



























































Machine Learning (ML) has seen exponential growth in recent years. With an increasing number of models being developed, there’s a growing need for transparent, systematic, and comprehensive tracking of these models. Enter MLFlow and LangTest: two tools that, when combined, create a revolutionary approach to ML development.
MLFlow is designed to streamline the machine learning lifecycle, managing everything from experimentation and reproducibility to deployment. By providing an organized framework for logging and versioning, MLFlow Tracking helps teams ensure their models are developed and deployed with transparency and precision.
On the other hand, LangTest has emerged as a transformative force in the realm of Natural Language Processing (NLP) and Large Language Model (LLM) evaluation. Pioneering the path for advancements in this domain, LangTest is an open-source Python toolkit dedicated to rigorously evaluating the multifaceted aspects of AI models, especially as they merge with real-world applications. The toolkit sheds light on a model’s robustness, bias, accuracy, toxicity, fairness, efficiency, clinical relevance, security, disinformation, political biases, and more. The library’s core emphasis is on depth, automation, and adaptability, ensuring that any system integrated into real-world scenarios is beyond reproach.
What makes LangTest especially unique is its approach to testing:
- Smart Test Case Generation: Rather than relying on fixed benchmarks, it crafts customized evaluation scenarios tailored for each model and dataset. This method captures model behavior nuances, ensuring more accurate assessments.

- Comprehensive Testing Range: LangTest boasts a plethora of tests, spanning from robustness checks and bias evaluations to toxicity analyses and efficiency tests, ensuring models are both accurate and ethical.

- Automated Data Augmentation:Beyond mere evaluation, LangTest employs data augmentation techniques to actively enhance model training, responding dynamically to the changing data landscape.

- MLOps Integration:Fitting seamlessly into automated MLOps workflows, LangTest ensures models maintain reliability over time by facilitating automated regression testing for updated versions.
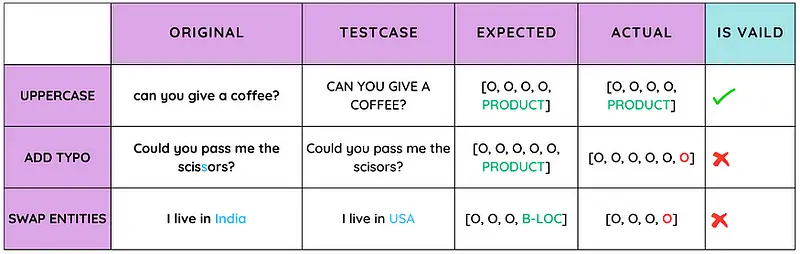

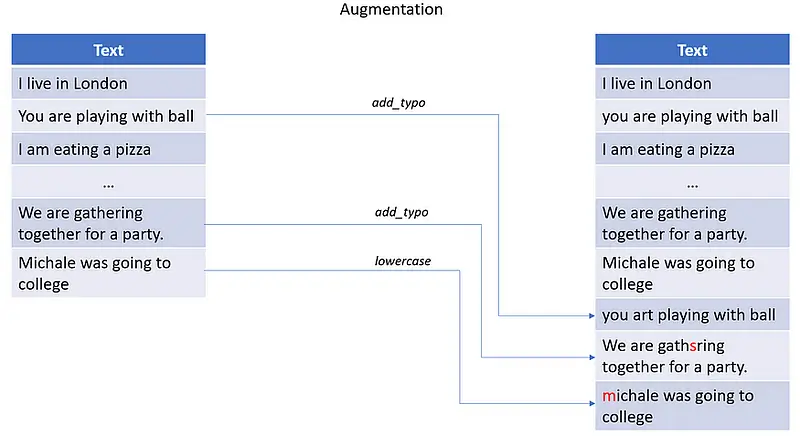

LangTest has already made waves in the AI community, showcasing its efficacy in identifying and resolving significant Responsible AI challenges. With support for numerous language model providers and a vast array of tests, it is poised to be an invaluable asset for any AI team.
Why Integrate MLFlow Tracking with LangTest?
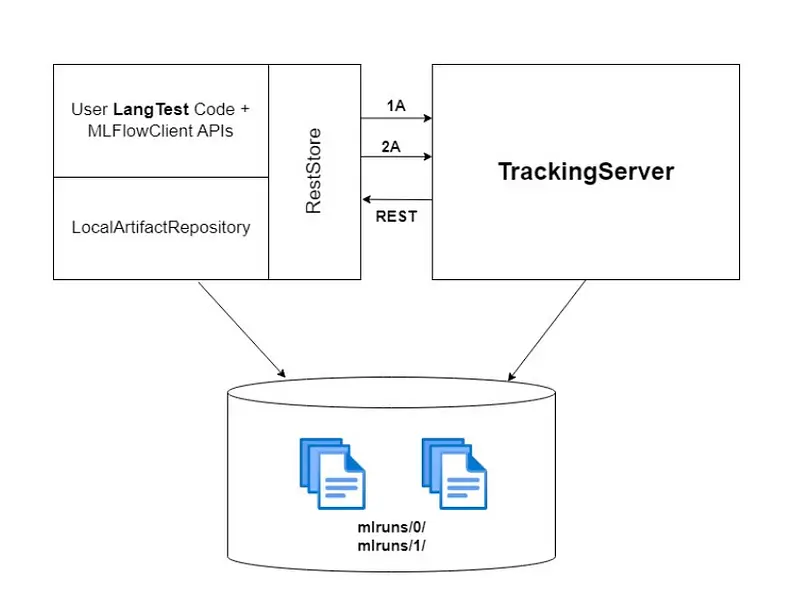
The combination of MLFlow tracking and LangTest in the model development process revolutionizes how we approach machine learning, making it more transparent, insightful, and efficient. By seamlessly merging LangTest’s advanced evaluation dimensions with MLFlow’s tracking capabilities, we create a comprehensive framework that not only evaluates models based on accuracy but also thoroughly documents every run’s metrics and insights. This powerful synergy equips developers and researchers to spot historical trends, make informed decisions, compare model variations, troubleshoot problems effectively, encourage collaboration, ensure accountability, and continually improve models. This integration promotes a disciplined, data-driven approach, fostering the creation of AI systems that are more dependable, fair, and optimized while facilitating transparent communication with stakeholders. In essence, the integration of MLFlow tracking and LangTest represents an advanced model development approach that goes beyond conventional boundaries, ultimately delivering technically proficient and ethically sound models.
The integration of MLFlow Tracking and LangTest is akin to merging a powerful engine (MLFlow) with an advanced navigational system (LangTest). This synergy achieves the following:
- Transparency: Every run, metric, and insight is documented.
- Efficiency: Developers can spot historical trends, troubleshoot issues, and compare model variations effortlessly.
- Collaboration: Transparent documentation fosters better teamwork and knowledge sharing.
- Accountability: Every change, test, and result is logged for future reference.
Simply put, MLFlow’s advanced tracking meshes perfectly with LangTest’s evaluation metrics, ensuring models are not only accurate but also ethically and technically sound.
How Does It Work?
The below code provides a quick and streamlined way to evaluate a named entity recognition model using the langtest library.
1. Installation:
!pip install langtest[transformers]
This line installs the `langtest` library and specifically includes the additional dependencies required for using it with the `transformers` library. The `transformers` library by Hugging Face offers a multitude of pretrained models, including those for natural language processing tasks.
2. Import and Initialization:
from langtest import Harness
h = Harness(task='ner', model={"model":'dslim/bert-base-NER',
"hub":'huggingface'})
First, the Harness class from the langtest library is imported. Then, a `Harness` object is initialized with specific parameters. The `task` parameter is set to `ner`, indicating that the objective is Named Entity Recognition (NER). The `model` parameter specifies which model to use, with `dslim/bert-base-NER` being the selected pretrained model from Hugging Face’s model hub.
3. Test Generation and Execution:
h.generate().run()
The `generate()` method of the `Harness` object creates a set of test cases appropriate for the NER task and the selected model. The `run()` method then executes these test cases, evaluating the model’s performance on them.
With the mlflow_tracking=True flag, MLFlow’s tracking feature springs into action. It’s as easy as:
h.report(mlflow_tracking=True) !mlflow ui
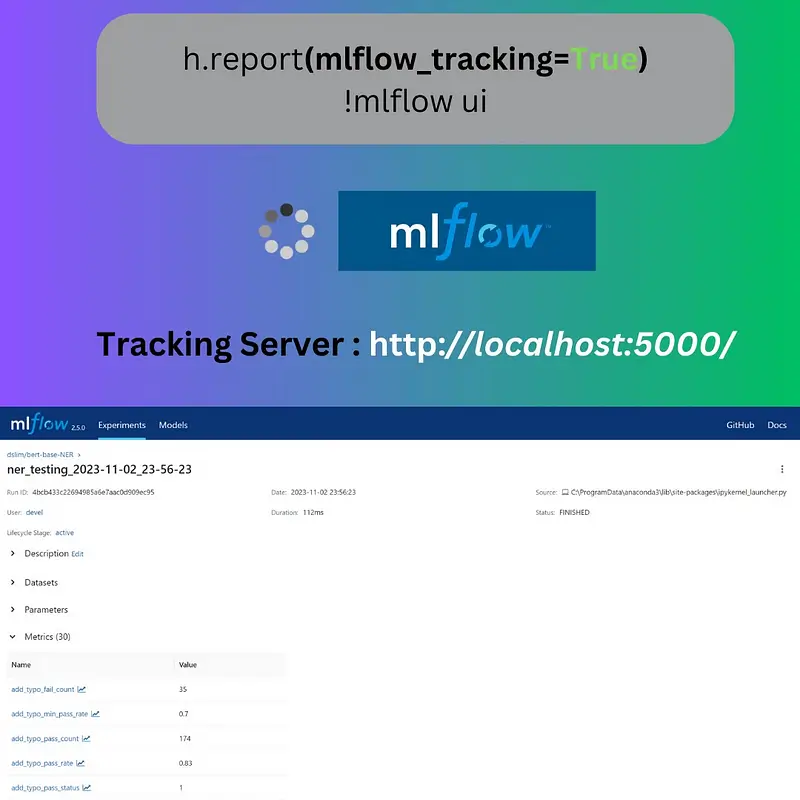
What Happens Behind the Scenes?
- Initiation: Setting
mlflow_tracking=Trueinthe report method propels you to a locally hosted MLFlow tracking server. - Representation: Each model run is depicted as an “experiment” on this server. Each experiment is uniquely named after the model and stamped with the date and time.
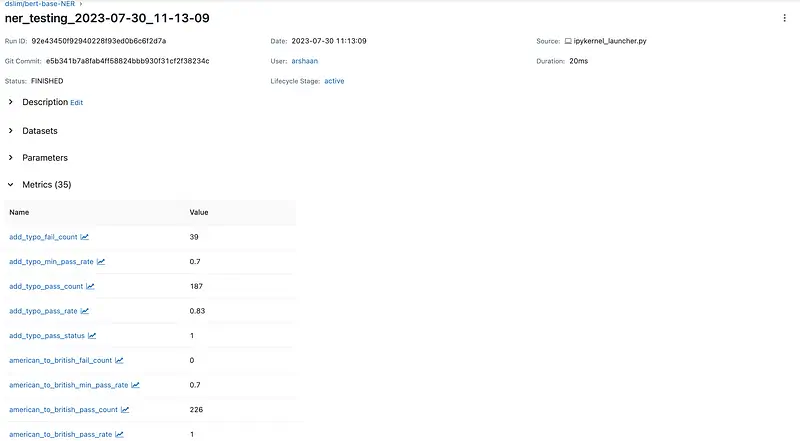
- Detailed Logging: Want to dive into a specific run’s metrics? Just select its name. You’re then taken to a detailed metrics section housing all the relevant data.
- Historical Data: If you rerun a model (with the same or different configurations), MLFlow logs it distinctly. This way, you get a snapshot of your model’s behavior for every unique run.
- Comparisons:With the ‘compare’ section, drawing comparisons across various runs is a cinch.
If you want to review the metrics and logs of a specific run, you simply select the associated run-name. This will guide you to the metrics section, where all logged details for that run are stored. This system provides an organized and streamlined way to keep track of each model’s performance during its different runs.
The tracking server looks like this with experiments and run-names specified in the following manner:
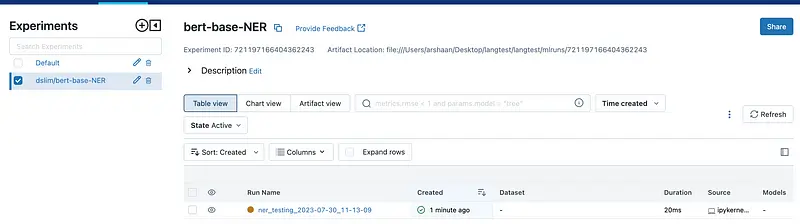
To check the metrics, select the run-name and go to the metrics section.
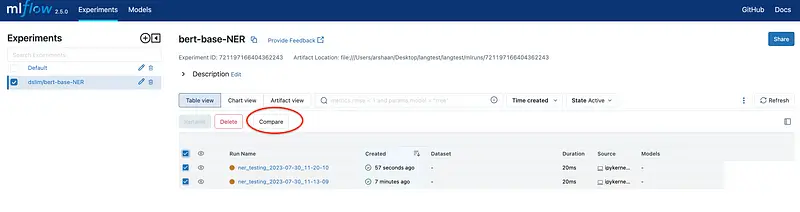
If you decide to run the same model again, whether with the same or different test configurations, MLflow will log this as a distinct entry in its tracking system.
Each of these entries captures the specific state of your model at the time of the run, including the chosen parameters, the model’s performance metrics, and more. This means that for every run, you get a comprehensive snapshot of your model’s behavior under those particular conditions.
You can then use the compare section to get a detailed comparison for the different runs.
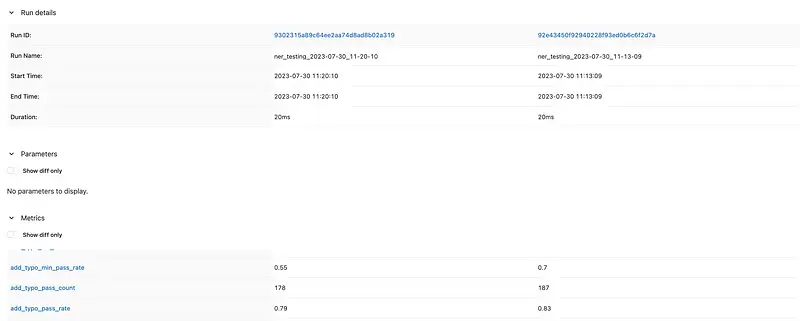
Thus, MLflow acts as your tracking system, recording the details of each run, and providing a historical context to the evolution and performance of your model. This capability is instrumental in maintaining a disciplined and data-driven approach to improving machine learning models.
In Conclusion
The alliance of MLFlow Tracking and LangTest elevates the traditional model development process, making it more disciplined, data-driven, and transparent. Whether you’re a seasoned ML developer or just starting, this combination equips you with the tools needed to create robust, efficient, and ethical AI systems. So, next time you’re about to embark on an ML project, remember to harness the power of MLFlow and LangTest for an optimized development journey.




