Sentiment analysis, also known as opinion mining, is the process of computationally identifying and categorizing the subjective information contained in natural language text. Spark NLP’s deep learning models have achieved state-of-the-art results on sentiment analysis tasks, thanks to their ability to automatically learn features and representations from raw text data.

Sentiment analysis is a popular natural language processing (NLP) task that involves determining the sentiment of a given text, whether it is positive, negative, or neutral. With the rise of social media platforms and online reviews, sentiment analysis has become increasingly important for businesses to understand their customers’ opinions and make informed decisions.
Deep learning models have revolutionized the field of sentiment analysis by providing highly accurate and scalable solutions to automatically classify text into different sentiment categories. Deep learning models can automatically learn features and representations from raw text data, making them well-suited for sentiment analysis tasks. These models have opened up new avenues for researchers and practitioners to develop more accurate and efficient sentiment analysis systems, which can have significant applications in various industries such as marketing, customer service, and product development.
Deep learning models for sentiment analysis can be trained on different types of text data, including reviews, social media posts, and news articles. The performance of these models depends on various factors such as the size and quality of the training data, the choice of model architecture, and the hyperparameters used during training.
Spark NLP has multiple approaches for detecting the sentiment (which is actually a text classification problem) in a text. There are separate blog posts for the rule-based systems and for statistical methods.
In this article, we will discuss using a pretrained Deep Learning (DL) model and then training a model, which chains together algorithms that aim to simulate how the human brain works.
Let us start with a short Spark NLP introduction and then discuss the details of deep learning-based sentiment analysis techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
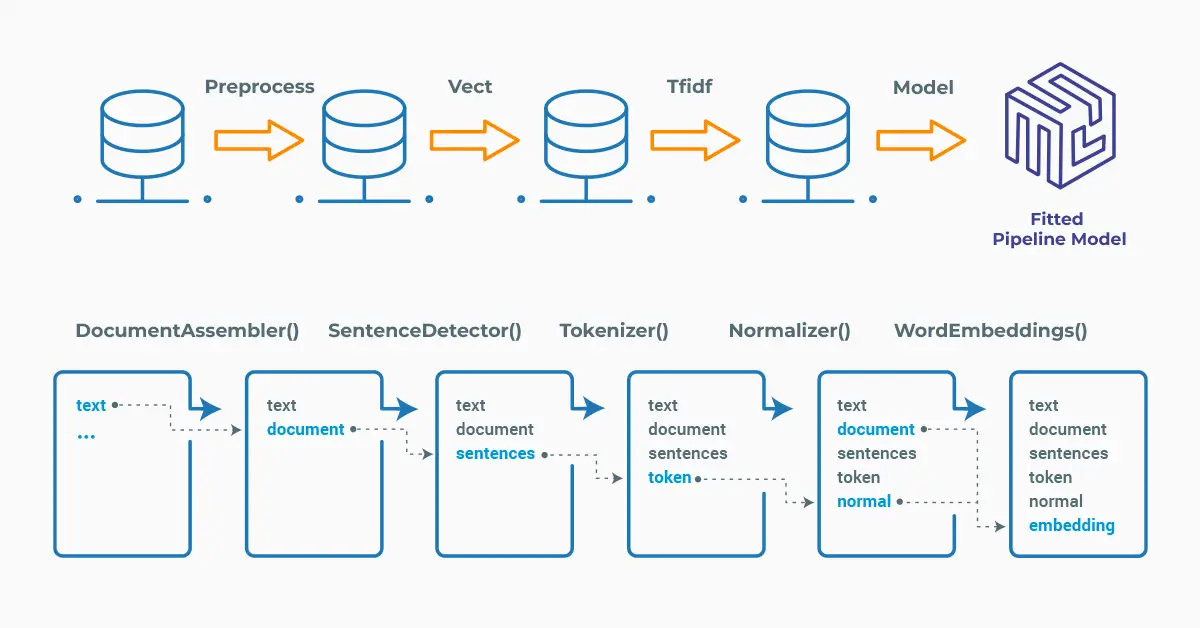
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
Solutions to Sentiment Analysis Problem
Various models can be used for sentiment analysis, but there are some key differences between them.
Machine Learning (ML) models for sentiment analysis typically use techniques such as logistic regression, decision trees, Naive-Bayes or support vector machines. These models require hand-engineering of features and may rely on domain-specific lexicons for sentiment analysis. They usually work well with smaller datasets and have faster training and inference times. However, they may not perform well on complex tasks and may not capture more nuanced aspects of language.
ML models are trained on labeled examples, where each example consists of a text and a corresponding label. During training, the model learns to identify patterns in the text that are associated with each label. For example, a machine learning model for sentiment analysis might learn to identify that the presence of certain words or phrases (such as “great” or “disappointing”) is associated with positive or negative sentiment.
On the other hand, DL models for sentiment analysis, such as recurrent neural networks (RNNs) or convolutional neural networks (CNNs), can learn representations of text automatically without the need for hand-engineering of features. These models can capture more complex patterns in the data and may perform better on more nuanced tasks such as sarcasm detection or emotion recognition. However, they may require larger datasets for training and may be computationally expensive, requiring high-performance computing resources.
In summary, ML models may be a better choice for simpler sentiment analysis tasks or when computational resources are limited, while DL models may be a better choice for more complex sentiment analysis tasks or when larger amounts of data are available.
Sentiment Analysis by Deep Learning
In deep learning-based sentiment analysis, the model is trained on a large corpus of text data, where the sentiment label is known. During training, the model learns to identify patterns and features that are indicative of a certain sentiment.
Deep learning models have proven to be very effective in sentiment analysis due to their ability to learn complex representations from large amounts of data. They can handle various forms of input data, including texts, images, and speech, and can be fine-tuned for specific domains and tasks, making them highly flexible and adaptable to various use cases.
Use a Model From the John Snow Labs Models Hub
Instead of training, saving, loading and getting predictions from a model, once again let’s start by using a pretrained model from the John Snow Lab Model’s Hub.
If you check the John Snow Lab Model’s Hub, you will see that there are more than 200 models about sentiment analysis.
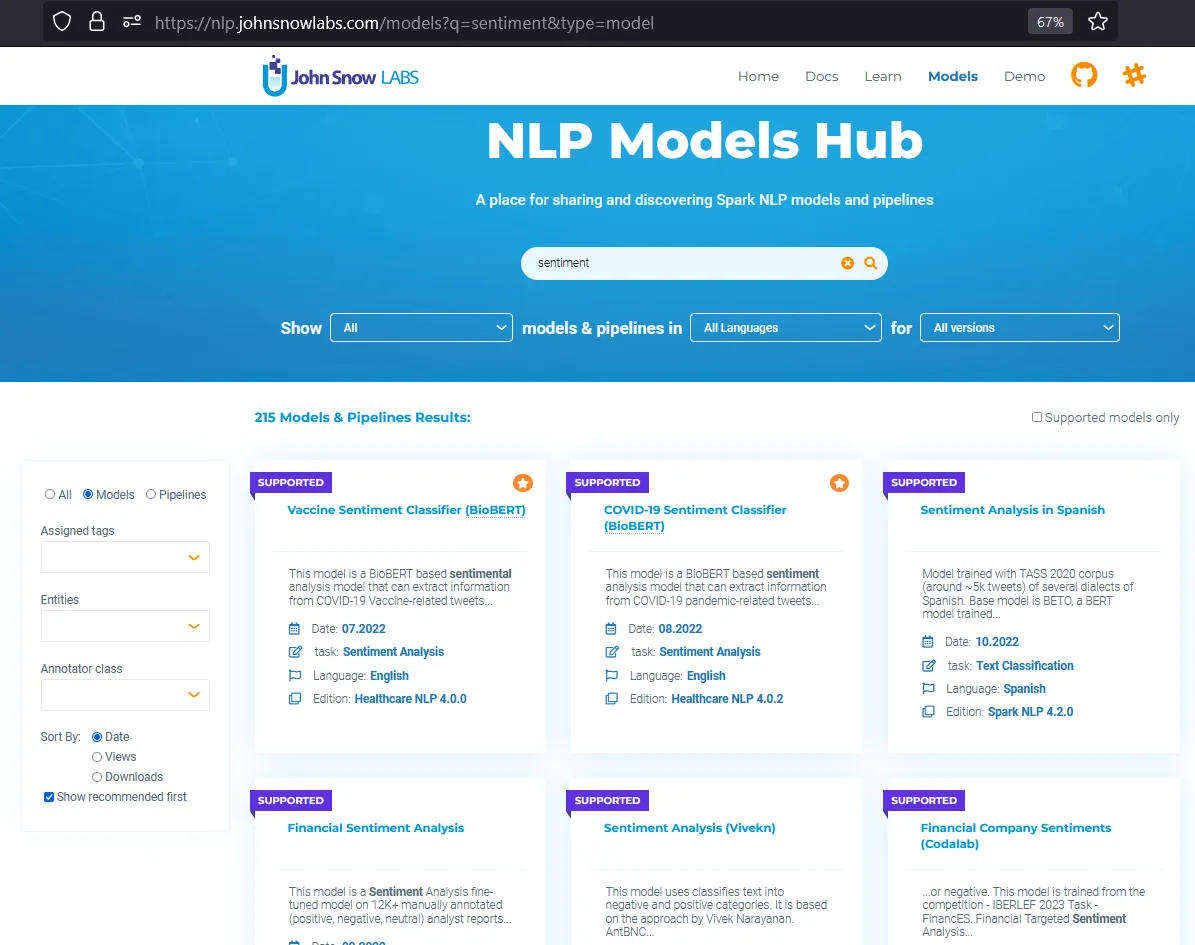
Let’s use the model named Sentiment Analysis of Tweets. This model automatically classifies sentiment in tweets as negative or positive using Universal Sentence Encoder embeddings.
In text classification applications (including sentiment analysis), it is imperative to consider all of the text instead of a single word because a single word may not provide enough information to accurately classify a text. By considering the entire text, we can capture the context of the text and use that to classify the text more accurately.
For this reason, UniversalSentenceEncoder, BertSentenceEmbeddings, SentenceEmbeddings or other sentence embeddings should be used for preparing the embeddings stage.
First, we define a short pipeline with SentimentDLModel as the last stage and then define 10 texts for sentiment analysis.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, LightPipeline
from sparknlp.annotator import (
UniversalSentenceEncoder,
SentimentDLModel
)
import pyspark.sql.functions as F
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
use = UniversalSentenceEncoder.pretrained("tfhub_use", "en")\
.setInputCols(["document"])\
.setOutputCol("sentence_embeddings")
sentimentdl = SentimentDLModel.pretrained("sentimentdl_use_twitter", "en")\
.setInputCols(["sentence_embeddings"])\
.setOutputCol("sentiment")
nlpPipeline = Pipeline(
stages = [
documentAssembler,
use,
sentimentdl
])
text_list = [
"""@Mbjthegreat i really dont want AT&T phone service..they suck when it comes to having a signal""",
"""holy crap. I take a nap for 4 hours and Pitchfork blows up my twitter dashboard. I wish I was at Coachella.""",
"""@Susy412 he is working today ive tried that still not working..... hmmmm!! im rubbish with computers haha!""",
"""Brand New Canon EOS 50D 15MP DSLR Camera Canon 17-85mm IS Lens ...: Web Technology Thread, Brand New Canon EOS 5.. http://u.mavrev.com/5a3t""",
"""Watching a programme about the life of Hitler, its only enhancing my geekiness of history.""",
"""GM says expects announcment on sale of Hummer soon - Reuters: WDSUGM says expects announcment on sale of Hummer .. http://bit.ly/4E1Fv""",
"""@accannis @edog1203 Great Stanford course. Thanks for making it available to the public! Really helpful and informative for starting off!""",
"""@the_real_usher LeBron is cool. I like his personality...he has good character.""",
"""@sketchbug Lebron is a hometown hero to me, lol I love the Lakers but let's go Cavs, lol""",
"""@PDubyaD right!!! LOL we'll get there!! I have high expectations, Warren Buffet style.""",
]
Now, we get predictions by transforming the model:
empty_df = spark.createDataFrame([['']]).toDF("text")
model = nlpPipeline.fit(empty_df)
df = spark.createDataFrame(pd.DataFrame({"text":text_list}))
result = model.transform(df)
We have the option to use spark.sql.functions to visualize the information in a better format:
result.select(
F.explode(
F.arrays_zip(
result.document.result,
result.sentiment.result)).alias("cols")
).select(
F.expr("cols['0']").alias("document"),
F.expr("cols['1']").alias("sentiment")
).show(truncate=False
)
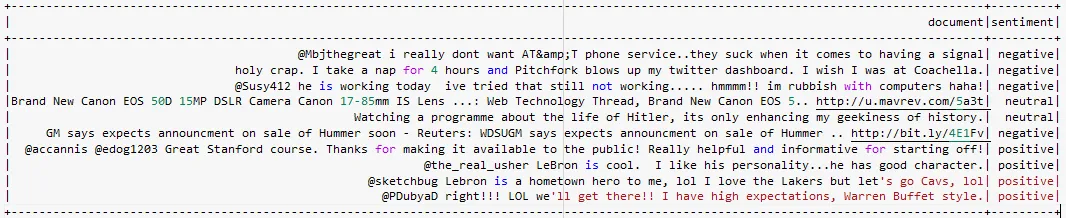
In the dataframe above, you can see the exploded results that show the predicted sentiments for the corresponding texts.
Using LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an Array of strings instead, to be annotated.
We can show the results in a Pandas DataFrame by running the following code:
import pandas as pd
light_model = LightPipeline(model)
light_result = light_model.fullAnnotate(text_list)
texts = []
results_tabular = []
for k in light_result:
for s in k["document"]:
texts.append((s.result))
for r in k["sentiment"]:
results_tabular.append(
(r.result))
text_column = pd.DataFrame(texts, columns=["text"])
sent_column = pd.DataFrame(results_tabular, columns=["sentiment"])
pd.concat([text_column,sent_column], axis=1)
The dataframe shows the predicted sentiments of the texts
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run sentiment analysis with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
# Returns a pandas Data Frame, we select the desired columns
nlp.load("en.sentiment.twitter").predict("""@Mbjthegreat i really dont want AT&T phone service..they suck when it comes to having a signal""")

After using the one-liner model, the result shows that the detected sentiment is Negative
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
Train a Model by SentimentDLApproach
Finally, instead of using a pretrained model, we will train a model by using a labelled dataset and then use this trained model to get predictions.
We load the datasets from John Snow Labs AWS S3 and get them as dataframes. Both the training and test datasets involve 25,000 rows of labelled text and there is perfect balance between positive and negative sentiments.
!wget -q aclimdb_train.csv https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sentiment-corpus/aclimdb/aclimdb_train.csv
!wget -q aclimdb_test.csv https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/sentiment-corpus/aclimdb/aclimdb_test.csv
trainDataset = spark.read \
.option("header", True) \
.csv("aclimdb_train.csv")
testDataset = spark.read \
.option("header", True) \
.csv("aclimdb_test.csv")
trainDataset.show(5, truncate=150)
First 5 rows of the training dataset is shown below:

The pipeline below is quite similar to the one that we used for SentimentDLModel:
# Import the required modules and classes
from sparknlp.annotator import (
SentimentDLApproach
)
documentAssembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
useEmbeddings = UniversalSentenceEncoder.pretrained() \
.setInputCols(["document"]) \
.setOutputCol("sentence_embeddings")
sentimentdl = SentimentDLApproach() \
.setInputCols(["sentence_embeddings"]) \
.setOutputCol("sentiment") \
.setLabelColumn("label") \
.setMaxEpochs(5) \
.setEnableOutputLogs(True)
pipeline = Pipeline() \
.setStages(
[
documentAssembler,
useEmbeddings,
sentimentdl
]
)
pipelineModel = pipeline.fit(trainDataset)
!cat ~/annotator_logs/SentimentDLApproach_12faa854e3b3.log
Training logs show the constant increase in the accuracy of the model.

Now, we can get predictions on the Test Dataset:
result = pipelineModel.transform(testDataset)
result_df = result.select('text','label',"sentiment.result").toPandas()
result_df.head(20)

The columns show the text, original label and the predicted sentiment (result)
The predictions of the trained model is shown in the “result” column, whereas ground truth is shown in the “label” column.
This is just a quick result; normally we use many more than 5 epochs. Also, SentimentDLApproach annotator has multiple parameters and those parameters can have a significant impact on the metrics of a text classification model.
For additional information, please consult the following references.
- Documentation : SentimentDL
- Python Docs : SentimentDL
- Scala Docs : SentimentDL
- For extended examples of usage, see the Spark NLP Workshop repository.
- For LightPipelines, check this post.
Conclusion
Sentiment analysis is an important NLP task that aims to classify the sentiment of a piece of text as positive, negative, or neutral. Spark NLP’s deep learning models have shown great success in sentiment analysis tasks and these models have significantly improved the accuracy of sentiment analysis tasks by learning contextual information and capturing the nuances of language.
However, there are still some challenges in sentiment analysis that deep learning models need to address. These include handling imbalanced datasets, dealing with sarcasm, irony, and figurative language, and incorporating domain-specific knowledge. Moreover, the performance of deep learning models is highly dependent on the quality of the training data, which needs to be carefully curated and labeled.
Despite these challenges, sentiment analysis deep learning models have significant potential to be applied in various fields, such as marketing, customer service, and politics. They can be used to analyze customer feedback, predict consumer behavior, and gauge public opinion. With further advancements in deep learning, we can expect sentiment analysis models to become even more accurate and useful in various applications.