























































Most OCR tools tell you what a document says. That’s fine for search indexing and RAG. But when your workflow needs to act on a specific piece of text (redact a patient name, verify a form field, flag an amount for audit) you also need to know where that text lives on the page.
At John Snow Labs, we built JSL Vision OCR-1B ( jsl_vision_ocr): a 1B on-premise model that extracts text and returns precise bounding-box coordinates for every word (small enough to run on a single T4 GPU).
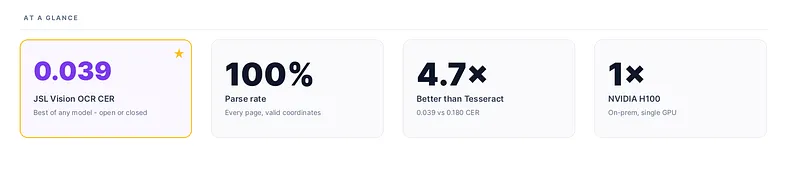
We benchmarked it against 14 competing models, including GPT-5.2, Gemini 2.5 Pro, Claude 4.5, Tesseract, and EasyOCR, on the FUNSD dataset.
JSL Vision OCR came out #1 overall, beating every closed-source frontier model, including Google’s Gemini 2.5 Pro.
What “grounded OCR” looks like
Here’s what it looks like in practice. Input on the left, JSL Vision OCR output on the right:

Every word gets its own bounding box and predicted text. That’s what makes redaction, field extraction, and compliance auditing possible: downstream code can find any specific word and act on its location.
Why “where” matters: grounded OCR
Most OCR models output flat text. That’s fine for search and RAG. Real enterprise workflows need grounded OCR, text extraction with precise bounding-box coordinates:
-
- Medical de-identification: you can’t redact a name if you don’t know where it is on the page
- Form-field extraction: values have to be mapped to specific boxes, not free text
- Compliance auditing: regulators want to see exactly which text was flagged
- Document anonymization: blur or mask a region, not an entire page
We call this BBox OCR: the model reads the text and returns its spatial coordinates.
Not every model can do this. Of the 15 models we benchmarked, 6 cannot emit bounding boxes at all, including popular open-source OCR models like RolmOCR-8B, Nanonets-OCR2, Phi-4-Multimodal, DeepSeek-OCR, and Chandra OCR 2. If your pipeline needs spatial grounding, those models are simply unusable.
The top 3

jsl_vision_ocr wins outright at 0.039 BBox CER with a 100% parse rate. Gemini 2.5 Pro is the closest competitor at 0.053, and Gemini 2.5 Flash rounds out the podium at 0.092, making it the best available closed-source alternative for grounded OCR on a budget.
The full leaderboard
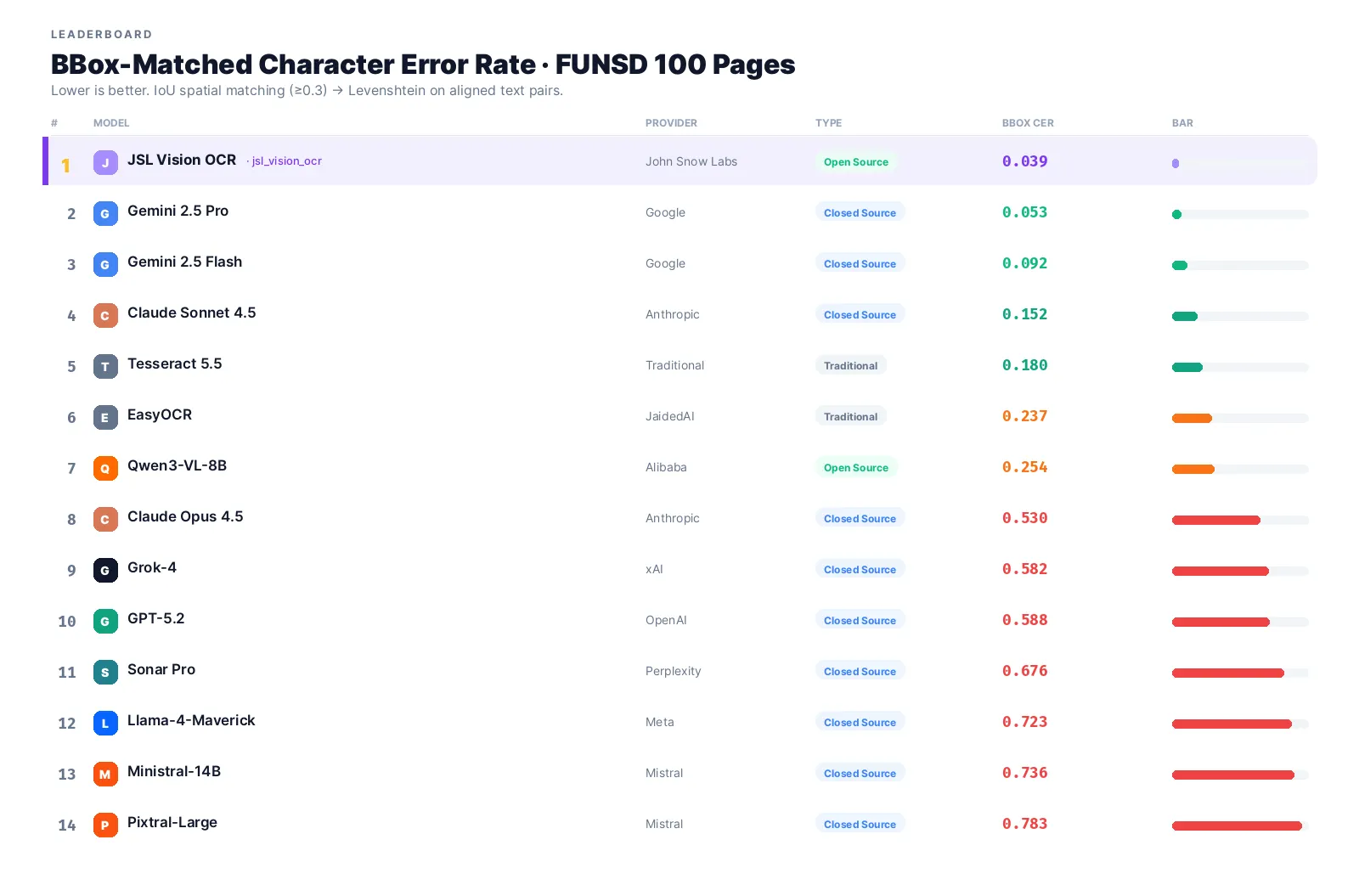
Three things stand out in the data:
Most frontier CS VLMs hallucinate coordinates. GPT-5.2, Grok-4, and Claude Opus all score above 0.5 CER. Their boxes look plausible in the output but don’t correspond to real text positions. For any downstream task that depends on location, they are unusable.
Gemini 2.5 Flash is roughly 2× worse than Pro at grounded OCR (0.092 vs 0.053). The gap is much larger than the marketing implies, if you’re building on Flash for cost savings, you’re paying with accuracy.
Pixtral-Large fails on parse rate. At 12%, meaning it produced no parseable bbox output on 88 of 100 pages, it’s effectively unusable for grounded OCR regardless of its actual CER on the pages it did process.
Cost vs accuracy
Accuracy isn’t the only thing that matters in production. The same benchmark, plotted against cost per 1,000 documents (log scale), looks like this:
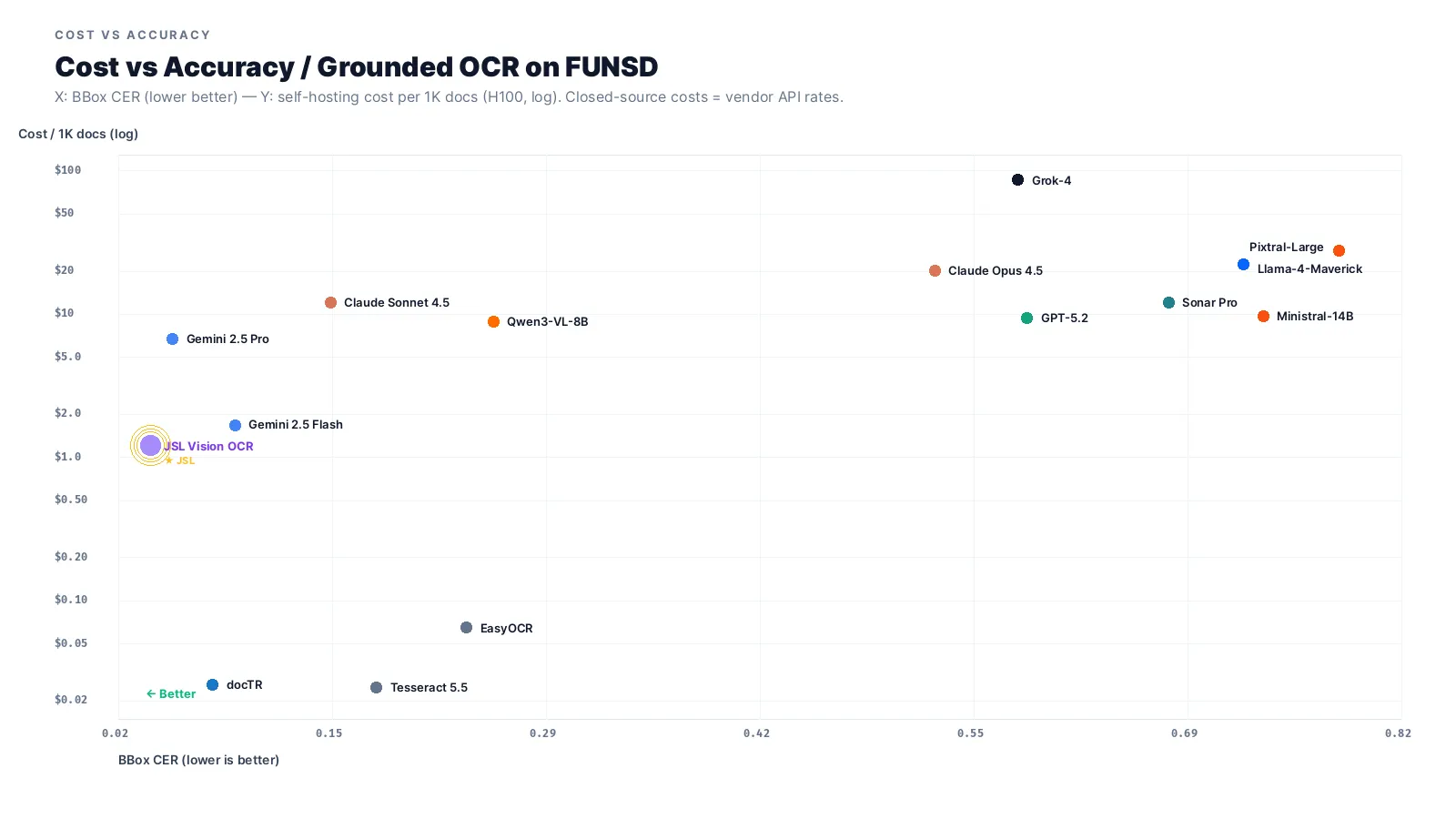
JSL Vision OCR sits in the bottom-left, the corner you want to be in: lowest CER, near-zero cost (~$0.56 per 1K docs on a single T4). The closed-source frontier models occupy the top-left: Gemini 2.5 Pro at ~$6.75 per 1K, GPT-5.2 at ~$9.45 per 1K. Grok-4 has dropped since launch (now ~$3.38 per 1K) but its 0.582 CER makes it unusable for grounded OCR regardless. Tesseract and EasyOCR are cheaper still (CPU-only) but their CER is 4–6× higher.
Why JSL Vision is so cheap: a single NVIDIA T4 at $0.50/hour handles all inference. At ~4 seconds per page on T4, that’s $0.00014 per second × 4 seconds × 1,000 = $0.56 for 1,000 documents. No API tokens. No data leaving your environment.
Avg duration per document
Latency matters for batch jobs and interactive use cases:
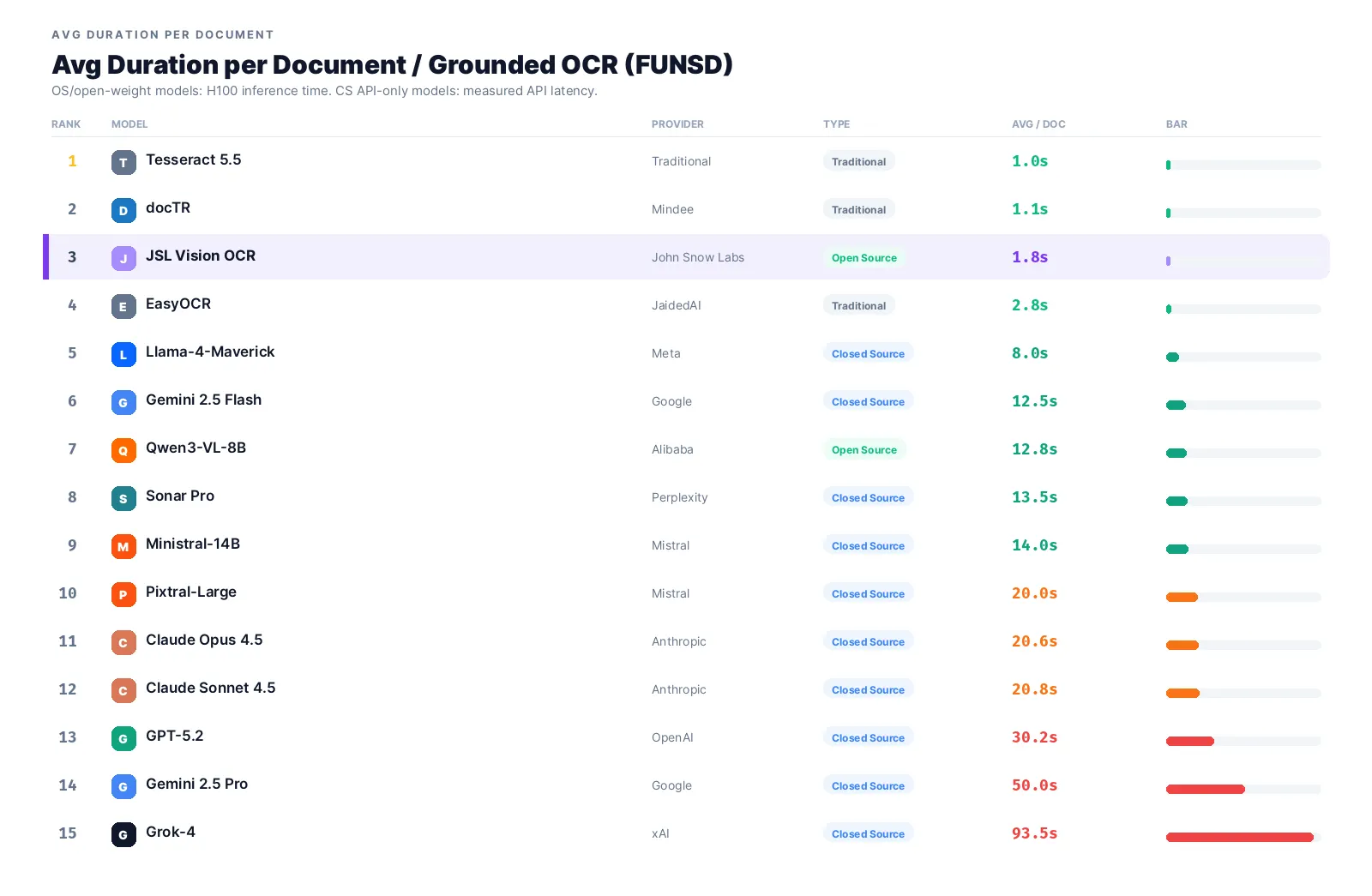
JSL Vision OCR is 3rd-fastest of 14 at 1.8s per page, beaten only by traditional engines (Tesseract, EasyOCR) that run on CPU but with 4–6× worse accuracy. Frontier APIs are an order of magnitude slower: Gemini 2.5 Pro (50s), Pixtral-Large (69s), Grok-4 (94s).
JSL Vision OCR vs traditional OCR
Tesseract and EasyOCR have been the production standard for bounding-box OCR for years. They detect text regions and return coordinates natively. JSL Vision OCR beats all of them.
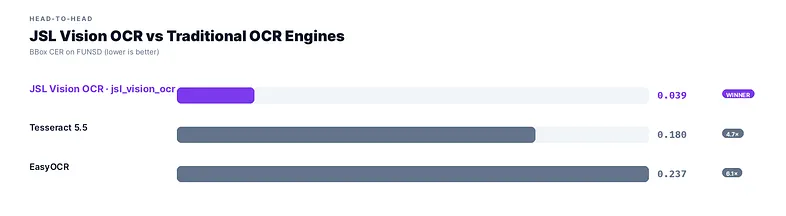
Tesseract (0.180 CER) is the closest traditional competitor at 4.7× worse accuracy. EasyOCR trails further at 6.1× worse. Neither handles handwriting, complex layouts, or non-English scripts reliably. JSL Vision OCR runs as a single end-to-end VLM pass with no two-stage pipeline, no per-document tuning, and a 100% parse rate.
Built for healthcare and regulated industries
JSL Vision OCR is designed for organizations that can’t send their data to external APIs:
- HIPAA / GDPR / SOC 2 compliance, data never leaves your infrastructure
- Deployable via Docker or Amazon SageMaker, production-ready today
- Single NVIDIA T4 (1B model) or A10G (8B model), no distributed infrastructure
- Deterministic, same input, same output, every time
- Any image-convertible input, PDF, PNG, JPG
How we ran the benchmark
- Dataset: FUNSD, Form Understanding in Noisy Scanned Documents. 100 pages from the training split.
- BBox CER metric: IoU-based spatial matching (threshold 0.3, score filter 0.15) followed by Levenshtein distance on matched text pairs. Unmatched regions counted as insertion/deletion errors.
- Closed-source models: Evaluated via OpenRouter API.
- Open-source VLMs: Evaluated via vLLM v0.17.1 on a single NVIDIA H100.
- Traditional OCR: Native Python libraries (tesserocr, easyocr).
- Parse rate: Percentage of pages where the model produced any parseable bounding-box output.
All results reproducible, code and per-page JSON caches archived on the JSL benchmark cluster.
CPU vs GPU: latency and cost
We benchmarked all major OS OCR models on both H100 GPU and c5.2xlarge CPU (8 vCPUs, float32) using HF transformers. Same 5 FUNSD pages, same prompts.
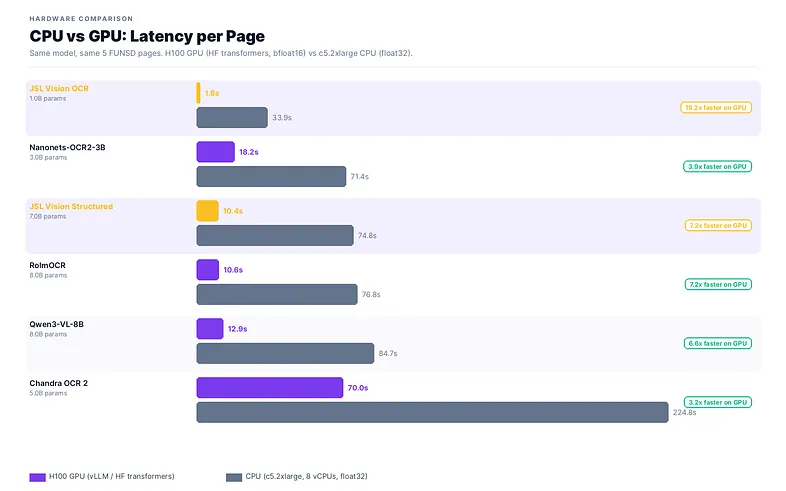
GPU is 2–7× faster per page across all model sizes. The speedup peaks at 7.2× for 7–8B models. JSL Vision OCR at 1.76s/page via vLLM is the fastest. vLLM’s optimized serving gives it an additional throughput advantage over the HuggingFace Transformers baseline used for other models.
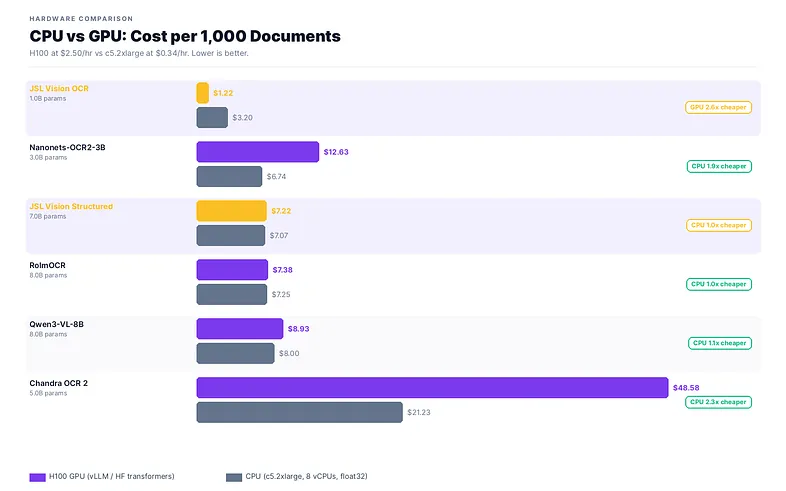
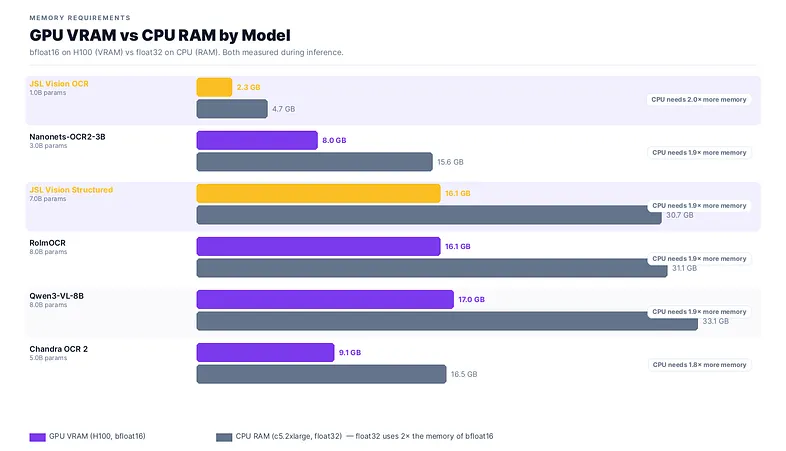
CPU compute at ~$0.34/hr is ~7× cheaper per hour than an H100 ($2.50/hr), so CPU comes out ahead on cost for most models despite the latency penalty. For JSL Vision OCR-1B, a T4 at $0.50/hr is the better call: close to CPU cost but 3–5× faster per page. JSL Vision OCR via vLLM at $0.56/1K docs on T4 beats every CPU option on both speed and cost simultaneously.
What’s next
This is the first of a three-part series:
- Grounded (BBox) OCR on FUNSD, you are here
- Image → Markdown OCR on FUNSD
- Schema-Constrained JSON OCR on OmniOCR
The numbers are reproducible, the methodology is public, and the hardware required is as little as a single T4 GPU. State-of-the-art grounded OCR no longer requires giving up your data or your infrastructure.
Building a de-identification, form extraction, or compliance auditing pipeline? Talk to us about JSL Vision OCR: we can run it on your documents.




