
























































Using Spark NLP in Python to identify named entities in texts at scale.

Named Entity Recognition with Python
TL;DR: Named Entity Recognition (NER) is a Natural Language Processing (NLP) technique that involves identifying and extracting entities from a text, such as people, organizations, locations, dates, and other types of named entities. NER is used in many fields of NLP, and using Spark NLP, it is possible to perform an extraction of entities from text in multiple ways with very high accuracy.
Named Entity Recognition (NER) is a Natural Language Processing (NLP) task that involves identifying and extracting entities from a text, such as people, organizations, locations, dates, and other types of named entities. NER aims to automatically recognize and classify named entities within a text, providing valuable information that can be used for various applications.
NER models are typically trained using supervised machine learning or deep learning algorithms. The training process involves providing the model with a set of annotated data, called the training set, that includes text documents along with labels for the named entities present in the text. The training set is typically created by human annotators who label the named entities in the text with predefined categories. The dataset is divided into a training set and a validation set, which is used to tune the model’s hyperparameters.
NER can be a challenging task, as named entities can have various forms and can be ambiguous in certain contexts. For example, the word apple can refer to a fruit or to the technology company. Similarly, the word Amazon can refer to a rain forest or to the e-commerce giant. Therefore, NER systems need to be able to disambiguate named entities based on context and other features.
In this article, we will discuss three annotators from the Spark NLP, namely NerDLModel, NerConverter and NerOverwriter.
NerDLModel is an annotator in the Spark NLP library that is used to recognize and extract entities from text. NerDLModel works as a pipeline component in Spark NLP and can be configured with various parameters to adjust its behavior. NerDLModel supports several pretrained models from the John Snow Labs Models Hub for different languages and can also be trained on custom data.
Overall, NerDLModel provides a powerful and customizable way to perform NER extraction in Spark NLP, making it a useful tool for a wide variety of NLP tasks.
NerConverter is another annotator in the Spark NLP library that is used to convert NER annotations between different formats. The main purpose of NerConverter is to enable interoperability between different NER models or tools that use different annotation formats.
NerConverter works as a pipeline component in Spark NLP and can be configured with various parameters to adjust its behavior. It can convert annotations between different formats, including IOB, BIO, and CONLL (CoNLL-U format).
NerOverwriter is a component in the Spark NLP library that is used to modify the output of a pre-existing NER model by using custom rules and patterns to identify and annotate additional entities. NerOverwriter works as a pipeline component in Spark NLP and can be configured with various parameters to adjust its behavior.
In this post, the aim is to discuss NER extraction by Spark NLP.
Let us start with a short Spark NLP introduction and then discuss the details of the named entities with some solid results.
How to use Spark NLP for NER in Python
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
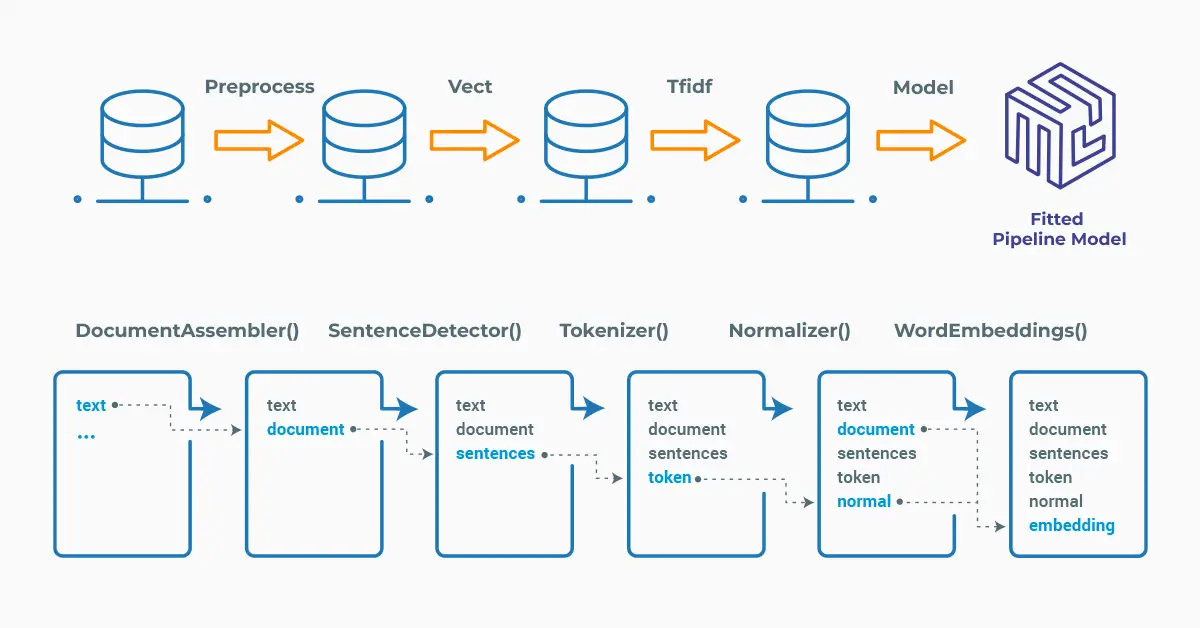
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
NER using Python: Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
!pip install spark-nlp !pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
NerDLModel
NerDLModel is an annotator in Spark NLP and it uses various embeddings as an input for extracting entities.
Instead of training, saving, loading and getting predictions from a model, we can use a pretrained model. In NLP, a pretrained model is a model that has been trained on a large amount of data for a specific task, such as image recognition, text classification, entity recognition or language translation. Pretrained models are typically trained on massive datasets using powerful hardware and advanced algorithms.
There are more than 14,500 models in the John Snow Labs Model’s Hub. NLP models often use word embeddings to represent words as dense vectors of real numbers and the embeddings capture semantic and syntactic information about words and are often pre-trained on large corpora of text. Depending on the type of embeddings that were used during training of the model, the vector dimension typically ranges from 100 to 768 dimensions.
The NerDLModel annotator expects DOCUMENT, WORD_EMBEDDINGS and TOKEN as input, and then will provide NAMED_ENTITY as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
To understand the concept better, we will use the following model: Detect Entities (BERT), where the model automatically extracts the following entities using distilbert_base_cased embeddings:
CARDINAL, DATE, EVENT, FAC, GPE, LANGUAGE, LAW, LOC, MONEY, NORP, ORDINAL, ORG, PERCENT, PERSON, PRODUCT, QUANTITY, TIME, WORK_OF_ART
The model was trained using DistilBertEmbeddings (distilbert_base_cased), so same embeddings must be used in the pipeline.
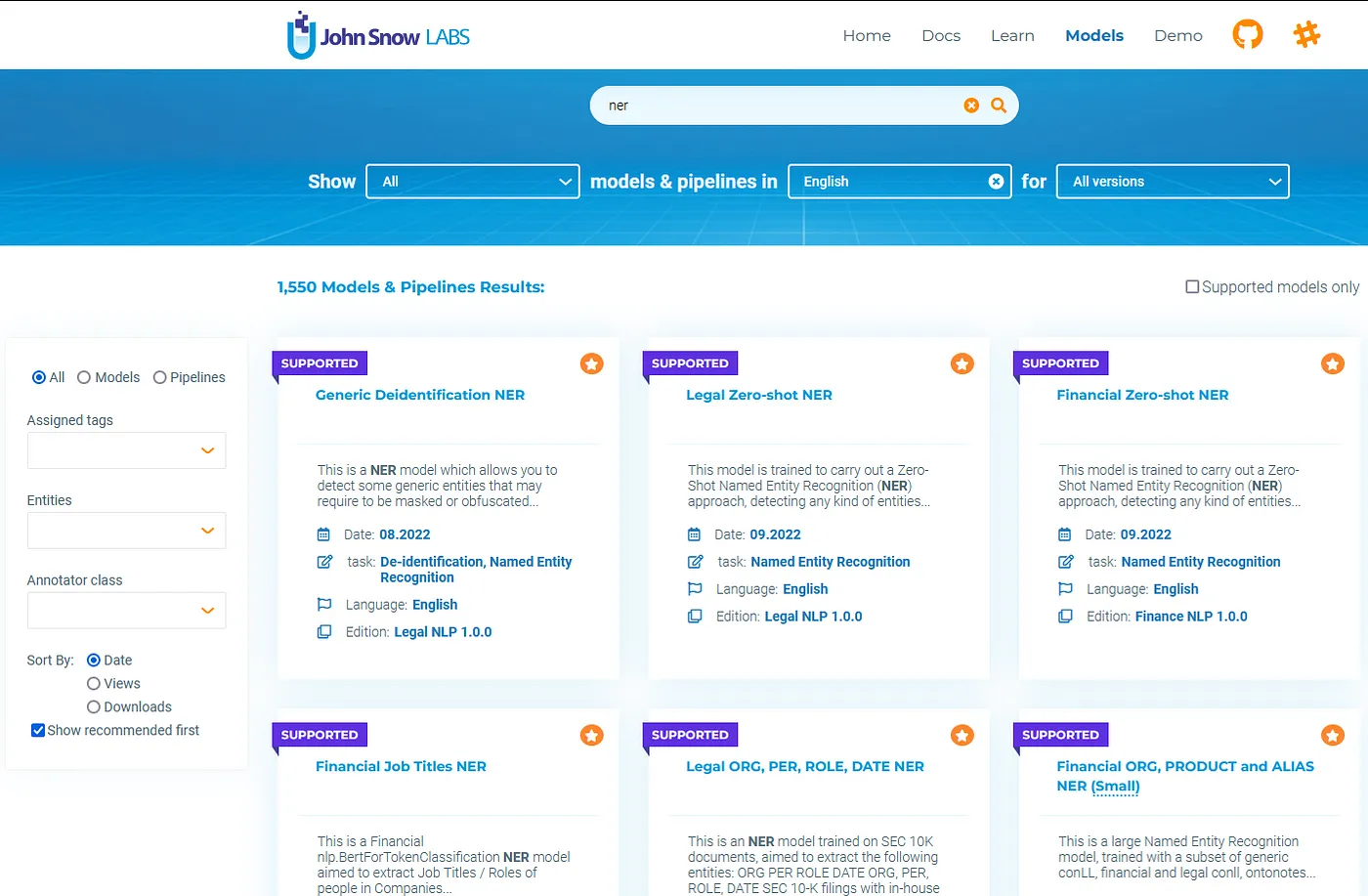
The screenshot below shows the search results for an NER model on the John Snow Labs Models Hub page:
Spark NLP has the pipeline approach and the pipeline will include the necessary stages.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, LightPipeline
from sparknlp.annotator import (
Tokenizer,
DistilBertEmbeddings,
NerDLModel,
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document = DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
# Step 2: Tokenization
token = Tokenizer()
.setInputCols("document")
.setOutputCol("token")
# Step 3: Bert Embeddings
embeddings = DistilBertEmbeddings.pretrained('distilbert_base_cased', 'en')
.setInputCols(["document", "token"])
.setOutputCol("embeddings")
# Step 4: Entity Extraction
ner_model= NerDLModel.pretrained("ner_ontonotes_distilbert_base_cased", 'en')
.setInputCols(["document", "token", "embeddings"])
.setOutputCol("ner")
# Define the pipeline
pipeline = Pipeline(stages=[document, token, embeddings, ner_model])
# Create an empty dataframe
empty_df = spark.createDataFrame([['']]).toDF("text")
# Fit the dataframe to the pipeline to get the model
pipelineModel = pipeline.fit(empty_df)
We will use the following news articles as the sample text.
sample_text = """Unions representing workers at Turner Newall say they are
'disappointed' after talks with stricken parent firm Federal Mogul.
TORONTO, Canada A second team of rocketeers competing for the #36;10 million
Ansari X Prize.
A company founded by a chemistry researcher at the University of Louisville
won a grant to develop a method of producing better peptides.
It's barely dawn when Mike Fitzpatrick starts his shift with a blur of
colorful maps, figures and endless charts, but already he knows what the day
will bring.
Southern California's smog fighting agency went after emissions of
the bovine variety Friday."""
# Convert the text to Dataframe
sample_data = spark.createDataFrame([[sample_text]]).toDF("text")
Let’s use LightPipeline here to extract the entities. LightPipeline is a Spark NLP specific Pipeline class equivalent to the Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data.
light_model = LightPipeline(pipelineModel) light_result = light_model.annotate(sample_text) list(zip(light_result['token'], light_result['ner']))

What you see above is a Python list of all the tokens of the sample_text and their corresponding entities extracted by the model. Here, B- stands for the beginning token for an extracted entity, I- stands for a token coming second or later after the beginning token and O is a label for any other entity which is not defined as an NER in that model.
In this text, Federal is labelled as B-ORG and Mogul as I-ORG, making those two tokens part of a chunk. Also, any punctuation or a value that is not extracted by the model will be labelled as O, such as ‘the’, ‘bring’, ‘will’, ‘.’, ‘,’ etc.
The next step will be using NerConverter.
NerConverter
NerConverter is used to convert the output of a NER model in Spark NLP into a format that is compatible with other downstream machine learning pipelines or applications.
NerConverter converts a IOB format (short for inside, outside, beginning) or IOB2 representation of NER to a user-friendly one, by associating the tokens of recognized entities and their label.
NerConverter expects DOCUMENT, NAMED_ENTITY and TOKEN as input, and then will provide CHUNK as output. The previous steps are expected to generate those annotator types, so that they will be used as input to NerConverter.
As you can see below, NerConverter is added as the fifth stage to the previous pipeline.
# Import NerConverter
from sparknlp.annotator import NerConverter
ner_converter = NerConverter() \
.setInputCols(["document", "token", "ner"]) \
.setOutputCol("ner_chunk")
nlpPipeline = Pipeline(
stages=[
document,
token,
embeddings,
ner_model,
ner_converter
])
# Fit the pipeline to get the model
pipelineModel = nlpPipeline.fit(sample_data)
Now, we transform the dataframe to get the entities:
result = pipelineModel.transform(sample_data)
Now, we will explode the results to get a nice dataframe of the entities. Here, chunks with no associated entity (tagged “O”) were filtered.
result.select(F.explode(F.arrays_zip(result.ner_chunk.result,
result.ner_chunk.metadata)).alias("cols")) \
.select(F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']['entity']").alias("ner_label")).show(truncate=False)
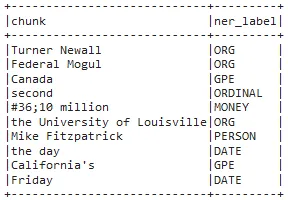
Dataframe showing only the chunks and their corresponding labels
As you can see, adding the NerConverter as the last stage helped us display only the chunks (or a combination of valuable extracted entities), not all the extracted tokens. This stage served as a filtering step and additionally, tokens labelled as B- and I- are connected to provide us the full chunk.
For example, if you do not use the NerConverter, you will get (‘Mike’, ‘B-PERSON’), (‘Fitzpatrick’, ‘I-PERSON’), but once the NerConverter stage is added, it will be possible to get Mike Fitzpatrick — PERSON, as the full chunk.
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run a named entity recognition Python model with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
ner_df = nlp.load('en.ner.debertav3_base.ontonotes').predict("""Unions representing workers at Turner Newall say they are disappointed after talks with stricken parent firm Federal Mogul.""")
ner_df[['entities_debertav3_base', 'entities_debertav3_base_class']]

After using the one-liner model, the result shows the NERs and their labels
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
NerOverwriter
Remember, we defined NerOverwriter as a component in the Spark NLP library that modifies the output of a pre-existing NER model.
The main purpose of NerOverwriter is to modify the output of a pre-existing NER model to identify and annotate additional entities or to correct false positive or false negative annotations. It does this by comparing the output of the pre-existing model to the custom rules and patterns and making the necessary modifications to the annotations.
The input for NerOverwriter have to be entities that are already extracted, type NAMED_ENTITY. The strings specified with setStopWords will have new entities assigned to, specified with setNewNerEntity.
Overall, NerOverwriter provides a flexible and customizable way to improve the accuracy of NER models in Spark NLP.
In the previous example, the model labelled the tokens from the first text as shown below.

Let’s say that, we want to change the label of the word Unions as B-ORG. NerOverwriter will be a perfect solution for this case:
from sparknlp.annotator import (
NerOverwriter
)
nerOverwriter = NerOverwriter() \
.setInputCols(["ner"]) \
.setOutputCol("ner_overwritten") \
.setNerWords(["Unions"]) \
.setNewNerEntity("B-ORG")
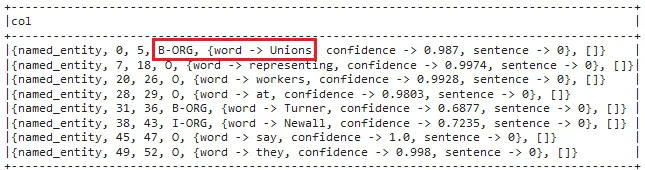
nerOverwriter.transform(result).selectExpr("explode(ner_overwritten)").show(truncate=False)
The result shows that, this time “Unions” is labelled as an Organization.
For additional information, please consult the following references:
- Documentation : NerDL, NerConverter, NerOverwriter.
- Python Docs : NerDL, NerConverter, NerOverwriter.
- Scala Docs : NerDL, NerConverter, NerOverwriter.
- For extended examples of usage, see the NerDL, NerConverter.
- For additional information, see Named Entity Recognition with BERT in Spark NLP, Text Chunking using Transformation-Based Learning.
Conclusion
In this article, we tried to get you familiar with the fundamentals of using NER models and extracting entities from unstructured texts.
NER is a crucial task in NLP that involves identifying and extracting entities such as people, places, organizations, dates, and other types of named entities from unstructured text data. NER helps in extracting relevant information from text data. For example, in news articles, named entities such as people, organizations, and locations can provide important information about the events described in the article.
NER can assist in answering questions related to specific entities. For example, if the question is about a particular location or person, NER can identify the entity and provide relevant information.
In summary, Named Entity Recognition plays a significant role in various NLP applications, enabling the extraction of useful information from text data and Spark NLP provides many solutions for this important problem.




