























































Training a NER with BERT with a few lines of code in Spark NLP and getting SOTA accuracy.
NER is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
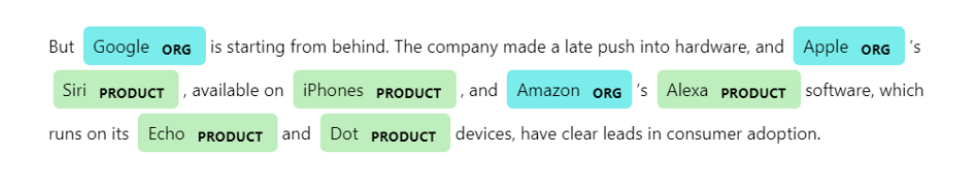
In this post, we will try to show you how to build a state-of-the-art NER model with BERT in Spark NLP library. The model we are going to implement is inspired by a former state of the art model for Named Entity Recognition: Bidirectional LSTM-CNN. This is a novel neural network architecture that automatically detects word- and character-level features using a hybrid bidirectional LSTM and CNN architecture, eliminating the need for most feature engineering.
In Spark NLP, there are three different pre-trained word embeddings models (and their variations) that you can plug and play depending on your use case.

Let’s get started!
We start with downloading the train and test set. We will use the official CoNLL2003 dataset, a benchmark dataset that has been used in nearly all the NER papers. You can download this dataset here.
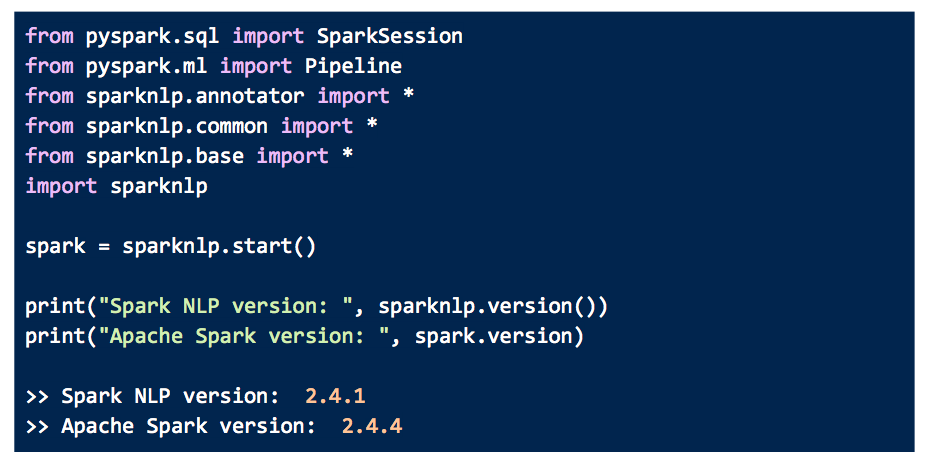
We import the relevant packages and then start coding.
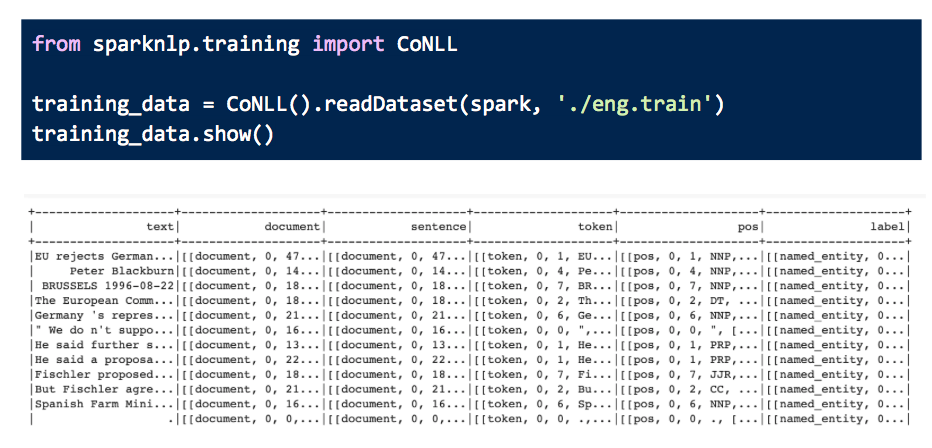
Then we convert the CoNLL file to Spark data frame with all the additional fields generated to be used later on.
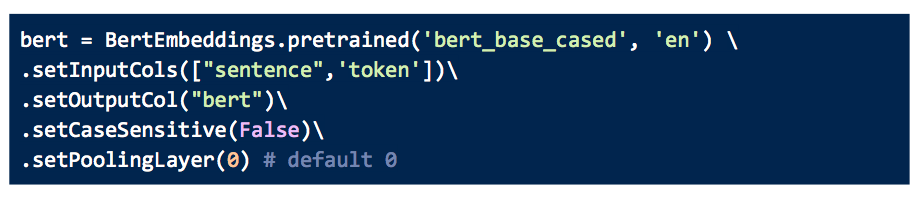
The next step is to get the word embeddings through BERT. We will use Spark NLP annotator called BertEmbeddings().
Then we import the NerDLApproach() annotator, the main module that is responsible for training the NER model.

Now we can append these two annotators in a pipeline.
 Fit the pipeline and get predictions.
Fit the pipeline and get predictions.

In sum, we can train a custom NER in SOTA algorithm with just a few lines of codes in Spark NLP.
You can find the detailed explanations and codes in this notebook.
Read also related articles on the topic:
Named Entity Recognition Python
After exploring named entity recognition (NER) with BERT in Spark NLP, integrating technologies like Generative AI in Healthcare can take clinical data analysis to the next level. By incorporating a Healthcare Chatbot, healthcare providers can automate responses, offer real-time insights, and engage with patients more efficiently, improving overall healthcare delivery.




