
























































If you’re working on annotation projects today, you’ve likely noticed the pressure mounting. Deadlines are tighter. Quality expectations are higher. And you’re expected to do more with less — often while validating outputs from AI models that sometimes feel like they’re making up answers.
The landscape of text annotation has fundamentally changed. What was once primarily about labeling datasets for model training has evolved into human-in-the-loop (HITL) workflows: continuous cycles where human experts validate, correct, and refine AI-generated outputs to ensure accuracy, reduce bias, and maintain contextual appropriateness.
If you’re an annotator, project manager, or team lead navigating this shift, this article breaks down what actually matters in modern annotation platforms and how to get up to speed faster than spending months learning through trial and error.
Why Human-in-the-Loop Annotation Still Matters
With large language models now capable of generating their own annotations, summaries, and extractions, it’s reasonable to ask whether manual annotation still matters. The answer is YES, but the role has fundamentally shifted.
We all know that the most advanced Large Language Models (LLMs) make mistakes. They hallucinate facts, misclassify sentiment, miss critical context, or introduce subtle biases. And they do it at scale.
Modern annotation isn’t just about creating training data anymore. It’s about:
- Human-in-the-loop validation of generative outputs to ensure accuracy and appropriateness
- Auditing auto-generated annotations to catch errors before they propagate through production systems
- Training specialized models that outperform general-purpose LLMs on domain-specific tasks
- Building feedback loops that enable continuous model improvement through expert corrections
High-quality annotations, especially those created by domain experts, remain the foundation of safe, accurate, and production AI. They enable organizations to move beyond “good enough” general models toward tailored systems that are faster, more cost-effective, and better aligned with real-world requirements.
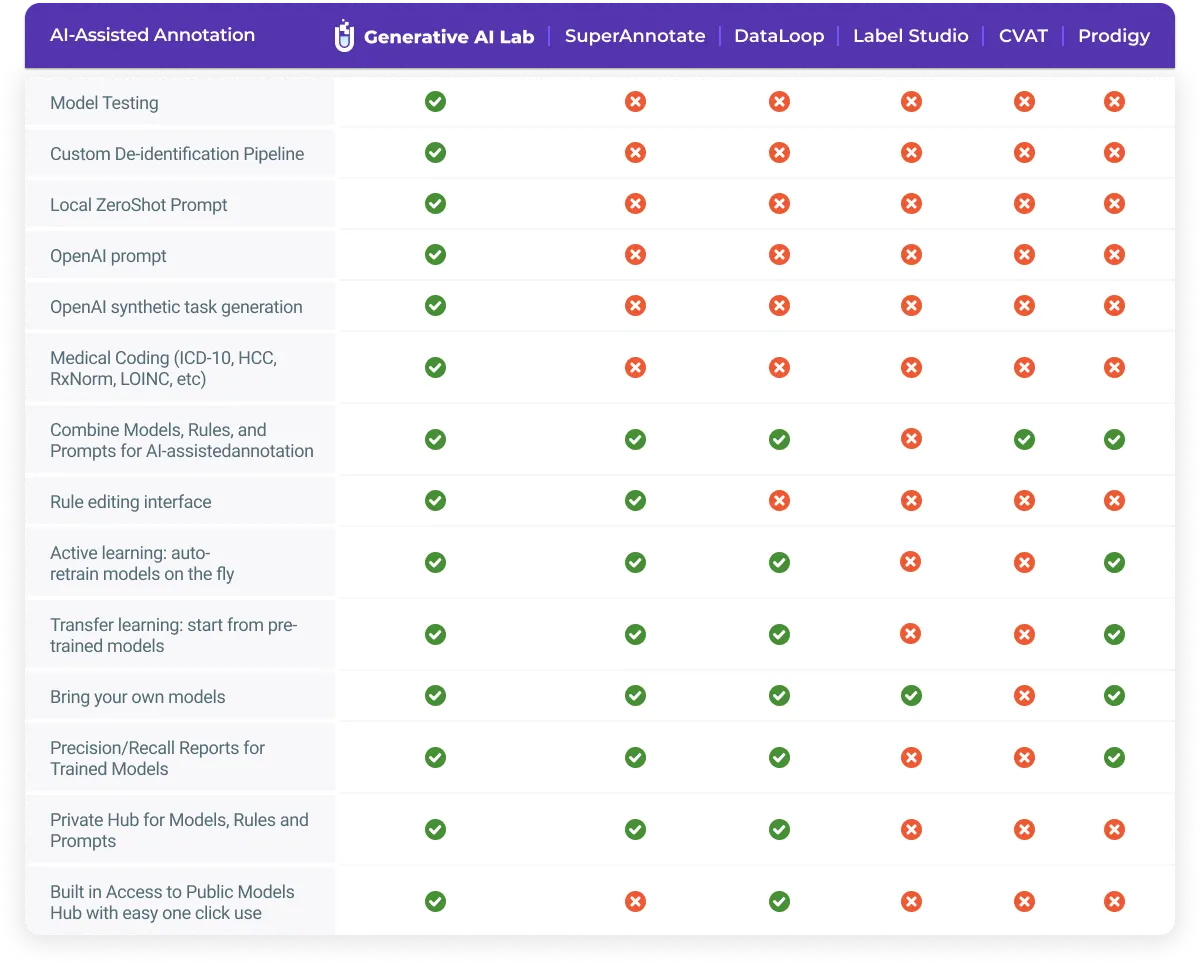
What to Look for in an Annotation Platform
As HITL workflows become more sophisticated, the tools need to keep pace. The best modern platforms combine several key capabilities:
- AI-Assisted Pre-Annotation
Starting from scratch on every document is inefficient. Effective tools leverage pre-trained models, rules, or prompts to suggest initial annotations. Annotators then review and correct these suggestions rather than labeling everything manually.
This approach can accelerate annotation by 10x or more while maintaining quality through human oversight — the essence of effective HITL systems.
- Clear Guidelines and Quality Control
Inconsistent annotations undermine model performance. Platforms that support detailed annotation guidelines, attached directly to each label, help teams maintain consistency across projects.
Built-in quality tracking, inter-annotator agreement metrics, and review workflows ensure problems are caught early, not after thousands of labels have been created.
- Blind Testing and Consensus Analysis
One of the most powerful recent developments in annotation platforms is blind testing — the ability to present multiple model outputs or annotation options to reviewers without revealing which system generated which result.
This eliminates confirmation bias and brand preference. Instead of favoring outputs from “the expensive model” or “the model we built in-house,” reviewers evaluate quality objectively based on accuracy, completeness, and contextual appropriateness.
Blind testing is particularly valuable for:
- Comparing multiple LLM outputs (GPT-4 vs. Claude vs. domain-specific models)
- Validating that expensive general-purpose models actually outperform smaller, specialized alternatives
- Building consensus among annotators on subjective tasks
- Identifying where human judgment differs from automated predictions
Platforms with built-in blind testing and consensus analysis make it easy to run these evaluations systematically rather than relying on anecdotal impressions.
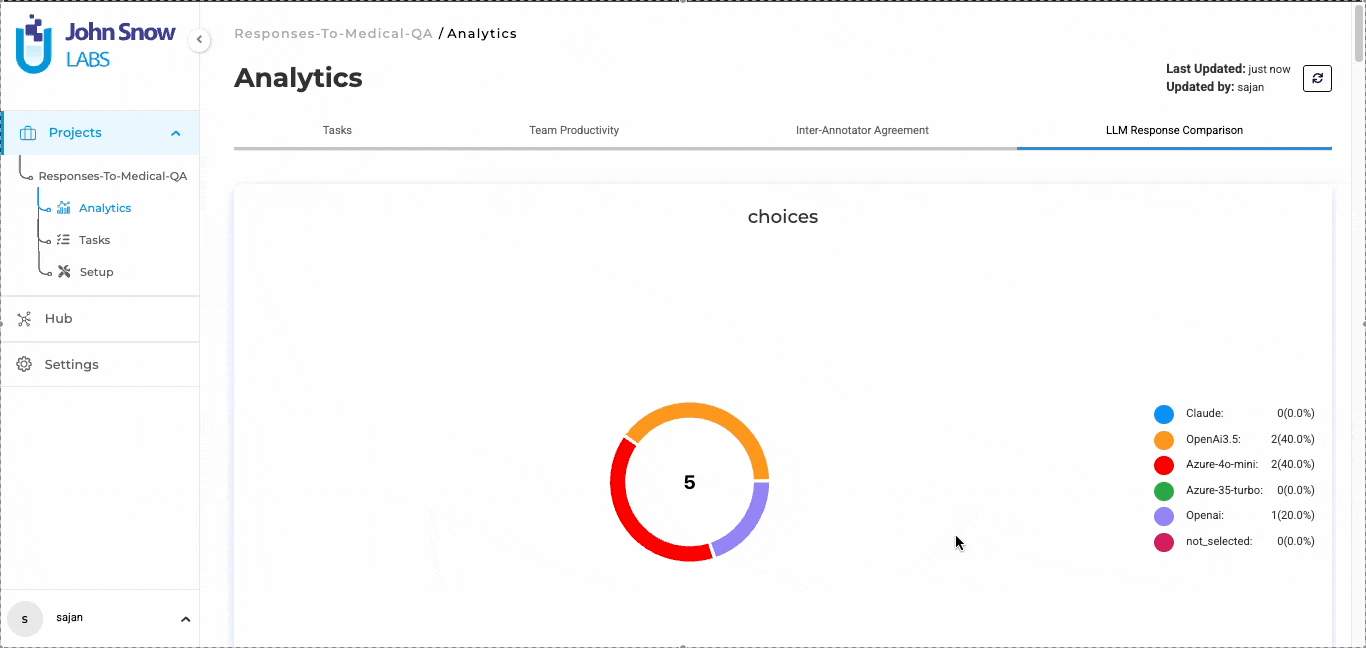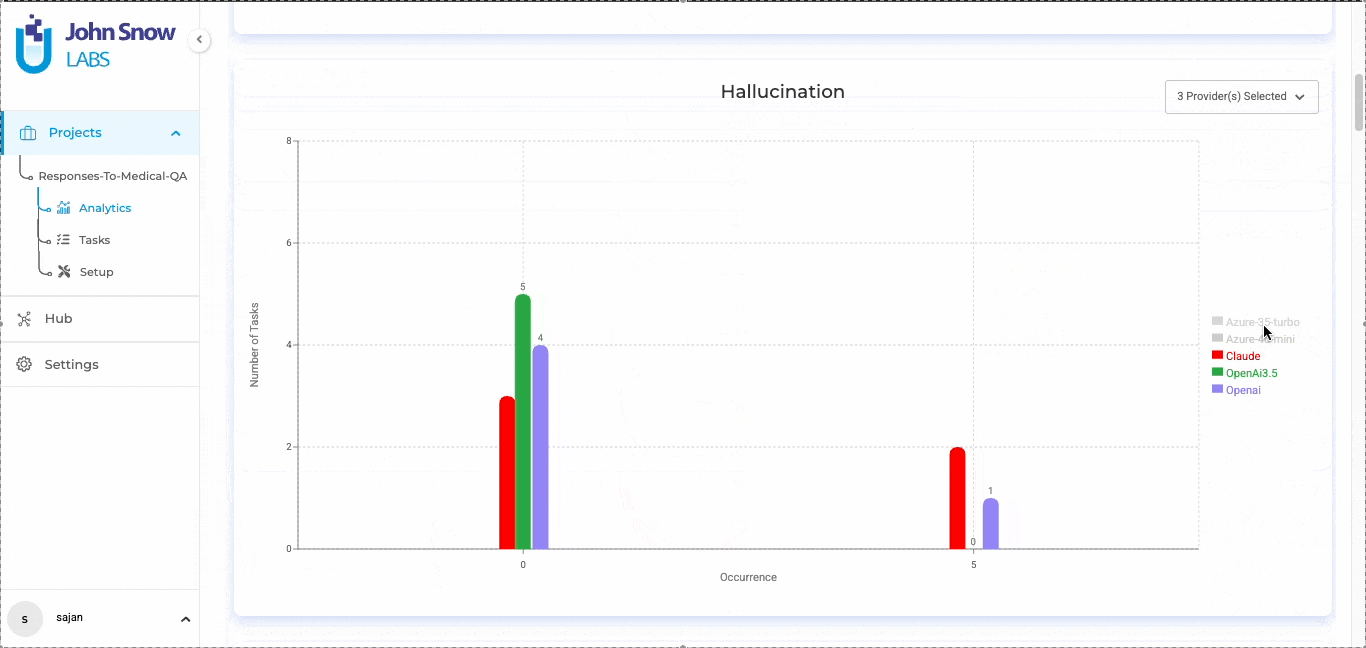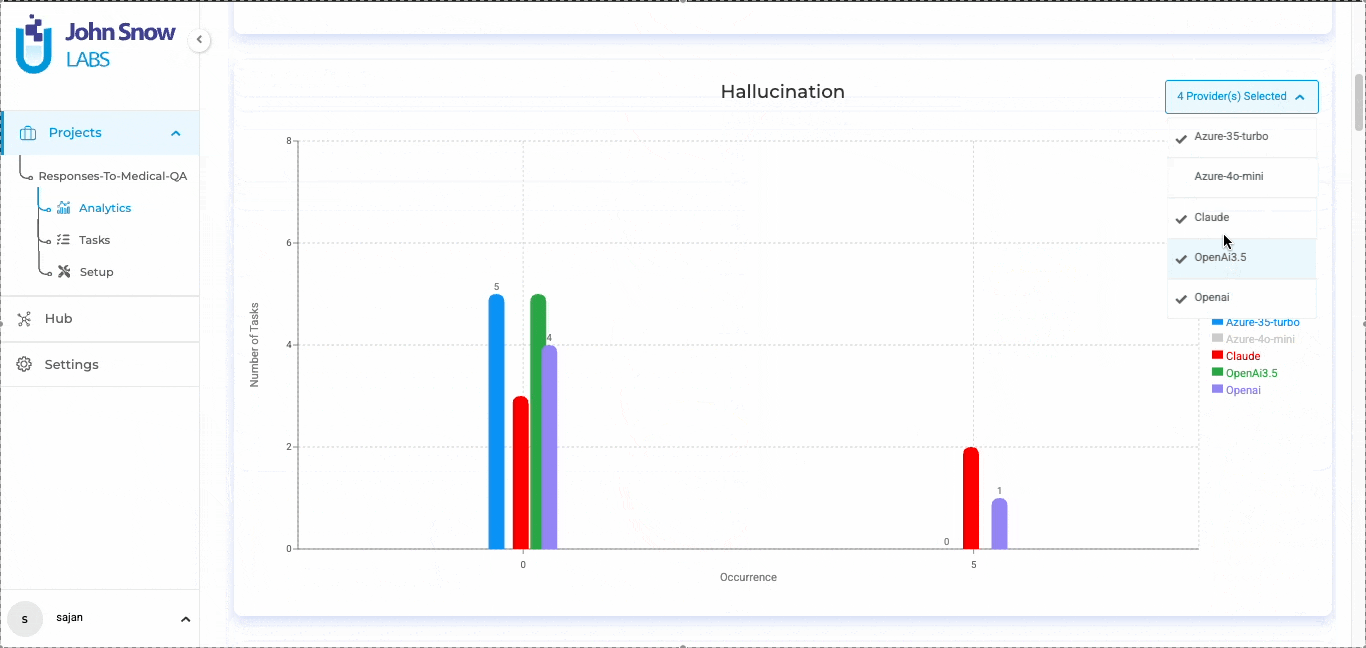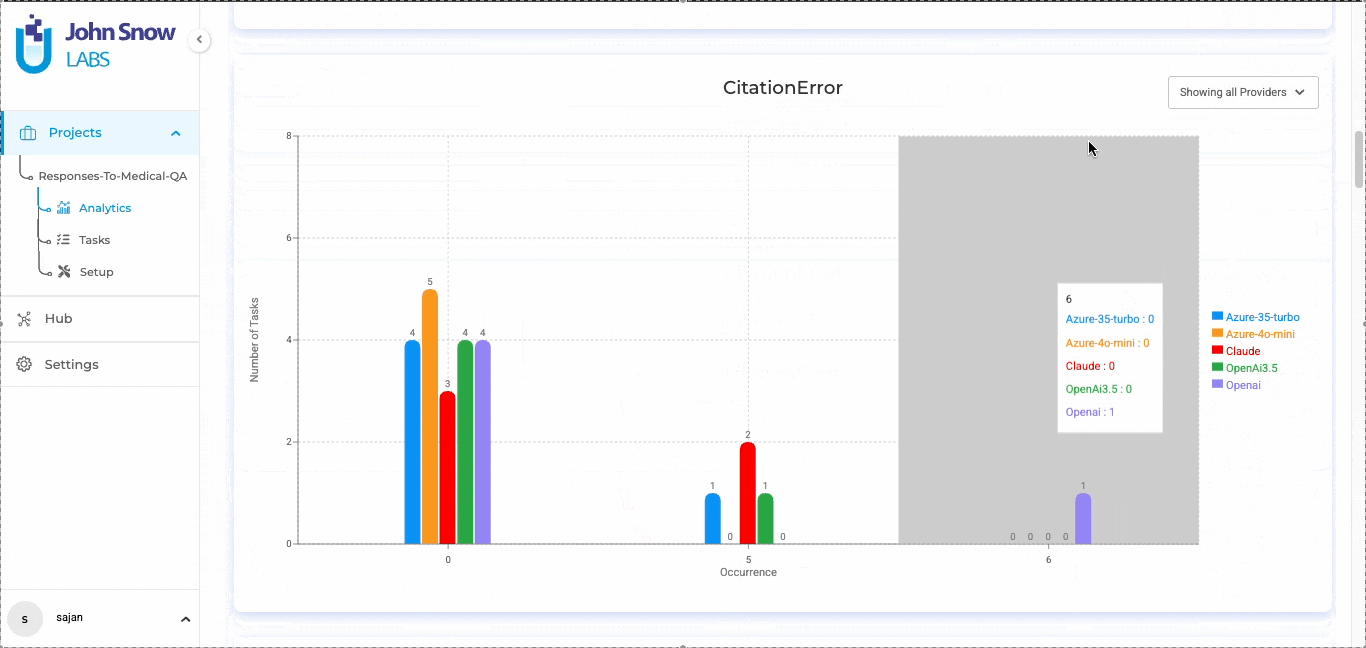
LLM evaluation in Generative AI Lab
- No-Code Model Training
Not every team has machine learning engineers and data scientists hanging out around. Platforms that enable domain experts to train custom models without writing code democratize AI development.
This is particularly valuable in specialized domains such as healthcare, legal, and finance, where subject-matter expertise is more critical than programming skills. With as few as 40–50 examples per label, domain experts can create models that outperform general-purpose LLMs on their specific tasks.
- Robust Testing and Evaluation
Accuracy on a test set isn’t enough. Production-ready models need comprehensive evaluation for bias, fairness, robustness, and real-world performance.
The best tools include automated testing frameworks that run dozens of checks — adversarial attacks, edge cases, demographic parity — before models reach production. Some platforms even auto-generate augmented data to retrain models on identified weaknesses, closing gaps without manual intervention.
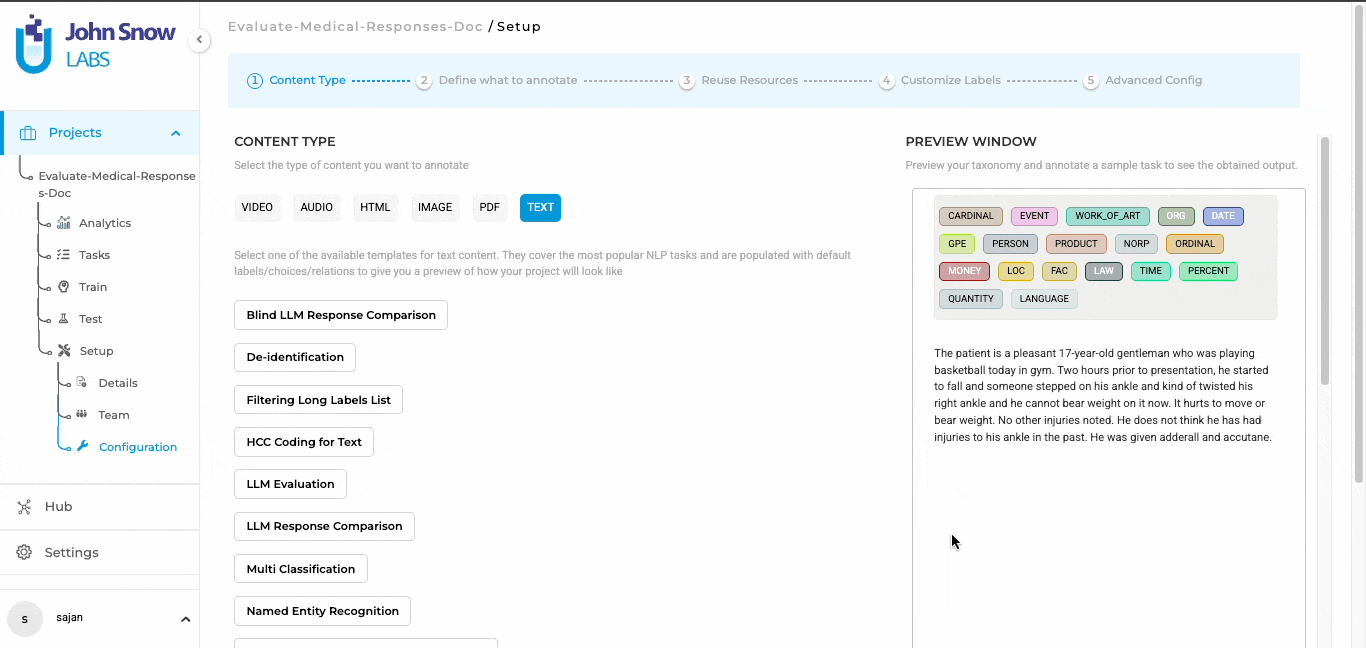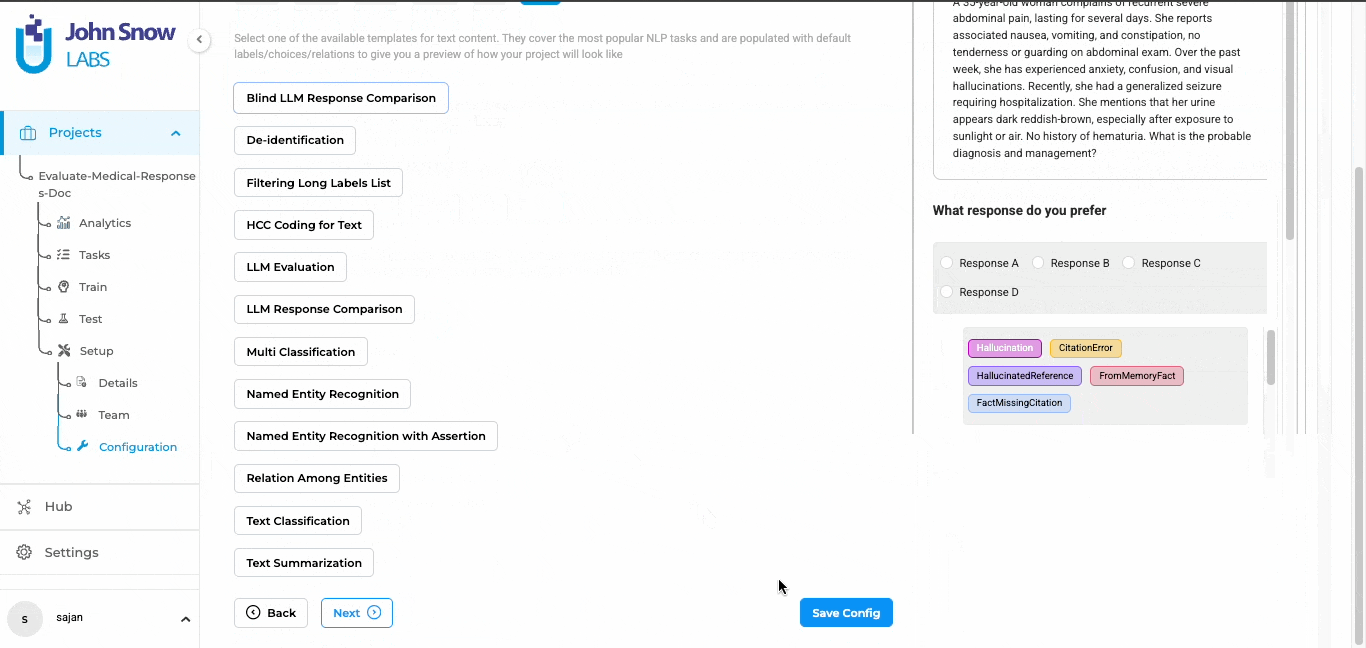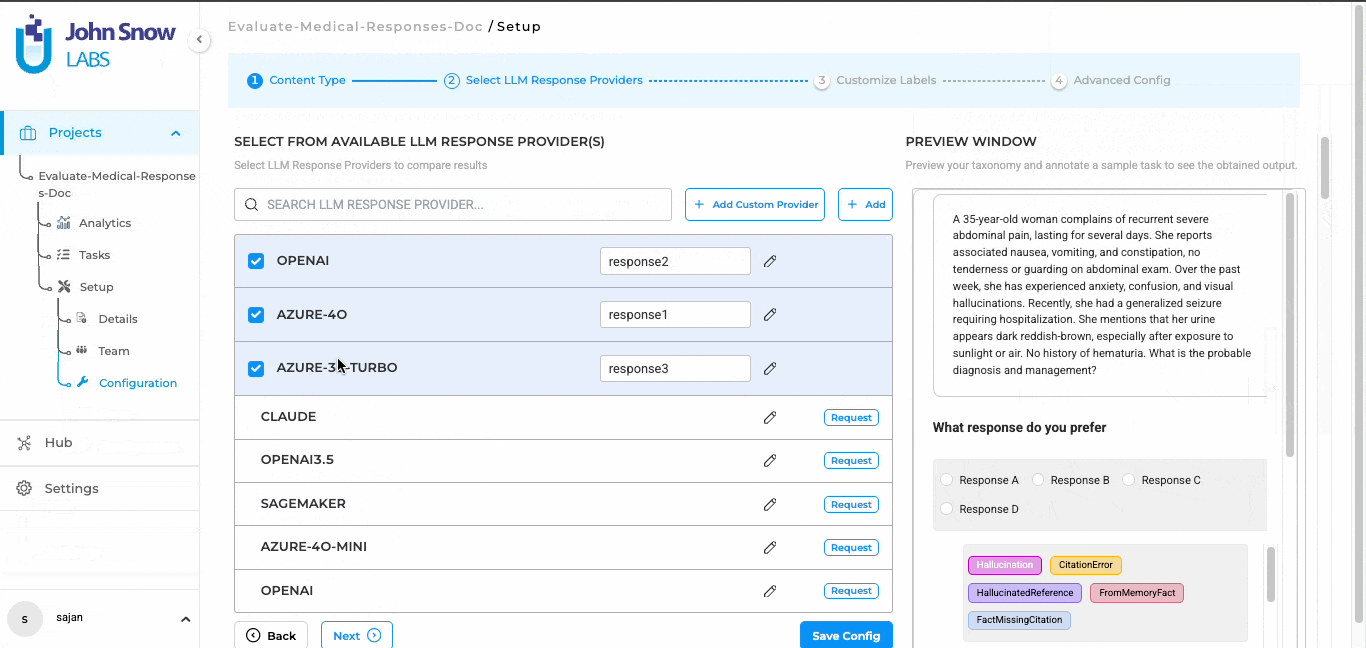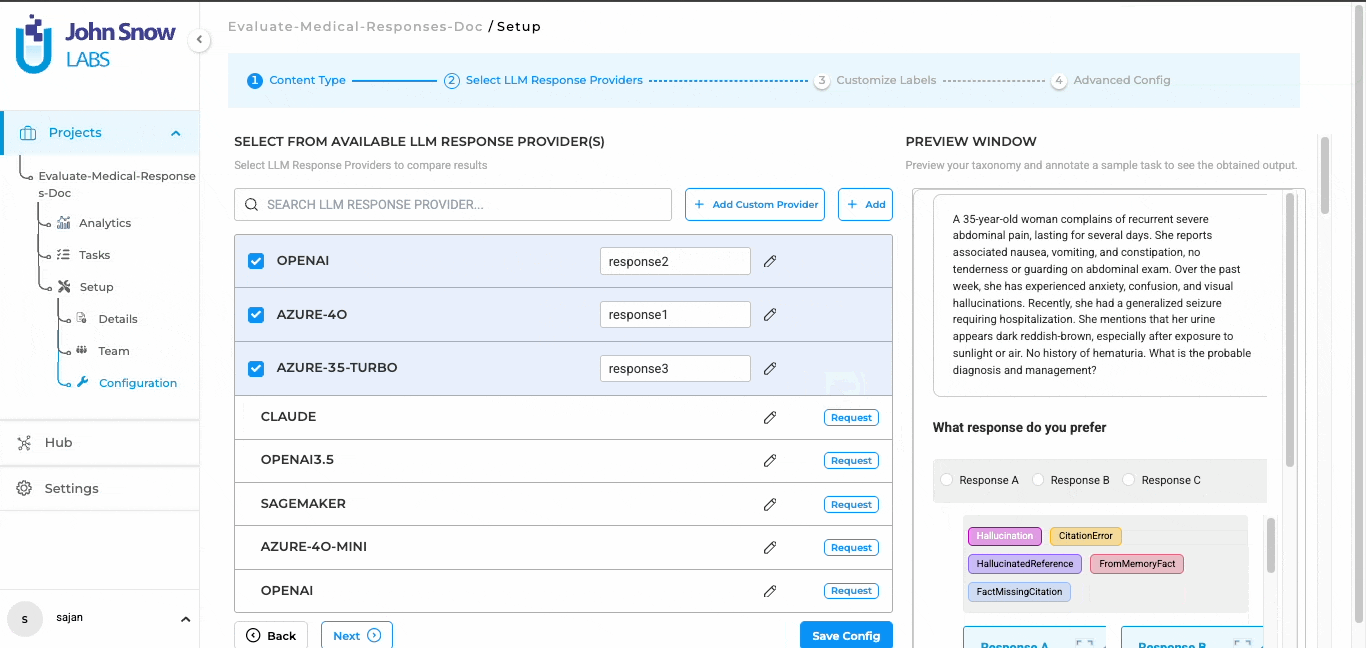
Blind testing in Generative AI Lab
- Enterprise Security and Compliance
For regulated industries, security isn’t optional. Look for platforms with:
- On-premises or air-gapped deployment options
- Role-based access controls and audit trails
- SSO integration and annotation versioning
- De-identification capabilities for sensitive data (PHI/PII)
These features ensure your annotation workflows meet regulatory requirements like HIPAA, GDPR, and SOC2 compliance.

Regulatory Requirements
The Learning Curve Challenge
Even with the right tool, teams often face a steep learning curve. Common pitfalls include:
- Writing vague annotation guidelines that lead to inconsistent labels
- Skipping quality checks until problems become systemic
- Not leveraging pre-annotation features effectively
- Failing to set up blind testing workflows that eliminate bias
- Insufficient model testing before deployment
Most teams learn these lessons through trial and error over months. Projects get delayed. Annotations need to be redone. Quality suffers.
A Faster Path Forward
This is where hands-on training makes a difference. The Beyond Data Annotation with Generative AI Lab tutorial takes a practical, show-don’t-tell approach to HITL annotation workflows.
It covers the full lifecycle of an annotation project:
- Setting up projects correctly from the start. How to structure data, define tasks, and configure workflows that scale across teams.
- Writing annotation guidelines that work. Creating clear, unambiguous rules with examples that prevent misinterpretation and maintain inter-annotator agreement.
- Handling data safely. Automated de-identification techniques for PHI and PII that maintain data utility while ensuring compliance.
- Leveraging AI-assisted annotation. Using pre-trained models and prompts to accelerate labeling without sacrificing quality in HITL workflows.
- Running blind tests and consensus analysis. Setting up unbiased evaluation workflows where annotators review outputs without knowing which model generated them — critical for objective model comparison.
- Training custom models without code. How domain experts can build specialized models on as few as 40–50 examples per label, then deploy them for production use.
- Testing models comprehensively. Running automated evaluations for accuracy, bias, fairness, and robustness before production deployment — including auto-generated test cases and data augmentation.
This approach compresses months of learning into an afternoon. No coding background is required. The focus is on practical skills that apply regardless of technical expertise.
The Bottom Line
Annotation has evolved from a one-time labeling task to human-in-the-loop systems that continuously validate, refine, and improve AI models. The tools have evolved too—combining automation, blind testing, teamwork insights, and rigorous evaluation on a single platform.
But tools alone aren’t enough. Understanding how to use them effectively — how to write good guidelines, leverage pre-annotation, eliminate bias through blind testing, maintain quality, and test comprehensively — makes the difference between projects that drag on for months and those that ship on time with high-quality results.
Hands-on training offers a shortcut through the learning curve. Ninety minutes of focused, practical instruction can save weeks or months of trial and error.
For teams building human-in-the-loop AI systems, that’s time well spent.




