The latest major release merges 50 pull requests, improving accuracy and ease and use
Release Highlights
When we first introduced the natural language processing library for Apache Spark 18 months ago, we knew there was a long roadmap ahead of us. New releases came out every two weeks on average since then – but none has been bigger than Spark NLP 2.0.
We have no less than 50 Pull Requests merged this time. Most importantly, we become the first library to have a production-ready implementation of BERT embeddings. Along with this interesting deep learning and context-based embeddings algorithm, here are the biggest news of this release:
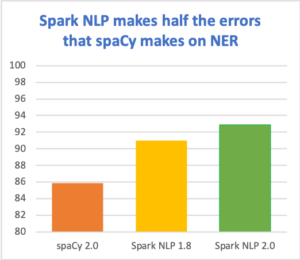
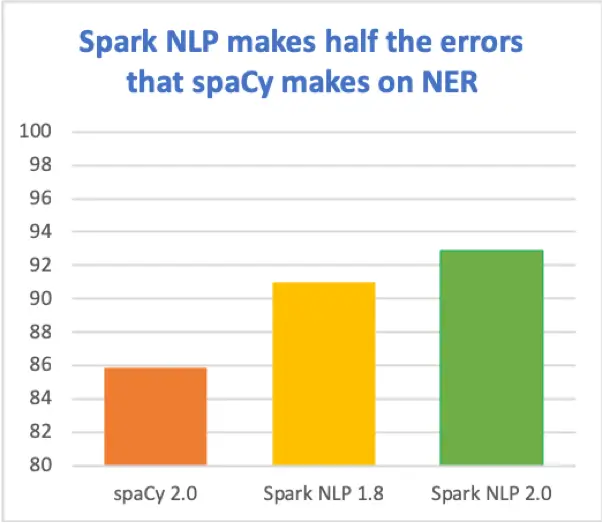
- Revamped and enhanced Named Entity Recognition (NER) Deep Learning models to a new state of the art level, reaching up to 93% F1 micro-averaged accuracy in the industry standard.
- Word Embeddings as well as Bert Embeddings are now annotators, just like any other component in the library. This means, embeddings can be cached on memory through DataFrames, can be saved on disk and shared as part of pipelines!
- We upgraded the TensorFlow version and also started using contrib LSTM Cells.
- Performance and memory usage improvements also tag along by improving serialization throughput of Deep Learning annotators by receiving feedback from Apache Spark contributor Davies Liu.
- Revamping and expanding our pre-trained pipelines list, plus the addition of new pre-trained models for different languages together with tons of new example notebooks, which include changes that aim the library to be easier to use. API overall was modified towards helping newcomers get started.
- OCR module received a suite of improvements that increase accuracy.
All of this comes together with a full range of bug fixes and annotator improvements, follow up the details below!
New Features
- BertEmbeddings annotator, with four google ready models ready to be used through Spark NLP as part of your pipelines, includes Wordpiece tokenization.
- WordEmbeddings, our previous embeddings system is now an Annotator to be serialized along Spark ML pipelines
- Created training helper functions that create spark datasets from files, such as CoNLL and POS tagging
- NER DL has been revamped by using contrib LSTM Cells. Added library handling for different OS.
Enhancements
- OCR improved the handling of images by adding binarizing of buffered segments
- OCR now allows automatic adaptive scaling
- SentenceDetector params merged between DL and Rule based annotators
- SentenceDetector max length has been disabled by default, and now truncates by whitespace
- Part of Speech, NER, Spell Checking, and Vivekn Sentiment Analysis annotators now train from dataset passed to fit() using Spark in the process
- Tokens and Chunks now hold metadata information regarding which sentence they belong to by sentence ID
- AnnotatorApproach annotators now allow a param trainingCols allowing them to use different inputs in training and in prediction. Improves Pipeline versatility.
- LightPipelines now allow method transform() to call against a DataFrame
- Noticeable performance gains by improving serialization performance in annotators through the removal of transient variables
- Spark NLP in 30 seconds now provides a function SparkNLP.start() and sparknlp.start() (python) that automatically creates a local Spark session.
- Improved DateMatcher accuracy
- Improved Normalizer annotator by supporting and tokenizing a slang dictionary, with case sensitivity matching option
- ContextSpellChecker now is capable of handling multiple sentences in a row
- Pre-trained Pipeline feature now allows handling John Snow Labs remote pre-trained pipelines to make it easy to update and access new models
- Symmetric Delete spell checking model improved training performance
Models and Pipelines
- Added more than 15 pre-trained pipelines that cover a huge range of use cases. To be documented
- Improved multi-language support by adding French and Italian pipelines and models. More to come!
- Dependency Parser annotators now include a pre-trained English model based on CoNLL-U 2009
Bugfixes
- Fixed python class name reference when deserializing pipelines
- Fixed serialization in ContextSpellChecker
- Fixed a bug in LightPipeline causing not to include output from embedded pipelines in a PipelineModel
- Fixed DateMatcher wrong param name not allowing to access it properly
- Fixed a bug where DateMatcher didn’t know how to handle dash in dates where the year had two digits instead of four
- Fixed a ContextSpellChecker bug that prevented it from being used repeatedly with collections in LightPipeline
- Fixed a bug in OCR that made it blow up with some image formats when using text preferred method
- Fixed a bug on OCR which made params not to work in cluster mode
- Fixed OCR setSplitPages and setSplitRegions to work properly if tesseract detected multiple regions
Developer API
- AnnotatorType params renamed to inputAnnotatorTypes and outputAnnotatorTypes
- Embeddings now serialize along a FloatArray in Annotation class
- Disabled useFeatureBroadcasting, showed better performance number when training large models in annotators that use Features
- OCR must be instantiated
- OCR works best with 4.0.0-beta.1
Build and release
- Added GPU build with tensorflow-gpu to Maven coordinates
- Removed .jar file from pip package
Now it’s your turn!
Ready to start? Go to the Spark NLP Homepage for the quick start guide, documentation, and samples.
Got questions? The homepage has a big blue button that invites you to join the Slack NLP Slack Channel. Us and the rest of the community are there every day to help you succeed. Looking to contribute? Start by reading the open issues and see what you can help with. There’s always more to do – we’re just getting started!
The latest advancements in natural language processing, including improved embeddings, pre-trained pipelines, and enhanced accuracy for NER and OCR, are paving the way for innovative applications in healthcare. By incorporating Generative AI in Healthcare and utilizing a Healthcare Chatbot, organizations can further enhance patient engagement, streamline processes, and provide more accurate and timely care solutions.