A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
Annotation Lab 2.7.0 is here! This is another feature rich release from John Snow Labs – Annotation Lab Team. It is powered by the latest Spark NLP and Spark NLP for Healthcare libraries and offers improved support for Rule Base Annotation. With the upgrade of Spark NLP libraries, the Models Hub page inside the application gets more than 100 new models for English along with the introduction of Spanish and German models. In Visual NER projects, it is now easier to annotate cross-line chunks. As always, there are many security and stabilizations shipped.
Here is an overview of what has been shipped in this release:
Spark NLP 3.4.1
Annotation Lab 2.7.0 includes Spark NLP 3.4.1 and Spark NLP for Healthcare. Model training is now significantly faster and issues related to Rule-based annotation have been solved. The Models Hub has increased the list of models and old incompatible models are now marked as “incompatible”. If there are any incompatible models downloaded on the machine, we recommend deleting them.
Spanish, German Models in Models Hub
In previous versions of the Annotation Lab, the Models Hub only offered English language models. But from version 2.7.0. models for two other languages are included as well, namely Spanish and German. It is possible to download or upload these models and use them for preannotation, in the same way as for English language models.
Improved Rule-Based Annotation
Rule-based annotation, introduced in 2.6.0, with limited options, was improved in this release. The Rule creation UI form was simplified and extended, and helpful tips were added to each field.While creating a rule, the user can define the scope of the rule as being a sentence or document.
- When a document is selected, the rule searched for a match on each sentence of a document.
- When a sentence is selected, the rule searched for a match on each token of a sentence.
A new toggle parameter Complete Match Regex is added to the rules. Complete Match Regex can be toggled on to preannotate the entity that exactly matches the regex or dictionary value regardless of the Match Scope.
Users can now view the Help Text for all rule fields by hovering over the ? icon. This release also adds the validation of fields: Suffix, Prefix, and Exception such that only single tokens are accepted.
When clearing prefixes, suffixes, and exceptions from the input field, the operation was not saved. In this version, these fields can be cleared to EMPTY and saved. Also case-sensitive is always true (and hence the toggle is hidden in this case) for REGEX while the case-sensitive toggle for dictionary can be toggled on or off.
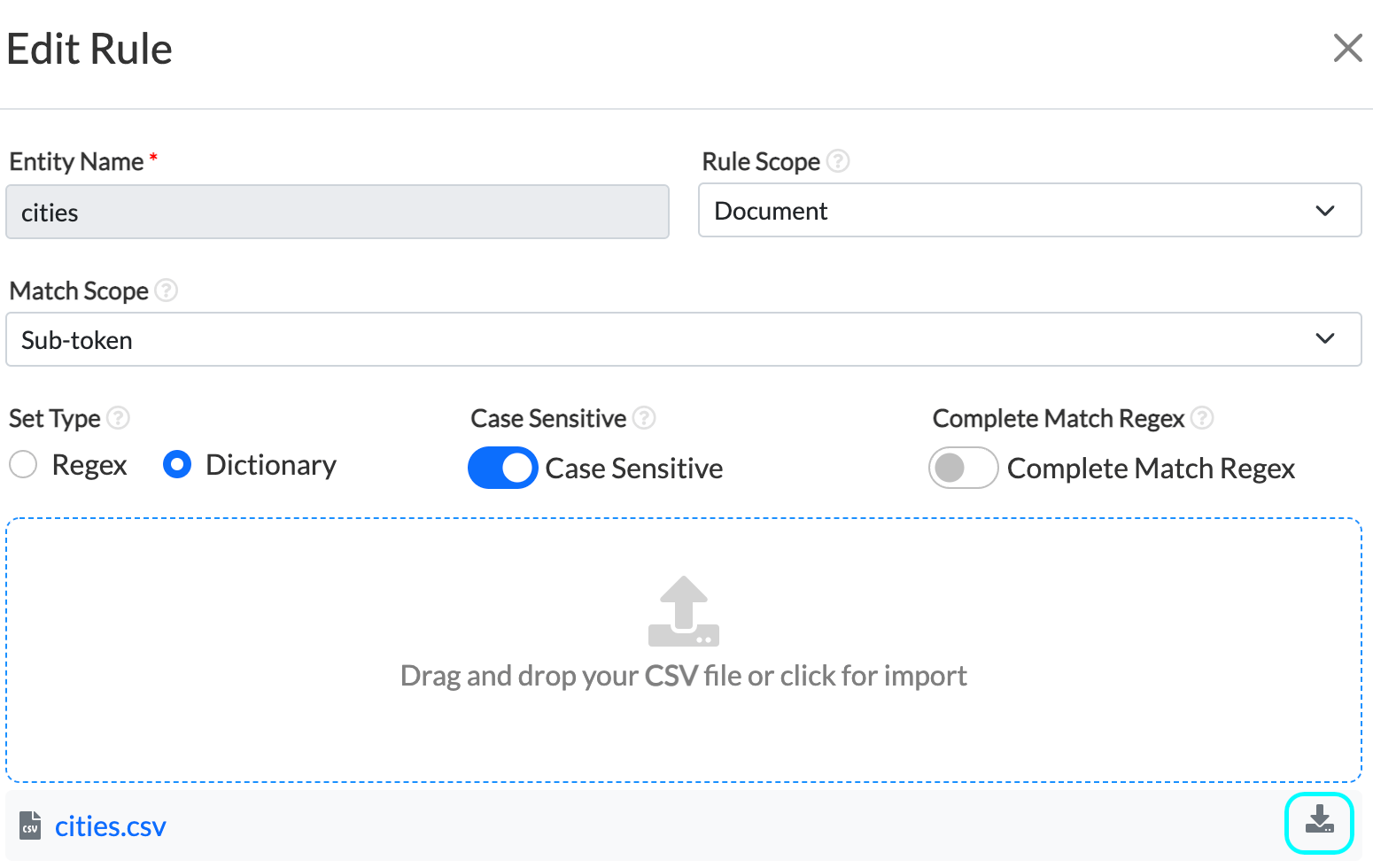
In the previous release, if a dictionary-based rule was defined with an invalid CSV file, the preannotation server would crash and would only recover when the rule was removed from the configuration. This issue has been fixed. Also, it is possible to upload both vertical and horizontal CSV which can consist of multi-token dictionary values.
Horizontal CSV for Disease Rule:
disease,chickenpox,pneumonia,common cold,tetanusVertical CSV for Disease Rule:
- disease
- chickenpox
- pneumonia
- common cold
- tetanus
Note: The first value in the CSV should be the same as the name of the rule.
Flexible annotations for Visual NER Projects
Chunk annotation
The chunk annotation feature added to Visual NER projects allows the annotation of several consecutive tokens as one chunk. It also supports multiple lines selection.
How to create multiple chunks?
To annotate a multi-token chunk follow the steps below:
- Activate the label to use
- Click on the first token
- Press the ‘a’ or shift key once [Do not keep on pressing the hotkey] or click on the ‘Select all’ button on the right-hand side.
- After releasing the hotkey select the last token on the chunkThis action will create one or several annotated regions which are linked by a Connected relation. The connected relations are organized in groups and they act as one annotation.
- Users can now select multiple tokens and annotate them together in Visual NER Projects.

- The label assigned to a connected group can be updated. This change will apply to all regions in the group.

- Edit the connected group: It is possible to remove one or several parts of the connected group and/or add new regions.

- Connected relations are independent of regular relations.

Constraints for relation labeling
While annotating projects with Relations between Entities, defining constraints (the direction, the domain, the co-domain) of relations is important. Annotation Lab 2.7.0 offers a way to define such constraints by editing the Project Configuration. The Project Owner or Project Managers can specify which Relation needs to be bound to which Labels and in which direction. This will hide some Relations in Labeling Page for NER Labels which will simplify the annotation process and will avoid the creation of any incorrect relations in the scope of the project.
To define such constraint
- Add allowed attribute to the <Relation> tag
- L1>L2 means Relation can be created in the direction from Label L1 to Label L2, but not the other way around
- L1>L2 means Relation can be created in either direction between Label L1 to Label L2
- If the allowed attribute is not present in the tag, there is no such restriction
A sample Project Configuration with Constraints for Relation Labeling
<View>
<Header value="Sample Project Configuration for Relations Annotation"/>
<Relations>
<Relation value="Was In" allowed="PERSON>LOC"/>
<Relation value="Has Function" allowed="LOC>EVENT,PERSON>MEDICINE"/>
<Relation value="Involved In" allowed="PERSON<>EVENT"/>
<Relation value="No Constraints"/>
</Relations>
<Labels name="label" toName="text">
<Label value="PERSON"/>
<Label value="EVENT"/>
<Label value="MEDICINE"/>
<Label value="LOC"/>
</Labels>
<Text name="text" value="$text"/>
</View>

Security
Security issues related to SQL Injection Vulnerability and Host Header Attack were fixed in this release.