A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
Support Training with large documents
For training a model, the memory requirement grows as the number of tasks increases in the project. The required memory is higher for projects with 100s of pages per document. For handling large volumes of training data, Annotation Lab 3.1.0 integrates a Spark NLP feature called Memory Optimization Approach. When this approach is chosen, the training jobs are successful even on machine with lower memory resources than the minimum required, with the expense of time it takes to complete.
This feature is automatically enabled when the training data is greater then 5MB. The training log can be monitored to check if this feature is enabled. (as shown in below image)
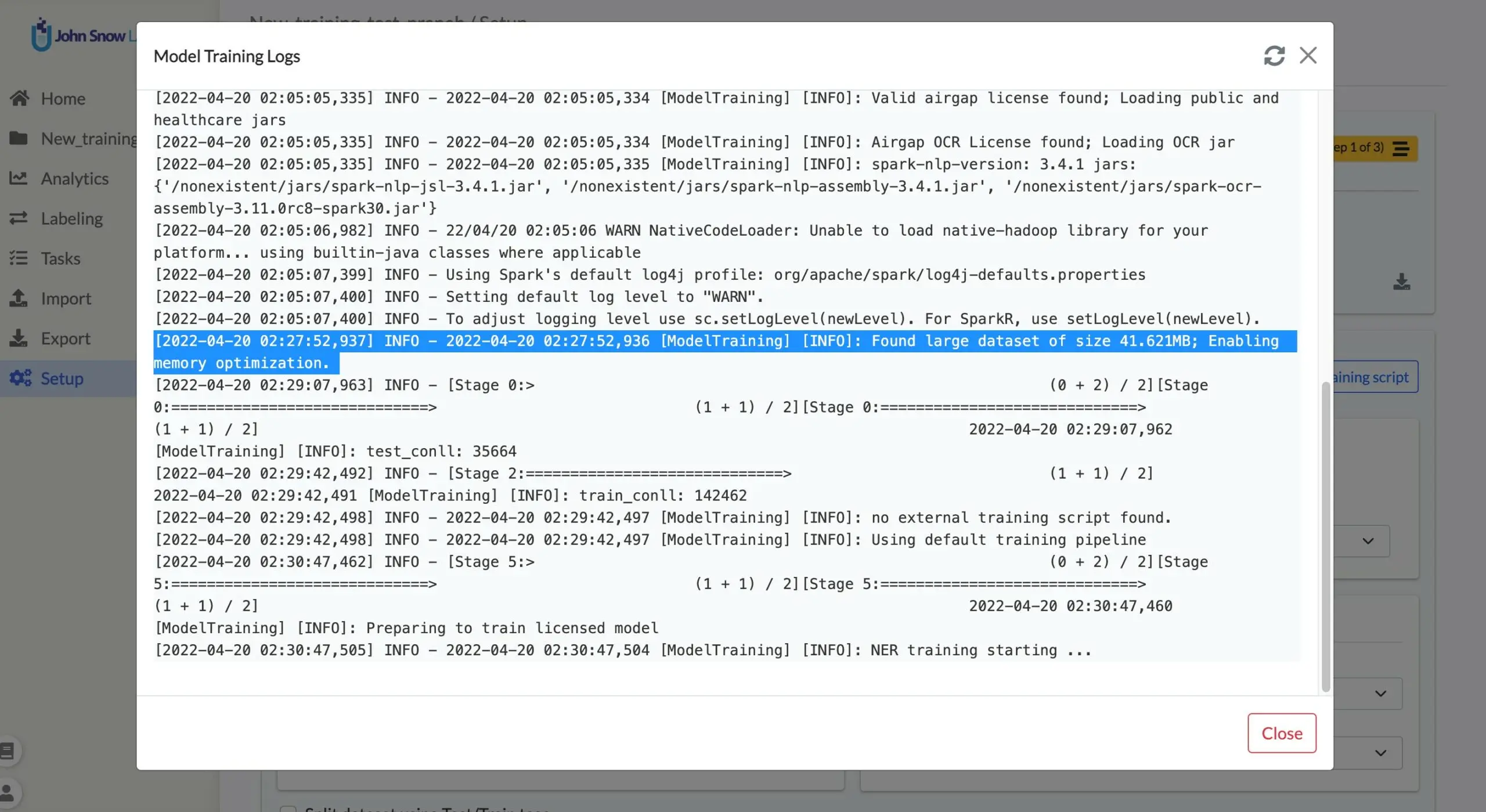
Note: If batch size is too high, the training may fail with memory issue. In that case reducing it to a lower value may help.
Improvements in Visual NER Projects
Visual NER task title set is supplied along with image url
When importing Visual NER tasks using URLs defined in a JSON input file, Annotation Lab uses the provided URLs as task titles. Going forward, users can provide title in the input JSON along with the URL for tasks to import. This sets the title of the task accordingly.
{"image": "<a href="https://url-to-image.png/">https://url-to-image.png</a>", "title": "Demo Image Title"}
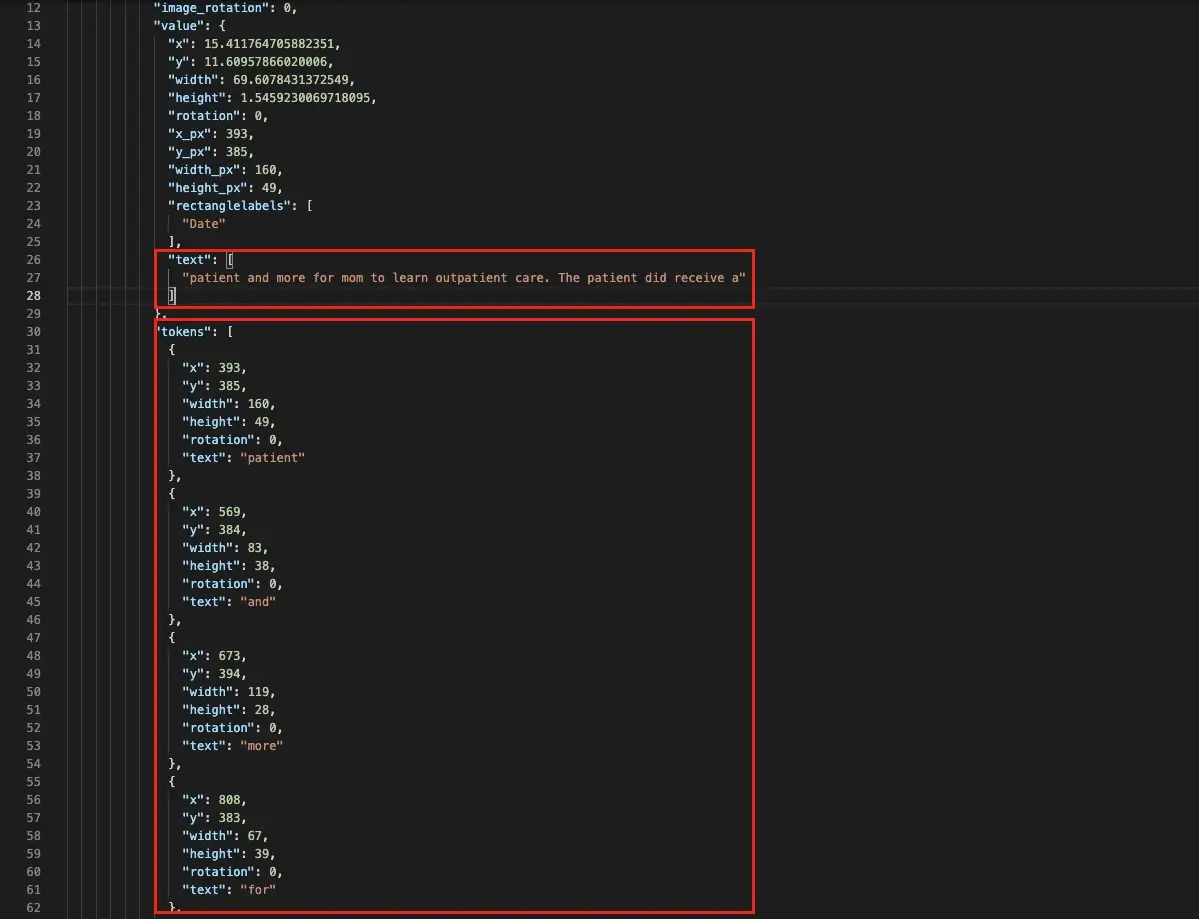
Token-level annotation in the JSON export
The JSON export for the Visual NER projects contains both chunk and token-level annotations. This is useful for preparing training data for Spark OCR visual models.
Importing Sample Task in Visual NER
Sample tasks can be imported into the Visual NER project using any available OCR server (created by another project).
Cross-line annotation
Multi-chunk annotation can be done without changing the start token when the end token is the last word on the document.

Visual NER export in Pascal VOC format
For Visual NER project, users can export tasks in the VOC format for multi-page tasks with/without completions.
Restoring database and files
During restoring backup file in the previous versions, the SECRETS (kubernetes) of the old machine needed manual transfer to the target machine. With v3.1.0, all the SECRETS are backed-up automatically along with database backup and hence they are restored without any hassle.
To restore Annotation Lab from backup a new clear installation of Annotation Lab is required. It can be done using the script annotationlab-install.sh shipped with installation artifacts. Then move the latest backup from S3 bucket and unzip them in the restore/database/ directory. Next go to the restore/database/ directory and execute the script restore_all_databases.sh with name of your backup archive as argument.
Like wise for file backup, move the files backup to restore/files directory. Go to restore/files directory and execute script restore_files.sh with name of your backup archive as argument.
For example:
cd restore/database/ sudo ./restore_all_databases.sh 2022-04-14-annotationlab-all-databases.tar.xz cd restore/files/ sudo ./restore_files.sh 2022-04-14-annotationlab-files.tar
Note:
- You need xzand bash installed to execute this script.
- This script works only with backups created by Annotation Lab backup system.
- Run this scripts with sudocommand
After restoring database and files, reboot Annotation Lab:
sudo reboot
After the server reboots, user can login using the credentials from the backed up server.
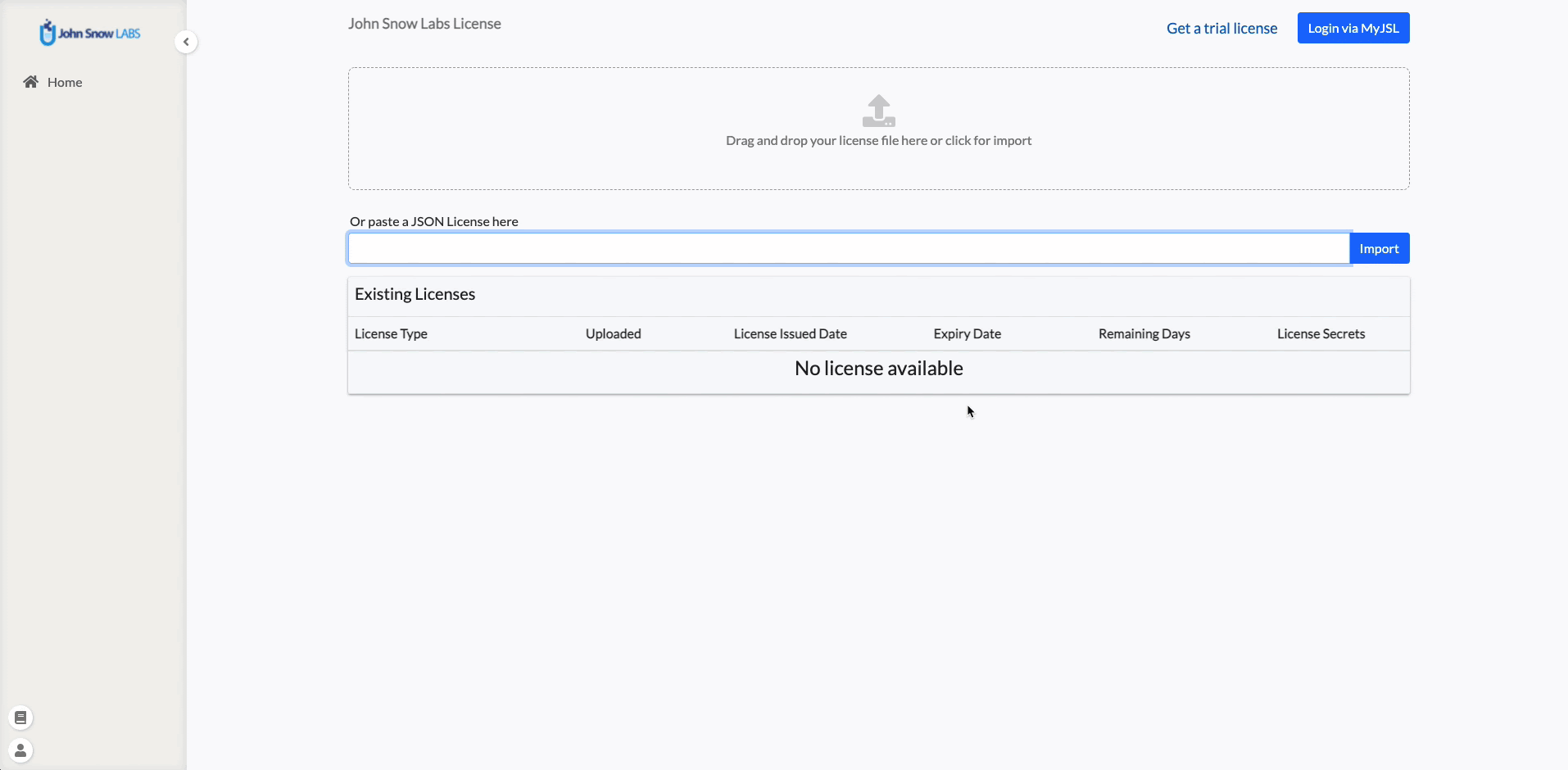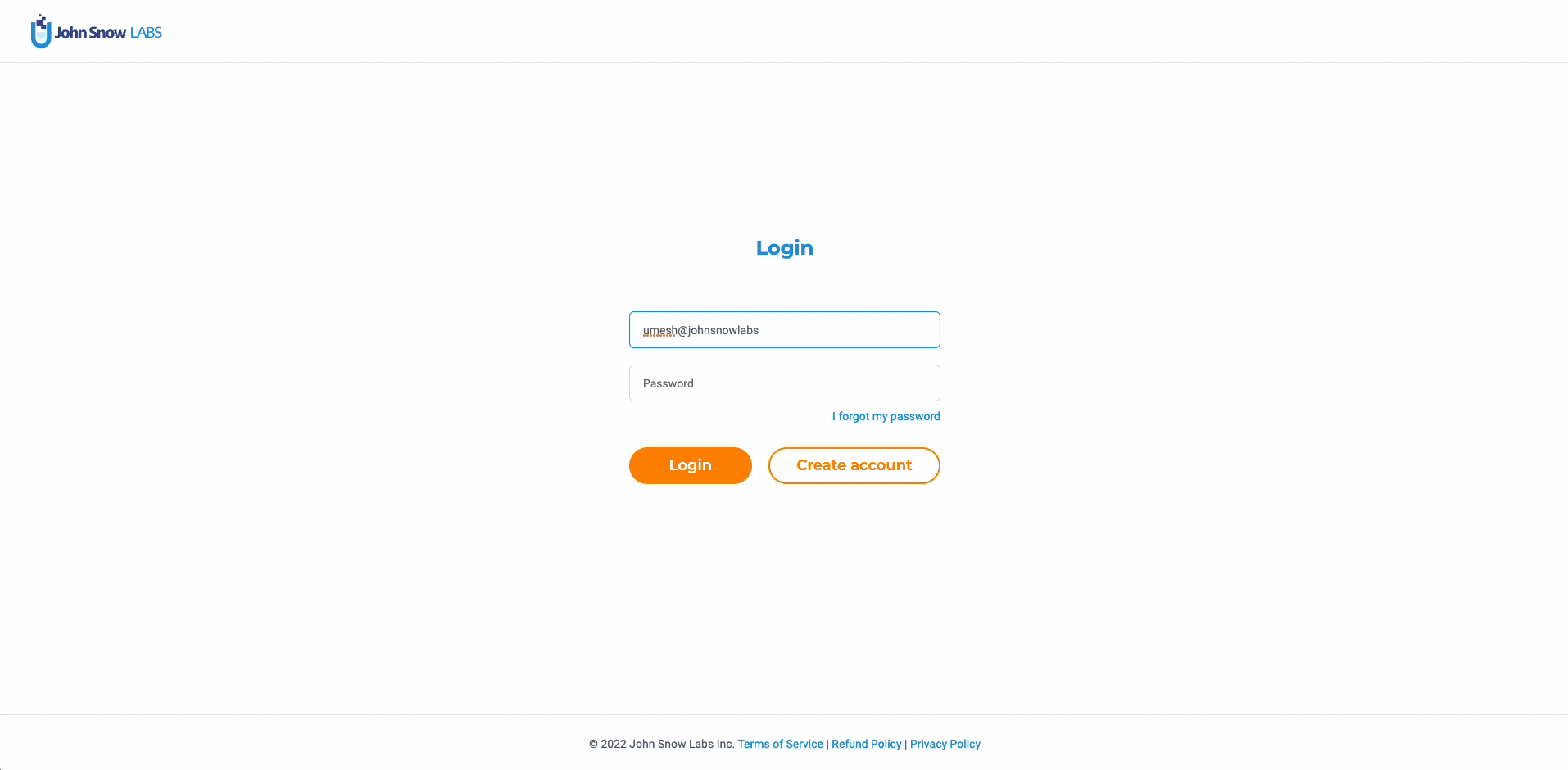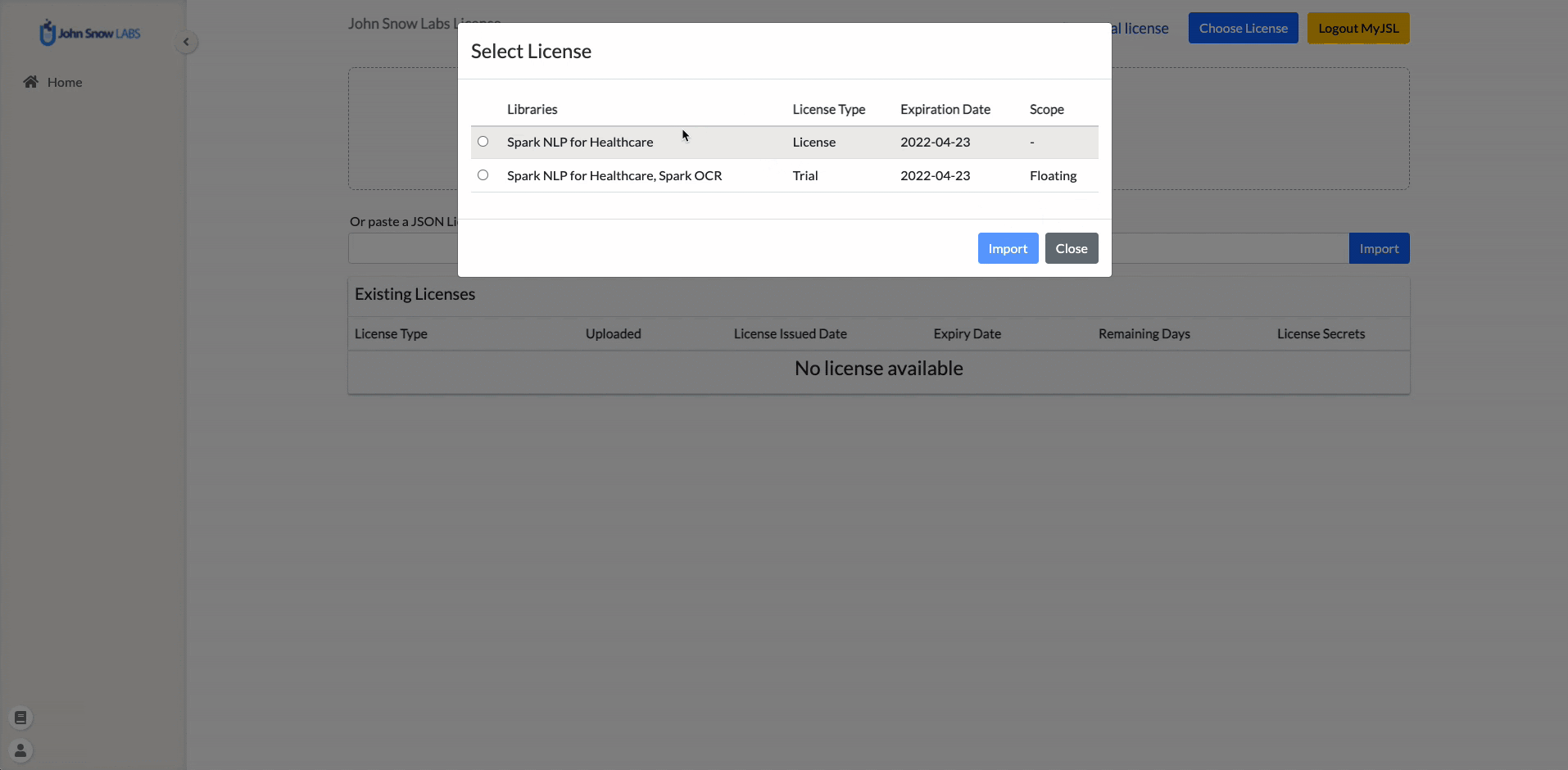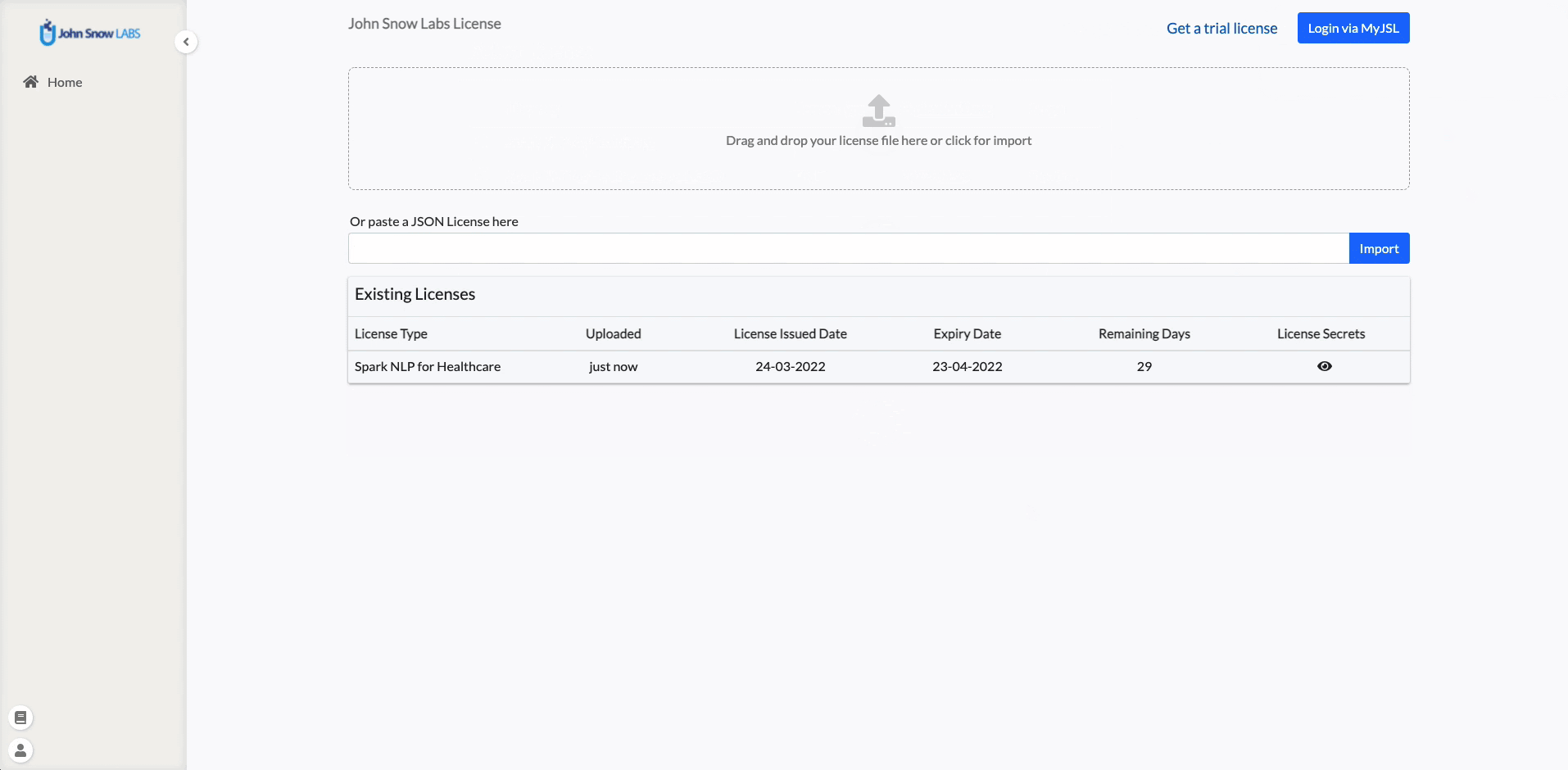
Integration with my.johnsnowlabs.com
Annotation Lab can directly be integrated with your https://my.johnsnowlabs.com/ account. This means the available licenses can be easily imported by Admin users of Annotation Lab without having to download or copy them manually.