
























































Rule-based sentiment analysis in Natural Language Processing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.

Sentiment analysis is an automated process capable of understanding the feelings or opinions that underlie a text. This process is considered as text classification and it is also one of the most interesting subfields of NLP.
Sentiment analysis studies the subjective information in an expression, that is, opinions, appraisals, emotions, or attitudes towards a topic, person or entity. Expressions can be classified as positive, negative, or neutral — in some cases, even much more detailed.
Some popular sentiment analysis applications include social media monitoring, customer support management, and analyzing customer feedback.
You can see the differences between the rule-based approach and Machine Learning (ML) approach in the figure below.
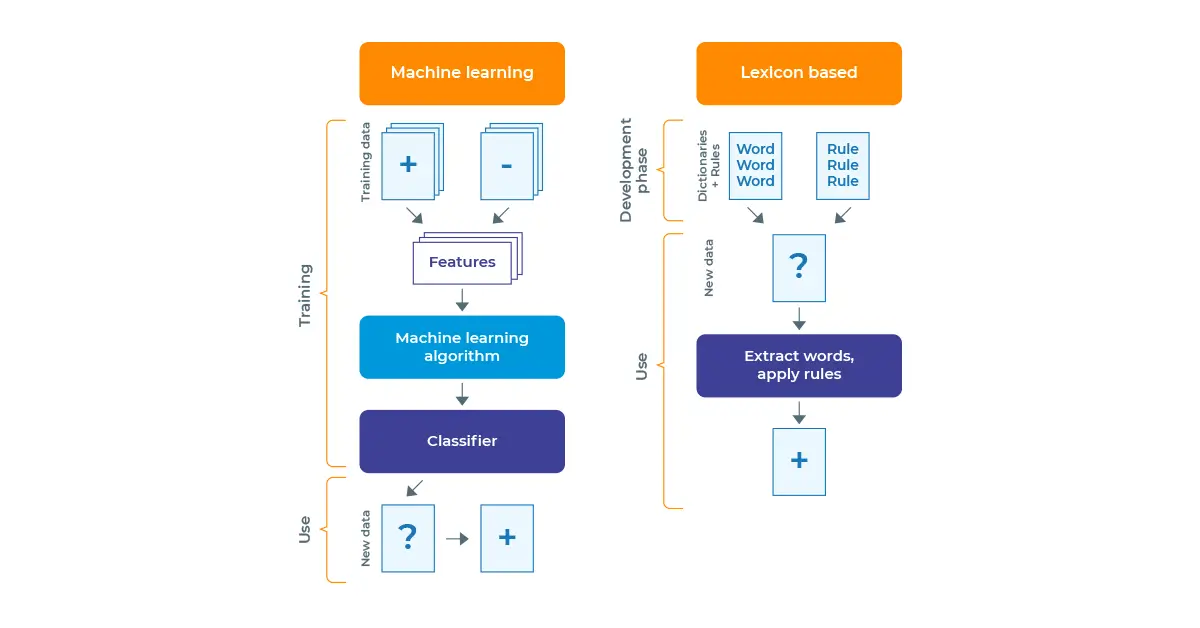
Difference between rule-based and machine learning based sentiment analysis applications
In this post, you will learn how to use Spark NLP to perform sentiment analysis using a rule-based approach.
Spark NLP also provides Machine Learning (ML) and Deep Learning (DL) solutions for sentiment analysis. If you are interested in those approaches for sentiment analysis, please check ViveknSentiment and SentimentDL annotators of Spark NLP.
Let us start with a short Spark NLP introduction and then discuss the details of those sentiment analysis techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
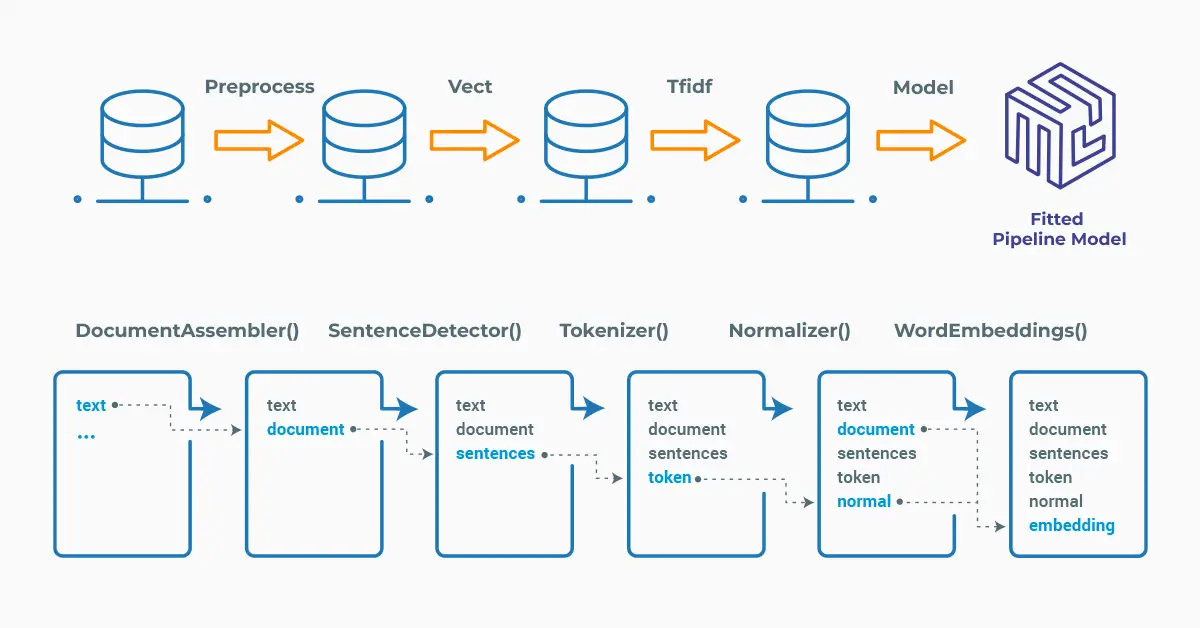
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Rule-based Approach vs ML/DL Models
In sentiment analysis, a rule-based approach involves defining a set of rules or patterns based on specific linguistic or domain knowledge. For example, a rule-based system for sentiment analysis might use rules such as “if a text contains positive adjectives, it is likely to be positive” or “if a text contains negative adjectives and an exclamation mark, it is likely to be strongly negative.”
In contrast, ML models for text classification learn to classify text based on patterns in the data. These models are trained on labeled examples, where each example consists of a text and a corresponding label. During training, the model learns to identify patterns in the text that are associated with each label.
On the other hand, DL models for text classification use neural networks to learn representations of the text and classify it into one or more categories. These models can automatically learn high-level features from the raw text and capture complex patterns in the data. For example, a DL model for sentiment analysis might learn to represent a text as a vector of word embeddings and use a neural network to classify it as positive, negative or neutral.
Rule-based systems can be more interpretable, since the rules are explicitly defined, and can be more effective in cases where there is a clear set of rules that can be used to define the classification task. However, rule-based systems can be less flexible and less effective when dealing with complex patterns in the data. In contrast, ML and DL models can be more effective at capturing complex patterns in the data but may be less interpretable and require more data to be trained effectively.
Another difference is that DL models often require a large amount of data to train effectively, while rule-based systems can be developed with smaller amounts of data. Additionally, DL models may require more computational resources and can be more challenging to set up and optimize compared to rule-based systems.
Trends in Healthcare NLP
Beyond these traditional distinctions, NLP in healthcare is rapidly evolving with new methods and use cases.
Recent advancements in healthcare NLP are increasingly focused on multimodal integration, where text is analyzed in combination with other data types such as medical images, voice recordings, and genomic data. This shift allows sentiment analysis to go beyond patient feedback forms or clinical notes, capturing insights from diverse information streams that reflect a patient’s full health journey. By embedding sentiment understanding into multimodal pipelines, healthcare providers can achieve more holistic assessments of patient well-being and treatment responses.
Another important trend is the adoption of large medical language models fine-tuned for healthcare contexts. Specialized LLMs trained on clinical guidelines, EHR data, and biomedical literature have demonstrated significant improvements in handling domain-specific sentiment nuances, such as distinguishing between clinical concern and patient anxiety. When combined with Spark NLP pipelines, these models enable more accurate interpretation of complex medical expressions, ensuring that healthcare sentiment analysis supports both clinical decision-making and patient-centered care.
Finally, recent findings highlight the growing role of real-time sentiment monitoring in healthcare operations. Hospitals and research institutions have begun implementing continuous analysis of patient communications, telemedicine sessions, and clinical trial reports. This approach allows early detection of negative sentiment trends, such as patient dissatisfaction or safety concerns, and provides actionable insights to clinicians and administrators. Integrating sentiment analysis into live workflows ensures that care teams can intervene promptly, improving both patient trust and overall health outcomes.
Sentiment Detector
SentimentDetector is an annotator in Spark NLP and it uses a rule-based approach. The logic here is a practical approach to analyzing text without training or using machine learning models. In the case discussed below, result of this approach is a set of rules based on which the text is labeled as (Positive / Negative / Neutral), but in some cases the result may be much simpler as either positive or negative.
A dictionary of predefined sentiment keywords must be provided with the parameter setDictionary, where each line is a word delimited to its class (either positive or negative). The dictionary can be set either in the form of a delimited text file or directly as an External Resource.
By default, the sentiment score will be assigned labels “positive” if the score is >= 0, else “negative”. To retrieve the raw sentiment scores, setEnableScore needs to be set to true.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
The Sentiment Detector annotator expects DOCUMENT and TOKEN as input, and then will provide SENTIMENT as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
Start by loading the Dataset, Lemmas and the Sentiment Dictionary.
! wget -N https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/lemma-corpus-small/lemmas_small.txt -P /tmp ! wget -N https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sentiment-corpus/default-sentiment-dict.txt -P /tmp
Once you download the Lemmas and the Sentiment Dictionary, they will be saved in the /tmp/ folder of the Colab notebook. You can see the first few lines below:
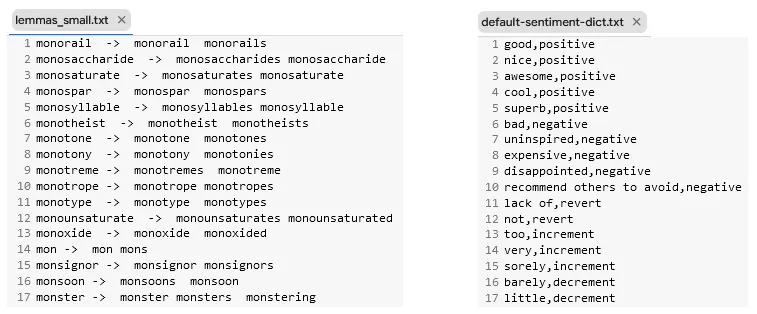
First few lines of the lemmas and sentiment dictionary
There are more than one options for the dataset. You can write a sentence or a few sentences and then convert them to a spark dataframe and then get the sentiment prediction, or you can get the sentiment analysis of a huge dataframe. There are examples below for both options.
Spark NLP has the pipeline approach and the pipeline will include the necessary stages.
Please notice that Lemmatizer is added to the pipeline as the fourth stage and the target was to find lemmas out of words with the objective of returning a base dictionary word.
SentimentDetector is the fifth stage in the pipeline and notice that default-sentiment-dict.txt was defined as the reference dictionary.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, Finisher
from sparknlp.annotator import (
SentenceDetector,
Tokenizer,
Lemmatizer,
SentimentDetector
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Sentence Detection
sentence_detector = SentenceDetector().setInputCols(["document"]).setOutputCol("sentence")
# Step 3: Tokenization
tokenizer = Tokenizer().setInputCols(["sentence"]).setOutputCol("token")
# Step 4: Lemmatization
lemmatizer= Lemmatizer().setInputCols("token").setOutputCol("lemma")
.setDictionary("lemmas_small.txt", key_delimiter="->", value_delimiter="\t")
# Step 5: Sentiment Detection
sentiment_detector= (
SentimentDetector()
.setInputCols(["lemma", "sentence"])
.setOutputCol("sentiment_score")
.setDictionary("default-sentiment-dict.txt", ",")
)
# Step 6: Finisher
finisher= (
Finisher()
.setInputCols(["sentiment_score"]).setOutputCols("sentiment")
)
# Define the pipeline
pipeline = Pipeline(
stages=[
document_assembler,
sentence_detector,
tokenizer,
lemmatizer,
sentiment_detector,
finisher
]
)
As usual in Spark ML, we need to fit the pipeline to make predictions (see this documentation page if you are not familiar with Spark ML).
# Create a spark Data Frame with an example sentence
data = spark.createDataFrame(
[
[
"The restaurant staff is really nice"
]
]
).toDF("text") # use the column name `text` defined in the pipeline as input
# Fit-transform to get predictions
result = pipeline.fit(data).transform(data).show(truncate = 50)
The predicted sentiment will be displayed as a dataframe:

Let’s try another example, this time with a negative sentiment:
# Create a spark Data Frame with an example sentence
data = spark.createDataFrame(
[
[
"I recommend others to avoid because it is too expensive"
]
]
).toDF("text") # use the column name `text` defined in the pipeline as input
# Fit-transform to get predictions
result = pipeline.fit(data).transform(data).show(truncate = 50)
And the prediction is:

Applying on a Dataframe
This time, we may get sentiment predictions on an entire dataframe in order to check the efficiency of the model.
We will download a dataset from John Snow Labs AWS S3:
!wget -q aclimdb_test.csv https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sentiment-corpus/aclimdb/aclimdb_test.csv
testDataset = spark.read \
.option("header", True) \
.csv("aclimdb_test.csv")
testDataset.show(truncate = 100)
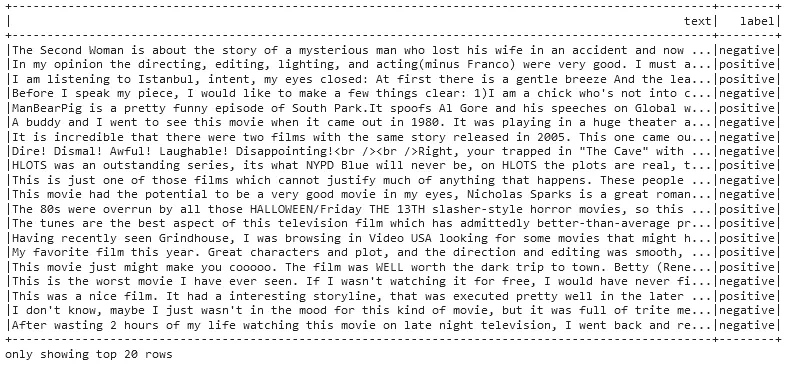
Test dataset, columns showing the text and the labels
Remember, our model is already in memory, so we can get predictions from that model for the whole 25,000 rows.
sentiment_detector = SentimentDetector() \
.setInputCols(["lemma", "sentence"]) \
.setOutputCol("sentiment_score") \
.setDictionary("/tmp/default-sentiment-dict.txt", ",")
pipeline = Pipeline(stages = [document_assembler,
sentence_detector,
tokenizer,
lemmatizer,
sentiment_detector,
finisher])
empty_df = spark.createDataFrame([['']]).toDF("text")
pipelineModel = pipeline.fit(empty_df)
We used a sentiment corpus with 25,000 rows of labelled data and measured the time for getting the result.
%%time
pipelineModel.transform(testDataset).select('text','label',"sentiment.result").show(6)
Prediction was very quick

The dataframe shows the text, label (ground truth) and predicted sentiment columns
For additional information, please consult the following references.
- Documentation: SentimentDetector
- Python Docs : SentimentDetector
- Scala Docs: SentimentDetector
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
In this post, we tried to get you familiar with the basics of the rule_based SentimentDetector annotator of Spark NLP. Rule-based sentiment analysis is a type of NLP technique that uses a set of rules to identify sentiment in text. This system uses a set of predefined rules to identify patterns in text and assign sentiment labels to it, such as positive, negative, or neutral.
Spark NLP provides ML and DL solutions, but those are discussed in another medium blog post.
Deciding between a rule-based, ML or DL approach in NLP depends on several factors, including the specific problem being addressed, the amount and quality of available data, and the level of interpretability required for the solution.
A rule-based approach is useful when the problem is well-defined and can be modeled using a set of explicit rules. This approach can be used when the linguistic or domain knowledge required to define the rules is well-established, and the amount of available data is limited. Additionally, rule-based approaches can be more transparent and interpretable than ML or DL models since the rules are explicitly defined.
FAQ
What is the main advantage of using a rule-based sentiment analysis approach in Spark NLP?
Rule-based sentiment analysis provides transparency and interpretability, since the rules are explicitly defined. This makes it easier to audit, customize for specific domains, and apply even when large labeled datasets are not available.
Can rule-based sentiment analysis be combined with machine learning or deep learning models?
Yes. Many modern pipelines use hybrid approaches where rules handle domain-specific patterns and machine learning models capture more complex relationships. Spark NLP supports seamless integration of rule-based annotators with ML and DL models in a single pipeline.
How is healthcare sentiment analysis evolving with Spark NLP and recent NLP trends?
Healthcare projects increasingly use multimodal pipelines, domain-specific large language models, and real-time monitoring. Spark NLP enables these advances by allowing integration of text with other data sources, improving interpretation of nuanced medical language, and supporting live patient feedback analysis.
What are the performance benefits of Spark NLP for sentiment analysis?
Spark NLP is optimized for scalability and speed. It can process very large datasets, millions of documents, in distributed environments with low latency. This makes it suitable for enterprise and healthcare use cases that require continuous monitoring.
Do I need large amounts of training data to use Spark NLP for sentiment analysis?
Not necessarily. With rule-based approaches, you can start with a sentiment dictionary or domain lexicon without labeled data. Pretrained models are also available in Spark NLP for ML and DL sentiment analysis, reducing the need to collect and annotate data from scratch.




