one document or multiple documents.
- Does it work with structured information (tables)? Check the notebook to see examples on tables.
- Can we add shifts to the dates? Yes, Check the notebook to see the examples.
How to run
Legal NLP is part of the Enterprise Spark NLP suite, the only auto-scalable NLP framework which is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()
Fancy trying?
We’ve got 30-day free licenses for you with technical support from our legal team of technical and SMEs. Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!





