

























































Motivation
John Snow Labs’ main promise to the healthcare industry is that we will keep you at the state of the art. We’ve reimplemented our core algorithms every year since 2017 – migrating to BERT, then BioBERT, then our own fine-tuned language models, then token classification & sequence classification models, then zero-shot learning, and recently end-to-end visual document understanding and speech recognition. Our biggest customers work for us to be future-proof – because unlike others we do not advocate of stick to a specific technology or approach, but instead evolve quickly to productize the best-performing techniques as they become available.
As such, we regularly try and benchmark new papers, models, libraries, or services that come out claiming new capabilities in healthcare NLP. This includes recently released models like ChatGPT and BioGPT. Since we get asked about them a lot, this blog post summarizes early findings in benchmarking them versus current state-of-the-art models for medical natural language processing tasks: named entity recognition, relation extraction, assertion status detection, entity resolution, and de-identification.
TL;DR: We do not recommend these models for production use today. They are impressive research advances, and we use them internally to bootstrap smaller and more accurate models, but they are not fit for the vast majority of real-world use cases.
What are the issues?
Simply put, ChatGPT doesn’t do what you need it to:
- In our internal evaluations of such models, they significantly lag in accuracy compared to current state-of-the-art models. Precision ranged between 0.66 to 0.86, and recall was particularly problematic at between 0.40 and 0.52. This means that the human abstractors you have in place will still have to read the entire documents, resulting in minimal time & cost savings for you.
- There is no way to tune and provide feedback to these models. While they are very fast to bootstrap, you cannot tune ChatGPT, meaning that these models won’t improve over time based on feedback from your abstractors (or the many historical documents you’ve already abstracted). This is critical in healthcare systems, where models have to be localized due to differences in clinical guidelines, writing styles, and business processes.
- These models are far slower and more expensive to run than their productized & more accurate counterparts. The cost of a single ChatGPT query is estimate to be $0.36. Given the length of typical patient stories, this implies paying tens of dollars in computing costs alone to analyze a single cancer patient’s story. Beyond hardware costs, there is also the issue of clock time: For example, reproducing clinical NER benchmarks on Facebook’s Galactica model required 4 hours to process a single 2-page note on a machine with 8 GPUs.
- These models are not regularly updated. They are typically not retrained (new versions come out instead), or retrained annually. This means that you’ll be missing new clinical terms, medications, and guidelines – with no ability to tune or train these models.
- There is no support for visual documents – operating on scanned documents or images at all. This means that a portion of the work that is often required in real-world use cases – like clinical abstraction, clinical decision support, or real-world data – will remain manual, and as a result, the overall result will require a separate OCR pipeline or have to remain manual (since the models won’t be able to consider both text & images together when providing answers or recommendations).
- There is no pre-processing pipeline. Clinical text like EHR records includes about 50% copy-and-pasted content, sections, and multiple pages. This has to be normalized first; note that the exact same sentence can mean different things if it’s under “chief complaint”, “history of present illness”, or “plan”. You’ll need to build that yourself as well, instead of using a pre-built & widely validated solution. Like scanned documents, this will also have to be built in a custom way outside the large language models.
- Models like GPT-3 or ChatGPT require calling a cloud API – and sharing your data with the company providing them. Even if the setup becomes HIPAA compliant, and even if you’re allowed to share the data that way, you’re providing that company with the intellectual property needed to train & tune better clinical models, instead of building that intellectual property internally by privately tuning your own oncology abstraction models (which is how John Snow Labs’ software & license works).
Zero-Shot Learning
The good news is that you can get the benefits of prompt engineering right now with John Snow Labs, without these downsides. There are three first-to-market features that are already available and in use by early adopters to build production-grade, accurate, tunable, scalable, private, cheaper to run, kept current, healthcare-tuned, and compliant NLP solutions.
First, Zero-shot named entity recognition and zero-shot relation extraction enable you to extract custom entities and relationships from medical text without any training, tuning, or data labeling. This is useful when your goal is to optimize go-to-market time over accuracy – i.e. can I get a model that’s 80% accurate today, instead of a model that’s 95% accurate in 3 months? For example, if you’re automating the process of creating a cancer registry, then you may wish to invest to optimize the models for fields relating to tumor staging & histology, but go with zero-shot models for the 400+ rarely filled data fields.
Models based on Longformer, Albert, Bert, CamemBert, DeBerta, DistillBert, Roberta, and XlmRoberta have been implemented already. John Snow Labs has already progressed a step further than enabling prompt engineering with the automated prompt generation, based on the T5 transformer. This functionality is currently not available in Hugging Face, which only supports zero-shot text classification.
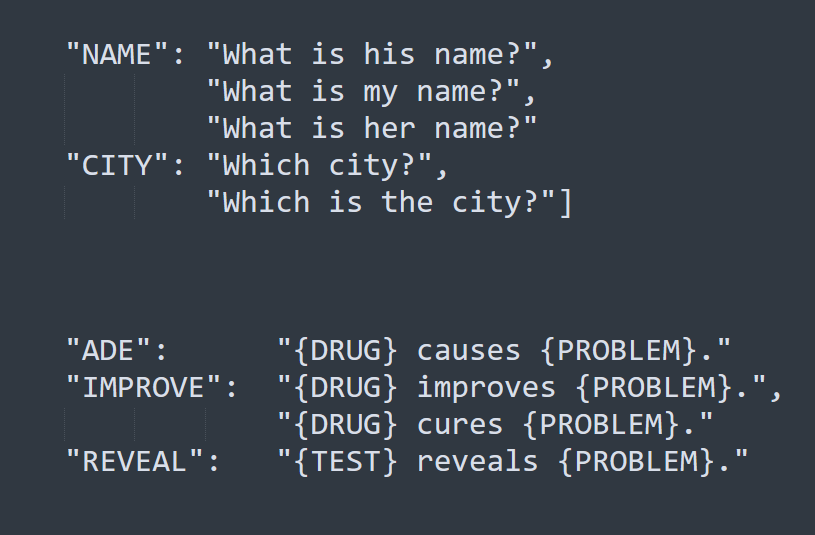
No-Code Prompt Engineering
A second use for zero-shot prompt engineering is to bootstrap higher-accuracy models. Instead of labeling data from scratch, you can pre-annotate data with prompts, after which your domain experts only need to correct what it got wrong. This is similar to what we’ve done with programmatic labeling –we’ve added it to the NLP Lab as another way to bootstrap models, but not as a full replacement.
The NLP Lab lets you seamlessly combine models (transfer learning), rules (programmatic labeling), and prompts (zero-shot learning) to bootstrap NLP model development. This typically makes labeling projects 80%-90% faster than “from scratch” projects. Importantly, the ability to combine models, rules, and prompts for different tasks gives you the best of all worlds, in contrast to systems that focus on AI-assisted labeling with models (i.e. LabelBox), rules (i.e. Snorkel), or prompts (i.e. ChatGPT).
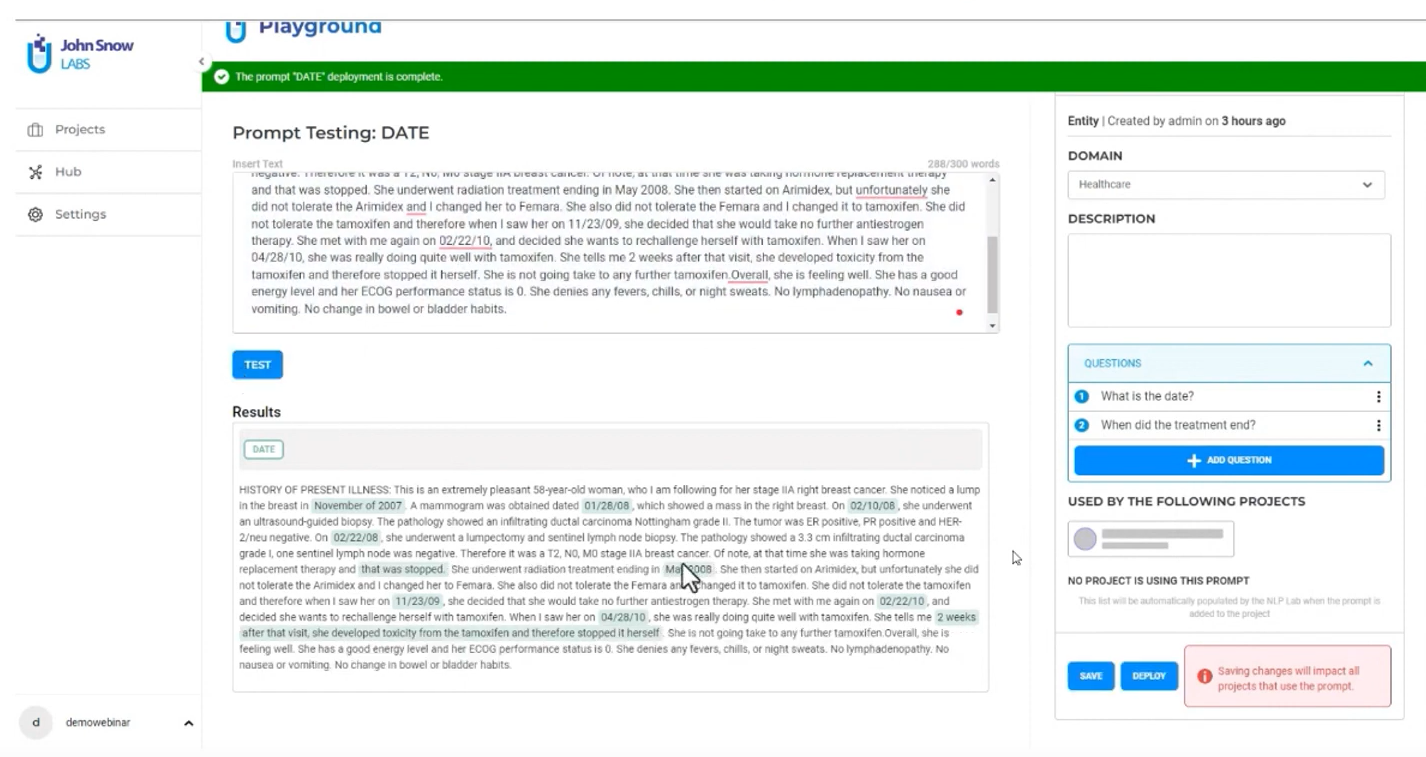
The NLP Lab is the first to market with a user interface intended for non-technical domain experts (i.e. medical doctors use it to train & tune models) that allows you to start with a prompt (or a pre-trained model, or a rule), see how well it performs on real data, provide feedback as needed, and publish that model. That is how you can quickly scale this effort to support a broad range of document types, medical contexts, and entities & relationships to extract. We see other customers already doing the same, and we’ve been doing this internally for a while now. There’s no point in reinventing the wheel by starting from a cloud API and rebuilding this entire workflow and user experience.
Zero-Shot Visual Question Answering
Zero-shot visual question answering is also already available. This model is based on the architecture of Donut: an OCR-free Document Understading Transformer that can answer questions (i.e. do fact extraction) directly from an image or visual document. This does not require any training or tuning. As of October 2022, this architecture delivers state-of-the-art accuracy on a variety of visual document understanding benchmarks covering receipts, invoices, tickets, letters, memos, emails, and business cards – in English, Chinese, Japanese, and Korean.
The supported visual NLP tasks are document classification, information extraction, and question answering. For example, the model can be provided in this image:

And then asked to answer these two questions:
questions = [["When is the Coffee Break?",
"Who is giving the Introductory Remarks?"]]
Without any training or tuning, it will provide these two answers:
answers = [[“11:34 to 11:39 a.m.”,
“lee a. waller, trrf vice presi- ident”]]
Note that these questions require visual understanding in addition to reading the text: The model should implicitly deduce that this image is an agenda of an event, that it’s most likely that the times on the left column state when each event happens, and that if what looks like a person’s name appears next to a topic, it’s most likely that this person is the speaker for that session. This “common sense” knowledge is available out of the box – in a production-grade, scalable, and private library.
What Next?
It is early days for large language models. We expect high-speed innovation to continue – with new entrants building on GPT3, DALL-E, and ChatGPT flooding the commercial & open-source arenas. John Snow Labs will provide you the benefits of these models as you as they’re reliable and ready for prime time in the healthcare & life science industries. We highly recommend that you start using what’s currently available – and welcome feedback and requests. Prompt engineering, No-code, and Responsible AI are the three major NLP trends we’re focused on in 2023 and you’ll see much more in all three areas in the software we’re building for you this year.





