























































Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence detection is an essential component in many natural language processing (NLP) tasks, as it enables the analysis of text at a more granular level by breaking it down into individual sentences.

Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text. It is a critical step in several natural language processing (NLP) tasks because many NLP tasks take sentence as an input unit, such as part-of-speech tagging, dependency parsing, named entity recognition or machine translation.
By accurately identifying sentence boundaries, sentence detection in Spark NLP enables downstream NLP tasks to work effectively and produce meaningful results. Spark NLP also offers pretrained models for many languages, which can be easily integrated into NLP pipelines to achieve accurate sentence detection results.
SentenceDetectorDL is an annotator of Spark NLP, which detects sentence boundaries using a deep learning approach. The models are trained on a large corpus of text data and are designed to work well on a wide range of text genres and domains.
In this post, you will learn how to use Spark NLP to perform sentence detection using pretrained models.
We will discuss detecting the sentence boundaries in a text by SentenceDetectorDL, which is a deep learning-based sentence detection annotator that is part of the Spark NLP library.
Let us start with a short Spark NLP introduction and then discuss the details of the sentence detection techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
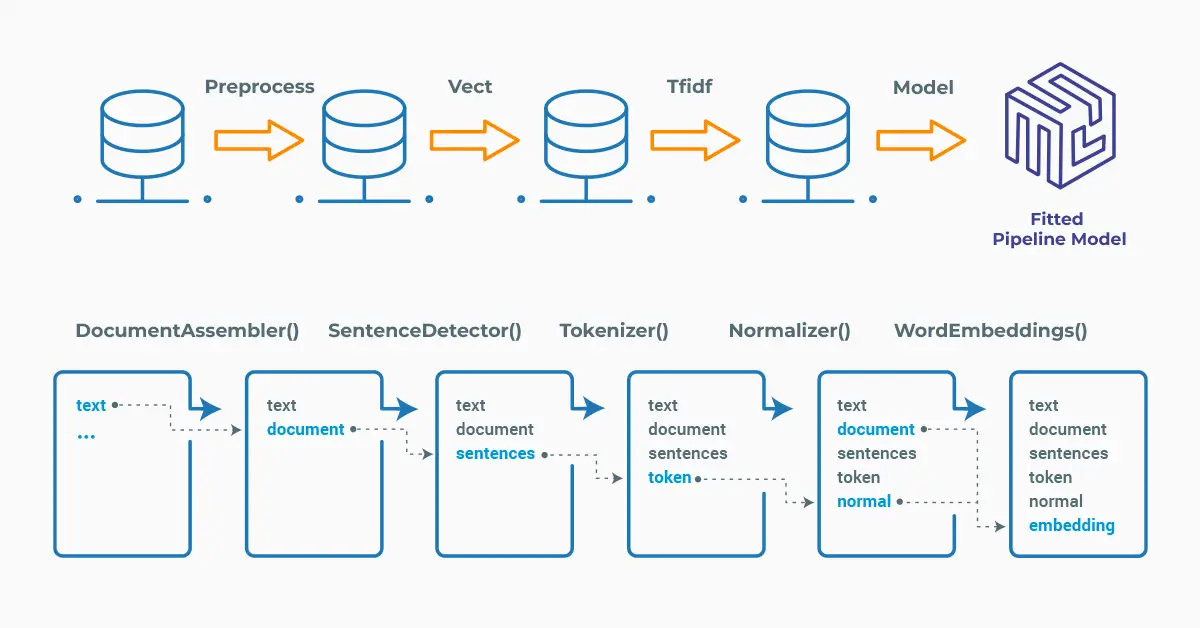
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
SentenceDetectorDLModel
SentenceDetectorDL is based on a general-purpose neural network model for sentence boundary detection. Two models (English and multi-language) are available in the John Snow Labs Models Hub and they were trained on the corpus discussed in the article named South-East European Times: A parallel corpus of Balkan languages.
Here are the test metrics on various languages for multilang model.
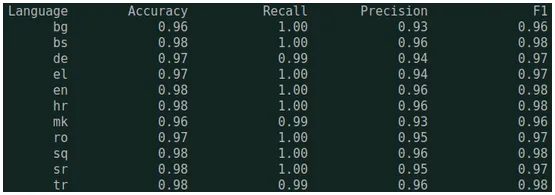
Supported Languages are Bulgarian, Bosnian, Danish, German, Greek, English, Spanish, Finnish, French, Croatian, Italian, Macedonian, Dutch, Portuguese, Romanian, Albanian, Serbian, Swedish, Turkish.
SentenceDetectorDL annotator expects DOCUMENT as input, and then will provide DOCUMENT (sentences ) as output. Thus, we need the previous step, which produces the DOCUMENT that will be used as the input to SentenceDetectorDL.
We use the model sentence_detector_dl in the following short pipeline:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, PipelineModel, LightPipeline
from sparknlp.annotator import (
SentenceDetectorDLModel
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Gets separate sentences from the Document
sentencerDL = (
SentenceDetectorDLModel.pretrained("sentence_detector_dl", "en")
.setInputCols(["document"])
.setOutputCol("sentences")
)
sd_pipeline = PipelineModel(stages=[document_assembler, sentencerDL])
We will use a LightPipeline for the process. LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles; instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data.
sd_model = LightPipeline(sd_pipeline)
After that, we feed the text and use the model to detect the sentences:
text = """John loves Mary.mary loves Peter
Peter loves Helen .Helen loves John;
Total: four. people involved."""
for anno in sd_model.fullAnnotate(text)[0]["sentences"]:
print("{}\t{}\t{}\t{}".format(
anno.metadata["sentence"], anno.begin, anno.end, anno.result))

Detected sentences
Here is a more complex text, with random additions of \n characters to test the efficiency of the model:
text = '''
There are many NLP tasks like text summarization, question-answering,
sentence prediction to name a few. One method to get\n these tasks done
is using a pre-trained model. Instead of training
a model from scratch for NLP tasks using millions of annotated texts each
time, a general language representation is created by training a model on a
huge amount of data. This is called a pre-trained model. This pre-trained model is
then fine-tuned for each NLP tasks according to need.
Let's just peek into the pre-BERT world…
For creating models, we need words to be represented in a form \n understood
by the training network, ie, numbers. Thus many algorithms were used to
convert words into vectors or more precisely, word embeddings.
One of the earliest algorithms used for this purpose is word2vec. However,
the drawback of word2vec models was that they were context-free. One problem
caused by this is that they cannot accommodate polysemy. For example,
the word 'letter' has a different meaning according to the context. It can
mean 'single element of alphabet' or 'document addressed to another person'.
But in word2vec both the letter returns same embeddings.
'''
for anno in sd_model.fullAnnotate(text)[0]["sentences"]:
print("{}\t{}\t{}\t{}".format(
anno.metadata["sentence"], anno.begin, anno.end,
anno.result.replace('\n',''))) # removing \n to beutify printing

14 sentences were extracted from the text and the model did not have any problems with the \n characters
Multi-language SentenceDetectorDL
In addition to English, the model supports 18 languages. Just remember to use “xx” instead of “en” while working on text written in other supported languages.
sentencerDL_multilang = SentenceDetectorDLModel\
.pretrained("sentence_detector_dl", "xx") \
.setInputCols(["document"]) \
.setOutputCol("sentences")
sd_pipeline_multi = PipelineModel(stages=[document_assembler, sentencerDL_multilang])
sd_model_multi = LightPipeline(sd_pipeline_multi)
We use the following Greek text to test our model:
gr_text= '''
Όπως ίσως θα γνωρίζει, όταν εγκαθιστάς μια νέα εφαρμογή, θα έχεις διαπιστώσει
λίγο μετά, ότι το PC αρχίζει να επιβραδύνεται. Στη συνέχεια, όταν επισκέπτεσαι
την οθόνη ή από την διαχείριση εργασιών, θα διαπιστώσεις ότι η εν λόγω
εφαρμογή έχει προστεθεί στη
λίστα των προγραμμάτων που εκκινούν αυτόματα, όταν ξεκινάς το PC.
Προφανώς, κάτι τέτοιο δεν αποτελεί μια ιδανική κατάσταση, ιδίως για τους
λιγότερο γνώστες, οι
οποίοι ίσως δεν θα συνειδητοποιήσουν ότι κάτι τέτοιο συνέβη. Όσο περισσότερες
εφαρμογές στη λίστα αυτή, τόσο πιο αργή γίνεται η
εκκίνηση, ιδίως αν πρόκειται για απαιτητικές εφαρμογές. Τα ευχάριστα νέα
είναι ότι η τελευταία και πιο πρόσφατη preview build της έκδοσης των
Windows 10 που θα καταφθάσει στο πρώτο μισό του 2021, οι εφαρμογές θα
ενημερώνουν το χρήστη ότι έχουν προστεθεί στη λίστα των εφαρμογών που
εκκινούν μόλις ανοίγεις το PC.
'''
for anno in sd_model_multi.fullAnnotate(gr_text)[0]["sentences"]:
print("{}\t{}".format(
anno.metadata["sentence"],
anno.result.replace('\n',''))) # removing \n to beutify printing

5 sentences were extracted from the Greek text
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run sentence detection with one line of code, we can simply use the following code for the first sample text:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
nlp.load("sentence_detector").predict("""John loves Mary.Mary loves Peter. Peter loves Helen .Helen loves John; Total: four people involved.""")
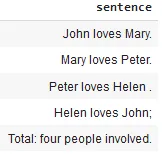
Sentences after using the one-liner model
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
For additional information, please check the following references.
- Documentation : SentenceDetectorDL
- Python Docs : SentenceDetectorDL
- Scala Docs : SentenceDetectorDL
- For extended examples of usage, see the Spark NLP Workshop repository.
Beyond technical implementation, recent developments in healthcare illustrate how sentence detection is influencing clinical practice. Healthcare providers increasingly adopt sentence-level NLP models not only for processing clinical notes but also to support real-time clinical decision-making. In practical use, integrating sentence detection into electronic health record (EHR) systems has been associated with more structured extraction of comorbidities and treatment timelines, helping physicians access more complete patient histories during consultations.
Another notable development is the broader application of multilingual NLP in international healthcare research. Hospitals and research institutes are making greater use of sentence detection across multiple languages to align datasets from global clinical studies. This approach helps reduce potential misinterpretations in trial documentation, supports smoother international collaboration, and contributes to more efficient research workflows.
Finally, combining sentence-level embeddings with generative AI tools is changing how medical literature is analyzed. When used alongside large medical language models, sentence detection can improve the clarity and consistency of complex medical text processing, such as summarizing radiology findings or identifying potential adverse drug reactions. This trend points to a future where sentence detection strengthens the foundation of more context-aware AI systems in medicine.
Conclusion
Sentence detection is a crucial step in many NLP applications, and Spark NLP offers accurate models to achieve accurate and efficient sentence detection. Sentence detection is essential because it enables the analysis of text at a more granular level, by breaking it down into individual sentences. This helps to segment large blocks of text into smaller, more manageable units and allows certain NLP algorithms to focus on analyzing one sentence at a time.
The accurate segmentation of text into sentences enables downstream NLP tasks to work effectively, improving the accuracy of many subsequent tasks. The ability to handle multiple languages, coupled with the flexibility to customize pipelines to meet specific application needs, makes Spark NLP a top choice for sentence detection.
FAQ
What is the main advantage of using Spark NLP for sentence detection?
Spark NLP provides state-of-the-art pretrained models that are optimized for both speed and accuracy. It can handle large datasets in distributed environments, making it suitable for real-world applications where scalability and performance are critical.
Can Spark NLP detect sentences in multiple languages?
Yes. The SentenceDetectorDL model supports English and a wide range of other languages, including Spanish, German, French, Greek, Turkish, and more. By using the multilingual model (“xx”), users can apply sentence detection to texts written in 18+ languages.
How does Spark NLP handle noisy text with irregular formatting?
The deep learning–based SentenceDetectorDL is trained on diverse corpora and performs well even when texts contain formatting issues, such as line breaks, punctuation errors, or missing capitalization. This robustness makes it effective for real-world data like clinical notes, social media, or unstructured documents.
Is sentence detection useful beyond text preprocessing?
Absolutely. While it is often the first step in an NLP pipeline, accurate sentence detection improves downstream tasks such as named entity recognition, sentiment analysis, machine translation, and clinical decision support systems. It ensures models process text in logical, context-aware units.
Can Spark NLP be integrated with other NLP and AI tools?
Yes. Spark NLP is designed to work seamlessly with Apache Spark ML pipelines, deep learning frameworks, and even generative AI systems. Recent integrations show its value in healthcare, where sentence detection combined with large medical language models enhances clinical summarization and research analysis.




