






















































This blog post explores using Healthcare NLP, a powerful NLP library, for clinical text analysis. It focuses on Contextual Assertion for clinical text analysis, which significantly boosts accuracy in identifying negation, possibility, and temporality in medical records. The post demonstrates how Contextual Assertion outperforms deep learning based assertion status detection, particularly in accurately categorizing health conditions. Summarized metrics from benchmark comparisons show an average improvement in F1 scores by around 10–15%, underscoring the enhanced precision and reliability of Contextual Assertion in healthcare data analysis.
Spark NLP & LLM
The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. This library provides over 2,200 pre-trained models and pipelines tailored for medical data, enabling accurate information extraction, NER for clinical and medical concepts, and text analysis capabilities. Regularly updated and built with cutting-edge algorithms, the Healthcare library aims to streamline information processing and empower healthcare professionals with deeper insights from unstructured medical data sources, such as electronic health records, clinical notes, and biomedical literature.
John Snow Labs’ GitHub repository serves as a collaborative platform where users can access open-source resources, including code samples, tutorials, and projects, to further enhance their understanding and utilization of Spark NLP and related tools.
John Snow Labs also offers periodic training to help users gain expertise in utilizing the Healthcare Library and other components of their NLP platform.
John Snow Labs’ demo page provides a user-friendly interface for exploring the capabilities of the library, allowing users to interactively test and visualize various functionalities and models, facilitating a deeper understanding of how these tools can be applied to real-world scenarios in healthcare and other domains.
Introduction
Assertion status detection in medical NLP aims to classify the assertions made on given medical concepts (e.g. diseases, symptoms) as being present, absent, possible, conditional, hypothetical, or associated with someone else (family member) in the patient’s clinical notes or reports.[1][2][4] The key assertion classes are:
- Present: The medical concept definitely exists or has occurred for the patient.
- Absent: The medical concept does not exist or has never occurred for the patient.
- Possible: There is some uncertainty about whether the concept exists or not.
- Conditional: The concept exists or occurs only under certain circumstances.
- Hypothetical: The concept may develop or occur for the patient in the future.
- Past: The concept is related to a past condition, treatment, or examination prior to the current encounter.
- Family: The concept is associated with a family member rather than the patient.[1]
Accurately detecting these assertions is crucial, as negated or uncertain mentions of medical concepts can significantly impact diagnosis and treatment decisions.[3][4] For example, detecting that a symptom is absent or just possible can prevent misdiagnosis.
Sources
[1] Detect Assertion Status (assertion_jsl) | Healthcare NLP 3.1.2
[2] Assertion detection in Text Analytics for health — Azure AI services
[3] Assertion Detection in Clinical Natural Language Processing
[4] Assertion Detection in Clinical Notes: Medical Language Models to …
[5] [PDF] Assertion Detection in Clinical Natural Language Processing using …
Here is the sample text and result:
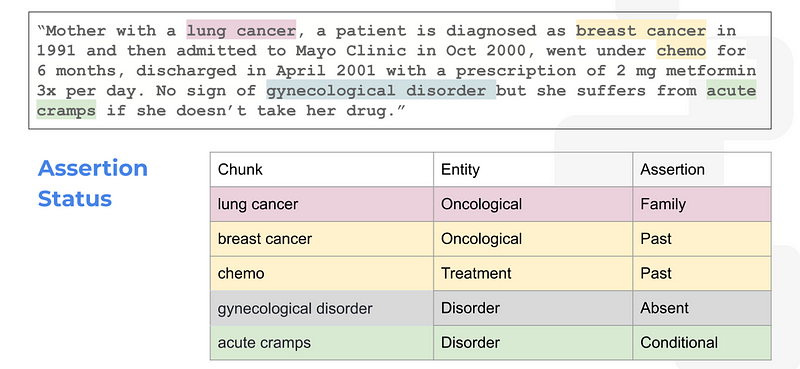
You can access all assertion models from the John Snow Labs’ Models Hub
These are pretrained models with AssertionDL (A Deep Learning based approach used to extract Assertion Status from extracted entities and text).

Contextual Assertion
Understanding the context of textual data is critical in the field of Natural Language Processing (NLP), particularly in clinical settings where patient care can be directly impacted by the accuracy of medical record interpretation. Contextual signals that offer important information about the patient’s history, symptoms, and diagnosis include denial, uncertainty, and assertion. This blog post will explore the process of identifying and annotating these cues using a contextual assertion, with an emphasis on managing negation and past events in clinical texts.
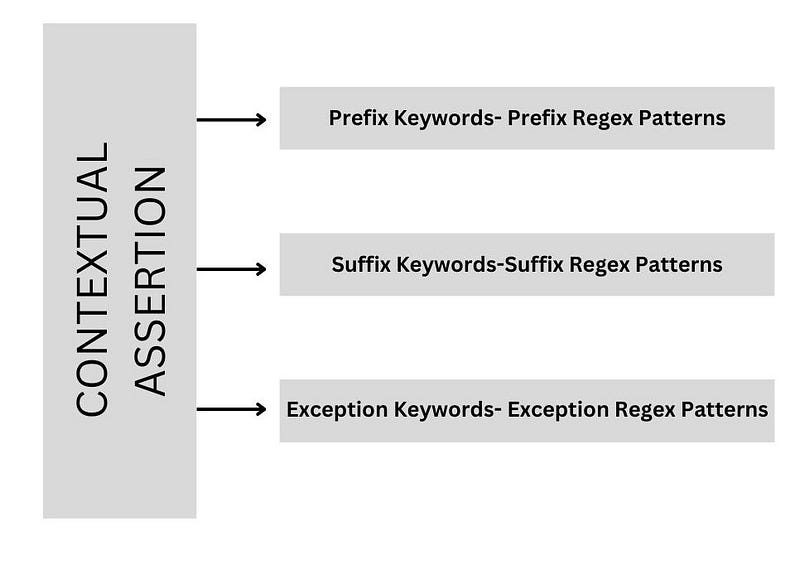
Let’s explore constructing a complete pipeline to extract all necessary information in the end.
Sample Clinical Text:
text = """ Patient resting in bed. Patient given azithromycin without any difficulty. Patient has audible wheezing, states chest tightness.No evidence of hypertension. Patient denies nausea at this time. Zofran declined. Patient is also having intermittent sweating associated with pneumonia. Patient refused pain but tylenol still given.Alcoholism unlikely. Patient has headache and fever. Patient is not diabetic. Not clearly of diarrhea. Lab reports confirm lymphocytopenia. Cardiac rhythm is Sinus bradycardia. Patient also has a history of cardiac injury. No kidney injury reported. No abnormal rashes or ulcers. Patient might not have liver disease. Confirmed absence of hemoptysis. Although patient has severe pneumonia and fever, test reports are negative for COVID-19 infection. COVID-19 viral infection absent. """
Pipeline:
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence_detector = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
tokenizer = Tokenizer() \
.setInputCols(["sentence"]) \
.setOutputCol("token")
word_embeddings = WordEmbeddingsModel \
.pretrained("embeddings_clinical", "en", "clinical/models") \
.setInputCols(["sentence", "token"]) \
.setOutputCol("embeddings")
clinical_ner = MedicalNerModel \
.pretrained("ner_clinical", "en", "clinical/models") \
.setInputCols(["sentence", "token", "embeddings"]) \
.setOutputCol("ner")
ner_converter = NerConverter() \
.setInputCols(["sentence", "token", "ner"]) \
.setOutputCol("ner_chunk")
contextual_assertion = ContextualAssertion()\
.setInputCols("sentence", "token", "ner_chunk") \
.setOutputCol("assertion") \
flattener = Flattener() \
.setInputCols("assertion") \
.setExplodeSelectedFields({"assertion":["metadata.ner_chunk as ner_chunk",
"begin as begin",
"end as end",
"metadata.ner_label as ner_label",
"result as result"]})
pipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
tokenizer,
word_embeddings,
clinical_ner,
ner_converter,
contextual_assertion,
flattener
])
sample_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(sample_df).transform(sample_df).show(truncate= False)
Output:
+------------------+-----+---+---------+----------------+ |ner_chunk |begin|end|ner_label|assertion_result| +------------------+-----+---+---------+----------------+ |any difficulty |59 |72 |PROBLEM |absent | |hypertension |149 |160|PROBLEM |absent | |nausea |178 |183|PROBLEM |absent | |zofran |199 |204|TREATMENT|absent | |pain |309 |312|PROBLEM |absent | |tylenol |318 |324|TREATMENT|absent | |Alcoholism |428 |437|PROBLEM |absent | |diabetic |496 |503|PROBLEM |absent | |kidney injury |664 |676|PROBLEM |absent | |abnormal rashes |691 |705|PROBLEM |absent | |ulcers |710 |715|PROBLEM |absent | |liver disease |741 |753|PROBLEM |absent | |hemoptysis |777 |786|PROBLEM |absent | |COVID-19 infection|873 |890|PROBLEM |absent | |viral infection |902 |916|PROBLEM |absent | +------------------+-----+---+---------+----------------+
With using Contextual Assertion in default parameters, we detected the negation of clinical conditions. Upon examining the results, it was found that Tylenol, although initially present, was not detected in the final output. To address this issue, we can utilize the scopeWindow parameter. By setting the scopeWindow to [2, 2]—which means looking at 2 tokens to the left and 2 tokens to the right—we can achieve more accurate assertions and prevent such omissions.
Scope Window
With this feature, we can determine how many tokens will be searched for the desired regex and keywords in the clinical condition found, that is, on the left and right of the ner chunk. If no assignment is made to the scope window, it looks at the entire sentence by default.
Now let’s change our text a little and give our contextual assertion parameters to detect clinical conditions that have occurred in the past and label them as past.
Sample Clinical Text:
text = """ Patient given azithromycin last month. Patient has audible wheezing yesterday. Patient is also having intermittent sweating associated with pneumonia. Before, patient refused pain. Last year, alcoholism unlikely. Patient has headache and fever. Patient is not diabetic. Not clearly of diarrhea. """
Modified Version of Contextual Assertion:
pattern = '(?:yesterday|last\s(?:night|week|month|year|Monday|Tuesday|Wednesday|Thursday|Friday|Saturday|Sunday)|(?:a|an|one|two|three|four|five|six|seven|eight|nine|ten|several|many|few)\s(?:days?|weeks?|months?|years?)\sago|in\s(?:\d{4}|\d{1,2}\s(?:January|February|March|April|May|June|July|August|September|October|November|December)))'
contextual_assertion = ContextualAssertion() \
.setInputCols(["sentence", "token", "ner_chunk"]) \
.setOutputCol("assertion") \
.setPrefixKeywords(["before", "past"]) \
.setSuffixKeywords(["before","past"]) \
.setPrefixRegexPatterns([pattern]) \
.setSuffixRegexPatterns([pattern]) \
.setScopeWindow([5,5])\
.setAssertion("past")
flattener = Flattener() \
.setInputCols("assertion") \
.setExplodeSelectedFields({"assertion":["metadata.ner_chunk as ner_chunk",
"begin as begin",
"end as end",
"metadata.ner_label as ner_label",
"result as result"]})
Output:
+----------------+-----+---+---------+------+ |ner_chunk |begin|end|ner_label|result| +----------------+-----+---+---------+------+ |azithromycin |15 |26 |TREATMENT|past | |audible wheezing|52 |67 |PROBLEM |past | |pain |176 |179|PROBLEM |past | |alcoholism |193 |202|PROBLEM |past | +----------------+-----+---+---------+------+
In this example, to identify chunks related to the past, we provided specific regex patterns and keywords to the Contextual Assertion component. We also set a broad scope of [5, 5]. Additionally, if case sensitivity is important, we can set the caseSensitive parameter to true (the default value is false).
As seen in the output above, all clinical conditions in the past could be detected.
Scope Window Delimiters
Delimiters are specific characters or keywords used to define the boundaries of a text, aiding limiting the scope of operations. You can set delimiters with the setScopeWindowDelimiters method.
“ There is no gastroenteritis here, we do care about heart failure “
For example, in the sentence above, if the scopeWindowDelimiter is set to a comma, the text will not be searched for the “heart failure” chunk before the comma.
Include Chunk To Scope
If you want the chunk itself to be included in the search within the text, you can enable this property by using the setIncludeChunkToScope method.
Exceptions
We can prevent unwanted patterns by using the setExceptionKeywords and setExceptionRegexPatterns methods. In the usage of Contextual Assertion in default mode, Exception Patterns for Negex are used.
Usage with AssertionDL
Alternatively, we have another assertion detection technique that we call AssertionDL, which utilizes Deep Learning to determine assertion status. The Healthcare NLP library includes over 150 assertion models & pipelines in Models Hub. For more information, please refer to the Annotator Page on Website and the Notebook to learn more about that.
To improve the performance of underperforming assertions in AssertionDL, we can leverage Contextual Assertion techniques and combine the results using an Assertion Merger.
Here’s how you can achieve this:
Sample Text:
text = """Patient has a family history of diabetes. Father diagnosed with heart failure.Sister and brother both have asthma.Grandfather had cancer in his late 70s.No known family history of substance abuse. Family history of autoimmune diseases is also noted."""
Pipeline :
#AssertionDL
clinical_assertion = AssertionDLModel.pretrained("assertion_dl_large", "en", "clinical/models") \
.setInputCols(["sentence", "ner_chunk", "embeddings"]) \
.setOutputCol("assertion")\
.setEntityAssertionCaseSensitive(False)
#Associated_with_someone_else
contextual_assertion_associated = ContextualAssertion\
.pretrained("contextual_assertion_someone_else", "en", "clinical/models") \
.setInputCols(["sentence", "token", "ner_chunk"])\
.setOutputCol("assertionAssociated")\
.setCaseSensitive(False)\
.setAssertion("someone_else")\
.setIncludeChunkToScope(True)\
.setScopeWindow([3,3])\
.setExceptionKeywords([])\
#Merger
assertionMerger = AssertionMerger()\
.setInputCols("assertionAssociated","assertion")\
.setOutputCol("assertion_merger")\
.setMergeOverlapping(True)\
.setAssertionSourcePrecedence("assertionAssociated,assertion")\
.setOrderingFeatures(["source"])
Prioritization can be made between incoming assertions with the assertion merger in the setAssertionSourcePrecedence method.
Comparing the Results of AssertionDL Alone vs. AssertionDL Combined with Contextual Assertion:
Output of Using Contextual Assertion and AssertionDL together:
+-------------------+-----+---+---------+------------+ |ner_chunk |begin|end|ner_label|result | +-------------------+-----+---+---------+------------+ |diabetes |32 |39 |PROBLEM |someone_else| |heart failure |64 |76 |PROBLEM |someone_else| |asthma |108 |113|PROBLEM |someone_else| |cancer |142 |147|PROBLEM |someone_else| |substance abuse |193 |207|PROBLEM |someone_else| |autoimmune diseases|228 |246|PROBLEM |someone_else| +-------------------+-----+---+---------+------------+
Output of AssertionDL:
+-------------------+-----+---+---------+------------+ |ner_chunk |begin|end|ner_label|result | +-------------------+-----+---+---------+------------+ |diabetes |32 |39 |PROBLEM |someone_else| |heart failure |64 |76 |PROBLEM |present | |asthma |108 |113|PROBLEM |someone_else| |cancer |142 |147|PROBLEM |someone_else| |substance abuse |193 |207|PROBLEM |someone_else| |autoimmune diseases|228 |246|PROBLEM |someone_else| +-------------------+-----+---+---------+------------+
A key difference observed in the results is that heart failure, which should be categorized as someone_else in the assertions, is mistakenly identified as present in the assertionDL results. This highlights that Contextual Assertion provides more accurate results in such scenarios.
Benchmarks

Dataset: assertion_oncology_smoking_status_wip
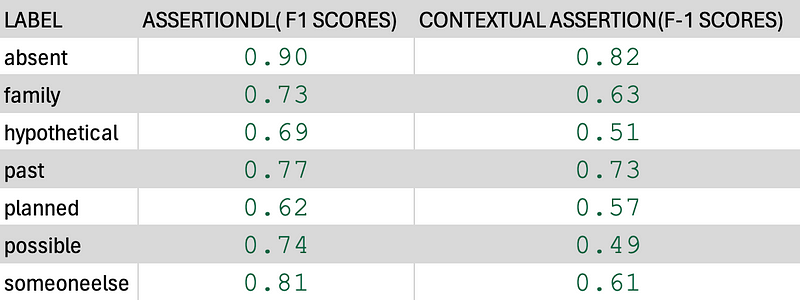
Dataset: assertion_jsl_augmented_38k
Based on the results, Contextual Assertion performed better on dataset assertion_oncology_smoking_status_wip, while assertionDL achieved higher accuracy rates on dataset assertion_jsl_augmented_38k.
It’s great to see that Contextual Assertion achieves comparable metrics on test sets only by using the rules we specified, without even seeing anything from the training set. You can customize the contextual assertion model further with your own rules and the patterns in your dataset and achieve even higher metrics.
Conclusion
Contextual Assertion, a powerful component within Spark NLP, extends beyond mere negation detection. Its ability to identify and classify a diverse range of contextual cues, including uncertainty, temporality, and sentiment, empowers healthcare professionals to extract deeper meaning from complex medical records.





