The potential consequences of “hallucinations” or inaccuracies generated by ChatGPT can be particularly severe in clinical settings.
Misinformation generated by LLMs could lead to incorrect diagnoses, improper treatment recommendations, or false health advice, ultimately putting patients’ lives at risk. Additionally, the propagation of human biases could exacerbate existing disparities in healthcare outcomes, further marginalising underrepresented populations.
There is an increasing concern that LLMs could potentially intensify human biases and diminish performance quality, particularly for susceptible subgroups. It is essential to explore the possibility of algorithmic underdiagnosis in clinical notes, which are a vital source of information for diagnosing and treating diseases. One of the recent studies investigated the presence of bias in two datasets — smoking and obesity — in the context of clinical phenotyping. The findings reveal that advanced language models tend to consistently underdiagnose specific vulnerable intersectional subpopulations, such as young males for smoking and middle-aged females for obesity. Implementing LLMs with these inherent biases could negatively impact clinicians’ decision-making processes, potentially leading to unequal access to healthcare. These results underscore the importance of thoroughly evaluating LLMs in a clinical setting and bring attention to the possible ethical consequences of utilizing such systems for disease diagnosis and prognosis.
Given the critical nature of clinical and biomedical applications, it is essential to address these challenges and develop strategies to mitigate the risks associated with the use of LLMs in healthcare. This may involve refining training data, incorporating expert knowledge, or developing methods to better align AI systems with human values and ethical considerations.
A recent perspective in the New England Journal of Medicine discussed the potential benefits, limits, and risks of using GPT-4, a large language model, in medicine. The authors examined the safety and usefulness of these models in answering clinical questions that arose during care delivery at Stanford Health Care. Preliminary results showed that GPT-4 and its predecessor GPT-3.5 provided safe answers 91–93% of the time, while agreeing with known answers only 21–41% of the time.
In that study, twelve clinicians across multiple specialties reviewed the responses to 64 medical questions to assess their safety and agreement with the original consultation report answers. While a significant proportion of responses were deemed safe, the agreement with known answers was found to be low. Additionally, the study highlighted the issue of high variability in responses when the same question was submitted multiple times.
Another recent experiment conducted by Dr. Josh Tamayo-Sarver, an emergency department physician, involved using ChatGPT to analyse anonymised medical narratives from patients’ history and suggesting differential diagnoses. While the AI chatbot was able to provide the correct diagnosis among its suggestions for half of the patients, it also exhibited potentially dangerous limitations.
In one instance, ChatGPT failed to consider the possibility of an ectopic pregnancy for a 21-year-old female patient, which could have resulted in fatal consequences if she had relied solely on the AI’s diagnosis. Additionally, ChatGPT struggled with atypical patient presentations and didn’t perform well when presented with imperfect information.
Dr. Tamayo-Sarver highlights that AI’s primary utility in medicine lies in processing vast amounts of patient data to offer deep insights, rather than serving as a diagnostic tool. The experiment serves as a cautionary tale, emphasizing the need for realistic expectations of AI’s current capabilities and the potential dangers of relying on AI chatbots for medical diagnoses, which can be life-threatening in some cases.
“My fear is that countless people are already using ChatGPT to medically diagnose themselves rather than see a physician. If my patient in this case had done that, ChatGPT’s response could have killed her.” ~ Dr. Tamayo-Sarver

Example of Incorrect Output by GPT-4 in clinical settings (source: Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine)
LLMs like ChatGPT sometimes generate outputs that are entirely fabricated, known as hallucinations. Complicating matters, these models often express hallucinations with a high degree of confidence, making it difficult for non-experts to discern their validity. This is especially concerning in healthcare, where incorrect diagnoses or harmful advice could have severe consequences for patients.
To address these challenges, caution must be exercised when deploying AI models in healthcare. First, AI models should be thoroughly validated using real patient data and in collaboration with healthcare professionals. Second, patients should not use these models for self-diagnosis.
Using ChatGPT through API remotely
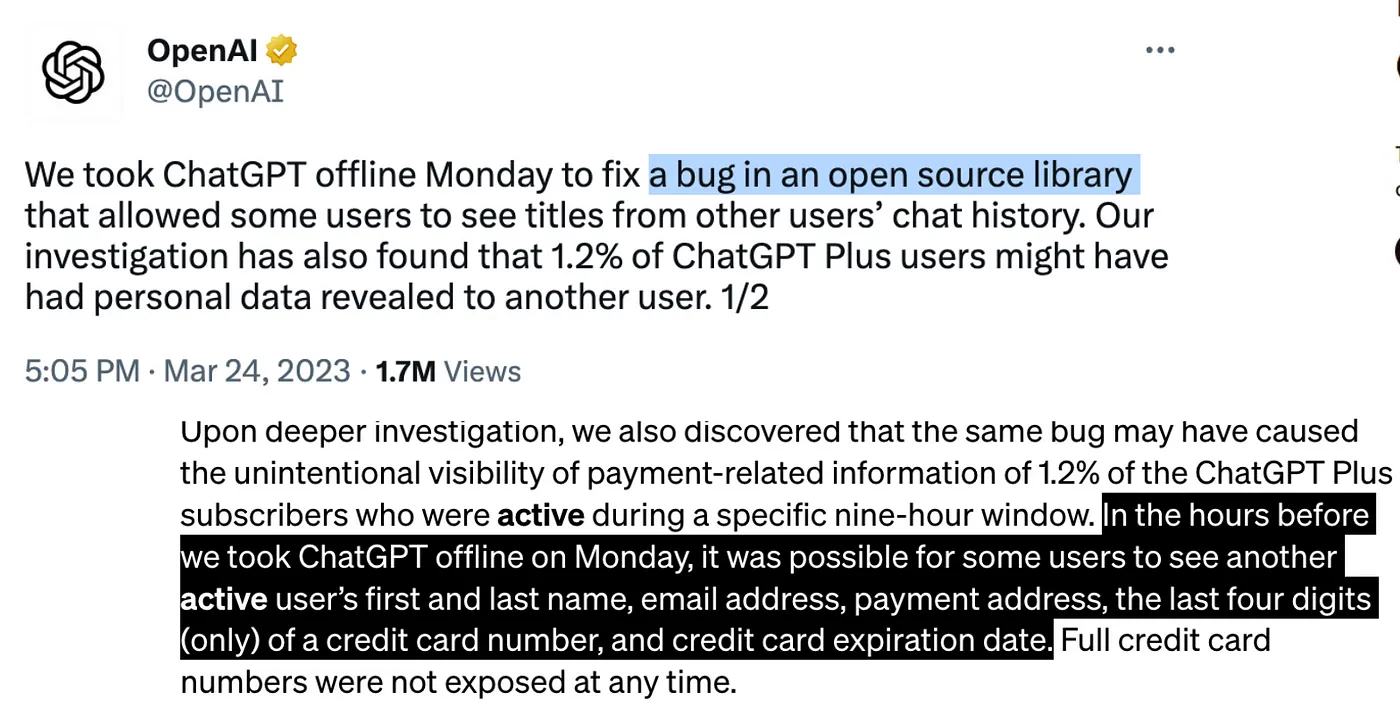
First and foremost, ChatGPT is currently not available on-premises, meaning the only way to access it is through OpenAI’s API. This exposes data to risks associated with vulnerabilities in third-party APIs and libraries. Sharing sensitive business information with AI chatbots poses considerable risks. OpenAI CEO Sam Altman acknowledged a significant ChatGPT glitch on March 22 that allowed some users to see the titles of other users’ conversations. The issue was promptly fixed, but not before revealing that 1.2% of ChatGPT Plus users may have had their personal data exposed.
https://openai.com/blog/march-20-chatgpt-outage
Further investigation uncovered that the same bug potentially exposed the payment-related information of 1.2% of active ChatGPT Plus subscribers during a specific nine-hour window. This information included users’ names, email addresses, payment addresses, and partial credit card details. The aforementioned bug is caused by third party library called Redis, that OpenAI uses to scale its services to serve millions of users. This shows that it is not just ChatGPT is only accesible by API but also it is using other dependencies that might have some vulnerabilities out of your control.
The far-reaching implications of chatbots remembering and learning from user input can be alarming. For instance, if proprietary corporate information were leaked, it could negatively impact stock prices, consumer sentiment, and client confidence. Legal leaks could even expose a company to liability.
The Samsung case serves as an example of employees accidentally sharing confidential information with ChatGPT. In three separate instances, Samsung employees unintentionally leaked sensitive data, including source code and meeting recordings. This information is now “out in the wild” for ChatGPT to feed on. Companies must also be vigilant about prompt injection attacks, which could reveal previous developer instructions or bypass programmed directives.
While it is very fast to bootstrap, you cannot fine tune ChatGPT, meaning that it won’t improve over time based on feedback from your abstractors (or the many historical documents you’ve already abstracted). This is critical in healthcare systems, where models have to be localized due to differences in clinical guidelines, writing styles, and business processes.
Last of all, these models are not regularly updated. They are typically not retrained (new versions come out instead), or retrained annually. This means that you’ll be missing new clinical terms, medications, and guidelines — with no ability to tune or train these models.
Sharing Sensitive Medical Data with ChatGPT
Using a remote API to parse sensitive medical data and personal health information (PHI) carries significant risks and implications. First and foremost, the potential exposure of private and sensitive data through vulnerabilities in third-party APIs and libraries could lead to data breaches, violating patient privacy and potentially resulting in hefty fines or legal consequences under data protection regulations, such as HIPAA or GDPR.
Moreover, medical data is often highly sensitive and should be handled with the utmost care. If unauthorised individuals were to access this information, it could lead to identity theft, insurance fraud, or discrimination based on health status. In addition, if the AI chatbot were to learn from the sensitive medical data it processes, it could inadvertently divulge confidential patient information in future interactions.
Furthermore, the use of a remote API increases the risk of data interception and tampering during transmission. Cybercriminals could potentially gain access to PHI or manipulate the data, leading to incorrect medical diagnoses, treatment plans, or other serious consequences for patients.
Lastly, using remote APIs to handle sensitive medical data could result in a loss of trust between healthcare providers and their patients. Patients may be less inclined to share vital information with their healthcare providers if they believe their data is not secure, potentially undermining the effectiveness of medical care.
In light of these risks and implications, healthcare organisations must exercise extreme caution when using remote APIs to parse sensitive medical data and PHI. Robust security measures, data encryption, and strict compliance with relevant data protection regulations are crucial to ensure the safety and privacy of patient information. One of these problem solutions is to use domain-specific medical chatbots that work on your data and have different access modes.
Is it possible to develop and deploy LLMs on-prem ?
Deploying alternatives to ChatGPT, such as Vicuna, Alpaca, and Dolly, on-premises is possible as long as their licenses permit commercial use. However, LLaMA’s current license does not allow for such use. Although these alternatives exist, it’s crucial to note that their performance may not be on par with ChatGPT, as they haven’t been as thoroughly evaluated. Companies should be aware of these limitations when considering on-premises deployment of alternative LLMs.
The performance of ChatGPT alternatives may be questionable compared to the original model, primarily because they have not undergone the same level of rigorous evaluation. While these alternatives might show promise in certain use cases, their overall effectiveness and reliability are not well-established. Companies should approach these alternatives with caution and be prepared to invest in thorough testing and evaluation to ensure they meet the desired performance standards.
Fine-tuning open source or homegrown LLMs for specific use cases is possible, but modern LLMs have billions of parameters, are trained on trillions of tokens, and can cost millions of dollars. For instance, training costs for LLaMA 65B by Meta amount to $4.05M, GPT-3 175B by OpenAI costs $4.6M, and BloombergGPT 50B totals $2.7M. These significant costs can be prohibitive for many organizations looking to develop and deploy LLMs on-premises.
As datasets and models continue to grow in size, the challenges associated with developing, deploying, and integrating LLMs into products and systems become more engineering-focused than data science-focused. Not every company can afford to maintain the unique skill set required to work with large models like ChatGPT or LLaMA in resource-limited environments. Additionally, integrating these models into larger systems to solve business problems is a complex task.
Deploying and maintaining LLMs is expensive, with costs running into thousands of dollars per month. This expense is in addition to the specialized skill sets needed to manage these models and implement guardrails effectively. Companies must consider the financial implications and the necessity of having the right expertise in-house before committing to deploying and maintaining LLMs on-premises.
Lastly, LLMs are essentially black boxes, making it difficult to control or intervene in their output. As a result, it is challenging to change their outcomes easily. Due to issues like hallucination, human intervention is still needed for fact-checking. While the goal may be to remove humans from the loop through automation, the reality is that humans are still required in the loop to ensure the veracity of the outcomes produced by LLMs.