






















































Empowering Domain Experts to Build State-of-the-Art AI Solutions Without Code.
Two years ago, Annotation Lab 1.0, no code AI platform, was launched by John Snow Labs, to respond to the burning need for a production-ready tool for annotating unstructured documents in all domains. We envisioned an easy-to-use instrument offered for free for any team of domain experts, without any restrictions in terms of the number of users, projects, or documents. We also knew that all enterprise-level features should be included and 100% free: security, privacy, team & project management, analytics, workflows, versioned audit trails, and scalability.
Following that vision, we added to the Annotation Lab AI features that ease the work of annotators by learning from their examples and by training models capable of suggesting high-quality pre-annotations.

This natural evolution of the Annotation Lab, guided by our user community, has taken the tool well beyond the annotation task and transformed it into a No-Code End-to-End AI platform: The NLP Labs.
Building an AI Tool for Domain Experts
Data extraction from text is a day-to-day task for specialists working in verticals such as Healthcare, Finance, or Legal. NLP models are now a well-established solution with proven utility in automating such efforts. However, model testing, tuning, and training require extensive data to reach maximum accuracy, as well as technical knowledge to operate them to analyze your data.
Up until now, AI models have been accessible to a handful of people: hands-on experts in deep learning and transfer learning. Our number one goal with the NLP Lab is to make this accessible to everyone, via an easy-to-use UI, without the need to know any details about under-the-hood libraries and model architectures.
Despite the recent advances in AI and the massive adoption of Deep Learning in all domains and verticals, NLP models are not a commodity yet and do not cover out-of-the-box all extraction needs that a team might have. To cover the blind spots of the existing models, when starting an annotation project and when training data is not yet available, the NLP Lab allows users to define rules and create prompts. Mixed together in NLP projects those new pre-annotation features expand the NLP Lab beyond the current model management capabilities in an attempt to respond to new challenges:
- How can users tune models to address the blind spots of pre-trained models, or fit them to very specific business needs?
- How can they take advantage of the large language models capable of understanding a text and answering questions about it?
- Is there an easy way to define questions or prompts that help identify entities or relations?
- How can domain experts write rules to extract simple entities such as phone numbers or SSN? Is there an easy way to test those rules?
- How can users test the quality of their annotations and fix the existing labeling errors in bulk?
- How can users test their models for bias and robustness?
What is the NLP Lab?
The NLP Lab is a full-fledged no-code AI Platform, powered by the John Snow Labs NLP libraries, that allows domain experts to handle the complete AI development cycle: from document acquisition and annotation to model testing/training/tuning to model deployment for pre-annotation. All that without writing a line of code, but via a friendly user interface and without any need to involve data scientists.
Collaborative Text Annotation
NLP Lab is a natural evolution of the Annotation Lab. As such, it includes all the annotation features offered by its predecessor. It covers out-of-the-box annotation for text, image (here you can find full scale image annotation tool), PDF, video, audio, or HTML documents, for tasks such as Named Entity Recognition, Classification, Relation Extraction, and Assertion Status.
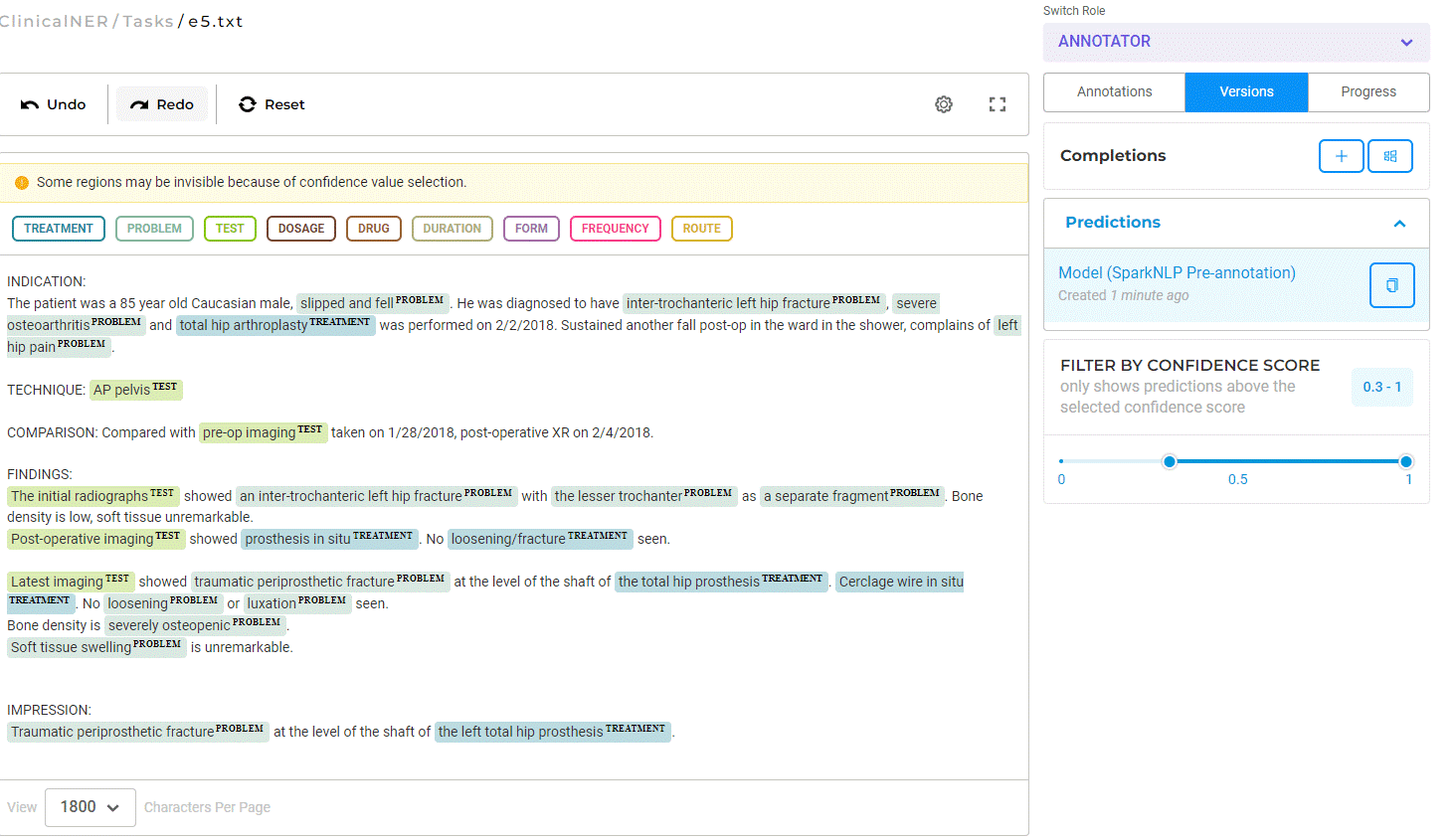
Figure 1. Text Annotation Interface
The tool offers support for a team to work together and annotate a set of documents – including reviews, comments, workflows, and project management features. The interface is very intuitive and easy to use, and data acquisition and annotation export are straightforward. Annotation versioning is maintained by the tool as well as a complete audit trail for all user actions. It is possible to compare versions in a visual manner or in an aggregated form via project analytics. Project analytics are available and cover tasks analytics, team productivity, and inter-annotator agreement charts.
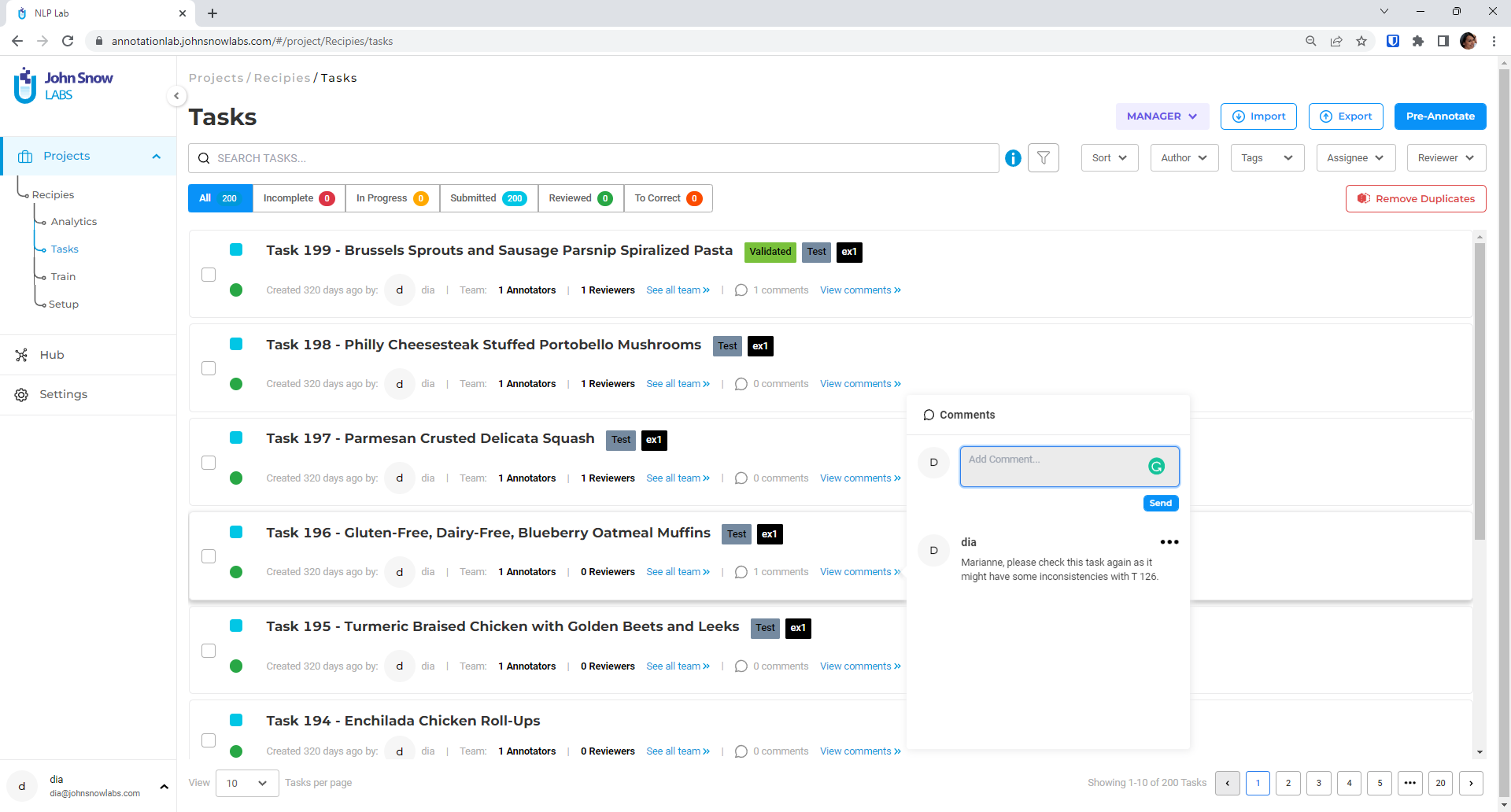
Figure 2. Tasks dashboard
The NLP Lab also includes out-of-the-box quality tests that can help identify label errors and provide automatic fixing strategies. Those can help improve the quality of the training data and thus of the resulting models.
Model Training, Tuning, and Testing
The NLP Lab targets a change in approach towards AI model testing, training, and tuning. The domain experts should gain their rightful place as main actors in the field, they need to be empowered to pass their knowledge to AI models, rules, or prompts and then apply those to automate day-to-day text analysis work.
This no-code NLP solution by John Snow Labs will remove the dependency on data scientists and empower non-technical users to perform all those tasks via an intuitive and easy-to-use UI interface, powered by the John Snow Labs NLP libraries under the hood.
The NLP Lab ensures the entire development cycle for model, rules, and prompts creation, testing, and publication is available to domain experts.
With the NLP Lab, users can quickly explore and test available models, rules, and prompts on their data via the new Playground feature and choose the ones that are more adapted to their needs to add to their projects. The Playground also allows straightforward editing of rules and prompts, allowing users to see live the results obtained on custom text and tailor those resources to their needs.
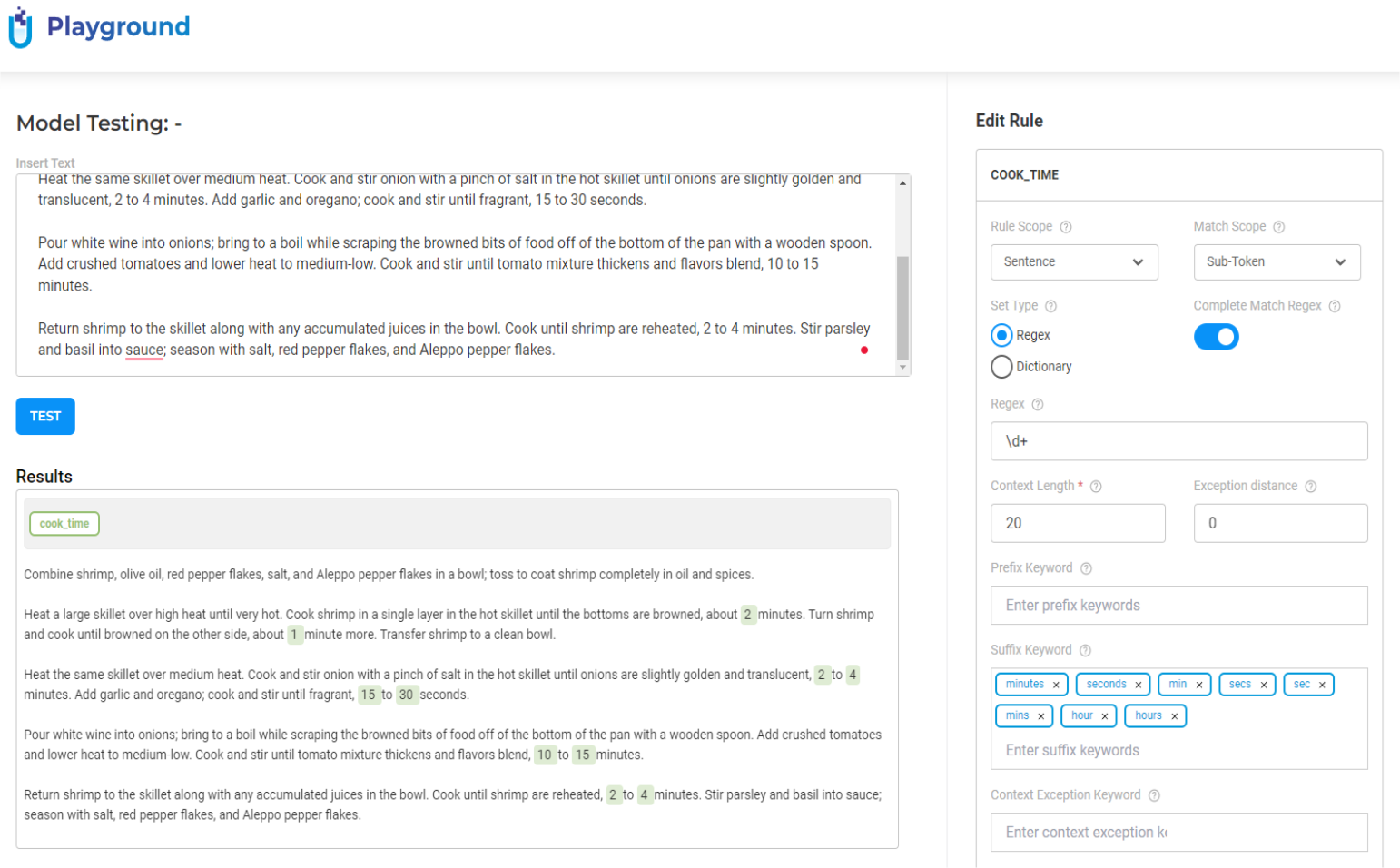
Figure 3. Playground environment for quickly testing models, rules, and prompts
When no pre-trained model exists for the target entities, relations, or classes, train a new model with the click of a button based on tasks manually annotated by domain experts. The new models will right away be available for testing or automatic pre-annotation. Users can deploy them for pre-annotating new tasks or export them for use in a production environment.
The active learning feature ensures new models are automatically trained in the background when new annotations are submitted in a project. The new configuration is automatically deployed and ready to use for pre-annotating new tasks.
Users can now easily go beyond model training and access model testing and tuning features available via an intuitive UI that hides all the hard-to-grasp scientific details of the NLP libraries used under the hood. Users can experiment with their annotations, train different versions of models, access their accuracy measures, then further iterate or deploy them for pre-annotation or publish them on s3.
The NLP Lab also allows users to benchmark models on annotated tasks tagged as test tasks. This is a useful indication of how accurate the pre-trained models are on the target documents and what is the level of agreement between the model and the domain experts on the test tasks. When the benchmarking results are not sufficiently high, NLP Lab allows users to tune existing models. Tuning starts from the base vanilla model and enriches it with new training data, letting the model adapt to the new data and improve its performance.
The NLP Lab has a scalable architecture that allows running as many parallel training and pre-annotation servers as your infrastructure permits.
Combining Models, Rules, and Prompts of John Snow Labs’ No-Code NLP Solution
To ensure you never have to start from scratch, the NLP Lab lets you combine three approaches to jumpstart your AI projects:
- Transfer Learning – Tune pre-trained deep learning models
- Programmatic Labeling – Define custom rules and let a model generalize them
- Prompt Engineering – Define natural language prompts for extracting answers
Programmatic labeling is a method of automatically generating annotations using regular expressions or dictionary-based rules, rather than having a human annotator label each data point manually. This can be useful when there is a large amount of data that needs to be labeled, as it can save time and resources compared to having a human annotator label the data by hand. Programmatic labeling can be very useful to recognize entities such as phone numbers, addresses, SNN, dates, money amounts, etc. in other words entities that have a relatively fixed text structure or that can be defined by a finite number of words.
Prompt engineering is the process of designing and crafting prompts, that repurpose question-answering language models for NLP tasks such as Named Entity Recognition and Relation extraction. The goal of prompt engineering is to create prompts that are clear and focused and provide the necessary context and information for the language model to generate accurate and coherent responses. Support for prompt engineering is becoming a critical feature for any text pre-annotation tool must support to ensure viable pre-annotations for domains not covered by pretrained NLP models or for new types of unseen documents or use cases. These capabilities allow non-technical domain experts to apply zero-shot and few-shot learning directly from the user interface.
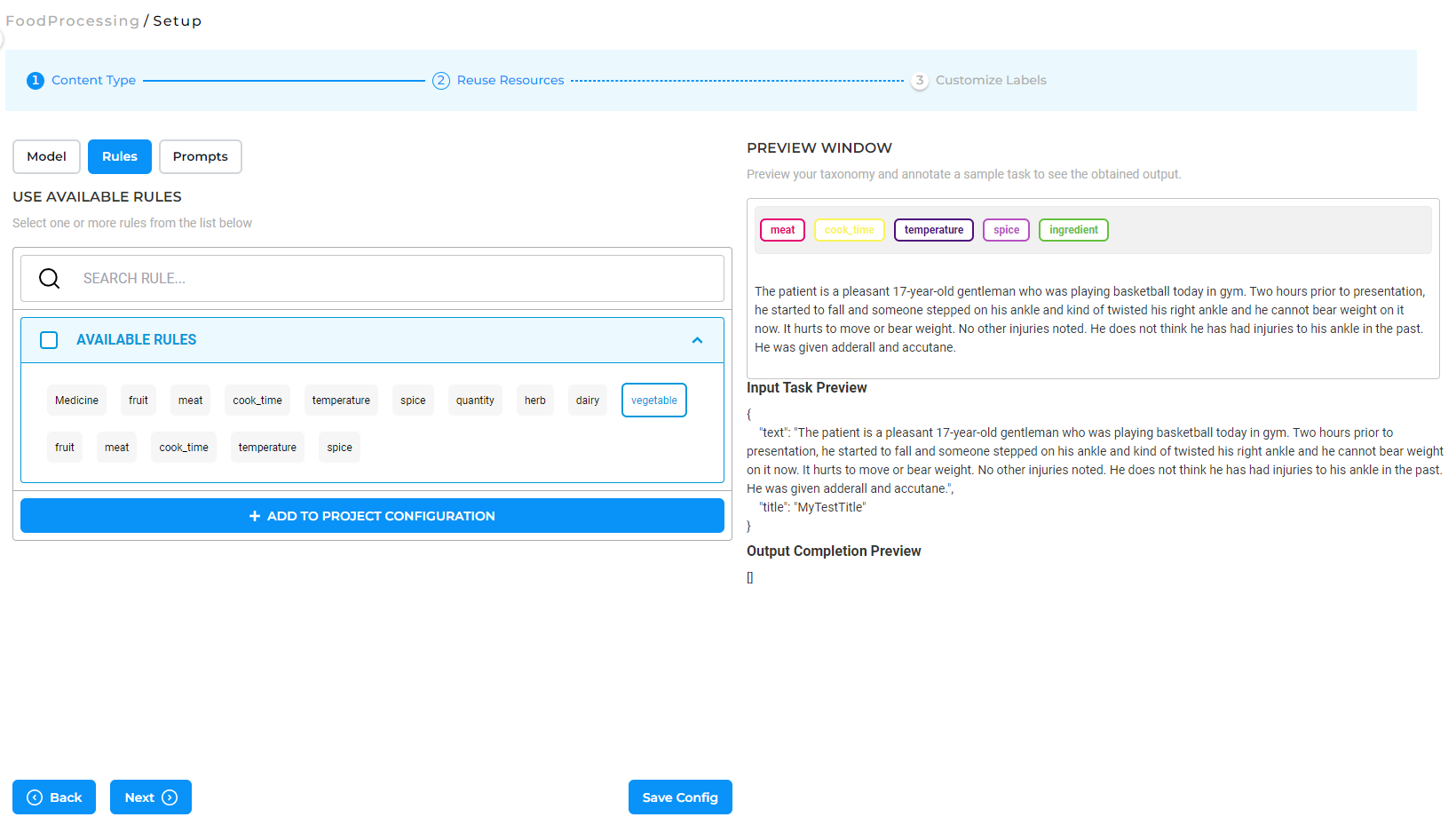
Figure 4. Combining models, rules, and prompts to fit all annotation needs.
The NLP Lab allows users to easily combine models, prompts, and rules into their projects to ensure that the annotation work never starts from scratch and that annotators do not waste time on tasks that are already covered by the machine. With rules and prompts, the NLP Lab ensures that far fewer manual annotations are required to achieve state-of-the-art accuracy. Users can mix & match the available resources easily to fit their purpose.
The Private Hub: Find, Share, Demo, and Serve Models
The NLP Lab offers direct access to 10,000+ models published on the NLP Models Hub. Those are accessible from the Hub section, on the NLP Models Hub page, where users can explore the available models, search models based on their name or description, and filter them based on the edition, task, and language for easier discoverability.
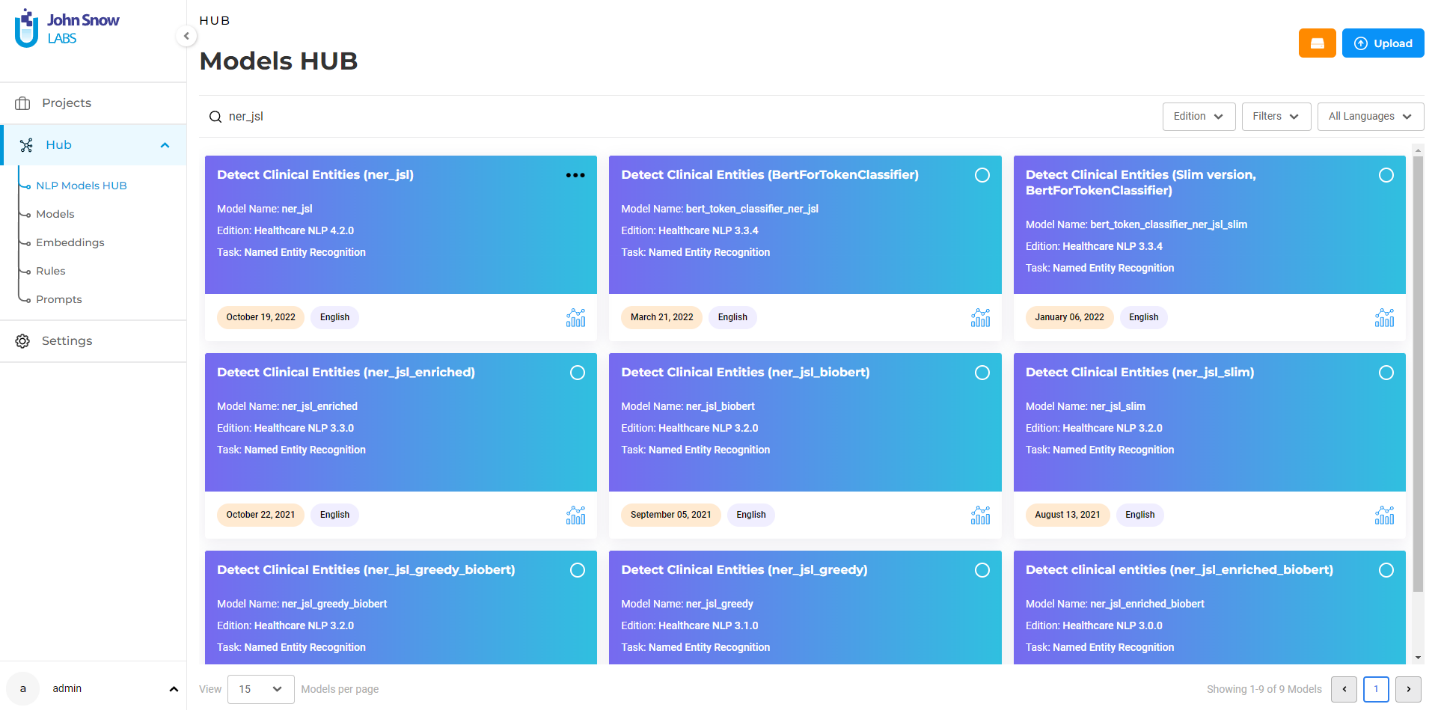
Figure 5. The Hub of Models, Rules, and Prompts
The Hub is also a place where team members can share custom or private models, rules, prompts, and embeddings for internal use. Those can be manually uploaded by users, or defined, trained, or tuned within the NLP Lab. Once the relevant models, rules, and prompts are discovered, they can quickly be tested on the Playground or reused as part of a new project. Models that are trained as part of annotation projects are automatically published to the private hub and can be accessed and reused by other users from the team. Benchmarking information is available for those and can be accessed using the icon next to the model name. Custom models can easily be published to s3 for safe storage or downloaded for external use. Resources on the private hub can be renamed, or removed when no longer needed.
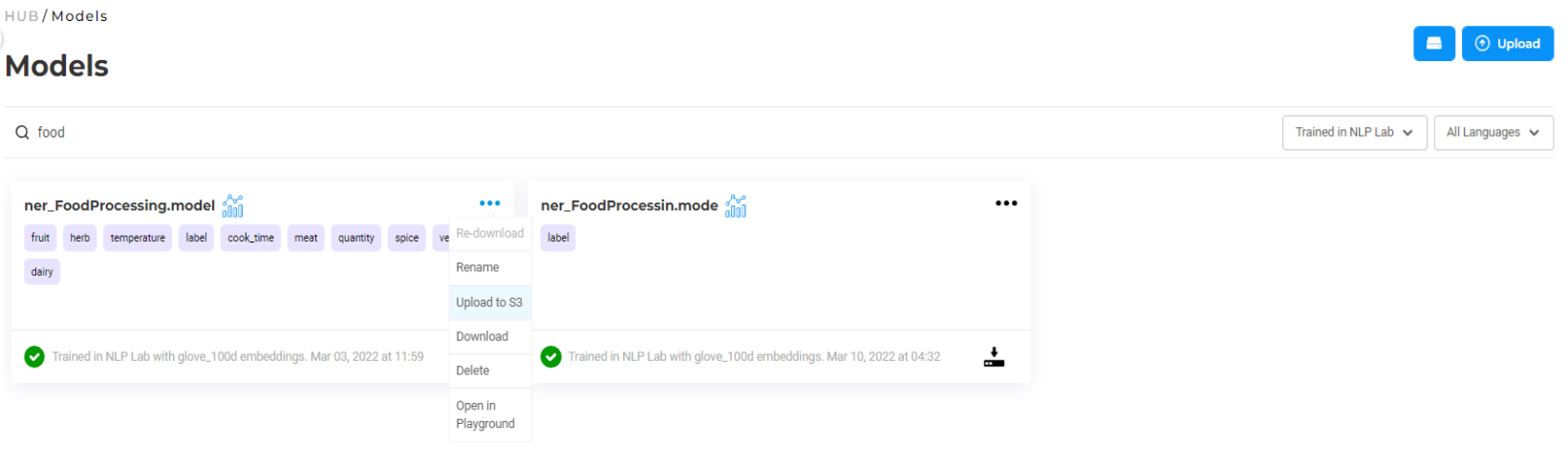
Figure 6. Models Operations
The NLP Lab allows fast model deployment, easy server configuration to accommodate running multiple training and pre-annotation servers in parallel.
The deployed pre-annotation servers can be accessed via the application UI or via API endpoints to ensure seamless integration with external services and tools.
Test Models for Bias and Robustness
Bias test for deep learning models are used to evaluate whether a model’s accuracy differs on certain groups of people. These tests can be used to identify and address potential biases in a model before it is deployed in real-world applications, where it may have significant consequences. It is important to include this type of test in the models’ life cycle as they can replicate and amplify existing biases in the data they are trained on. By identifying and addressing any biases in a model, users can help ensure that a model is fair and unbiased in its predictions, or can simply declare all existing biases in the case they are inherent to the data (e.g. breast cancer models will inherently be biased towards women).
Model robustness refers to the ability of a model to perform well on unexpected inputs. A robust model can handle input data that is different from the training data, and generalizes better to new environments and error conditions. One way to test and increase the robustness of a deep-learning model is via data augmentation. Augmenting the training data by applying random transformations to the input text, such as capitalizations or typos, can help train a model to better generalize on such data. By increasing the robustness of a deep learning model, one can improve its performance and make it more reliable for use in real-world applications.
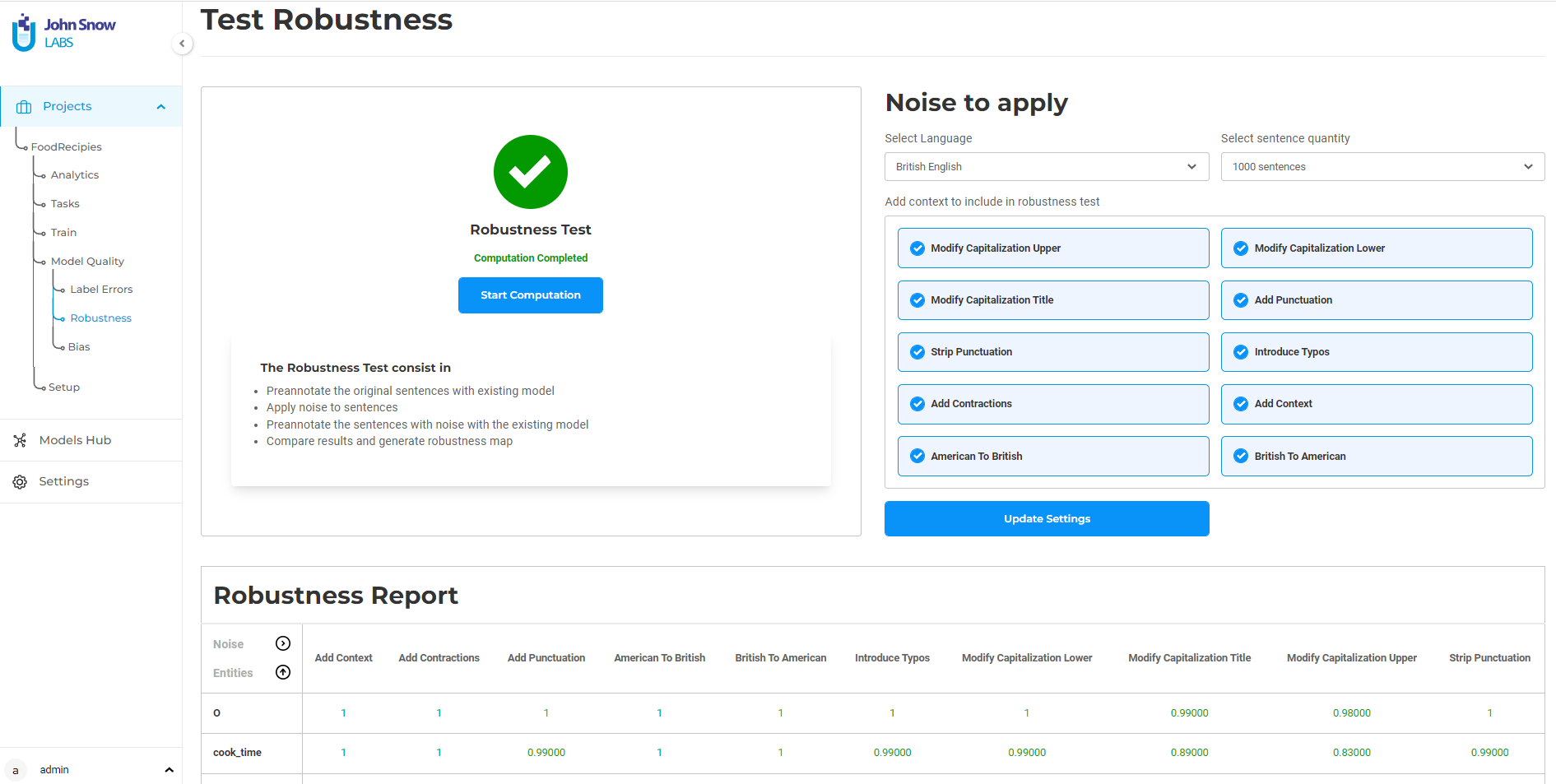
Figure 7. Quality Tests in the NLP Lab
The NLP Lab will include automatic testing of models’ bias and robustness and provide recommendations to the user on how to improve models if necessary. For instance, for bias improvement, the tools should guide users on what tasks to annotate next so that the model is more balanced. To improve the robustness of a model, this no-code NLP solution will automatically apply data augmentation methods to expand the training data in such a way that the model will learn how to deal with messy text.
Getting Started is Easy
The NLP Labs is a free tool that can be deployed in a couple of clicks on the AWS and Azure Marketplaces, or installed on-premise with a one-line Kubernetes script. Get started here:




