Sentence embeddings are a powerful tool in natural language processing that helps analyze and understand language. Transformers, a type of neural network architecture, are a popular method for generating these embeddings. Using sentence embeddings with Transformers has become popular because it allows for the creation of high-quality vector representations of entire sentences that capture their semantic and syntactic meaning.

Sentence embeddings with Transformers are a powerful natural language processing (NLP) technique that use deep learning models known as Transformers to encode sentences into fixed-length vectors that can be used for a variety of NLP tasks. Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences.
Transformers have revolutionized the field of NLP by enabling the creation of language models that can understand context and generate coherent text, and sentence embeddings are one of the many applications of this technology. By generating a vector representation of a sentence, these embeddings allow us to compare and measure the similarity between sentences, cluster similar sentences together, and perform a wide range of other NLP tasks.
In Spark NLP, this technique can be applied using the Bert, RoBerta or XlmRoBerta (multilingual) sentence level embeddings, which leverages pretrained transformer models to generate embeddings for each sentence that captures the overall meaning of the sentence in a document. These embeddings can then be used for a variety of downstream tasks, such as sentiment analysis, text classification, or semantic search.
By late 2025, healthcare NLP pipelines increasingly adopted multimodal sentence embeddings that fuse clinical notes with imaging narratives and structured labs, creating a single patient-centric representation. This unified view improves retrieval-augmented workflows (e.g., finding prior similar cases), reduces duplication in diagnostics, and supports safer handoffs between departments by aligning textual, visual, and tabular evidence into one embedding space.
Domain-specialized transformer embeddings also became a practical default for clinical decision support, outperforming general-purpose models on rare disease phenotyping and treatment response summarization. Beyond raw accuracy, these healthcare-tuned embeddings integrate calibration, bias checks, and audit trails so quality teams can trace which evidence (sentences, sections, sources) influenced a recommendation, making model outputs easier to validate and govern.
In 2026, continual learning patterns matured: hospitals fine-tune sentence embeddings on rolling updates from guidelines, formularies, and local outcome data without full retraining. This keeps models aligned with current practice, lowers drift, and shortens validation cycles, so upgrades ship faster while preserving safety controls, versioned datasets, and human-in-the-loop sign-off.
BertSentenceEmbeddings, RoBertaSentenceEmbeddings and XlmRoBertaSentenceEmbeddings are annotators in Spark NLP that use the pre-trained BERT (Bidirectional Encoder Representations from Transformers) — family language models to generate fixed-length sentence embeddings for natural language text.
Generating sentence embeddings from word embeddings is also a popular approach in Spark NLP that involves transforming individual word embeddings into a fixed-size vector representation that captures the meaning and context of a whole sentence. This process is achieved through a variety of techniques such as averaging or pooling that enable the modeling of sentence-level semantics and enable downstream tasks such as sentiment analysis, text classification, and machine translation. The resulting sentence embeddings can capture complex relationships between words, syntax, and context and provide a more comprehensive understanding of textual data.
Spark NLP has multiple solutions for producing sentence embeddings with transformers for longer pieces of text. In this article, we will discuss using state-of-the-art transformer-based models for this task.
There is also a short section about generating sentence embeddings from Bert word embeddings, focusing specifically on the average-based transformation technique.
Let us start with a short Spark NLP introduction and then discuss the details of producing sentence embeddings with transformers with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
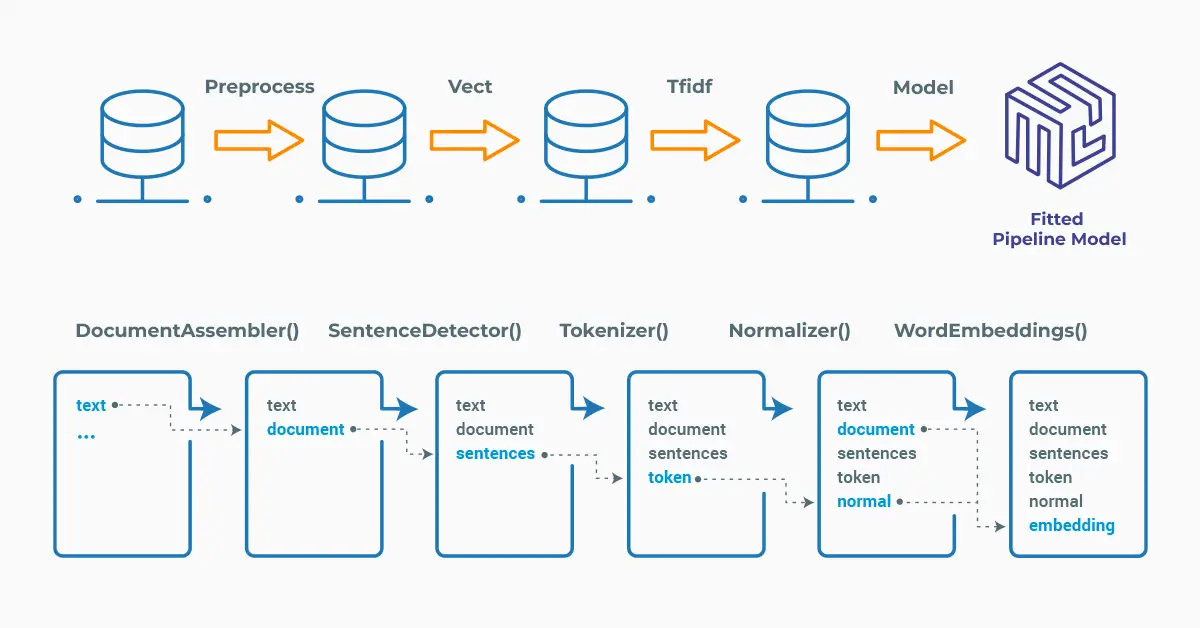
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
BertSentenceEmbeddings
BertSentenceEmbeddings is a Spark NLP annotator that provides sentence-level embeddings using BERT (Bidirectional Encoder Representations from Transformers). BERT provides dense vector representations for natural language by using a deep, pretrained neural network with the Transformer architecture.
We will use the following model: Smaller BERT Sentence Embeddings, where the model generates sentence embeddings using the BertSentenceEmbeddings annotator of Spark NLP. Model’s homepage will give you detailed information about the model, its size, data source used for training and a sample pipeline showing how to use it.
Please check the details of the pipeline below, where we generate the sentence embeddings of a text:
from sparknlp.base import DocumentAssembler
from sparknlp.annotator import SentenceDetector, BertSentenceEmbeddings
from pyspark.ml import Pipeline
import pyspark.sql.functions as F
documentAssembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
embeddings = BertSentenceEmbeddings.pretrained("sent_small_bert_L2_128") \
.setInputCols(["sentence"]) \
.setOutputCol("sentence_bert_embeddings")\
.setCaseSensitive(True) \
.setMaxSentenceLength(512)
pipeline = Pipeline(stages=[documentAssembler,
sentence,
embeddings])
In Spark ML, we need to fit the defined pipeline to make predictions (see this documentation page if you are not familiar with Spark ML).
After that, we define a text and generate sentence embeddings for this text by transforming the model.
text = "NLP combines computer science and linguistics to enable computers to
understand human language. NLP has various applications, such as chatbots and
sentiment analysis. Deep learning models have significantly advanced NLP
capabilities. NLP faces challenges such as ambiguity and context-dependency."
example_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(example_df)
result_bert = model.transform(example_df)
Let’s explode the results to see the sentence and the corresponding embeddings (128 dimensional vector for this model):
result_df = result_bert.select(F.explode(F.arrays_zip
(result_bert.sentence.result,
result_bert.sentence_bert_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("Bert_sentence_embeddings"))
result_df.show(truncate=150)

Sentences and the corresponding Bert sentence embeddings
Using LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an array of strings instead, to be annotated.
Check this post to learn more about this class.
We can produce the predictions by running the following code:
from sparknlp.base import LightPipeline light_model_emb = LightPipeline(pipelineModel = model, parse_embeddings=True)
Let’s see the sentences and the corresponding Bert sentence embeddings:
annotate_results_emb = light_model_emb.annotate(text) list(zip(annotate_results_emb['sentence'], annotate_results_emb['sentence_bert_embeddings']))

LightPipeline result showing the original sentences and the generated Bert sentence embeddings
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run the Bert Sentence Embeddings model with one line of code, we can simply use the following code:
from johnsnowlabs import nlp
embeddings_df = nlp.load('en.embed_sentence.small_bert_L2_128').predict(text, output_level='sentence')
embeddings_df
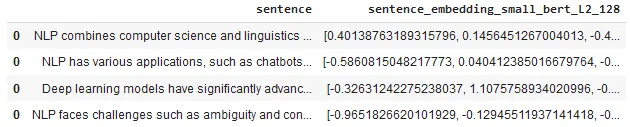
Bert sentence embeddings generated by the One-liner model
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
RoBertaSentenceEmbeddings
RoBertaSentenceEmbeddings is an annotator in Spark NLP that generates fixed-length sentence embeddings using the RoBERTa (Robustly Optimized BERT approach) model. RoBERTa is a variant of the BERT model that has been further optimized for NLP tasks, using techniques such as dynamic masking and larger batch sizes during training.
Let’s use this annotator and the Spark NLP model to produce RoBerta sentence embeddings:
from sparknlp.annotator import RoBertaSentenceEmbeddings
embeddings = RoBertaSentenceEmbeddings.pretrained("sent_roberta_base", "en") \
.setInputCols("sentence") \
.setOutputCol("sentence_roberta_embeddings")
pipeline = Pipeline(stages=[
documentAssembler,
sentence,
embeddings
])
model = pipeline.fit(example_df)
result_roberta = model.transform(example_df)
Explode the results to see the sentences and the corresponding RoBerta embeddings:
result_df = result_roberta.select(F.explode(F.arrays_zip(result_roberta.sentence.result,
result_roberta.sentence_roberta_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("RoBerta_sentence_embeddings"))
result_df.show(truncate=150)

Sentences and the corresponding RoBerta sentence embeddings
XlmRoBertaSentenceEmbeddings (Multilingual)
XlmRoBertaSentenceEmbeddings is a Spark NLP annotator that provides sentence-level embeddings using the XLM-RoBERTa model. XLM-RoBERTa is a multilingual BERT-based model that was pretrained on a massive dataset of text and code in 104 languages. XLM-RoBERTa has the same architecture as BERT, but uses a byte-level Byte-Pair Encoding (BPE) as a tokenizer and uses a different pretraining scheme.
Let’s use this model and try in different languages.
Text in French
Let’s define a French text and create a dataframe by using this text:
text = "La PNL combine l'informatique et la linguistique pour permettre aux
ordinateurs de comprendre le langage humain. La PNL a diverses applications,
telles que les chatbots et l'analyse des sentiments. Les modèles
d'apprentissage en profondeur ont des capacités de PNL considérablement
avancées. La PNL fait face à des défis tels que l'ambiguïté et la dépendance
au contexte."
example_df = spark.createDataFrame([[text]]).toDF("text")
Please check the details of the pipeline below, where we generate the XlmRoBerta sentence embeddings of the text:
from sparknlp.annotator import XlmRoBertaSentenceEmbeddings
embeddings = XlmRoBertaSentenceEmbeddings.pretrained("sent_xlm_roberta_base", "xx") \
.setInputCols("sentence") \
.setOutputCol("sentence_xlmroberta_embeddings")
pipeline = Pipeline(stages=[
documentAssembler,
sentence,
embeddings
])
model = pipeline.fit(example_df)
result_xlmroberta = model.transform(example_df)
Explode the results to see the sentences and the corresponding XlmRoBerta embeddings:
result_df = result_french.select(F.explode(F.arrays_zip(result_french.sentence.result,
result_french.sentence_xlmroberta_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("XlmRoBerta_sentence_embeddings"))
result_df.show(truncate=150)

Sentences of the French text and the corresponding XlmRoBerta sentence embeddings
Text in German
Now, do the exact same thing for the text written in German.
text = "NLP verbindet Informatik und Linguistik, um Computer in die Lage
zu versetzen, die menschliche Sprache zu verstehen. NLP hat verschiedene
Anwendungen, wie Chatbots und Stimmungsanalysen. Deep-Learning-Modelle
verfügen über deutlich erweiterte NLP-Fähigkeiten. NLP steht vor
Herausforderungen wie Mehrdeutigkeit und Kontextabhängigkeit."
example_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(example_df)
result_german = model.transform(example_df)
Explode the results to see the sentences and the corresponding XlmRoBerta embeddings:
result_df = result_german.select(F.explode(F.arrays_zip(result_german.sentence.result,
result_german.sentence_xlmroberta_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("XlmRoBerta_sentence_embeddings"))
result_df.show(truncate=140)

Sentences of the German text and the corresponding XlmRoBerta sentence embeddings
From Word to Sentence Embeddings
It is also an option in Spark NLP to produce the word embeddings by using a Bert model with the BertEmbeddings annotator, and then use the SentenceEmbeddings annotator to generate the sentence embeddings. Notice that we set the Pooling Strategy parameter to Average.
from sparknlp.annotator import Tokenizer, BertEmbeddings, SentenceEmbeddings
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
bert_embeddings = BertEmbeddings().pretrained(name='small_bert_L4_256', lang='en') \
.setInputCols(["sentence",'token'])\
.setOutputCol("embeddings")
embeddingsSentence = SentenceEmbeddings() \
.setInputCols(["sentence", "embeddings"]) \
.setOutputCol("sentence_embeddings") \
.setPoolingStrategy("AVERAGE")
bert_pipeline = Pipeline(stages=[document_assembler,
sentence,
tokenizer,
bert_embeddings,
embeddingsSentence
])
We will use the English text that we defined previously.
example_df = spark.createDataFrame([[text]]).toDF("text")
model = bert_pipeline.fit(example_df)
result = model.transform(example_df)
Let’s explode the results to see the sentences and the corresponding sentence embeddings produced by using the Bert word embeddings.
result_df = result.select(F.explode(F.arrays_zip(result.sentence.result,
result.sentence_embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("sentence"),
F.expr("cols['1']").alias("Bert_sentence_embeddings"))
result_df.show(truncate=120)

Sentences and the sentence embeddings generated from the Bert word embeddings
Using Sentence Embeddings to Calculate Sentence Similarity
Sentence similarity is a fundamental task in NLP that aims to measure the semantic similarity between two sentences and sentence embeddings can be used to calculate semantic similarity between sentences.
Cosine distance, also known as cosine similarity, is a measure of similarity between two non-zero vectors in a high-dimensional space. If the cosine distance is closer to 1, it indicates that the two vectors are very similar and have a small angle between them. Conversely, if the cosine distance is closer to -1, it indicates that the two vectors are very dissimilar and have a large angle between them. A cosine distance of 0 means that the two vectors are orthogonal and have no similarity.
For this, we start with importing the Python libraries, scipy and numpy:
from scipy.spatial import distance import numpy as np
Let’s define three sentences, two of them about the same topic:
sentence_0 = "ChatGPT's sophisticated natural language processing capabilities enable it to generate human-like responses to a wide range of queries."
sentence_1 = "With its comprehensive training on diverse topics, ChatGPT can understand and generate text on a wide range of subjects."
sentence_2 = "A diabetic foot is any pathology that results directly from peripheral arterial disease."
sentence_df = spark.createDataFrame([[sentence_0], [sentence_1], [sentence_2]]).toDF("text")
Use the pipeline for BertSentenceEmbeddings:
embeddings_bert = BertSentenceEmbeddings.pretrained("sent_small_bert_L2_128") \
.setInputCols(["sentence"]) \
.setOutputCol("sentence_bert_embeddings")\
.setCaseSensitive(True) \
.setMaxSentenceLength(512)
pipeline = Pipeline(stages=[documentAssembler,
sentence,
embeddings_bert])
model = pipeline.fit(example_df)
Generate the embeddings for the sample sentences:
embeddings = model.transform(sentence_df).select('sentence_bert_embeddings.embeddings').collect()
Once we have the embeddings, we need to turn them into arrays in order to use them to calculate cosine distances:
v0 = np.array(embeddings[0]['embeddings'][0]) v1 = np.array(embeddings[1]['embeddings'][0]) v2 = np.array(embeddings[2]['embeddings'][0])
Let’s get the cosine distance values:
similarity_a = 1 - distance.cosine(v0, v1) similarity_b = 1 - distance.cosine(v1, v2) similarity_c = 1 - distance.cosine(v2, v0)
Finally, check the similarity values between the three sentences:
similarity_a, similarity_b, similarity_c
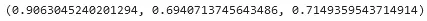
The pair of sentences with higher similarity are sentence_0 and sentence_1, which makes sense, considering that they both refer to ChatGPT and the last sentence is about the patients with diabetes.
You can find another example of sentence similarity in this blog post.
For additional information, please consult the following references:
- Documentation : BertSentenceEmbeddings, RoBertaSentenceEmbeddings, XlmRoBertaSentenceEmbeddings.
- Python Docs : BertSentenceEmbeddings, RoBertaSentenceEmbeddings, XlmRoBertaSentenceEmbeddings.
- Scala Docs : BertSentenceEmbeddings, RoBertaSentenceEmbeddings, XlmRoBertaSentenceEmbeddings.
- For extended examples of usage, see the Spark NLP Workshop repository.
- For LightPipelines, check this post.
Conclusion
Sentence embeddings with Transformers represent a significant advancement in the field of NLP. By leveraging the power of deep learning models like Transformers, sentence embeddings allow us to encode sentences into fixed-length vectors that can be used for a wide range of NLP tasks, from sentiment analysis to text classification and beyond.
Generating sentence embeddings from word embeddings is also a powerful technique in NLP that enables the transformation of individual word embeddings into a fixed-size vector representation that captures the meaning and context of a whole sentence.
The sentence embeddings produced by transformer-based architectures provide a more comprehensive understanding of textual data, enabling the development of more accurate and robust NLP applications. Spark NLP has many alternatives for generating the sentence embeddings using the transformer-based language models.
Sentence similarity is a fundamental task in NLP that aims to measure the semantic similarity between two sentences. Cosine Similarity measures the cosine of the angle between the vectors of two sentences. Traditional methods often fail to capture the semantic meaning and contextual information of the sentences, leading to inaccurate results. Sentence embeddings has emerged as a promising technique for calculating sentence similarity.
FAQ
- What are sentence embeddings in Spark NLP used for?
They are vector representations of entire sentences that capture semantic meaning. In Spark NLP, they are applied to tasks like semantic search, clustering, classification, question answering, and retrieval-augmented generation (RAG). - Which transformer models can I use for sentence embeddings?
Spark NLP supports BERT, RoBERTa, and XLM-RoBERTa. BERT is efficient for English and smaller workloads, RoBERTa offers stronger accuracy on English tasks, and XLM-RoBERTa is best for multilingual data. - How do sentence embeddings improve healthcare NLP?
They unify clinical notes, imaging reports, and structured data into patient-centric representations. This supports better decision support, case retrieval, and evidence-based recommendations in hospitals and research. - What are the latest trends in sentence embeddings?
Key advances include multimodal embeddings that combine text with other data types, domain-specialized transformers tuned for clinical tasks, and continual learning pipelines that adapt to updated guidelines without full retraining. - How can organizations ensure compliance when deploying these models?
Best practices include anonymizing patient data, maintaining audit logs, calibrating models for bias, versioning datasets, and using human-in-the-loop review for high-risk outputs. This ensures both accuracy and regulatory alignment.